-
基于 Retina-GAN 的视网膜图像血管分割
目录
时间:2022 ; 作者:侯松辰, 张俊虎 ;会议:ISSN
1.简要说明
1.1针对的现象
当前分割仍存在问题: (1) 眼底血管错综复杂导致分割结果中各类评价指标还有进步空间; (2) 对于血管细微分支类别的准确率还有待优化.
1.2改进的过程
为了尝试解决这个问题. 本文提出了将 RU-Net 网络作为生成器部分的 GAN 改进版模型, 并添加了一种 Attention 机制, 应用在生成器部分, 使分割区域更明确, 提高分割的准确度和特异度; 判别器选择卷积神经网络. 在对数据集的预处理上, 本文使用了自动色彩均衡 ACE 算法[10], 并与其他预处理方式的实验结果比对, 对 DRIVE 数据集通过翻转、旋转角度、均匀切割等操作将数据集扩充至3 840 张, 实验显示, 本文的模型展现了更好的性能。
1.3创新点
(1) 本文将 Attention 机制与 RU-Net 结构融合应用到生成对抗网络 (generative adversarial network, GAN) 的生成器中, 形成了一种新的结构——Retina-GAN.
(2)同时在对眼底图像的预处理步骤上选择了自动色彩均衡 (ACE), 提高图像对比度, 使血管更加清晰
1.4结果
实验显示, 本文的模型展现了更好的性能。
2.涉及到的知识点
2.1.ACE
ACE 模仿人类视觉系统模型来对色彩校正和增强, ACE 能够对自适应滤波进行局部的调整, 使图像的对比度、亮度和色彩能够自适应局部或者是非线性特征的情况.
它需要两个阶段. 第一视觉编码阶段恢复场景区域的外观, 第二显示映射阶段将过滤后的图像的值归一化. 如式 (2)[10]、式 (3) 所示, 在一阶段, 输出图像 R 在色度和空间调整后被创建, 创建后每个 p 都要依据图像的内容再次计算. 输出图像 R 中的每个像素分别为每个通道c 计算
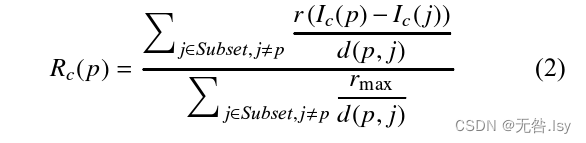
其中, p 和 j 为两个像素点, Ic(p)-Ic(j)) 表示 2 个点的亮度差, d(p,j)是距离度量函数, r(.) 为亮度表现函数, 且为奇函数, 式 (2) 的作用是调整局部图像的对比度,r(.) 的作用是依照局部内容动态放缩范围, 比如放大细微的差异, rmax表示 r(.)的最大值, Rc(p)为中间结果

对于输出图像Oc(p), sc为线段[(mc, 0), (Mc, 255)]的斜率, mc = minp Rc(p), Mc = maxp Rc(p). 使用 ACE 的增强结果如图 2(b) 所示

2.2 RU-Net
Alom 等人被 RCNN, U-Net 以及深度残差模型所启发, 提出了基于 U-Net 的 RCNN[19] 模型 RU-Net[11],这种方法结合了这 3 种模型的优势, 如图 3. 与 U-Net模型相比, 所提出的模型有 3 方面的差异. RU-Net 由卷积编码和解码单元两部分组成, 在编码单元以及解码单元中, 常规前卷积层被使用循环卷积层 RCL 和带有残差单元的 RCL 所取代. RCL 单元其本身能包含高效的特征积累方法, 带有 RCL 的单元对模型的深入建设大有裨益.

2.3Retina-Attention 机制
在图像语义分割领域中, Attention 机制通过学习获得一个对于目标图像的特征权重分布, 比如我们重点关注的特征的权重相对较高, 而不关心的特征权重则相对较低, 这个权重分布被加到原图的特征上, 为随后的任务提供参考, 使其更多地关注重点特征, 放弃一些不重要的特征, 这样能够显著提高效率
近年, 众多学者将 Attention 机制与深度学习的结合研究中不断探索, 使二者相得益彰, 其中, 提取掩膜 (mask) 成为一个很好的手段. 掩膜给图像添加一层新的权重, 使图像中的重点变得突出, 然后通过学习和训练, 让深度神经网络在后续工作中继承关注新图片中的重点或者说我们感兴趣的区域, 注意力由此而来.
受 Self-Attention[21] 的启发, 我们需要注意的仅是含有有效视网膜信息的图像, 或者说是含有血管信息 的图像, 在本文中也就是圆形内部的信息这部分是我们的感兴趣区域 (ROI). 由此本文在生成器部分添加了一种 Attention 机制, 将其命名为 Retina-Attention, 整体结构如图 4 所示.

该机制分为两个步骤:(1) 提取掩膜, 通过二值分割将 ROI 区域与无关背景区别开来, 如图 5.
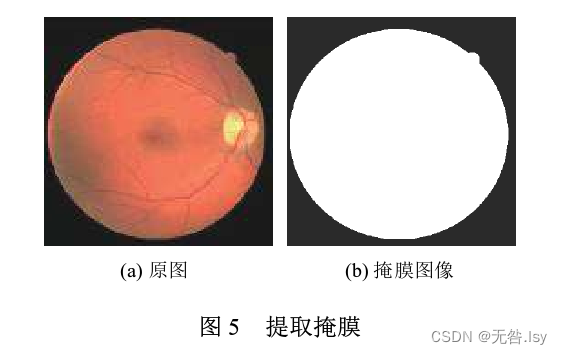
(2) 将掩膜与 RU-Net 的倒数第 2 层特征映射进行相乘, 如图 4 中长箭头所示. 如式 (7) 所示:

其中, R 表示 ROI (感兴趣区域), 也就是我们注意力要关注的区域, F 表示特征. 这个 Attention 机制的作用就是让 G 只关注眼底图像中有信息的视网膜区域 (圆形内部的区域), 放弃没有有效信息的噪声背景 (圆形外黑色区域), 这样做能有效提高分割效率, 防止 G 生成不必要的信息来占用 D 的效率. 提取掩膜有时由于提取之后信息量太少从而导致分类器网络层数堆叠大大减少的问题, 采用这种掩膜与 RU-Net 中的残差网络合的方式对当前网络层的信息加上掩膜, 同时也能够把上一层的信息传递下来, 可以有效防止提取信息量较少问题的发生
3.基于深度学习的 Retina-GAN 模型整体网络架构
本文将生成对抗网络 (generative adversarial net-work, GAN) 与 RU-Net 结合并添加一种 Attention 机制, 构成 Retina-GAN 视网膜血管分割模型, 如图 1 所示, Retina-GAN 由 3 个部分组成: (1) 图像预处理阶段, 采用自动色彩均衡 (ACE),加强图像对比度, 对图像阈值分割得到掩膜图像, 扩充 数据集, 每张图像分成 16 个 patch; (2) 生成器部分, 该部分采用 RU-Net 网络[11], 添加 Retina-Attention 机制, 将模型关注区域锁定在有效 视网膜区域, 生成的 patch 进行重组; (3) 判别器部分, 采用卷积神经网络对生成的图像进行判别, 继而优化损失函数.

4.其他
4.1数据集
DRIVE
4.2评价指标
选择使用准确性 (accuracy,Acc)、灵敏度 (sensitivity, Sen) 以及特异性 (specificity,Spe) 这 3 个性能指标.
4.3实验设置
实验选择 Adam 梯度下降方式, 动量项系数为默认值, 学习率设为 0.000 5, 每训练一次 G, 随后训练 D, 交替训练. 关于硬件, CPU 选择英特尔 i7 处理器,GPU 为英伟达 GTX 1080. 模型训练步骤如下: (1) 将专家手工分割图像输入 D 进行训练; (2) 把 DRIVE 中的眼底图像和掩膜输入 G 得到G(z), 再把 G(z) 与经过 ACE 处理后的眼底图像标记为 负样本输入到 D 进行训练; (3) 训练 G, 得到 G(z) 后再输入 D 中继续训练. 反向传播的过程中 D 的参数没有更新, 只传递误差, G 的 参数要更新和优化; 步骤 (1)–(3) 迭代训练, 令 G(z) 对于 D 而言能够以假乱真
5.结束语
尽管通过实验证明了 Retina-GAN 结构的效果在以往算法上有了提升, 但对于灵敏度的指标还有很大 提升空间, 未来的工作将围绕在不影响准确率的情况下来优化灵敏度展开
-
相关阅读:
二、Java内存模型与volatile
Java的4种引用类型
【GoLang】常量变量
JVM(Java Virtual Machine)内存模型篇
java 字符串只保留数字、字母、中文
东北大学pillow库上机实验(第三方库练习)
Mysql索引、事务与存储引擎 (事务、MySQL 存储引擎)
SpringBoot快速开发利器:CLI 属实真牛逼!
vscode编辑器 取消import自动排序
小白也能懂的可转债上市价格预测
- 原文地址:https://blog.csdn.net/weixin_51781852/article/details/125889779