-
模型优化方法
目录
引入概念(可以反向传播去推导):
每一层的梯度都与它当前层数接收到的数据相关,除此之外,层数越往前,和梯度相关的因素就越多(后面层数的梯度 与 后面层接收到的数据经过目标函数的导函数 的 累乘将越多),这里累乘意味着当相关因素大于1的时候,前几层的梯度会比较大,小于一时,会非常小,对后几层的影响会越来越小。过大过小的情况,分别被称为,梯度爆炸和梯度消失。
sigmoid
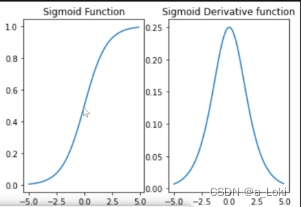
左图为sigmoid函数图像,右图为导函数图像,对于sigmoid激活函数,其导函数最大值为0.25,在累乘情况下有可能出现梯度消失的现象。
如果sigmoid函数接收到的值处于饱和状态(非常大或非常小),此时导函数取值趋近于零,则更容易导致模型梯度消失。此时对于复杂模型而言,看似层数很多,但前几层的梯度非常小,因此梯度更新慢,学习能力较弱,单纯的增加层数也无法得到更好的效果。
tanh

对与tanh函数,因为函数可以输出负值,则可以输入零均值的数据,就意味着导函数接受到的结果也可能在0附近,此时导函数取得最大值1,也保证后续层接受到的数据为零均值的数据(Zero-centered Data),可有效避免梯度消失的情况。
梯度和导函数关系如下:
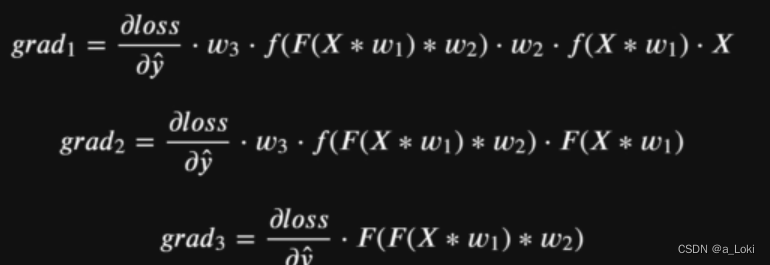
但是,如果梯度更新中,出现个别参数,较大的情况,则更新过程会出现波动,一部分更新很快,一部分得不到更新,出现梯度爆炸(梯度不平稳)的情况
以上问题解决
无论是梯度爆炸还是梯度消失,都属于梯度不平稳的现象,解决此现象,一般有:参数初始化方法,数据的归一化方法,衍生激活函数使用方法,学习率调度方法和梯度下降方法。这些方法都有一个基本的理论:glorot条件
通过之前的经验,要让梯度有一个稳定的变化,核心是激活函数的导数值尽可能区最大值,也就是输入数据为Zero-centered Data。输入数据一般为X*w,X可以用归一化方法处理,关键在于w如何变为Zero-centered Data(一般w会给到网络自动生成)。对于w,明确的一点是它的均值为0,而方差的确定需要满足glorot条件,即:正向传播时,每个线性层输入数据的方差等于输出数据的方差,同时,反向传播时,数据流经某层之前和流经某层之后该层的梯度也具有相同的方差。(主要围绕tanh函数的优化)
Relu
relu函数的累乘不会出现梯度爆炸或者梯度消失的现象,但由于其部分数值归零的特性,会出现Dead Relu Problem(神经元活性失效) 问题。
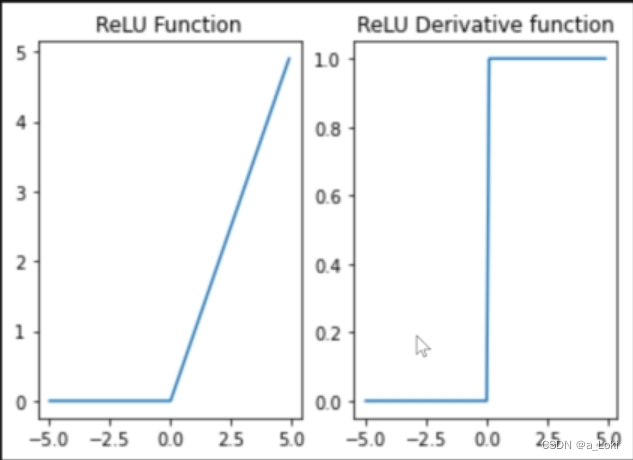
根据上面的导函数图像性质,当输入数据为负时,会存在导函数取值为零,则后续梯度的累乘过程中都为零,此时梯度无法更新。
通过调整学习率缓解Dead Relu Problem
当迭代次数越多,越容易陷入我们梯度全为零的问题中,而较小的学习率就以为更小的步长,此时模型更加保守,更加不容易走到梯度为零的位置,而更小的梯度则需要更多的迭代次数(迭代次数与计算量有关),但relu函数的计算量相对于前两个函数来说较小,不会有显著提升(初始化输入的数据不能让梯度为零)。
而只要不出现神经元活性失效问题,则导函数取值都为一,梯度的取值也会更加平稳,不会出现梯度爆炸或者消失的现象。小批量梯度下降中,可能会出现一批数据输出是零的情况,此时,梯度是不更新的,而不为零,则为一。
-
相关阅读:
git --- Docker搭建本地Git仓(Gogs)
Docker与VM虚拟机的区别以及Docker的特点
电子技术基础之一(电容和电感)
c#中适配器模式详解
vim 替换命令 “:s“
使用Spark的foreach算子及UDTF函数实现MySQL数据的一对多【Java】
linux安装opencv
浅浅懂了一些transformer中的self-attation
【饭谈】细嗦那些职场中喜欢用领导口气命令别人的同事
棒子老虎鸡-第12届蓝桥杯Scratch选拔赛真题精选
- 原文地址:https://blog.csdn.net/a_Loki/article/details/125663885