-
操作系统--进程概念
前言:
管理的理念
- 用结构体或者类描述一个被管理对象
- 当对象很多时,就要通过特定的数据结构来组织对象,因此这就回到对数据结构的增删查改。—而那些特点的数据结构有很多,这也是数据结构这门科目出现的部分原因
- 同样作为OS的4大管理块中的进程管理,我们要想管理好一个进程,就要先描述进程,再组织进程
进程
概念
狭义上:进程指的是加载到内存中的程序文件,但这非常不利于OS管理,组织进程。
广义上:由OS为维护加载到内存中程序文件的创建的属 性集合==进程控制块PCB(process control block)==和 加载到内存中的程序文件构成的集合。
特点
进程是具有独立性的,各个进程之间互不干扰。
进程控制块–PCB
-
PCB包含了进程的所有属性信息,这样OS就可以通过PCB,间接管理进程而不需要与程序文件进行交互即
进程的管理任务与PCB具体强相关,而与程序文件无关,
-
不同操作系统下,PCB的称呼不同,linux下,它的PCB称为task_struct
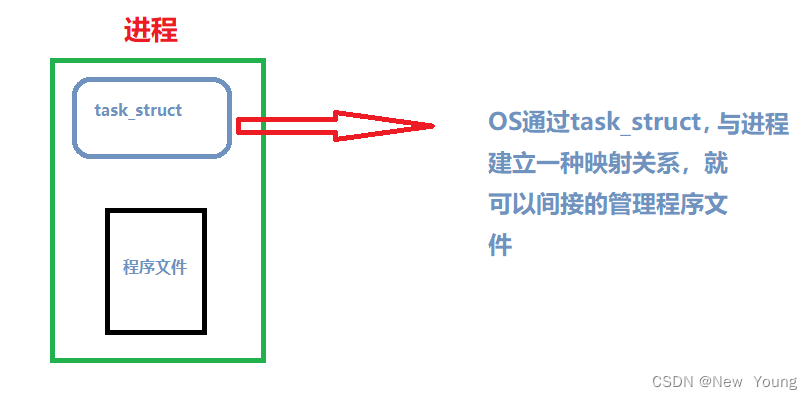
PCB的内部构成
介绍常见的
ID
-
描述进程的唯一标示符,用来区别其他进程。可以getpid()函数获得自己的ID,也通过getppid获得父进程的标识符ID

-
在命令行上运行的命令,其父进程都是bash

上下文数据
- 一个进程是不可能一直占用CPU资源的,而平常我们观察到的进程似乎是一直在运行着是因为:OS会规定每个进程在CPU中的单次运行时间片,(这时间片是非常非常小的,纳秒级别),一但进程运行超过了这个时间片,CPU会将该进程暂时弹出,执行下一个进程,因为时间足够小,在我们人看来进程是一直运行的,但对CPU来说是不一样的
- 同时进程在运行是会产生大量的临时数据(各种寄存器,外设,内存等),如果不及时保存这些数据,当再次占据CPU资源时,会产生紊乱,因此我们可以在PCB嵌套定义一个结构体用于记录临时数据,这称为保存上下文数据。当再次占据CPU资源时,恢复临时数据,这称为恢复上下文数据,通过这种操作就可以在进程的被切换时,而不影响进程的运行
状态:
-
任务状态(下面详解),退出代码,退出信号。
-
一般进程结束都会将退出码返回给父进程,以便父进程获取信息,这也是大多数语言中的main,最后都要返回一个值。通echo $?,可以获得最近进程的退出码。

优先级:
CPU是有限的,而进程数量是很多的,要想分配管理好每个进程必然要有一个规则去规定进程的先后顺序
程序计数器:
程序中即将被执行的下一条指令的地址。同函数栈帧时记录call下一条指令地址。
内存指针:
指向程序代码和进程相关数据的指针,还有指向其他进程共享的内存块的指针。
I/ O状态信息:
- 包括显示的I/O请求,分配给进程的I/ O设备(屏幕,键盘,网卡等)和被进程使用的文件列表。
- 程序进行的IO,最终都会以进程的形式进行IO
记账信息:
- CPU资源的时间总和,CPU总会依据该时间总和,来均衡的让其它进程去使用CPU资源
- 使用的时钟数总和,时间限制,记账号等
创建进程
当单个进程无法满足需求时,我们可以通过fork()OS接口来创建子进程来帮助完成一部分需求。
父子进程
我们创建子进程,是为了完成父进程不能完成的需求,同时进程是具有独立性,互不干扰的,因此子进程的PCB ,代码,数据是有变化的
PCB
- 子进程的PCB会以父进程的PCB为模板来初始化自己的PCB
- 因为父子进程的PCB中的程序计数器–(存放下一条指令的地址)是相同的,这也是为什么在输出设备上,子进程不会执行之前的代码,而是依据程序计数器直接执行下一条指令。
代码
代码是不可更改的,因此父子进程共享代码
数据
如果父子进程共享同样的数据,一旦数据变化,会严重破坏进程的独立性,因此对于数据
- 如果父子进程只是读数据,那么他们共享该数据
- 如果父子进程中出现了写数据,会采用“写时拷贝"即开辟另外一份空间存放数据的方式,维护进程的独立性
fork()
现象
观察下列代码
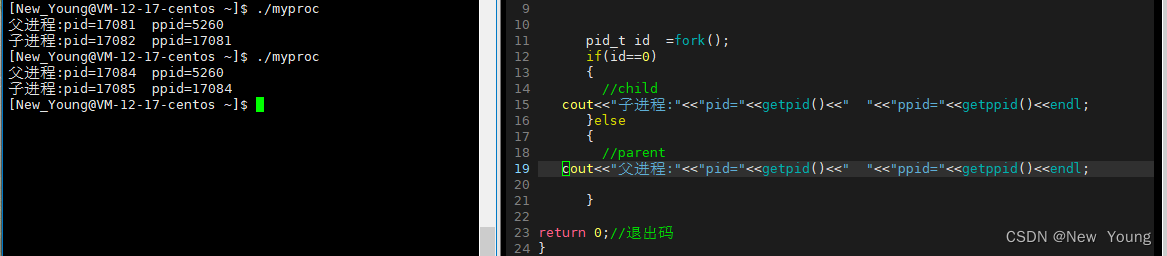
-
父子进程的结果是不同的?-----即id的值是不同的
-
fork函数有2个返回值?
结论
- fork函数的返回值是要写入到 id这块内存中的,为了进程的独立性,这需要进行“写时拷贝",自然就有2分独立的id空间
- 对于父进程来说,它的子进程可能会很多,而要想找到子进程,只能通过pid识别,因此fork()函数对父进程返回子进程的pid,但是子进程可以通过 getppid找到父进程,因此fork函数对子进程返回0;

进程状态
状态分类
static const char * const task_state_array[] = { "R (running)", /* 0 */ "S (sleeping)", /* 1 */ "D (disk sleep)", /* 2 */ "T (stopped)", /* 4 */ "t (tracing stop)", /* 8 */ "X (dead)", /* 16 */ "Z (zombie)", /* 32 */ };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
R运行状态
R并不意味着进程一定在运行中,它表明:进程要么是在CPU中正在运行,要么在运行队列中进行排队
S浅度睡眠状态–阻塞/挂起
- 进程不一定只使用CPU资源,可能还会使用外设资源,如:网卡,键盘,屏幕等,只有这些资源同时具备了,进程才能运行下去,而在获得某些资源的返回信息前,进程处于浅度睡眠。
- S状态下,获得资源返回信息后,进程就可以运行了,因此S是可中断状态
D深度睡眠状态—阻塞/挂起
类似S状态,但是D状态可能需要等待很长时间的资源反馈,为了避免被杀死,D状态又称为 不可中断状态。
T暂定状态
可以通过发送 SIGSTOP 信号给进程来停止(T)进程。这个被暂停的进程可以通过发送 SIGCONT 信号让进程继续运行
t追踪状态
类似VS下的打断点,让进程stop,以观察数据信息
X死亡状态
- 进程死亡后,父进程获得相关信息,回收子进程的资源
- 回收资源是瞬间的,因此这个状态不可观察到
Z僵尸状态
任何进程在死亡前,OS都会将其死亡的原因,时间等信息返回给父进程,这样父进程就可以控制回收子进程资源,而一旦子进程资源未被回收,子进程就处于 “僵尸状态”。之后进程进入死亡状态,回收资源。
经典状态验证
R状态

S状态
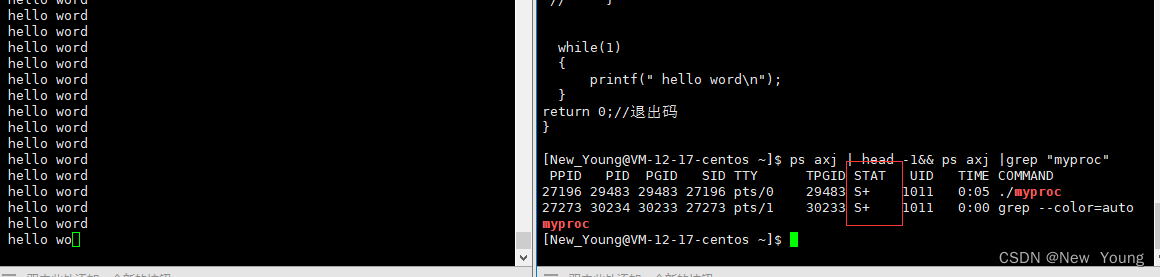
为什么程序在我们看来是在一直运行?
printf函数是需要驱动屏幕,只有当屏幕进行反馈后,进程才能继续进行,但是这个时间消耗对于CPU来说是很长的,因此CPU会将进程设置为S状态,当资源齐全后,唤醒进入R状态
T状态
通过指令 kill -19 +PID,可以暂停一个进程
通过 kill -18 +PID ,可以恢复一个进程
通过kill -9 +PID,可以杀死一个进程

少+号的原因:
- 进程默认是在前台运行,一但通过指令暂停进程,进程就会由前台运行转为后台运行
- 前台下:可以通过ctrl+c,结束进程,但是不能进行任何指令相关操作
- 后台下:不同通过ctr+c,结束进程,只能通过kill指令,且能正常指向shell指令
Z状态
当子进程死亡时,父进程不采取任何行动时,子进程进入Z状态
孤儿进程
当父进程死亡时,子进程为死亡,子进程处于"孤儿状态",同时子进程的会被OS领养。
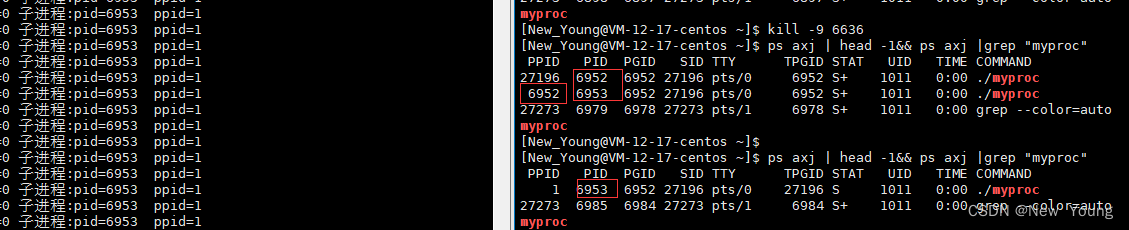
优先级
因为CPU资源是有限的,进程之间必然要有优先级

- UID : 代表执行者的身份
- PID : 代表这个进程的代号
- PPID :代表这个进程是由哪个进程发展衍生而来的,亦即父进程的代号
- PRI :代表这个进程可被执行的优先级,其值越小越早被执行
- NI :代表这个进程的nice值 ,范围[-20,19]
PRI and NI
- RI也还是比较好理解的,即进程的优先级,或者通俗点说就是程序被CPU执行的先后顺序,此值越小进程的优先级别越高
那NI呢?就是我们所要说的nice值了,其表示进程可被执行的优先级的修正数值 - PRI值越小越快被执行,那么加入nice值后,将会使得PRI变为: PRI(new)=PRI(old)+nice,PRI总是以80为起点
这样,当nice值为负值的时候,那么该程序将会优先级值将变小,即其优先级会变高,则其越快被执行 - 所以,调整进程优先级,在Linux下,就是调整进程nice值
nice其取值范围是-20至19,一共40个级别
PRI vs NI
需要强调一点的是,进程的nice值不是进程的优先级,他们不是一个概念,但是进程nice值会影响到进程的优先级变化。可以理解nice值是进程优先级的修正修正数据
总结
操作系统概念挺多的,细学吧!
-
相关阅读:
解决Java 8 date/time type `java.time.LocalDateTime` not supported by default
【MySQL 8.0新特性】窗口函数
TiDB ——TiKV
每天学习一点英语——number,amount,quantity区别、用法
代理模式+动态代理+静态代理+那些使用场景?
HTML期末大作业(HTML+CSS+JavaScript响应式游戏资讯网站bootstrap网页)
【已解决】Unity 使用NPOI 写word文档报错:System.TypeLoadException:……0.86.0.518
【补题日记】[2022杭电暑期多校3]B-Boss Rush
【XGBoost】第 5 章:XGBoost 揭幕
化工原理 --- 热量传递
- 原文地址:https://blog.csdn.net/qq_55439426/article/details/126018679