-
AIOps指标异常检测之无监督算法
随着系统规模的变大、复杂度的提高、监控覆盖的完善,监控数据量越来越大,运维人员无法从海量监控数据中发现质量问题。智能化的异常检测就是要通过AI算法,自动、实时、准确地从监控数据中发现异常,为后续的诊断、自愈提供基础。
异常检测算法分类
大量应用场景对快速有效检测异常的需求以及异常检测场景相较于其他场景的特殊性,使得异常检测问题的研究具有极大的应用和研究价值,促使很多异常检测算法被提出和实践.智能化的异常检测算法主要分为三大类,基于统计的异常检测算法、无监督异常检测算法和有监督异常检测算法.下面对三种检测算法作简要介绍和对比分析。
一、基于统计的异常检测算法
基于统计的异常检测算法, 利用统计学思想, 通过对历史数据计算统计特征, 然后判断待检测的数据是否符合历史数据的统计特征, 如果是则认为是正常, 如果不是则认为是异常。
常用的基于统计的异常检测算法有3-sigma, 四分位数, 同比, 环比等等。
基于统计的异常检测算法的特点是简单易用, 可解释性强, 但无法处理复杂的场景。
二、无监督异常检测算法
无监督异常检测算法,通过对数据进行计算分析, 识别出那些相对孤立的点, 把这些孤立点就看作为异常点。由于无监督异常检测算法的应用场景往往只需要得到异常的排名,认为最为异常的一部分数据是异常数据,所以其输出结果大多是样本点对应的异常分数,异常分数对应到样本点的异常程度。在所有无监督异常检测方法中,基于样本点之间的距离或者样本点所在的密度来判别样本是否为异常,是无监督异常检测常用的经典方法。
常用的无监督异常检测算法有孤立森林, LOF, One-Class-SVM等等。
无监督异常检测算法的特点是无需打标数据, 在特征选取合理情况下准确性高, 能处理大规模复杂场景等, 但也存在特征选取难, 可解释性差等问题。
三、有监督异常检测算法
对于有监督异常检测,首先需要一大批带有标签的数据作为训练数据, 将训练数据作为有监督算法的输入, 对算法模型进行训练后得到模型, 然后将待检测的数据作为模型的输入, 最终模型给出待检测是正常还是异常类别。
常用的有监督异常检测算法有SVM, ANN, 决策树, CNN, RNN等等。
通过有监督学习方法,在实验数据中可以得到比较好的异常分类效果。但是在实际异常检测过程中,异常数据往往是少量的,多变的,并且之前可能没有出现过,所以要获得足量准确、适用于有监督算法的数据是很困难的。因此,有监督异常检测不适用于大规模指标异常检测的落地。
下表是三种类别算法从几个维度对比结果:
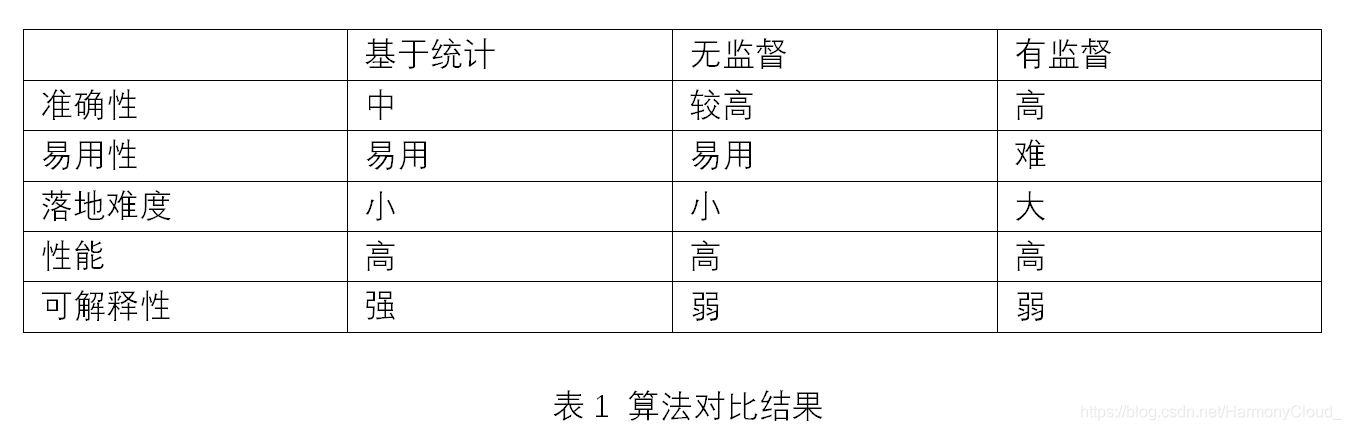
通过上面对三种异常检测的对比分析,可以看出无监督检测算法在能保证较高准确性的同时,在易用性和落地难度上有较大优势。因此在工程实践中,无监督异常检测算法运用的比较多。下面就重点介绍一下运维领域无监督算法在异常检测中的应用情况。
无监督异常检测算法
在各类异常检测应用场景中,由于本身数据量巨大,同时数据量随时间快速增长,因此往往无法给新增数据打上足量且准确的异常或者正常标签, 所以有监督异常检测算法难以胜任。而基于统计的异常检测算法准确率有限, 无法满足一些复杂的场景, 因此在大规模异常检测中表现也不尽人意. 综合起来, 无监督异常检测算法无疑是最适合大规模异常检测的落地和实践。
无监督异常检测的数据量往往是较大的。无监督异常检测算法不要求训练数据具有类别标签,这意味着与有标签数据相比,同样数量的无标签数据所提供的信息更少,因此无监督算法需加入更多的训练数据进行训练。同时由于大数据场景下,数据量的快速增长给训练算法提供了足够大的数据量,使得依靠数据量保证模型准确性的无监督异常检测算法能够顺利运行。
无监督异常检测算法另外一个难点就是如何提取和选取数据特征, 因为无监督算法往往处理的是多维数据, 通过对数据多个维度的特征进行综合判断, 最终确定数据的异常与否.。
常用的无监督异常检测算法有孤立森林, LOF, One-Class-SVM等等。
实验
1. 实验数据
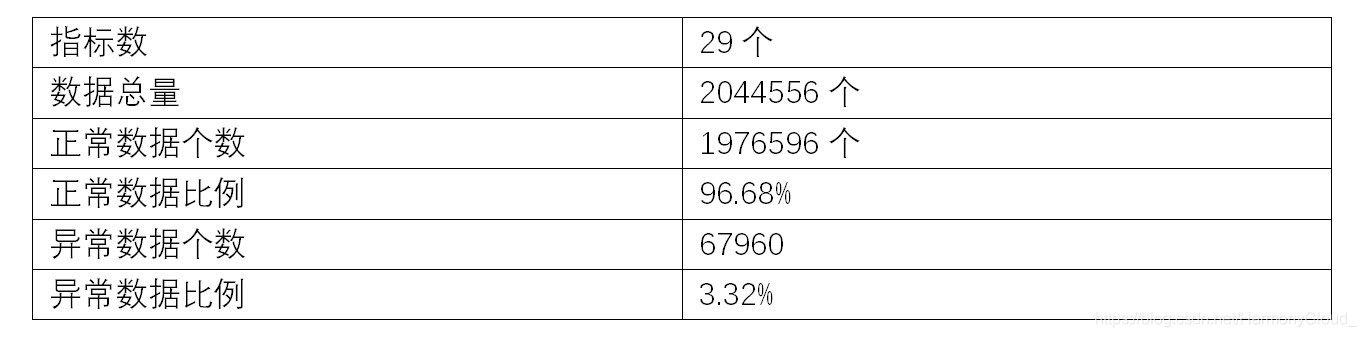
因为需要最终通过统计误报率和漏报率等指标来衡量算法的优劣,所以必须要用打标数据,因此本次实验选用清华打标数据,数据包括29个指标,每个指标3个月的数据.数据介绍见下表:
2. 数据特征选择
无监督算法一般是对多维数据进行处理, 因此需要对原来单维的数据进行特征提取, 使其成为多维数据。
-
特征提取方案一
参考腾讯异常检测框架Metis中选用的数据特征, 最大值, 最小值, 值域, 均值, 中位数, 方差, 偏度, 峰度, 同比, 环比, 周期性 自相关系数, 变异系数, 移动平均算法, 带权重的移动平均算法, 指数移动平均算法, 二次指数移动平均算法, 三次指数移动平均算法, 奇异值分解算法, 自回归算法, 深度学习算法, 熵特征, 值分布特征这些特征作为数据的特征, 其在无监督的孤立森林算法的表现为: 从误报率和漏报率可以看出,效果并不好,查找资源发现,孤立森林, LOF等无监督算法不适合处理太多纬度的数据, 该特征集特征太多,最终导致算法效果不理想。
从误报率和漏报率可以看出,效果并不好,查找资源发现,孤立森林, LOF等无监督算法不适合处理太多纬度的数据, 该特征集特征太多,最终导致算法效果不理想。 -
特征提取方案二
论文《云环境中时序数据的预测和异常检测算法的研究_王超》中提到过,在对时序数据进行预测时, 也采用了无监督算法, 其选用的特征为:当前值, 前一个值, 前两个值, 前五个值的均值, 前一天同时刻前后5个值均值,前5天同时刻均值, 故该方案参考上面的特征提取方法, 在无监督的孤立森林算法的表现为:

从误报率和漏报率可以看出,效果也不是很理想, 分析原因是大部分无监督算法都建立在计算数据点之间的距离之上, 如果直接使用上述的特征, 数据与数据直接的距离并没有实际的意义, 因此该数据特征集也不是很合适。 -
特征提取方案三
论文《云环境中时序数据的预测和异常检测算法的研究_王超》中提到的数据特征集的个数和意义其实比较合适, 只是数据点之间的距离没有实际意义, 因此对特征集进行重定义:当前值, 前一个值与当前值的差值, 前两个值与当前值的差值, 前五个值的均值与当前值的差值, 前一天同时刻前后5个值均值与当前值的差值,前5天同时刻均值与当前值的差值, 在无监督的孤立森林算法的表现为:

特征提取方案三最终的效果能满足要求,因此本次实验最终选用特征提取方案三中的特征作为最终的数据特征。
3. 算法实验
本次实验分别对孤立森林算法, LOF算法, One-Class-SVM算法三种算法进行了实验. 将数据分为两部分, 前15天的数据作为训练数据, 后15天的数据作为测试数据, 并对测试数据的检测结果进行统计分析, 得出漏报率和误报率等指标。
-
孤立森林算法
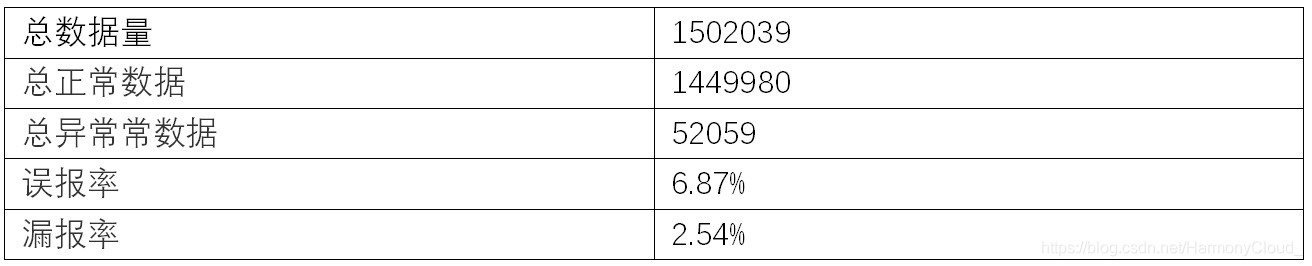
孤立森林是在训练数据集上训练出一定数据的决策树,这些决策树是能将特定数据集分割成一个个数据点,对待检测的点,如果能在较短的路径下找到类别,就认为该点是异常点,算法介绍可参考https://www.jianshu.com/p/d9fb673301a3。Sklearn中对孤立森林进行了实现和封装,但是在模型构建时,必须指定异常数据的比例,检测结果异常的比例就和模型构建时提供的比例相同,这在实际使用过程中不太合理,因此对Sklearn中对孤立森林进行了改进和重新实现将异常数据的比例参数去掉,最终将算法运行在特征数据集上。孤立森林的效果如下:
-
LOF算法
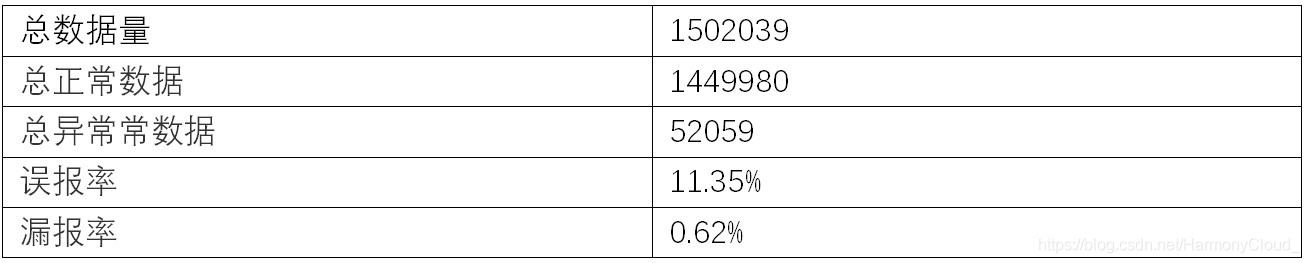
LOF算法是典型的基于密度的无监督异常检测算法, 其认为待检测点在一点范围内数据点密度太小就为是异常,介绍可参考:https://blog.csdn.net/wangyibo0201/article/details/51705966。Sklearn中对LOF也进行了实现和封装, 因此本次实验直接调用sklearn的包(sklearn.neighbors.LocalOutlierFactor)运行LOF算法。LOF算法效果如下:
-
One-Class-SVM算法
One-Class-SVM算法是利用训练数据, 得出超平面, 该超平面能将数据集分为异常面和正常面, 然后判断待检测数据处于那个面上, 算法介绍可参考:https://blog.csdn.net/a1154761720/article/details/50708398。Sklearn中对One-Class-SVM也进行了实现和封装, 因此本次实验直接调用sklearn的包(sklearn.svm.OneClassSVM)运行One-Class-SVM算法。One-Class-SVM算法效果如下:
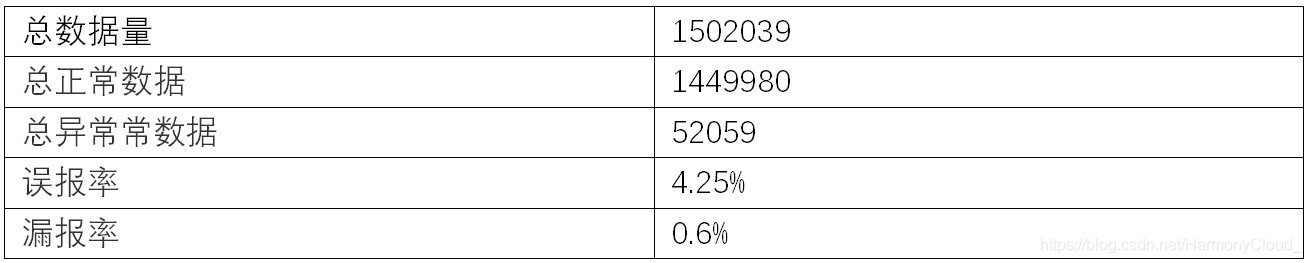
4. 无监督算法优化
从以上三个实验结果可以看出, 三个算法的效果都表现一般, 是因为每种算法擅长处理的场景和特征都不同, 如果能将这些算法柔和起来, 可能效果会跟好, 因此本次实验对无监督算法进行了改进。
改进办法是分别用三种算法对同一个待检测点进行检测, 然后通过投票的方式最终确定待检测点是正常还是异常。其投票方式是两个以上判断为异常就为异常, 两个以上判断为正常就为正常。
算法效果如下:
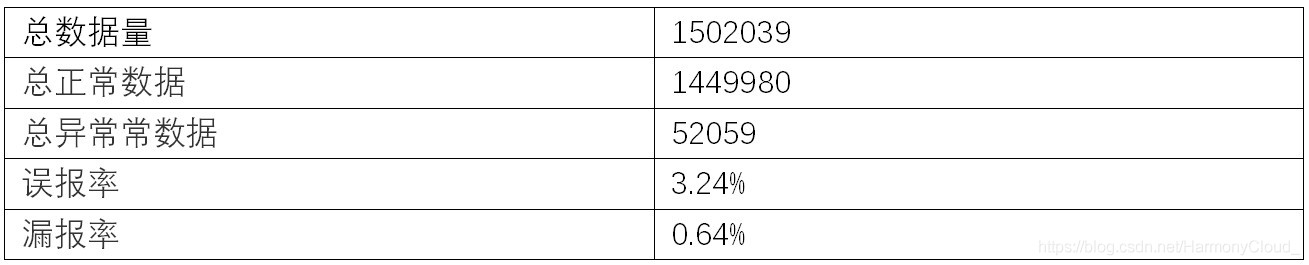
5.基于统计异常检测与无监督异常检测结果对比
因为有监督异常检测无法大规模落地和实践, 本次实验就不进行对比分析了. 因此重点对无监督异常检测确实和基于统计异常检测进行对比分析。

总的来说,无监督异常检测算法在漏报和误报上都比基于统计异常检测表现优秀, 尤其是误报率有大幅的领先. 证明无监督异常检测确实比基于统计异常检测更加准确有效。 -
-
相关阅读:
1964springboot VUE小程序在线学习管理系统开发mysql数据库uniapp开发java编程计算机网页源码maven项目
小程序技术在信创操作系统中的应用趋势:适配能力有哪些?
Java 中的异常和处理详解
Linux下编译libevent源码
设计模式与应用:组合模式
抖音SEO源码
原址删除有序数组重复整数
javascript中的数组设计方法
ShardingSphere笔记(一): 经验和踩坑总结
cesium实现水面水流及淹没效果绘制的封装
- 原文地址:https://blog.csdn.net/HarmonyCloud_/article/details/125999227