-
深入理解Linux0.11内核之文件系统之SYS_WRITE系统调用
上篇文章从硬件层面对磁盘做了一个简单的介绍,让读者大概清楚了一个磁盘内部的组成,明白了其中最小单位扇区,一个扇区512字节。并且介绍了Linux0.11内核中使用的MINIX文件系统(也就是抽象一层对磁盘的描述),让读者对引导块、超级快、逻辑位图、inode位图、inode、数据块(除了数据块,其他的都是描述数据块的元数据信息)。有一个初步的认识。并且因为磁盘和内存速度相差太大,所以引入了内存中的高速缓存。因为对齐的问题,缓存块和数据块的大小都是1024大小。并且也存在元数据信息描述——缓存头。为了快速找到数据块对应的缓存块,那么对于缓存块的元数据信息缓存头做了一个HASH表的映射(O1时间复杂度)。并且因为数据块和缓存块的数量不一致,所以还引入了空闲链表来对缓存头做了一个双向链表,其目的是当HASH映射不成功时就从空闲链表中寻找一个合适的缓存头来和数据块做映射,并且会加入到HASH表中做映射,下次就可以直接从HASH表中通过O1复杂度来遍历映射。以上内容都是对上篇文章做的总结,并且这些内容都是本节课的前置知识。
正文:
在Linux0.11内核中所有的系统调用都是通过int 0x80中断向量发起的软件中断(对于中断的说法,各有千秋,有人说中断就是异常,而中断又有硬件中断、软件中断之类)马上会出关于中断的文章,会仔仔细细来描述中断的流程。而我这个系列都会按照intel手册中的说法。

intel手册的描述 就分为,硬件中断和异常,而异常又分为abort、fault、trap,而硬件中断其实也是符合异常这三种其中一种。所以外面很多书就把中断叫成异常.....(是不是感觉越讲越乱了,其实大可不必纠结),对于我们暂时先明白0x80是一个同步发生的中断,是需要主动触发的一个中断(所以称之为同步中断)。再再再次强调,先不要纠结中断的类别,我们先回归正题追寻int 0x80中断向量产生的系统调用。
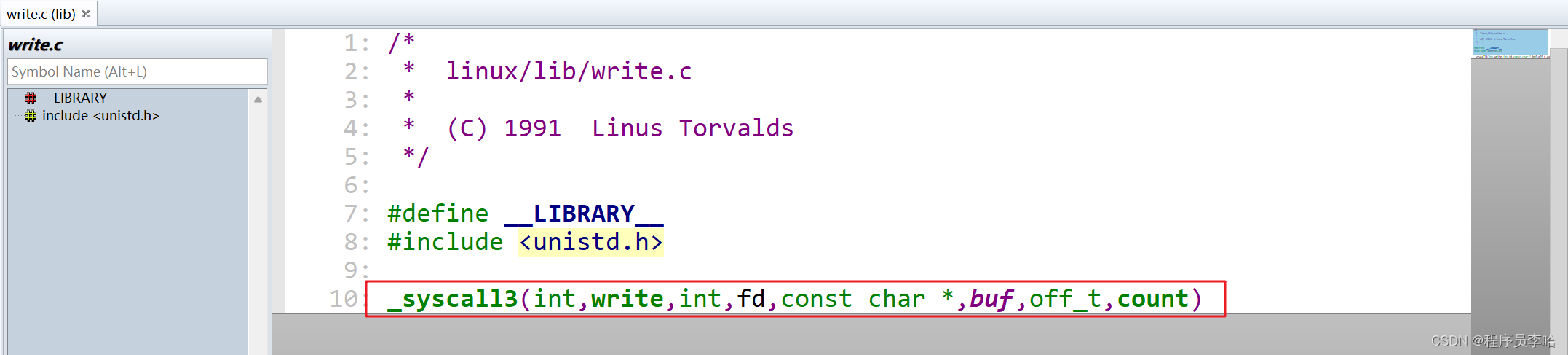
Linux0.11内核源码write.c文件 - // 这里通过int 0x80产生了一个中断。
- // 并且把系统调用的编号放到了eax寄存器中(因为后续要通过编号查表)
- // 并且把参数a放到了ebx寄存器中
- // 并且把参数b放到了ecx寄存器中
- // 并且把参数c放到了edx寄存器中。
- #define __NR_write 4
- #define _syscall3(type,name,atype,a,btype,b,ctype,c) \
- type name(atype a,btype b,ctype c) \
- { \
- long __res; \
- __asm__ volatile ("int $0x80" \
- : "=a" (__res) \
- : "0" (__NR_##name),"b" ((long)(a)),"c" ((long)(b)),"d" ((long)(c))); \
- if (__res>=0) \
- return (type) __res; \
- errno=-__res; \
- return -1; \
- }
内联汇编后续也会出帖子来详解,但是其实也不影响继续往下走,这里的内联汇编,也就是使用int 0x80产生了一个中断,并且把系统调用的编号放入到eax寄存器中,把其他函数参数分别放到了ebx、ecx、edx寄存器中。
当发生了中断以后,CPU就会去Linux内核中找到内核实现的idt表项。通过0x80中断向量找到具体的中断描述符,再通过中断描述符找到具体的回调方法。
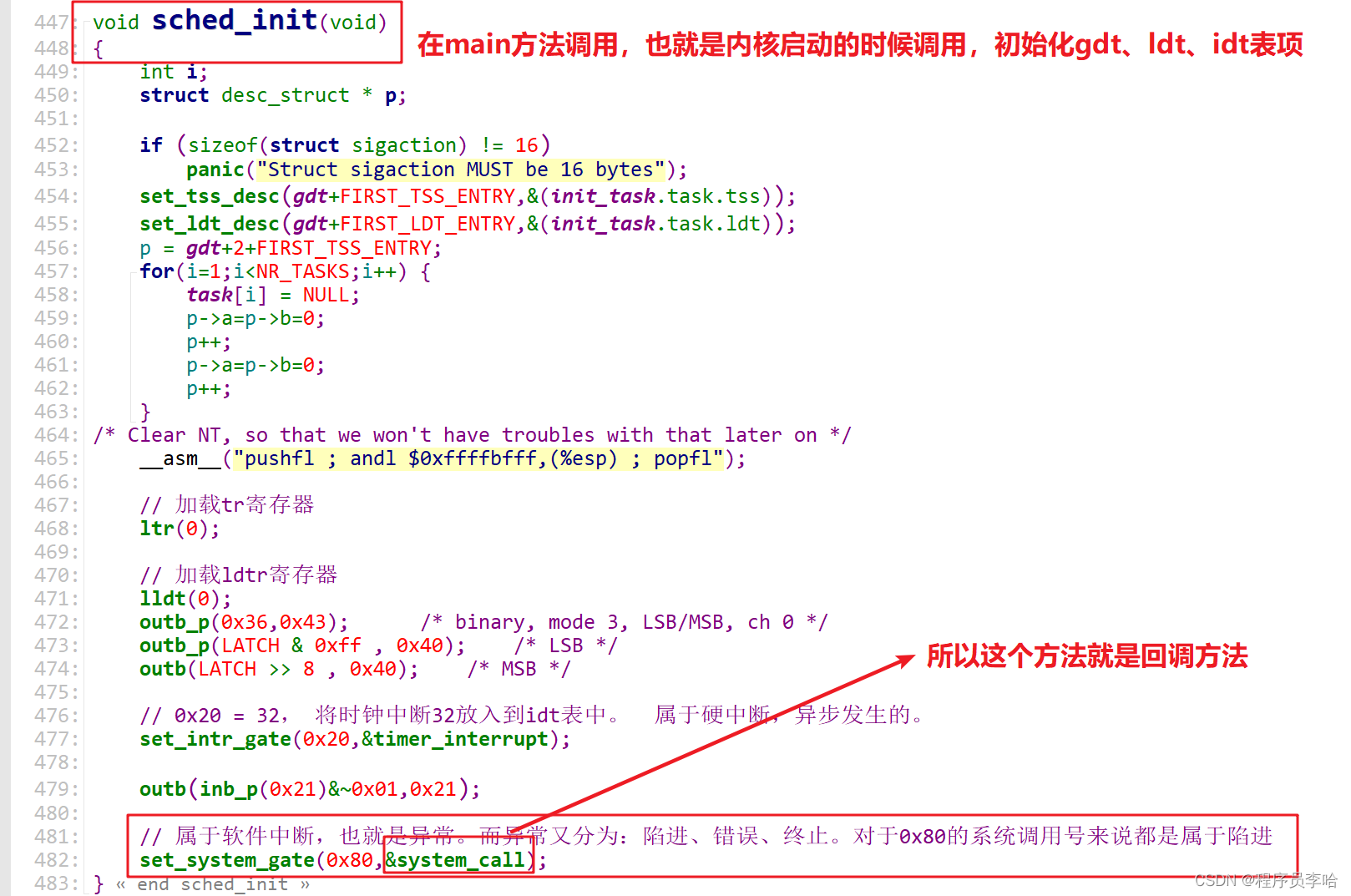
Linux0.11内核源码sched.c文件 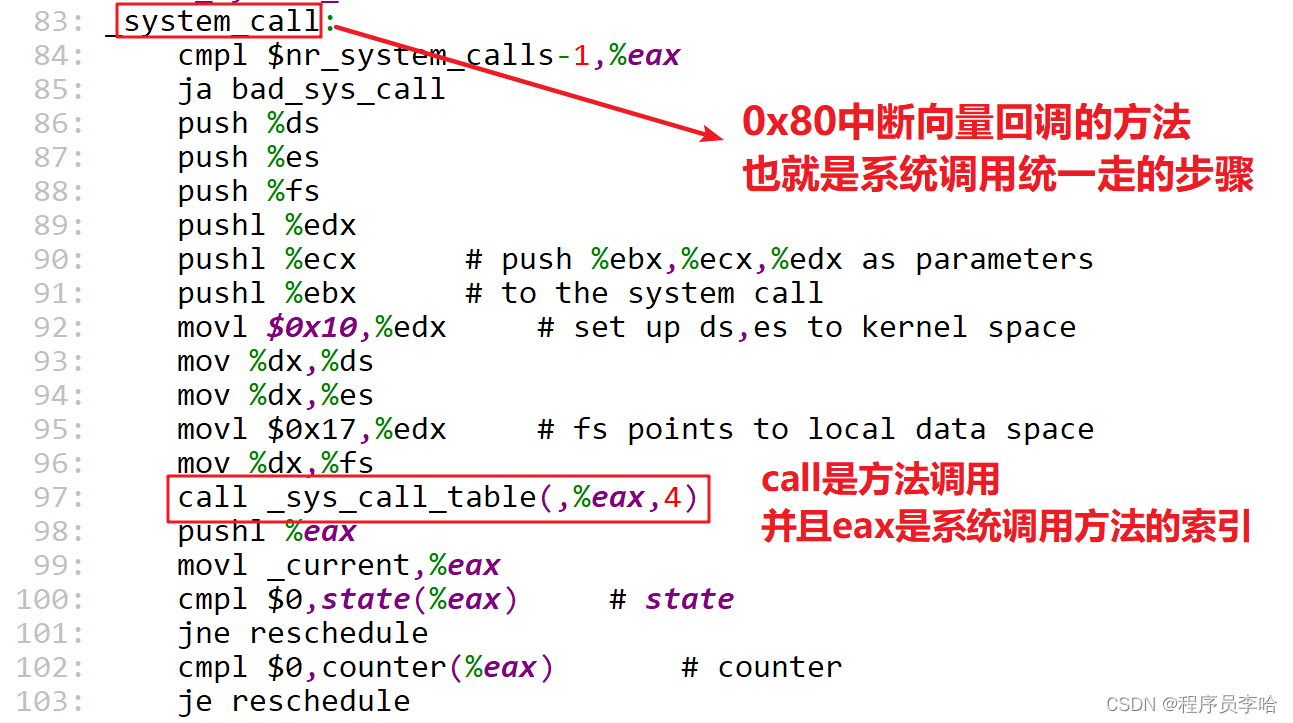
Linux0.11内核源码system_call.s文件 
Linux0.11内核源码sys.h文件 对上面几张图的操作做一个总结:
- 在main方法启动内核时会通过sched_init方法对gdt、ldt、idt表项以及其他操作初始化。所以这里对0x80中断向量进行了初始化,当触发此中断,会调用到system_call函数来进行处理。
- 当发生int 0x80中断操作后,CPU会去找内核实现的idt表项,通过0x80中断向量找,最后找到0x80对应的处理函数system_call。
- 所以找到system_call方法,这里是汇编代码, 看不懂没关系。这里通过call指令找sys_call_table表,通过eax寄存器(eax是之前内联汇编传来的索引)*4(因为int数组的一个单元是4个字节)定位到具体的系统调用。最终找到了本文章讲术的sys_write系统调用,对于0.11内核来说,系统调用的流程都是这样。
- // fd是具体打开的文件索引下表,通过sys_open函数调用分配给用户态.
- // char * buf是写入的数据
- // count 是写入的长度。 一般这种写入都是这种套路,写入的数据+写入的长度.
- int sys_write(unsigned int fd,char * buf,int count)
- {
- // 一个打开的文件,抽象成一个file结构体
- struct file * file;
- struct m_inode * inode;
- //
- if (fd>=NR_OPEN || count <0 || !(file=current->filp[fd]))
- return -EINVAL;
- // 文件操作的大小为0
- if (!count)
- return 0;
- // 获取到当前file数组元素对应的inode。
- inode=file->f_inode;
- // 管道文件,这不不属于我们关注的点。
- if (inode->i_pipe)
- return (file->f_mode&2)?write_pipe(inode,buf,count):-EIO;
- // 字符文件
- if (S_ISCHR(inode->i_mode))
- return rw_char(WRITE,inode->i_zone[0],buf,count,&file->f_pos);
- // 操作块设备,也就是操作disk.
- if (S_ISBLK(inode->i_mode))
- return block_write(inode->i_zone[0],&file->f_pos,buf,count);
- // 常规文件处理。
- if (S_ISREG(inode->i_mode))
- return file_write(inode,file,buf,count);
- // 什么都不是就直接打印错误,并且返回
- printk("(Write)inode->i_mode=%06o\n\r",inode->i_mode);
- return -EINVAL;
- }
因为当前是MINIX文件系统,所以抽象成一块一块的数据块,所以直接看到block_write()方法。
- //
- int block_write(int dev, long * pos, char * buf, int count)
- {
- // 得到当前在第几块
- int block = *pos >> BLOCK_SIZE_BITS;
- // 得到一块中具体的偏移量
- int offset = *pos & (BLOCK_SIZE-1);
- int chars;
- int written = 0;
- struct buffer_head * bh;
- register char * p;
- while (count>0) {
- // 一个块的大小减去偏移量,等于当前这个块剩余的数量
- chars = BLOCK_SIZE - offset;
- // 一块足够了
- if (chars > count)
- chars=count;
- // 如果刚好又一块的大小
- if (chars == BLOCK_SIZE)
- // 根据设备号和第几块得到具体的缓存头。
- // 内部维护了一个hash表+链表。 空闲链表。
- bh = getblk(dev,block);
- // 不整齐的处理,底层还是getblk
- else
- bh = breada(dev,block,block+1,block+2,-1);
- block++;
- if (!bh)
- return written?written:-EIO;
- // 走到这里就代表已经获取到了bh。所以下面的操作都是写入到高速缓存的逻辑。
- // 这里都是算出这次写入后的偏移量值。
- p = offset + bh->b_data;
- offset = 0;
- *pos += chars;
- written += chars;
- count -= chars;
- // 具体的写入过程,
- while (chars-->0)
- *(p++) = get_fs_byte(buf++);
- // 这里代表数据已经脏了。
- bh->b_dirt = 1;
- brelse(bh);
- }
- return written;
- }
对以上操作做出一个总结:
- 通过fd,找到具体的file文件,file结构体在内核中就是打开的一个文件。所以file结构体的操作肯定是在sys_open系统调用中处理的。
- 通过file拿到具体的inode节点。之前介绍的MINIX文件系统中,inode是描述数据块的,所以在这里inode是描述多个数据块组成一个文件。
- 通过file结构体中的pos参数,因为file结构体是打开文件的一个抽象,所以pos是打开文件后此文件的偏移量。然后通过pos参数算出具体的是那一块,并且一块是1024byte,也就可以获取到一块中具体的offset.
- 根据设备号和块号通过getblk方法找到对应的缓存头。得到缓存头就可以获取到缓存头对应的缓存块,进行写入了。
这里的操作就是getblk,和breada两个方法。而breada方法底层也就是使用getblk,所以这里就只讲解getblk。
- struct buffer_head * getblk(int dev,int block)
- {
- struct buffer_head * tmp, * bh;
- repeat:
- // 找到了就返回,没找到就往下走。
- if (bh = get_hash_table(dev,block))
- return bh;
- // 没通过hash表拿到,我们就通过空闲链表来获取。
- tmp = free_list;
- do {
- // 如果不为0就代表已经被其他人使用了。
- if (tmp->b_count)
- continue;
- // bh是当前,tmp是下一个
- // BADNESS(tmp)
- if (!bh || BADNESS(tmp)<BADNESS(bh)) {
- bh = tmp;
- // 找到为0的就很满足的离开了。 但是也有可能遍历完全部也找不到...
- if (!BADNESS(tmp))
- break;
- }
- /* and repeat until we find something good */
- } while ((tmp = tmp->b_next_free) != free_list);
- // 如果上面的do while循环执行完毕都没有找到bh,那就先休息一下,再继续找
- // 也就是目前没有空闲。
- if (!bh) {
- // 传入一个buffer等待队列进去。
- sleep_on(&buffer_wait);
- goto repeat;
- }
- // 走到这里代表通过空闲链表已经找到了...
- // 为了没有bug,这里再次判断是否已经被其他进程给上锁了,如果上锁了继续睡眠等待,等待继续尝试。
- wait_on_buffer(bh);
- // 执行到这里代表是当前进程获取到锁了。
- // 但是已经被其他进程使用了,所以重新寻找。
- if (bh->b_count)
- goto repeat;
- // b_dirt 修改标志位, 0未修改 ,1已修改。
- // 进while循环就代表是已被修改的
- while (bh->b_dirt) {
- // 脏数据先写回磁盘中。
- sync_dev(bh->b_dev);
- wait_on_buffer(bh);
- if (bh->b_count)
- goto repeat;
- }
- /* NOTE!! While we slept waiting for this block, somebody else might */
- /* already have added "this" block to the cache. check it */
- if (find_buffer(dev,block))
- goto repeat;
- /* OK, FINALLY we know that this buffer is the only one of it's kind, */
- /* and that it's unused (b_count=0), unlocked (b_lock=0), and clean */
- bh->b_count=1;
- bh->b_dirt=0;
- bh->b_uptodate=0;
- remove_from_queues(bh);
- bh->b_dev=dev;
- bh->b_blocknr=block;
- // 操作链表和hash表,并且重新计算了hash值。
- insert_into_queues(bh);
- return bh;
- }
这个方法愿成为最核心的方法,也比较的复杂,能懂这个方法就明白sys_write和sys_read基本都明白了。所以接下来的解释会特别的详细。
- 先通过设备号和块号使用hash定位到hash表中的缓存头
- 如果从hash表中没有找到。没找到的原因也很简单,高速缓存的总大小就这么大,所以缓存块和缓存头的数量有限,所以缓存头的映射会一直做改变,也就是动态迁移的,当被一个文件使用的到的时候就会链到HASH表中,下次就O1时间复杂度能找到这个缓存头。
- 而这里缓存头的数量有限,HASH表映射不到的情况下。所以linus设计的时候就设计了一个空闲链表(其实是把所有的缓存头给双向链表起来,但是时间复杂度比HASH表慢太多了,所以为了效率就出现了HASH来优化这个空闲链表),所以就会去free_list这个链表去找满意的缓存头(为什么要用满意来形容),可以具体看到这里的代码,这里BADNESS是一个权限算法,优先级是上锁的小于已经脏了的,对于的字段为b_lock和b_dirt两个字段。而tmp是空闲链表的下一个,bh是当前。如果权限算出来为0,那么就是又没上锁又没脏的缓存头就直接break;那么如果遍历完所有的空闲链表都没有找到一个权限算出来为0的呢,就会找出一个比较满意的。
do {
// 如果不为0就代表已经被其他人使用了。
if (tmp->b_count)
continue;
// bh是当前,tmp是下一个
// BADNESS(tmp)// 找到为0的就很满足的离开了。 但是也有可能遍历完全部也找不到...
if (!BADNESS(tmp))
break;
}
} while ((tmp = tmp->b_next_free) != free_list); -
当遍历完所有的空闲链表,都没有找到bh,注意是没有找到,并不是没有找到满意的,那么就会sleep_on先去休息(sleep_on的代码下面会细说,这个操作很骚)。然后再使用goto语句从头再来再来一次(因为休息一段时间,可能会变得美好)。
-
往下走就是找到了,注意这里可能是完美的,也可能是比较满意的,也可能是很差的(又脏又有锁),所以会使用wait_on_buffer()来判断是否已经上锁了,如果上锁了就会调用sleep_on去睡眠,等待锁的释放。思考一下,就算之前do/while获取到的是完美的bh,又没锁又不脏,其实走到这里一切皆有可能,因为当时是单核cpu,走分时复用的调度机制。所以一切皆有可能,如果上锁了就等呗。
-
如果没上锁就往下执行,如果上锁就等待释放锁,然后往下执行。如果当前的bh(缓存头)已经被别其他进程使用了就使用goto语句从头再来。
-
如果没被其他进程使用,那么就会去处理已经脏了的bh(缓存头)。通过sync_dev(bh->b_dev)方法将已经脏了的数据落盘。具体的落盘过程后续也会仔细讲解。当落盘出来以后,可能又被其他进程上锁了,或者已经被其他进程给占用了。上锁了就sleep_on等待锁的释放,如果被占用了就goto从头再来。
-
find_buffer()如果HASH表中能直接查出来了,那么就代表其他进程使用了同一个设备和块号并且已经执行完,把对应的bh放入到HASH表中了。我们就直接goto从头再来。而刚开始就是用过get_hash_table直接找HASH表,找到了就返回。
-
如果HASH表中没有,那么接下来就是成功获取到了,就是一些占坑的赋值操作,并且将bh做一个HASH映射,添加到HASH表中。并且bh链到free_list链表尾部。
-
此方法返回bh,然后就可以将本次写的数据写入到这个bh对应的缓存块中。
sync_dev的讲解
这是高速缓存写会磁盘的逻辑,也比较复杂。
- int sync_dev(int dev)
- {
- int i;
- struct buffer_head * bh;
- bh = start_buffer;
- for (i=0 ; iif (bh->b_dev != dev)continue;wait_on_buffer(bh);if (bh->b_dev == dev && bh->b_dirt)ll_rw_block(WRITE,bh);}sync_inodes();bh = start_buffer;for (i=0 ; iif (bh->b_dev != dev)continue;wait_on_buffer(bh);if (bh->b_dev == dev && bh->b_dirt)ll_rw_block(WRITE,bh);}return 0;}
这里遍历所有的缓存头,然后找到当前的这个bh缓存头。如果没有上锁就判断数据是不是脏的,如果是脏的就调用ll_rw_block方法落盘。
将ll_rw_block之前要注意这里是不是2个一模一样的for循环,是不是写的有问题?肯定是没问题的,因为落盘是异步的。所以第二个for循环是在等待落盘成功。
- void ll_rw_block(int rw, struct buffer_head * bh)
- {
- unsigned int major;
- // 这里找到当前设备对应的操作,在0.11内核中文件操作封装成了一个一个结构体,一个是当前请求的队列,一个是当前设备操作的方法,也就是函数指针。
- // 并且存在不同的设备,所以底层封装成了一个设备数组。所以major是得到当前设备对应的数组下标
- if ((major=MAJOR(bh->b_dev)) >= NR_BLK_DEV ||
- !(blk_dev[major].request_fn)) {
- printk("Trying to read nonexistent block-device\n\r");
- return;
- }
- // 将当前设备和bh封装成一个请求
- make_request(major,rw,bh);
- }
这里找到当前设备对应的操作,在0.11内核中文件操作封装成了一个结构体,结构体内部一个是当前请求的队列,一个是当前设备操作的方法,也就是函数指针。
并且存在多种的设备,所以底层封装成了一个设备数组。所以major是得到当前设备对应的数组下标。所以继续往make_request()方法看。
- static void make_request(int major,int rw, struct buffer_head * bh)
- {
- struct request * req;
- int rw_ahead;
- /* WRITEA/READA is special case - it is not really needed, so if the */
- /* buffer is locked, we just forget about it, else it's a normal read */
- // 把预读和预写转换成读写,如果没有就不走这块
- if (rw_ahead = (rw == READA || rw == WRITEA)) {
- // 被锁了直接溜了
- if (bh->b_lock)
- return;
- if (rw == READA)
- rw = READ;
- else
- rw = WRITE;
- }
- // 不是读,不是写,那是怪物?
- if (rw!=READ && rw!=WRITE)
- panic("Bad block dev command, must be R/W/RA/WA");
- // 先看已经被上锁没,被上锁了就等待释放锁,再获取锁。
- // 准备动手,先上锁。不上锁的话,等等一边写高速缓存,一边高速缓存落盘磁盘,那就G了
- lock_buffer(bh);
- // 如果在等待的过程中,别的进程已经把缓存区的资源落盘了,或者已经把读的数据读完了,那不贼爽,我啥都不同干了。
- if ((rw == WRITE && !bh->b_dirt) || (rw == READ && bh->b_uptodate)) {
- // 进到这里表示,读写的任务被别人干完了,我只需要把我当前上的锁给释放就行。
- // 释放当前缓存头的锁,并且将当前缓存头中等待队列唤醒。
- unlock_buffer(bh);
- return;
- }
- repeat:
- /* we don't allow the write-requests to fill up the queue completely:
- * we want some room for reads: they take precedence. The last third
- * of the requests are only for reads.
- */
- // 走到这里表示锁还没释放,所以这边就是处理请求的具体逻辑
- // 如果是读 就获取到请求数组的最后一位地址
- if (rw == READ)
- // 获取到请求数组的最后一位元素的地址。
- req = request+NR_REQUEST;
- // 如果是写就获取到接近2/3的位置。因为要预留一小块位置给读。因为读牛逼...
- else
- req = request+((NR_REQUEST*2)/3);
- /* find an empty request */
- // 从读或者写的最后一位开始遍历。 直到找到空闲的。
- while (--req >= request)
- // dev为-1代表没被使用.
- if (req->dev<0)
- break;
- /* if none found, sleep on new requests: check for rw_ahead */
- // 如果找到了就代表req不为首地址
- // 如果没有找到就代表req为首地址 - 一个request结构体的地址。
- // 所以这里是没有找到。
- if (req < request) {
- // 如果是预读并且存在锁就直接溜了。
- if (rw_ahead) {
- // 释放锁,并且唤醒被睡眠的进程,让他们醒来判断锁。
- unlock_buffer(bh);
- return;
- }
- // 因为在request数组中没找到空闲的 先休息一下,然后从头再来。
- sleep_on(&wait_for_request);
- goto repeat;
- }
- // 走到这里代表找到了,然后占坑。
- /* fill up the request-info, and add it to the queue */
- req->dev = bh->b_dev;
- req->cmd = rw;
- req->errors=0;
- req->sector = bh->b_blocknr<<1;
- req->nr_sectors = 2;
- req->buffer = bh->b_data;
- req->waiting = NULL;
- req->bh = bh;
- req->next = NULL;
- // 添加到请求队列中,并且处理的逻辑。
- add_request(major+blk_dev,req);
- }
- 这里首先处理是不是预读和预写,如果是的话转换成读写。预读和预写在以后的sys_read会讲术。
- 然后给当前的bh上锁,准备写入,首先先判断当前的bh是不是已经被其他进程写完了,如果写完了就直接释放锁,然后返回。
- 如果别的进程没有写完,那么就从全局维护的request请求队列中找到一个空闲的请求,当request结构体的dev字段为-1就是空闲(在初始化过程中会把dev设置为-1,具体位置就不细追了)。并且这里是请求队列从后往前遍历,写只能从2/3的位置遍历。而读直接从最后开始,所以也就是充分表明了读优先。
- 如果遍历全局的请求队列找到了空闲的请求,那么就占坑,然后执行add_request(major+blk_dev,req); 如果没有找到,就睡眠,醒来再试,如果是预读预写的话直接释放锁然后返回,所以也能说明预读预写不能受阻塞的影响。
看add_request之前,我们先明白,此方法的参数。

blk_dev是0.11内核执行的设备数组,而major是之前通过当前设备获取到的设备数组的下标。所以这里是获取到具体的blk_dev_struct,也就是每个设备对应不同的处理函数,然后维护了一个请求队列。封装成一个blk_dev_struct结构体。所以这里就是获取到当前设备对应的请求队列和具体处理函数。
- static void add_request(struct blk_dev_struct * dev, struct request * req)
- {
- struct request * tmp;
- req->next = NULL;
- // 上锁,也就是关闭中断
- cli();
- if (req->bh)
- // 把当前请求的缓存头设置为不脏了,因为马上要被做掉了。
- req->bh->b_dirt = 0;
- // 如果当前处理硬盘 中没有请求就把当前的请求给他处理。
- if (!(tmp = dev->current_request)) {
- // 赋值请求.
- dev->current_request = req;
- // 释放锁
- sti();
- // 处理函数指针。所以真真的处理逻辑就在这里.
- (dev->request_fn)();
- return;
- }
- // 能到这里来就说明,当前dev设备,比如硬盘已经有请求了。
- // 因为request请求是一个单链表。
- // 做比较。
- // 第一次tmp是当前正常处理的请求,之后tmp是当前正在处理请求链表的下一个, req是当前进来的请求.
- // 目的是为了找到链表的插入位置。
- for ( ; tmp->next ; tmp=tmp->next)
- if ((IN_ORDER(tmp,req) ||
- !IN_ORDER(tmp,tmp->next)) &&
- IN_ORDER(req,tmp->next))
- break;
- // 添加到链表尾部的操作。
- req->next=tmp->next;
- tmp->next=req;
- sti();
- }
到这里就最底层了,再往下走就是CPU和硬盘的交互了.... 实在不容易....
这里并不复杂,就是判断当前设备的请求队列中是否有请求,如果没有,那么就当前进程进程干活,也就是调用request_fn函数指针,具体的回调要看初始化过程中往里面填写的函数。
而别的进程进来如果当前设备的请求队列中已经存在请求,那么就会把当前请求通过一系列的order排序,最终添加到当前设备的请求队列中(并不是尾部,具体位置要看order的排序算法)
所以接下来就刘看request_fn函数指针具体的实现,我们找到hd硬盘的。
- // 会在main方法中调用此方法。
- // 硬盘初始化
- void hd_init(void)
- {
- // 把请求队列给初始化。 对于硬盘来说是下标为3的,也就是第4个元素。
- blk_dev[MAJOR_NR].request_fn = DEVICE_REQUEST;
- // 硬盘中断的idt表的添加,中断处理函数的添加。
- set_intr_gate(0x2E,&hd_interrupt);
- // out指令 CPU通过端口传输数据给其他硬件(数据可能是控制指令、也可能是数据...)
- outb_p(inb_p(0x21)&0xfb,0x21);
- outb(inb_p(0xA1)&0xbf,0xA1);
- }
设置硬盘的处理函数
设置硬件中断——硬盘中断的idt表项,也就是设置硬盘中断的中断处理函数。
而out指令,我们看到intel开发手册中的解释把。

#define DEVICE_REQUEST do_hd_request,所以我们看到do_hd_request。
- // 硬盘的request_fn函数指针的回调地址。
- void do_hd_request(void)
- {
- int i,r;
- unsigned int block,dev;
- unsigned int sec,head,cyl;
- unsigned int nsect;
- INIT_REQUEST;
- // 获取到request结构体中的dev设备.
- dev = MINOR(CURRENT->dev);
- // 获取到request结构体中block块设备
- block = CURRENT->sector;
- if (dev >= 5*NR_HD || block+2 > hd[dev].nr_sects) {
- end_request(0);
- goto repeat;
- }
- block += hd[dev].start_sect;
- dev /= 5;
- __asm__("divl %4":"=a" (block),"=d" (sec):"0" (block),"1" (0),
- "r" (hd_info[dev].sect));
- __asm__("divl %4":"=a" (cyl),"=d" (head):"0" (block),"1" (0),
- "r" (hd_info[dev].head));
- sec++;
- nsect = CURRENT->nr_sectors;
- if (reset) {
- reset = 0;
- recalibrate = 1;
- reset_hd(CURRENT_DEV);
- return;
- }
- if (recalibrate) {
- recalibrate = 0;
- hd_out(dev,hd_info[CURRENT_DEV].sect,0,0,0,
- WIN_RESTORE,&recal_intr);
- return;
- }
- if (CURRENT->cmd == WRITE) {
- hd_out(dev,nsect,sec,head,cyl,WIN_WRITE,&write_intr);
- for(i=0 ; i<3000 && !(r=inb_p(HD_STATUS)&DRQ_STAT) ; i++)
- /* nothing */ ;
- if (!r) {
- bad_rw_intr();
- goto repeat;
- }
- port_write(HD_DATA,CURRENT->buffer,256);
- } else if (CURRENT->cmd == READ) {
- hd_out(dev,nsect,sec,head,cyl,WIN_READ,&read_intr);
- } else
- panic("unknown hd-command");
- }
对于这里的操作,不过细讲(因为我也没仔细看,因为都是文件系统对于硬盘中的扇区的定位之类的操作,其实对于我们学习来说已经不重要了)。重点看到最后一个if判断。这里的current就是当前的请求,cmd就是请求类型。而对于我们sys_write来说,肯定是看write的处理。所以看到hd_out()函数
- static void hd_out(unsigned int drive,unsigned int nsect,unsigned int sect,
- unsigned int head,unsigned int cyl,unsigned int cmd,
- void (*intr_addr)(void))
- {
- register int port asm("dx");
- if (drive>1 || head>15)
- panic("Trying to write bad sector");
- if (!controller_ready())
- panic("HD controller not ready");
- do_hd = intr_addr;
- outb_p(hd_info[drive].ctl,HD_CMD);
- port=HD_DATA;
- outb_p(hd_info[drive].wpcom>>2,++port);
- outb_p(nsect,++port);
- outb_p(sect,++port);
- outb_p(cyl,++port);
- outb_p(cyl>>8,++port);
- outb_p(0xA0|(drive<<4)|head,++port);
- outb(cmd,++port);
- }
这里注意把intr_addr函数指针赋值给do_hd。而intr_addr函数指针的原型是write_intr。后续发生硬盘中断后会回调write_intr方法。
上面已经介绍过out指令了,所以这里可以理解为把数据通过CPU,和硬盘指定的io端口进行交互,也就是把这些数据发送给硬盘中,那么,硬盘不是存储数据的么?怎么还能接收数据,我的理解是硬盘内部可能也有控制单元、存储单元(临时储存的,比如寄存器)、数据存储单元、缓存等等.....
所以这里就是CPU与硬盘做交互,然后就把内存中的高速缓存的数据写会到硬盘中.
并且在hd_init初始化方法中对idt表做了硬盘中断的设置。所以这个中断的回调机制是什么时候呢?也就是硬盘把数据写完了,或者是中途发生了错误,硬盘就会往CPU发送一个硬盘的硬件中断,所以,我们看到中断处理函数hd_interrupt.
- _hd_interrupt:
- pushl %eax
- pushl %ecx
- pushl %edx
- push %ds
- push %es
- push %fs
- movl $0x10,%eax
- mov %ax,%ds
- mov %ax,%es
- movl $0x17,%eax
- mov %ax,%fs
- movb $0x20,%al
- outb %al,$0xA0 # EOI to interrupt controller #1
- jmp 1f # give port chance to breathe
- 1: jmp 1f
- 1: xorl %edx,%edx
- xchgl _do_hd,%edx # 把do_hd和edx寄存器的值互换。
- testl %edx,%edx
- jne 1f
- movl $_unexpected_hd_interrupt,%edx
- 1: outb %al,$0x20
- call *%edx # "interesting" way of handling intr. 调用edx寄存器的值。
- pop %fs
- pop %es
- pop %ds
- popl %edx
- popl %ecx
- popl %eax
- iret
看到这两行就行,其他的不是我们的重要核型。
xchgl _do_hd,%edx // 把do_hd和eax的值互换,而do_hd之前方法中进行了赋值,所以直接看到write_intr函数。
call *%edx // call调用edx寄存器的值。
- static void write_intr(void)
- {
- if (win_result()) {
- bad_rw_intr();
- do_hd_request();
- return;
- }
- if (--CURRENT->nr_sectors) {
- CURRENT->sector++;
- CURRENT->buffer += 512;
- do_hd = &write_intr;
- port_write(HD_DATA,CURRENT->buffer,256);
- return;
- }
- end_request(1);
- do_hd_request();
- }
这里不做多的解释了, 只能说这里会继续遍历下一个读写请求。并且会使用所有被sleep_on等待的进程。
并且这里要思考,之前的进程是在同步等待高速缓存区数据落盘,而CPU和磁盘是异步交互。所以这个中断是其他进程触发的。所以也就是其他进程触发了硬盘中断,并且在这里唤醒了同步等待高速缓存区数据落盘的进程,以及其他在sleep_on中等待的进程。并且这里还执行了队列中下一个请求。因为请求又是CPU和磁盘异步的,所以这个中断就返回。然后CPU是分时复用的,所以又可能是下一个进程来处理硬盘中断。周而复始,如果下图。

wait_on_buffer的讲解
- static inline void wait_on_buffer(struct buffer_head * bh)
- {
- cli();
- while (bh->b_lock)
- sleep_on(&bh->b_wait);
- sti();
- }
cli和sti是关闭中断响应,就是保证了原子性,以后的文章会详细说明.
这里就是判断当前bh是不是上锁了,如果上锁了就调用sleep_on睡眠等待。
- void sleep_on(struct task_struct **p)
- {
- struct task_struct *tmp;
- if (!p)
- return;
- if (current == &(init_task.task))
- panic("task[0] trying to sleep");
- tmp = *p;
- *p = current;
- current->state = TASK_UNINTERRUPTIBLE;
- // 切换任务。
- schedule();
- if (tmp)
- tmp->state=0;
- }
这里比较复杂,很合理的来说就是跨进程的一个栈队列。
因为**p是一个二级指针。每次*p = current;都是把当前进程的信息给*p。所以下次调用sleep_on的方法的参数就是上一个current进程。并且这里的schedule方法会发生上下文切换,去让CPU执行其他方法。
我们回想一下硬件中断处理函数中, 虽然笔者没有详细的说明此方法。但是笔者有说过,会唤醒所有在sleep_on中的进程。而这里是一个队列。所以就是中断唤醒A,A唤醒B,B唤醒C。而这个队列是对于一个bh缓存头而言。当然在内核源码中这样的队列很多。
总结:
sys_write和sys_read两个系统调用算是很复杂的系统调用了。笔者也是已经尽了最大的努力。因为每个人的理解是有偏差,并且笔者的写作能力也有限。所以有哪里不懂的可以私聊笔者。笔者很欢迎跟大家一起学习内核。
最后,如果本帖对您有一定的帮助,希望能点赞+关注+收藏!您的支持是给我最大的动力,后续会一直更新各种框架的使用和框架的源码解读~!
-
相关阅读:
Lattice SII9136CTU-3 HDMI1.4 视频音频接口芯片
【漏洞分析】Li.Fi攻击事件分析:缺乏关键参数检查的钻石协议
Jenkins学习笔记
【论文翻译】使用变更数据捕获方法通过提取-转换-加载过程实时更新数据仓库
C/C++面试高频知识点八股文
C3P0连接池+MySQL的配置以及wait_timeout问题的解决
<C++>类和对象——引入
安卓Activity生命周期
基于多目标灰狼算法的冷热电联供型微网低碳经济调度(Matlab代码实现)
是不是所有的低代码产品都能解决真实问题
- 原文地址:https://blog.csdn.net/qq_43799161/article/details/125987358
 https://blog.csdn.net/qq_43799161/article/details/125905326?spm=1001.2014.3001.5501
https://blog.csdn.net/qq_43799161/article/details/125905326?spm=1001.2014.3001.5501