-
flink1.14 sql基础语法(一) flink sql表查询详解
flink sql表查询详解
1、高阶聚合
group by cube(维度1, 维度2, 维度3) group by grouping sets( (维度1,维度2),(维度1,维度3),() ) group by rollup(省,市,区)- 1
- 2
- 3
- 4
- 5
语法示例:
select privince, city, region, count(distinct uid) as u_cnt from t group by cube(province,city,region) select privince, city, region, count(distinct uid) as u_cnt from t group by rollup(province,city,region) select privince, city, region, count(distinct uid) as u_cnt from t group by grouping sets( (province,city), (province,city,region) )- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
2、时间窗口 TVF(表值函数)
flink从1.13开始,提供了时间窗口聚合计算的TVF语法。
表值函数的使用约束:
- (1)在窗口上做分组聚合,必须带上window_start 和 window_end 作为分组的key;
- (2)在窗口上做topn计算,必须带上window_start 和 window_end 作为partition的key;
- (3)带条件的join,必须包含2个输入表的window_start 和 window_end 等值条件。
select ...... from table( tumble (table t ,descriptor(rt),interval '10' minutes) )- 1
- 2
- 3
- 4
- 5
(1) 支持的时间窗口类型
1、滚动窗口(Tumble Windows)
TUMBLE (TABLE t_action,descriptor(时间属性字段),INTERVAL '10' SECOND[ 窗口长度 ] )- 1
2、滑动窗口(Hop Windows)
HOP (TABLE t_action,descriptor(时间属性字段),INTERVAL '5' SECONDS[ 滑动步长 ] , INTERVAL '10' SECOND[ 窗口长度 ] )- 1
3、累计窗口(Cumulate Windows)
CUMULATE (TABLE t_action,descriptor(时间属性字段),INTERVAL '5' SECONDS[ 更新最大步长 ] , INTERVAL '10' SECOND[ 窗口最大长度 ] )- 1
4、会话窗口(Session Windows)
暂不支持!(2) 语法示例
select window_start, window_end, channel, count(distinct guid) as uv from table ( tumble(table t_applog,descriptor(rt),interval '5' minute ) --滚动窗口 ) group by window_start,window_end,channel- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
3、窗口topn
-- bidtime,price,item,supplier_id 2020-04-15 08:05:00.000,4.00,C,supplier1 2020-04-15 08:07:00.000,2.00,A,supplier1 2020-04-15 08:09:00.000,5.00,D,supplier2 2020-04-15 08:11:00.000,3.00,B,supplier2 2020-04-15 08:09:00.000,5.00,D,supplier3 2020-04-15 08:11:00.000,6.00,B,supplier3 2020-04-15 08:11:00.000,6.00,B,supplier3- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
/** * 10分钟滚动窗口中的交易金额最大的前2笔订单 */ public class _02_Window_Topn_V2 { public static void main(String[] args) { // 创建表的执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); StreamTableEnvironment tenv = StreamTableEnvironment.create(env); // 从kafka中读取数据 String sourceTable = "CREATE TABLE source_table (\n" + " bidtime string ,\n" + " `price` double,\n" + " `item` STRING,\n" + " `supplier_id` STRING,\n" + " `rt` as cast( bidtime as timestamp(3) ),\n" + " watermark for rt as rt - interval '5' second\n" + ") WITH (\n" + " 'connector' = 'kafka',\n" + " 'topic' = 'topn1',\n" + " 'properties.bootstrap.servers' = 'hadoop01:9092',\n" + " 'properties.group.id' = 'testGroup',\n" + " 'scan.startup.mode' = 'earliest-offset',\n" + " 'format' = 'csv'\n" + ")"; tenv.executeSql(sourceTable); // 10分钟滚动窗口中的交易金额最大的前2笔订单 tenv.executeSql("select\n" + " *\n" + "from(\n" + " select window_start,window_end, \n" + " bidtime,\n" + " price,\n" + " item,\n" + " supplier_id,\n" + " row_number() over(partition by window_start,window_end order by price desc ) as rn\n" + " from table(\n" + " tumble(table source_table,descriptor(rt),interval '10' minute)\n" + " ) \n" + ") t1 where rn <= 2 ").print(); } } ## 结果如下 +----+-------------------------+-------------------------+-------------------------+-------+---------+--------------+-------+ | op | window_start | window_end | bidtime | price | item | supplier_id | rn | +----+-------------------------+-------------------------+-------------------------+-------+---------+--------------+-------+ | +I | 2020-04-15 08:00:00.000 | 2020-04-15 08:10:00.000 | 2020-04-15 08:09:00.000 | 5.0 | D | supplier3 | 1 | | +I | 2020-04-15 08:00:00.000 | 2020-04-15 08:10:00.000 | 2020-04-15 08:09:00.000 | 5.0 | D | supplier2 | 2 |- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
/** * * 10分钟滚动窗口内交易总额最高的前两家供应商,及其交易总额和交易单数 */ public class _02_Window_Topn_V3 { public static void main(String[] args) { // 创建表的执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); StreamTableEnvironment tenv = StreamTableEnvironment.create(env); // 从kafka中读取数据 String sourceTable = "CREATE TABLE source_table (\n" + " bidtime string ,\n" + " `price` double,\n" + " `item` STRING,\n" + " `supplier_id` STRING,\n" + " `rt` as cast( bidtime as timestamp(3) ),\n" + " watermark for rt as rt - interval '5' second\n" + ") WITH (\n" + " 'connector' = 'kafka',\n" + " 'topic' = 'topn1',\n" + " 'properties.bootstrap.servers' = 'hadoop01:9092',\n" + " 'properties.group.id' = 'testGroup',\n" + " 'scan.startup.mode' = 'earliest-offset',\n" + " 'format' = 'csv'\n" + ")"; tenv.executeSql(sourceTable); // 10分钟滚动窗口内交易总额最高的前两家供应商,及其交易总额和交易单数 String executeSql = "select\n" + " *\n" + "from(\n" + " select\n" + " window_start,\n" + " window_end,\n" + " supplier_id,\n" + " sum_price,\n" + " cnt,\n" + " row_number() over(partition by window_start,window_end order by sum_price desc ) as rn \n" + " from(\n" + " select\n" + " window_start,\n" + " window_end,\n" + " supplier_id,\n" + " sum(price) as sum_price,\n" + " count(1) as cnt\n" + " from table(\n" + " tumble(table source_table,descriptor(rt),interval '10' minute)\n" + " ) group by window_start,window_end,supplier_id\n" + " ) t1\n" + ") t1 where rn <= 2"; tenv.executeSql(executeSql).print(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
4、window join查询
语法:
- 在TVF上使用join
- 参与join 的两个表都需要定义时间窗口
- join 的条件中必须包含两表的window_start和 window_end的等值条件
支持join的方式:
- inner/left/right/full
- semi(where id in …)
- anti(where id not in …)
代码示例:
/** * 各种窗口的join代码示例 */ public class _03_Join { public static void main(String[] args) { // 创建表的执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); StreamTableEnvironment tenv = StreamTableEnvironment.create(env); /** * 1,a,1000 * 2,b,2000 * 3,c,2500 * 4,d,3000 * 5,e,12000 */ // 从socket流中读取数据 DataStreamSource<String> s1 = env.socketTextStream("hadoop01", 9999); SingleOutputStreamOperator<Tuple3<String, String, Long>> ss1 = s1.map(new MapFunction<String, Tuple3<String, String, Long>>() { @Override public Tuple3<String, String, Long> map(String line) throws Exception { String[] arr = line.split(","); return Tuple3.of(arr[0], arr[1], Long.parseLong(arr[2])); } }); /** * 1,bj,1000 * 2,sh,2000 * 4,xa,2600 * 5,yn,12000 */ DataStreamSource<String> s2 = env.socketTextStream("hadoop01", 9998); SingleOutputStreamOperator<Tuple3<String, String, Long>> ss2 = s2.map(new MapFunction<String, Tuple3<String, String, Long>>() { @Override public Tuple3<String, String, Long> map(String line) throws Exception { String[] arr = line.split(","); return Tuple3.of(arr[0], arr[1], Long.parseLong(arr[2])); } }); // 创建两个表 tenv.createTemporaryView("t_left",ss1, Schema.newBuilder() .column("f0", DataTypes.STRING()) .column("f1", DataTypes.STRING()) .column("f2", DataTypes.BIGINT()) .columnByExpression("rt"," to_timestamp_ltz(f2,3) ") .watermark("rt","rt - interval '0' second ") .build() ); tenv.createTemporaryView("t_right",ss2, Schema.newBuilder() .column("f0", DataTypes.STRING()) .column("f1", DataTypes.STRING()) .column("f2", DataTypes.BIGINT()) .columnByExpression("rt"," to_timestamp_ltz(f2,3) ") // 指定事件时间 .watermark("rt","rt - interval '0' second ") // 指定水位线 .build() ); // 各种窗口join的示例 // INNER JOIN String innerJoinSql = "select\n" + " a.f0,\n" + " a.f1,\n" + " a.f2,\n" + " b.f0,\n" + " b.f1\n" + "from\n" + "( select * from table( tumble(table t_left,descriptor(rt), interval '10' second) ) ) a\n" + "join\n" + "( select * from table( tumble(table t_right,descriptor(rt), interval '10' second) ) ) b\n" + // 带条件的join,必须包含2个输入表的window_start 和 window_end 等值条件 "on a.window_start = b.window_start and a.window_end = b.window_end and a.f0 = b.f0"; // tenv.executeSql(innerJoinSql).print(); // left / right / full outer String fullJoinSql = "select\n" + " a.f0,\n" + " a.f1,\n" + " a.f2,\n" + " b.f0,\n" + " b.f1\n" + "from\n" + "( select * from table( tumble(table t_left,descriptor(rt), interval '10' second) ) ) a\n" + "full join\n" + "( select * from table( tumble(table t_right,descriptor(rt), interval '10' second) ) ) b\n" + // 带条件的join,必须包含2个输入表的window_start 和 window_end 等值条件 "on a.window_start = b.window_start and a.window_end = b.window_end and a.f0 = b.f0"; // tenv.executeSql(fullJoinSql).print(); // semi ==> where ... in ... String semiJoinSql = "select\n" + " a.f0,\n" + " a.f1,\n" + " a.f2,\n" + "from\n" + "-- 1、在TVF上使用join\n" + "-- 2、参与join 的两个表都需要定义时间窗口\n" + "( select * from table( tumble(table t_left,decriptor(rt), interval '10' second) ) ) a\n" + "where f0 in\n" + "(\n" + " select\n" + " f0\n" + " from\n" + " ( select * from table( tumble(table t_right,decriptor(rt), interval '10' second) ) ) b\n" + " -- 3、join 的条件中必须包含两表的window_start和 window_end的等值条件\n" + " where a.window_start = b.window_start and a.window_end = b.window_end\n" + ")"; // tenv.executeSql(semiJoinSql).print(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
5、flink sql中的join分类
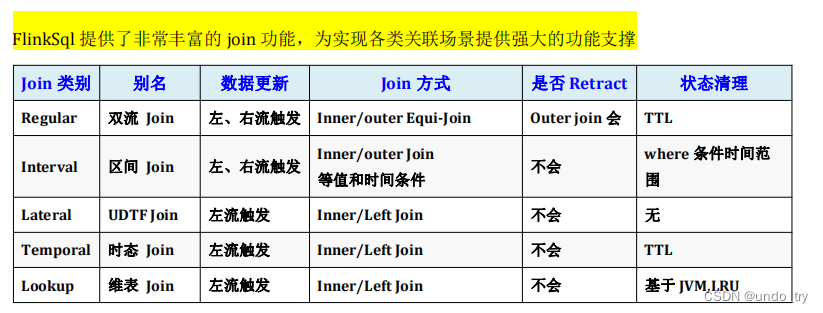
(1)regular join
常规join,flink底层是会对两个参与join的输入流中的数据进行状态存储的;所以,随着时间的推进,状态中的数据量会持续膨胀,可能会导致过于庞大,从而降低系统的整体效率;
可以如何去缓解:自己根据自己业务系统数据特性(估算能产生关联的左表数据和右表数据到达的最大时间差),根据这个最大时间差,去设置ttl 时长;
StreamTableEnvironment tenv = StreamTableEnvironmentcreate(env);// 设置table环境中的状态tt时长 tenv.getConfig().getConfiguration().setLong("table.exec.state.ttl",60*60*1000L);- 1
- 2
(2)Lookup join(维表join)
Lookup join跟其它的join有较大的不同,在 flinksql 中,所有的 source connector都实现自DynamicTableSource。
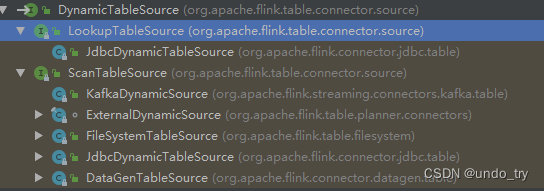
-
ScanTableSource是用的最多的常规TableSource,它会持续、完整读取源表,形成flink中的核心数据抽象—“数据流"; -
LookupTableSource,则并不对源表持续、完整读取,而是在需要的时候,才根据一个(或多个)查询key,去临时性地查询源表得到一条(或多条)数据;
lookup join为了提高性能,lookup的连接器会将查询过的维表数据进行缓存(默认未开启此机制),可以通过参数开启,比如 jdbc-connector 的 lookup模式下,有如下参数:
- lookup.cache.max-rows= (none) 未开启
- lookup.cache.ttl = (none) ttl缓存清除的时长
public class JdbcDynamicTableSource implements ScanTableSource, LookupTableSource, SupportsProjectionPushDown, SupportsLimitPushDown {- 1
- 2
- 3
- 4
- 5
它实现了上述两种接口,因而它是两种读取模式的混合封装体因而,它也实现了上述两个接口中各自的一个重要方法:
- getLookupRuntimeProvider
- getScanRuntimeProvider
对于lookupRuntimeProvider 来说,最重要的是其中的: JdbcRowDataLookupFunction
// lookup Function中最重要的就是eval方法 public void eval(Object... keys) { RowData keyRow = GenericRowData.of(keys); if (this.cache != null) { List<RowData> cachedRows = (List)this.cache.getIfPresent(keyRow); // 对于传入的keys,先从缓存中获取要查询的数据 if (cachedRows != null) { Iterator var24 = cachedRows.iterator(); while(var24.hasNext()) { RowData cachedRow = (RowData)var24.next(); // 如果缓存中拿到了数据,就直接输出 this.collect(cachedRow); } return; } } int retry = 0; // 否则,用jdbc去进行查询 while(retry <= this.maxRetryTimes) { try { // 构建jdbc查询语句statement this.statement.clearParameters(); this.statement = this.lookupKeyRowConverter.toExternal(keyRow, this.statement); // 执行查询语句,并获取resultSet ResultSet resultSet = this.statement.executeQuery(); Throwable var5 = null; try { if (this.cache == null) { while(resultSet.next()) { this.collect(this.jdbcRowConverter.toInternal(resultSet)); } return; } ArrayList rows = new ArrayList(); // 迭代resultSet while(resultSet.next()) { // 转成内部数据类型RowData RowData row = this.jdbcRowConverter.toInternal(resultSet); // 将数据装入到一个list后一次性输出 rows.add(row); this.collect(row); } // 将查询到的数据,放入到缓存中 rows.trimToSize(); this.cache.put(keyRow, rows); break; } catch (Throwable var20) { var5 = var20; throw var20; } finally { ... } } catch (SQLException var22) { ... } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
look up join的实例:
public class _04_LookUpJoin { public static void main(String[] args) throws Exception { // 创建flink sql的执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); StreamTableEnvironment tenv = StreamTableEnvironment.create(env); // 设置table环境中的状态时长ttl tenv.getConfig().getConfiguration().setLong("table.exec.state.ttl",60 * 60 * 1000L); /** * 1,a * 2,b * 3,c * 4,d * 5,e */ SingleOutputStreamOperator<Tuple2<Integer, String>> ss1 = env.socketTextStream("hadoop01", 9999) .map(new MapFunction<String, Tuple2<Integer, String>>() { @Override public Tuple2<Integer, String> map(String line) throws Exception { String[] arr = line.split(","); return Tuple2.of(Integer.parseInt(arr[0]), arr[1]); } }); // 创建主表(需要声明处理时间属性字段) tenv.createTemporaryView("a",ss1, Schema.newBuilder() .column("f0", DataTypes.INT()) .column("f1", DataTypes.STRING()) .columnByExpression("pt","proctime()") // 定义处理时间属性字段 .build()); // 创建lookup 维表(jdbc connector表) String lookUpSql = "-- register a MySQL table 'users' in Flink SQL\n" + "CREATE TABLE b (\n" + " id int,\n" + " name STRING,\n" + " gender STRING,\n" + " PRIMARY KEY (id) NOT ENFORCED\n" + ") WITH (\n" + " 'connector' = 'jdbc',\n" + " 'url' = 'jdbc:mysql://localhost:3306/ycak',\n" + " 'table-name' = 'users',\n" + " 'username' = 'root',\n" + " 'password' = 'zsd123456'\n" + ")"; tenv.executeSql(lookUpSql); // lookup join查询 String lookupSelectSql = "select\n" + " a.*,\n" + " c.*\n" + "from \n" + " a join b FOR SYSTEM_TIME AS OF a.pt as c\n" + "on a.f0 = c.id"; tenv.executeSql(lookupSelectSql).print(); env.execute(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
(3)Interval join
nterval Join:流与流的 Join,两条流一段时间区间内的 Join。Interval Join 可以让一条流去 Join 另一条流中前后一段时间内的数据
Regular Join 会产生回撤流,但是在实时数仓中一般写入的 sink 都是类似于 Kafka 这样的消息队列,然后后面接 clickhouse 等引擎,这些引擎又不具备处理回撤流的能力。 Interval Join 就是用于消灭回撤流的。
实际案例:曝光日志关联点击日志筛选既有曝光又有点击的数据,条件是曝光之后发生 4 小时之内的点击,并且补充点击的扩展参数(show inner interval click)
INSERT INTO sink_table SELECT show_log_table.log_id as s_id, show_log_table.show_params as s_params, click_log_table.log_id as c_id, click_log_table.click_params as c_params FROM show_log_table INNER JOIN click_log_table ON show_log_table.log_id = click_log_table.log_id AND show_log_table.row_time BETWEEN click_log_table.row_time - INTERVAL '4' HOUR AND click_log_table.row_time;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
时间区间条件的可用语法:
l_time = r_timel_time >= r_time AND l_time < + INTERVAL '10' MINUTEl_time BETWEEN r_time - INTERVAL '10' SECOND AND r_time + INTERVAL '5' SECOND
(4)temporal join(时态join/版本join)
左表的数据永远去关联右表数据的对应时间上的最新版本
-- 有如下交易订单表(订单id,金额,货币,时间) 1,88,e,1000 2,88,e,2000 3,68,e,3000 -- 有如下汇率表(货币,汇率,更新时间) e,1.0,1000 e,2.0,3000 -- temporal join的结果如下 1,88,e,1000,1.0 2,88,e,2000,1.0 3,68,e,3000,2.0- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
-- 创建表orders -- append-only表 create table orders( order_id STRING, price decimal(32,2), currency STRING, order_time TIMESTAMP(3), watermark for order_time as order_time )with (/*...*/) -- 创建汇率表,比如从cdc过来的表 create table currency_rates( currency STRING, conversion_rate decimal(32,2), update_time TIMESTAMP(3) METADATA from 'values.source.timestamp' VIRTUAL, watermark for update_time as update_time, PRIMARY KEY (currency) NOT ENFORCED )with ( 'connector' = 'kafka', 'value.format' = 'debezium-json', /*...*/ ) SELECT order_id, price, currency, conversion_rate, order_time FROM orders LEFT JOIN currency_rates FOR SYSTEM_TIMEAS OF orders.order_time ON orders.currency = currency_rates.currency;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
(5)窗口聚合
row_number() over ()
flinksql中,over聚合时,指定聚合数据区间有两种方式
方式1,带时间设定区间
RANGE BETWEEN INTERVAL '30'MINUTE PRECEDING AND CURRENT ROW
方式2,按行设定区间
ROWS BETWEEN 10 PRECEDING AND CURRENT ROWSELECT order_id, order_time, amount, SUM(amount) OVER( PARTITION BY productORDER BY order_time RANGE BETWEEN INTERVAL '1' HOUR PRECEDING AND CURRENT ROW ) AS one_hour_prod_amount_sum FROM Orders- 1
- 2
- 3
- 4
- 5
- 6
over window可以单独定义并重复使用,从而简化代码
SELECT order_id, order_time, amount, SUM(amount) OVER w AS sum_amount, AVG(amount) OVER w AS avg_amount FROM Orders WINDOW w AS ( PARTITION BY product ORDER BY order_time RANGE BETWEEN INTERVAL '1' HOUR PRECEDING AND CURRENT ROW )- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
-
相关阅读:
大数据旅游数据分析:基于Python旅游数据采集可视化分析推荐系统
Mathorcup数学建模竞赛第四届-【妈妈杯】C题:家庭暑假旅游套餐的设计(附MATLAB代码)
《安富莱嵌入式周报》第327期:Cortex-A7所有外设单片机玩法LL/HAL库全面上线,分享三款GUI, PX5 RTOS推出网络协议栈,小米Vela开源
27岁,准备转行做网络安全渗透,完全零基础,有前途吗?
Adobe 认证证书怎么考
ajax有哪些优缺点?
git reset soft mixed hard keep区别
废品回收小程序:高效便捷回收,推动市场发展
剑指Offer面试题解总结61~70
直到今天,信息孤岛依旧是各领域企业需要面对的问题
- 原文地址:https://blog.csdn.net/qq_44665283/article/details/125908709
