-
CSV文件存储
📋 个人简介
💖 作者简介:大家好,我是W_chuanqi,一个编程爱好者
📙 个人主页:W_chaunqi
😀 支持我:点赞👍+收藏⭐️+留言📝
💬 愿你我共勉:“若身在泥潭,心也在泥潭,则满眼望去均是泥潭;若身在泥潭,而心系鲲鹏,则能见九万里天地。”✨✨✨
4.3 CSV 文件存储
CSV,全称为 Comma-Separated Values,中文叫作逗号分隔值或字符分隔值,其文件以纯文本形式存储表格数据。CSV 文件是一个字符序列,可以由任意数目的记录组成,各条记录以某种换行符分隔开。每条记录都由若干字段组成,字段间的分隔符是其他字符或字符串,最常见的是逗号或制表符。不过所有记录都有完全相同的字段序列,相当于一个结构化表的纯文本形式。它比 Excel 文件更加简洁,XLS 文本是电子表格,包含文本、数值、公式和格式等内容,CSV 中则不包含这些,就是以特定字符作为分隔符的纯文本,结构简单清晰。所以,有时候使用 CSV 来存储数据是比较方便的。下面我们就来了解 Python 读取数据和将数据写入 CSV 文件的过程。
1.写入
这里先看一个最简单的例子:
import csv with open('data.csv', 'w') as csvfile: writer = csv.writer(csvfile) writer.writerow(['id', 'name', 'age']) writer.writerow(['1001', 'Mike', '20']) writer.writerow(['1002', 'Bob', '22']) writer.writerow(['1003', 'Jordan', '21'])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
这里首先打开 data.csv 文件,然后指定打开的模式为w(即写入),获得文件句柄,随后调用 csv库的 writer 方法初始化写入对象,传入该句柄,然后调用 writerow 方法传入每行的数据,这样便完成了写入。
运行结束后,会生成一个名为 data.csv 的文件,此时数据就成功写入了。直接以文本形式打开,
会显示如下内容:
可以看到,写入 CSV 文件的文本默认以逗号分隔每条记录,每调用一次 writerow 方法即可写入一行数据。用 Excel 打开 data.csv 文件的结果如图所示。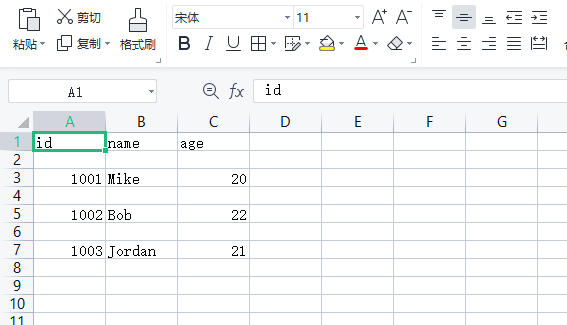
如果想修改列与列之间的分隔符,可以传入delimiter参数,其代码如下:
import csv with open('data.csv', 'w') as csvfile: writer = csv.writer(csvfile, delimiter=' ') writer.writerow(['id', 'name', 'age']) writer.writerow(['1001', 'Mike', '20']) writer.writerow(['1002', 'Bob', '22']) writer.writerow(['1003', 'Jordan', '21'])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
注意:

这里出现了异常,原因是这个文件在WPS里打开了,无法写入。。。
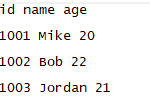
这里在初始化写人对象时,将空格传入了 delimiter 参数,此时输出结果中的列与列之间就是以空格分隔了,内容如下:
另外,我们也可以调用 writerows 方法同时写入多行,此时参数需要传人二维列表,例如:import csv with open('data.csv', 'w') as csvfile: writer = csv.writer(csvfile) writer.writerow(['id', 'name', 'age']) writer.writerows( [['1001', 'Mike', '20'], ['1002', 'Bob', '22'], ['1003', 'Jordan', '21']])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
输出结果是相同的,内容如下:

但是一般情况下,爬虫爬取的都是结构化数据,我们一般会用字典表示这种数据。csv库也提供了字典的写入方式,实例如下:
import csv with open('data.csv', 'w') as csvfile: fieldnames = ['id', 'name', 'age'] writer = csv.DictWriter(csvfile, fieldnames=fieldnames) writer.writeheader() writer.writerow({'id': '1001', 'name': 'Mike', 'age': '20'}) writer.writerow({'id': '1002', 'name': 'Bob', 'age': '22'}) writer.writerow({'id': '1003', 'name': 'Jordan', 'age': '21'})- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
这里先定义了 3个字段,用 fieldnames 表示,然后将其传给 Dictwriter 方法以初始化一个字典写入对象,并将对象赋给 writer 变量。接着调用写入了对象的 writeheader 方法先写入头信息,再调用writerow方法传人了相应字典。最终写人的结果和之前是完全相同的,内容如下:

这样就把字典写人了 CSV 文件中。
另外,如果想追加写入,可以修改文件的打开模式,即把 open 函数的第二个参数改成a,代码如下:
import csv with open('data.csv', 'a') as csvfile: fieldnames = ['id', 'name', 'age'] writer = csv.DictWriter(csvfile, fieldnames=fieldnames) writer.writerow({'id': '1004', 'name': 'Durant', 'age': '25'})- 1
- 2
- 3
- 4
- 5
- 6
- 7
这样再次执行这段代码,文件内容便会变成:
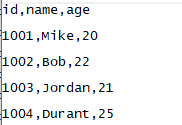
由结果可见,数据被追加写人到了文件中。
如果要写入中文内容,我们知道可能会遇到字符编码的问题,此时需要给 open 参数指定编码格式。例如,这里再写入一行包含中文的数据,代码改写如下:
import csv with open('data.csv', 'a', encoding='utf-8') as csvfile: fieldnames = ['id', 'name', 'age'] writer = csv.DictWriter(csvfile, fieldnames=fieldnames) writer.writerow({'id': '1004', 'name': '张伟', 'age': '25'})- 1
- 2
- 3
- 4
- 5
- 6
- 7
这里要是没有给 open 函数指定编码,可能会发生编码错误。
另外,如果接触过pandas等库,可以调用 DataFrame对象的to_csv方法将数据写入CSV文件中。
这种方法需要安装 pandas 库,安装命令为:
pip install pandas- 1
安装完成之后,我们便可以使用 pandas 库将数据保存为 CSV 文件,实例代码如下:
import pandas as pd data = [{'id': '1001', 'name': 'Mike', 'age': '20'}, {'id': '1002', 'name': 'Bob', 'age': '22'}, {'id': '1003', 'name': 'Jordan', 'age': '21'} ] df = pd.DataFrame(data) df.to_csv('data.csv', index=False)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
这里我们先定义了几条数据,每条数据都是一个字典,然后将其组合成一个列表,赋值为 data。紧接着我们使用 pandas 的 DataFrame 类新建了一个 DataFrame 对象,参数传入 data,并把该对象赋值为 df。最后我们调用 df 的 to_csv 方法也可以将数据保存为 CSV 文件。
2.读取
我们同样可以使用 csv 库来读取 CSV 文件。例如,将刚才写入的文件内容读取出来,相关代码如下:
import csv with open('data.csv', 'r', encoding='utf-8') as csvfile: reader = csv.reader(csvfile) for row in reader: print(row)- 1
- 2
- 3
- 4
- 5
- 6
运行结果如下:
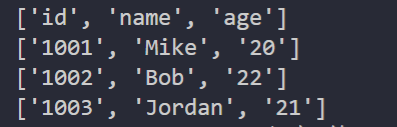
这里我们构造的是 Reader 对象,通过遍历输出了文件中每行的内容,每一行都是一个列表。注意,如果 CSV 文件中包含中文,还需要指定文件编码。
另外,我们也可以使用 pandas 的 read_csv 方法将数据从 CSV 文件中读取出来,例如:
import pandas as pd df = pd.read_csv('data.csv') print(df)- 1
- 2
- 3
运行结果如下:
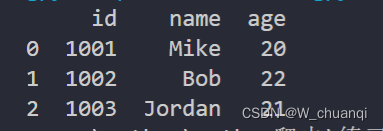
这里的 df 实际上是一个 DataFrame 对象,如果你对此比较熟悉,则可以直接使用它完成一些数据的分析处理。
如果只想读取文件里面的数据,可以把 df 再进一步转化为列表或者元组,实例代码如下:
import pandas as pd df = pd.read_csv('data.csv') data = df.values.tolist() print(data)- 1
- 2
- 3
- 4
这里我们调用了df 的valves属性,再调用 tolist方法,即可将数据转化为列表形式,运行结果如下:

另外,直接对 df 进行逐行遍历,同样能得到列表类型的结果,代码如下:
import pandas as pd df = pd.read_csv('data.csv') for index, row in df.iterrows(): print(row.tolist())- 1
- 2
- 3
- 4
- 5
运行结果如下:
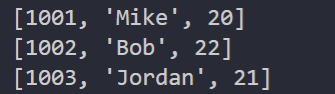
可以看到,我们同样获取了列表类型的结果。
-
相关阅读:
RocketMQ consumer 和 queue 对应关系
BATCH/批处理命令
IB考试45分是如何做到的?
Java源码分析(一)Integer
Linux su sudo命令
4383 [八省联考 2018] 林克卡特树(WQS 二分+DP)
LeetCode | 307. 区域和检索 - 数组可修改
JAVA核酸预约检测管理系统毕业设计 开题报告
2023-亲测有效-git clone失败怎么办?用代理?加git?
LVS负载均衡集群
- 原文地址:https://blog.csdn.net/W_chuanqi/article/details/126018385