-
(arxiv-2018) 重新审视基于视频的 Person ReID 的时间建模
重新审视基于视频的 Person ReID 的时间建模
paper题目:Revisiting Temporal Modeling for Video-based Person ReID
paper是南加州大学发表在arxiv 2018的工作
paper链接:链接
Abstract
基于视频的行人重识别是一项重要任务,由于监控和摄像头网络的需求不断增加,近年来备受关注。一个典型的基于视频的person reID系统由三部分组成:图像级特征提取器(例如CNN)、聚合时间特征的时间建模方法和损失函数。尽管已经提出了许多时间建模方法,但很难直接比较这些方法,因为特征提取器和损失函数的选择对最终性能也有很大影响。我们全面研究和比较了四种不同的时间建模方法(时间池化、时间注意力、RNN 和 3D 卷积网络),用于基于视频的行人 reID。我们还提出了一种新的注意力生成网络,它采用时间卷积来提取帧之间的时间信息。评估是在 MARS 数据集上完成的,我们的方法大大优于最先进的方法。我们的源代码发布在 https://github.com/jiyanggao/Video-Person-ReID。
1 Introduction
行人重新识别(re-ID)解决了在不同的图像或视频中检索特定人员(即查询)的问题,这些图像或视频可能取自不同环境中的不同摄像机。近年来,由于公共安全需求的增加和监控摄像头网络的快速增长,它受到了越来越多的关注。具体来说,我们专注于基于视频的行人重识别,即给定一个人的查询视频,系统尝试在一组gallery视频中识别此人。
最近现有的大多数基于视频的person reID方法都是基于深度神经网络[12,13,24]。通常,三个重要部分对基于视频的行人 reID 系统有很大影响:图像级特征提取器(通常是卷积神经网络,CNN)、用于聚合图像级特征的时间建模模块和用于训练网络。在测试期间,使用上述系统将probe视频和gallery视频编码为特征向量,然后计算它们之间的差异(通常是 L2 距离)以检索前 N 个结果。最近关于基于视频的行人 reID 的工作 [12, 13, 24] 主要集中在时间建模部分,即如何将一系列图像级特征聚合成剪辑级特征。
以前关于基于视频的行人 reID 的时间建模方法的工作分为两类:基于循环神经网络 (RNN) 和基于时间注意力。在基于 RNN 的方法中,McLanghlin 等人[13] 提出使用 RNN 对帧之间的时间信息进行建模; Yan等人[20] 还使用 RNN 对序列特征进行编码,其中最终隐藏状态用作视频表示。在基于时间注意力的方法中,Liu 等人[12] 设计了一个质量感知网络(QAN),它实际上是一个注意力加权平均值,用于聚合时间特征;Zhou等人[24] 提出使用时间 RNN 和注意力对视频进行编码。此外,Hermans等人[7] 采用了三元组损失函数和简单的时间池化方法,并在 MARS [17] 数据集上实现了最先进的性能。
尽管已经报道了上述方法的大量实验,但很难直接比较时间建模方法的影响,因为它们使用不同的图像级特征提取器和不同的损失函数,这些变化会显著影响性能。例如,[13] 采用 3 层 CNN 对图像进行编码; [20] 使用了手工制作的特征; QAN [12] 提取 VGG [16] 特征作为图像表示。
在本文中,我们通过固定图像级特征提取器(ResNet-50 [6])和损失函数(triplet loss 和 softmax cross-entropy loss)来探索不同时间建模方法对基于视频的 person re-ID 的有效性) 相同。具体来说,我们测试了四种常用的时间建模架构:时间池化、时间注意力 [12、24]、循环神经网络 (RNN) [13、20] 和 3D 卷积神经网络 [5]。 3D卷积神经网络[5]直接将图像序列编码为特征向量;为了公平比较,我们保持网络深度与 2D CNN 相同。我们还提出了一种新的注意力生成网络,它采用时间卷积来提取时间信息。我们在 MARS [17] 数据集上进行了实验,这是迄今为止可用的最大的基于视频的 person reID 数据集。实验结果表明,我们的方法在很大程度上优于最先进的模型。
总之,我们的贡献有两个:首先,我们全面研究了 MARS 上基于视频的人 reID 的四种常用时间建模方法(时间池化、时间注意力、RNN 和 3D conv)。我们将发布源代码。其次,我们提出了一种新颖的基于 temporal-conv 的注意力生成网络,它在所有时间建模方法中实现了最佳性能;借助强大的特征提取器和有效的损失函数,我们的系统大大优于最先进的方法。
2 Related Work
在本节中,我们将讨论相关工作,包括基于视频和基于图像的行人识别和视频时间分析。
基于视频的人员重识别。以前关于基于视频的行人reID 的时间建模方法的工作分为两类:基于循环神经网络 (RNN) 和基于时间注意力。McLanghlin等人[13] 首次提出通过 RNN 对帧之间的时间信息进行建模,将 RNN 单元输出的平均值用作剪辑级别表示。与 [13] 类似,Y an 等人[20]还使用RNN对序列特征进行编码,最终的隐藏状态用作视频表示。Liu等人[12] 设计了一个质量感知网络(QAN),它本质上是一个注意力加权平均,用于聚合时间特征;注意分数是从帧级特征图生成的。Zhou等人[24]和Xu等人[15] 提出使用时间 RNN 和注意力对视频进行编码。Zhong等人[1] 提出了一个对 RGB 图像和光流进行建模的双流网络,使用简单的时间池化来聚合特征。最近,Zheng等人[17] 为基于视频的行人 reID 构建了一个新的数据集 MARS,它成为该任务的标准基准。
基于图像的人员重识别。最近关于基于图像的人员 reID 的工作主要通过两个方向提高了性能:图像空间建模和度量学习的损失函数。在空间特征建模的方向,Su等人[18]和Zhao等人[21]使用人体关节来解析图像并融合空间特征。Zhao等人[22] 提出了一种用于处理身体部位未对齐问题的部分对齐表示。至于损失函数,通常使用 Siamese 网络中的铰链损失和身份 softmax 交叉熵损失函数。为了学习有效的度量嵌入,Hermans 等人[7] 提出了一种改进的三元组损失函数,它为每个锚样本选择最难的正负样本,并取得了最先进的性能。
视频时间分析。除了 person reID 工作之外,其他领域的时间建模方法,如视频分类 [8]、时间动作检测 [3, 14],也是相关的。Karpathy等人[8] 设计了一个 CNN 网络来提取帧级特征,并使用时间池化方法来聚合特征。Tran等人[19] 提出了一个 3D CNN 网络来从视频剪辑中提取时空特征。Hara等人[5] 探索了具有 3D 卷积的 ResNet [6] 架构。Gao等人[2, 4] 提出了一个时间边界回归网络来定位长视频中的动作。
3 Methods
在本节中,我们将介绍整个系统管道和时间建模方法的详细配置。整个系统可以分为两部分:从视频剪辑中提取视觉表示的视频编码器,优化视频编码器的损失函数以及将probe视频与gallery视频匹配的方法。视频首先被切割成连续的非重叠剪辑 { c k } \left\{c_{k}\right\} {ck},每个剪辑包含 T T T帧。剪辑编码器将剪辑作为输入,并为每个剪辑输出一个 D \mathrm{D} D维特征向量 f c f_{c} fc。视频级特征是所有剪辑级特征的平均值。
3.1 Video Clip Encoder
3D CNN。对于 3D CNN,我们采用 3D ResNet [5] 模型,该模型采用具有 ResNet 架构的 3D 卷积核 [6],专为动作分类而设计。我们用行人的身份输出替换最终的分类层,并使用预训练的参数(在 Kinetics [9] 上)。该模型以 T T T个连续帧(即一个视频片段)作为输入,最终分类层之前的层被用作行人的表示。
对于 2D CNN,我们采用标准的 ResNet-50 [6] 模型作为图像级特征提取器。给定一个图像序列(即一个视频片段),我们将每个图像输入到特征提取器中,并输出一个图像级特征序列 { f c t } , t ∈ [ 1 , T ] \left\{f_{c}^{t}\right\}, t \in[1, T] {fct},t∈[1,T],它是一个 T × D T \times D T×D矩阵, n \mathrm{n} n是剪辑序列长度, D D D是图像级特征维度。然后我们应用时间聚合方法将特征聚合成单个剪辑级别的特征 f c f_{c} fc,这是一个 D 维向量。具体来说,我们测试了三种不同的时间建模方法:(1)时间池化,(2)时间注意力,(3)RNN;这些方法的架构如图 1 所示。
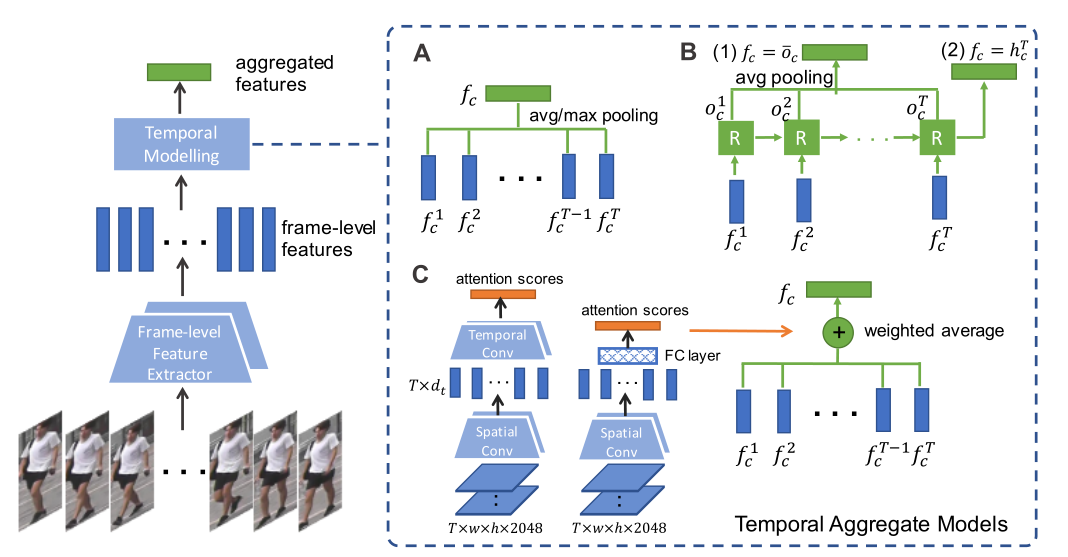
图 1:基于图像级特征提取器(通常是 2D CNN)的三种时间建模架构(A:时间池化,B:RNN 和 C:时间注意力)。对于 RNN,最终隐藏状态或单元输出的平均值用作剪辑级表示;对于时间注意力,展示了两种类型的注意力生成网络:“空间卷积+FC [12]”和“空间卷积+时间卷积”。
时间池化。在时间池化模型中,我们考虑最大池化和平均池化。对于最大池化, f c = max t ( f c t ) f_{c}=\max _{t}\left(f_{c}^{t}\right) fc=maxt(fct);对于平均池化, f c = 1 T ∑ t = 1 n f c t f_{c}=\frac{1}{T} \sum_{t=1}^{n} f_{c}^{t} fc=T1∑t=1nfct。
时间注意力。在时间注意力模型中,我们对图像特征序列应用注意力加权平均。鉴于剪辑 c c c的注意力是 a c t , t ∈ [ 1 , T ] a_{c}^{t}, t \in[1, T] act,t∈[1,T],那么
f c = 1 T ∑ t = 1 n a c t f c t f_{c}=\frac{1}{T} \sum_{t=1}^{n} a_{c}^{t} f_{c}^{t} fc=T1t=1∑nactfct
Resnet-50中最后一个卷积层的张量大小为 [ w , h , 2048 ] [w, h, 2048] [w,h,2048], w \mathrm{w} w和 h \mathrm{h} h取决于输入图像大小。注意力生成网络将一连串的图像级特征 [ T , w , h , 2048 ] [T, w, h, 2048] [T,w,h,2048]作为输入,并输出 T T T个注意力分数。我们设计了两种类型的注意力网络。(1) “空间卷积+FC[12]”。我们在上述输出张量上应用一个空间卷积层(核宽=w,核高=h,输入通道数=2048,输出通道数= d t d_{t} dt,简称 { w , h , 2048 , d t } \left\{w, h, 2048, d_{t}\right\} {w,h,2048,dt})和一个全连接(FC)层(输入通道= d t d_{t} dt,输出通道=1);卷积层的输出是一个标量向量 s c t , t ∈ [ 1 , T ] s_{c}^{t}, t \in[1, T] sct,t∈[1,T],作为剪辑 c c c的帧 t t t的分数。(2) “空间+时间卷积”:首先应用形状为 { w , h , 2048 , d t } \left\{w, h, 2048, d_{t}\right\} {w,h,2048,dt}的卷积层,然后我们得到剪辑的每一帧的 d t d_{t} dt维特征,我们在这些帧级特征上应用时间卷积层 { 3 , d t , 1 } \left\{3, d_{t}, 1\right\} {3,dt,1},生成时间注意力 s c t s_{c}^{t} sct。这两个网络如图1(C)所示。一旦我们有了 s c t s_{c}^{t} sct,有两种方法可以计算出最终的注意力分数 a c t a_{c}^{t} act:(1)Softmax函数[24]。
a c t = e s c t ∑ i = 1 T e s c i a_{c}^{t}=\frac{e^{s_{c}^{t}}}{\sum_{i=1}^{T} e^{s_{c}^{i}}} act=∑i=1Tesciesct
和(2)Sigmoid函数+L1归一化[12],
a c t = σ ( s c t ) ∑ i = 1 T σ ( s c i ) a_{c}^{t}=\frac{\sigma\left(s_{c}^{t}\right)}{\sum_{i=1}^{T} \sigma\left(s_{c}^{i}\right)} act=∑i=1Tσ(sci)σ(sct)
其中 σ \sigma σ表示Sigmoid函数。RNN。一个RNN单元在一个时间步骤 t t t对一个序列的图像特征进行编码,并将隐藏状态 h t h_{t} ht传递到下一个时间步骤。我们考虑用两种方法将一连串的图像特征聚合成一个单一的片段特征 f c f_{c} fc。第一种方法直接取上一个时间步骤的隐藏状态 h T h^{T} hT, f c = h c T f_{c}=h_{c}^{T} fc=hcT,如图1(B)所示。第二种方法计算RNN输出 { o t } , t ∈ [ 1 , n ] \left\{o^{t}\right\}, t \in[1, n] {ot},t∈[1,n]的平均值,即 f c = 1 T ∑ t = 1 T o c t f_{c}=\frac{1}{T} \sum_{t=1}^{T} o_{c}^{t} fc=T1∑t=1Toct。我们测试两种类型的RNN单元。长短期记忆(LSTM)和门控循环单元(GRU)。


-
相关阅读:
嵌入式 Linux 入门(十一、make 和 MakeFile)
小程序判断是否授权位置信息和手动授权
考研C语言复习进阶(6)
从 WebStorm 转到 VSCode!使用一周体验报告
痛快,SpringBoot终于禁掉了循环依赖
力扣 215. 数组中的第K个最大元素
【论文阅读 CIKM‘2021】Learning Multiple Intent Representations for Search Queries
CSS入门学习笔记例题详解(三)
es6总结
Docker实践笔记6:PHP容器制作
- 原文地址:https://blog.csdn.net/wl1780852311/article/details/126016333