-
ShardingSphere笔记(一): 经验和踩坑总结
ShardingSphere笔记(一): 使用经验总结
这篇文章里面只简单总结一些使用ShardingSphere的个人经验,具体的技术实现可以看后面的文章。
先叠个甲,这里面提到的一些解决方案是针对我们的项目总结出来的,可能并不适用于所有情况,算是一个思路。具体场景还需要具体分析。如果各位大佬有更好的解决方案欢迎讨论。
一、背景
公司之前的项目中,所有的历史数据都是使用单表进行存储的,随着历史数据越积越多,有的历史数据表中的数据已经到了上亿条数据,数据的查询就成了一个很大的问题。
以往的时候,除了历史数据查询操作历史数据表的情形比较少,很多数据的查询走的都是抽样表和近期表。但是随着功能的不断扩展,需要从历史数据中分析更多的东西,这时候分库分表就是一个很迫切的需求了。
框架选择
当时我们有两种选择,一个是 mycat、一个就是shardingsphere。
mycat是代理数据库访问,可以看成是一个数据库代理。
而shardingsphere提供了两个项目,一个shardingsphere-jdbc, 一个是shardingsphere-proxy。看名字就能看出来一个是提供jdbc驱动类的jdbc增强库。另一个就是类似于 mycat 的数据库代理了。经过查询一些资料我更倾向于shardingsphere-jdbc来做数据库分表。原因如下:
- 我们的项目不是类似于互联网那种提供云服务的项目,而是需要打包卖给很多客户的。考虑到部署与维护,架构需要尽量减少维护环节。
- shardingsphere 也提供了代理端的项目,如果使用 shardingsphere 来做,将来想要切换到代理数据库的实现方式切换成本也会比较小。
- shardingsphere 作为 Apache的顶级项目,框架稳定性方面会更信任一些。
- Mycat官网的文档真的欣赏不来,反而shardingsphere管网的文档很漂亮。
二、ShardingSphere-jdbc 只是一个帮助你路由的框架(踩坑总结)
这是我在使用和封装框架的过程中一个坑一个坑总结到的最深刻的经验。那就是ShardingShpere没有我们想象的那么智能,在数据分片中,它只是负责帮你去路由。
在这里我们需要先理解ShardingSphere是怎么来做路由的。他通过代理 jdbc,在sql查询的时候通过解析sql,找到你想要查询的表。然后根据你配置数据库表的分片算法根据对应的列找到应该从哪些数据库、哪些数据表中查询数据。
所以这是为什么它会存在很多限制:
- 存储过程不支持。(存储过程可以理解成在数据库端存储的封装好的函数,鬼才能从函数名解析到你想要查那个数据库呢,就算解析到了也改不了你的存储过程内容)
- 分片列的函数,对分片列的函数同样无法应用分片算法。
- 查询需要待分片列,如果不带分片列就没办法走分片算法,那么就会出现全表查询,所有表都要过一遍,尤其当存在join的时候,甚至存在笛卡尔积的查询次数。效率极差。
这还意味着:
1. 它默认会认为你配置的所有的节点都是存在的
就像上面说的,框架没有那么智能,它会认为你既然都让我路由了,那你所有的表都应该存在才是。所以忽略了这个情况就可能会出现一些莫名其妙的问题。以我踩过的坑为例。
我们是需要按月分表的,而按月分表我们又不想一次性建好那么多表,要不然数据库突然多了那么多空的数据表,管理也很麻烦。
所以来看看大聪明是怎么想办法解决这个问题的呢?
spring: shardingsphere: datasource: # .... rules: sharding: tables: # 需要分片的数据库表 test_data: # 大聪明觉得我一次性配置了200年的表规则,就可以一次性配置一劳永逸了吧,哈哈 actual-data-nodes: ${['ds1', 'ds2']}.test_data_${2018..2200}0${1..9}, ${['ds1', 'ds2']}.test_data_${2018..2200}0${10..12} table-strategy: # ....- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
这里,一次性配置了200年的数据表规则,但是数据库里面其实没有这么多的表。测试运行没问题。但是现实非常露骨,不仅露骨还会用骨头啪啪打脸。不出所料报错了。空指针异常。
在 Shardingsphere 5.2 版本以上是 ShardingSphereSchema.getColumns 空指针

在5.1 版本之前报错信息时 TableMetaData.getColumns 空指针

为什么会出现这个异常?查了官方的Issure,官方的回复统一都是检查一下 actual-data-nodes然后关闭了Issue, 所以后来在确保所有的真实表都存在之后这个问题才没有。
出现这个问题的原因就是:Shardingsphere默认认为你的真实表都应该是存在的,而且它不确定逻辑板是否存在,而且正常情况下逻辑表都是不存在的,在项目启动的时候它会去刷新Metadata,就是表的描述信息,但是因为大聪明为了一劳永逸配置了不存在的表,导致框架读取不到表信息。
2. 利用分表算法做动态数据库是不太现实的
这里又是一个踩的坑,我们的项目是这样的,有很多的数据源,每一个数据源中的历史数据表是需要分表的。我就想,我岂不是可以利用分片算法来切数据库吗?
于是我就有了下面的实现,我写了一个 数据库的分片算法,这里不做任何逻辑,利用 ThreadLocal 来确定使用哪一个数据库。
/** * 动态数据库的分库算法 * * @author wangp */ public class DynamicDataSourceShardingAlgorithm implements StandardShardingAlgorithm<String> { /** * 需要手动指定数据库, 因此这里使用 ThreadLocal 来记录当前的数据库 */ private static final ThreadLocal<String> currentDataSource = new TransmittableThreadLocal<>(); private Properties properties; @Override public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<String> shardingValue) { String dataSource = currentDataSource.get(); if (dataSource == null) { throw new IllegalStateException("Illegal data source !!!"); } for (String availableTargetName : availableTargetNames) { if (Objects.equals(availableTargetName, dataSource)) { return dataSource; } } throw new IllegalStateException("Un knows data source :" + dataSource); } @Override public Collection<String> doSharding(Collection<String> availableTargetNames, RangeShardingValue<String> shardingValue) { return Collections.singletonList(doSharding(availableTargetNames, (PreciseShardingValue) null)); } @Override public String getType() { return "DATASOURCE_SPI_BASED"; } public static void setCurrentDataSource(String dataSource) { currentDataSource.set(dataSource); } public static String getCurrentDataSource() { return currentDataSource.get(); } @Override public Properties getProps() { return properties; } @Override public void init(Properties properties) { this.properties = properties; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
spring: shardingsphere: rules: sharding: default-database-strategy: standard: sharding-algorithm-name: dynamic_ds_sharding sharding-column: acquisition_time sharding-algorithms: his_month_sharding: type: HIS_DATA_SPI_BASED dynamic_ds_sharding: type: DATASOURCE_SPI_BASED- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
然后想要使用哪一个数据库,就手动调用 DynamicDataSourceShardingAlgorithm.setCurrentDataSource(‘ds1’) 就可以切换到数据源ds1。诶嘿。

经过测试确实可以却换不同的数据源,但是很明显,大聪明又踩坑里面了。
分表的数据表通过这种方式没有问题,因为分表的数据查询肯定会走这个分表算法,那单表呢?。单表不走这个算法,那说明它失效了。结果显示单表只走了一个数据库,这和我们的初衷是不一致的。这就要提到shardignsphere的另一个默认的规则了。那就是 ShardingSphere是一个做分库+分表的框架,而不仅仅是做分表的框架,它会认为你配置给分表配置的数据源对他们来说都是生效的,而没有配置的分表,抱歉我们单表我们为什么要走路由逻辑?与路由理念不一致
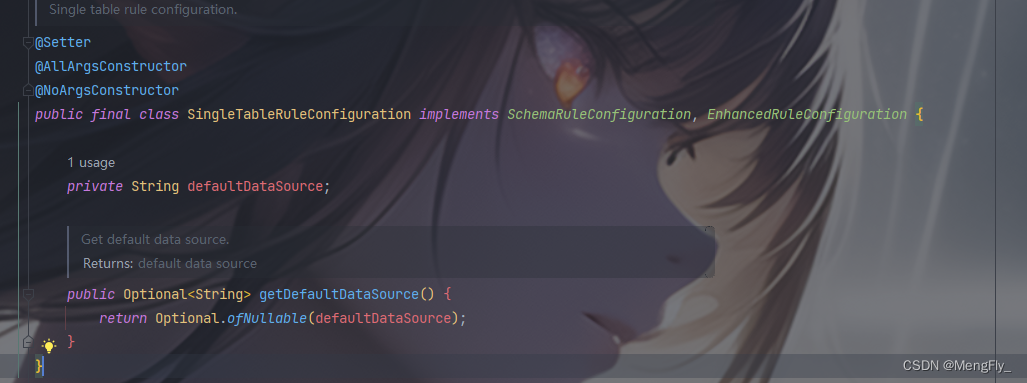
没办法研究它的文档和源码吧,结果研究了一圈没看到单表如何做路由,很明显在做无用功。因为单表配置 SingleTableRuleConfiguration 是一个final类,而且只有一个setDefaultDataSouce和getDefaultDataSource 方法,不允许你扩展也不允许你设置多路由。
所以最后放弃了这种做法,采用 SpringBoot 的 AbstractRoutingDataSource + ShardingSphere实现的动态数据源与数据库分表, 后面发现这种方式实现还有一种好处,众所周知,SardingSphere 不支持很多sql原生语句,那么在创建动态数据源的时候把原生的数据源和SharingSphere数据源一块加进去,想用哪一个用哪一个,丝般顺滑
更重要的是,利用这种方式还可以解决一个痛点,按月分表需要动态创建表,利用原生JDBC的datasource就很容易做到。而ShardingSphere的数据源却没有办法做到
这里提另一坑,官方给了一个强制路由的工具类,HintManager,可以设置走哪一个数据源,但是,强制路由,顾名思义,强制走路由,也就意味着使用了它你的分片算法就会失效,所以谨慎使用。
3. 查询语句不能使用关键字
封装完成框架,满心欢喜的运用到项目中,又又又报错了。熟悉的NullPointerException,心中一万只草泥马飘过 ~~~~~~~~~

经过追报错源码,原来是字段不能有关键字,因为Sharedingsphere 是基于sql解析来做路由的,所以对关键字要求比较高。
至于为什么要说这个坑,是因为使用mybatis框架的时候,报了这个错误他只提示你NPL异常,把报错信息给吞了,追了大半天报错堆栈才在原始的报错位置没有被传递出去的报错信息。no viable alternative at input sql, 最终报错到控制台的却是可怜的 Caused by: org.apache.shardingsphere.sql.parser.exception.SQLParsingException: null,不追代码鬼能知道是因为关键字的原因。4. 其他小坑
1. Compatible version of org.apache.shardingsphere.infra.util.yaml.constructor.ShardingSphereYamlConstructor$1
5.2 版本及以上会出现这个问题,因为需要的解析yaml文件的库版本不满足框架要求,pom文件中的 properties位置 调整yaml版本号即可(Springboot框架自带了这个框架,不需要重新引用)。
<properties> <snakeyaml.version>1.33snakeyaml.version> properties>- 1
- 2
- 3
三、 封装框架
根据我们的业务特性,我封装了我们公司使用的分表分库框架,利用Springboot spi 提供自动注入。维持原本的SardingSphere-jdbc-core-spring-boot-starter 配置不变,提供下面的功能。
- 根据配置自动配置历史数据的按月分表
- 无需配置真实数据表,框架启动后会根据路由判断真实表是否存在,真实表不存在自动创建表。(查询语句不创建表,否则将会导致大量空表)
- 动态切换数据库
- 提供原生jdbc数据源切换与shardingsphere数据源切换,方便执行一个存储过程(为了兼容老项目,新项目不太建议存储过程了,维护麻烦)。
技术点介绍安排
因为由于这里的分表逻辑是和我们公司业务相关性比较强,而且使用场景非常有限,但是里面的这几个技术点我这几天准备分几个部分写几个博客来一一介绍。
- ShardingSphere 怎么做自定义分表算法(以按月分表为例)
- 怎么做到路由查询自动创建表(以按月分表为例)
- ShardingSphere 整合 Springboot AbstractRoutingDataSource 做动态数据源于提供原生JDBC数据源。
-
相关阅读:
MQ - 34 基础功能:在消息队列内核中支持WebSocket的设计
Bootstrap弹框使用
我要写整个中文互联网界最牛逼的JVM系列教程 | 「类加载子系统」章节:类的加载过程之三:Initialization
数据库设计 Relational Language
大厂不是衡量能力的唯一出路,上财学姐毕业三年的经验分享
设计模式19-状态模式
1704. 判断字符串的两半是否相似
LeetCode 热题 HOT 100 第七十八天 406. 根据身高重建队列 中等题 用python3求解
linux下下载部署nginx
电脑重装系统word从第二页开始有页眉页脚如何设置
- 原文地址:https://blog.csdn.net/wangpengfei_p/article/details/127934537
