-
Spring源码:Spring 如何解决 Bean 的循环依赖
1. 什么是循环依赖
一个项目,随着业务的扩展,功能的迭代,必定会存在某些类和类之间的相互调用,比如 serviceA 调用了serviceB 的某个方法,同时 serviceB 也调用了serviceA 中的某个方法,从而形成了一种循环依赖的关系。
假如 Spring 容器启动后,先会实例化 A,但在 A 中又注入了 B,然后就会去实例化 B,但在实例化 B 的时候又发现 B 中注入了 A,于是又继续循环,后果就是导致程序 OOM。不过一般没有十年脑血栓应该都写不出来,哈哈哈。
2. 回顾 Bean 的创建流程
在上篇文章中讲到了Bean 的创建流程,大致调用链路如下:

因此,Spring在创建完整的 Bean 的过程中分为三步:
-
实例化,即 new 了一个对象;
对应方法:
AbstractAutowireCapableBeanFactory#createBeanInstance() -
属性注入,为第 1 步中 new 出来的对象中的属性进行填充(依赖注入);
对应方法:
AbstractAutowireCapableBeanFactory#populateBean() -
初始化,执行 Aware 接口方法,init-method以及实现了 InitializingBean 接口的方法。
对应方法:
AbstractAutowireCapableBeanFactory#initializeBean()
由于之前关于 Bean 的创建流程相对详细,所以某些代码就不在这里细讲。
3. Spring 如何解决循环依赖
针对循环依赖的情况,Spring 已经帮我们解决了单例的循环依赖问题。
栗子
ServiceA
@Data @Component public class ServiceA { @Autowired private ServiceB serviceB; }ServiceB
@Data @Component public class ServiceB { @Autowired private ServiceA serviceA; }启动容器会创建实例:

需要注意的是,Spring 只提供了在 单例无参构造函数 情况下的解决方式(在源码中也能体现),有参构造函数的加 @Autowired 的方式循环依赖是直接报错的,多例的循环依赖也是直接报错的。
Spring 为了解决单例模式下的循环依赖问题,使用了 三级缓存 ,通过上图 Bean 的创建流程来分析它是如何解决的。
3.1 三级缓存
什么是三级缓存,其实就是Spring中在实例化的时候定义了三个不同的Map,如果我们要解决循环依赖,其核心就是提前拿到提前暴露的对象,尽管它还没有初始化。
名称 描述 singletonObjects 一级缓存,用于存放完全初始化好的 Bean earlySingletonObjects 二级缓存,存放提前暴露的Bean,Bean 是不完整的,未完成属性注入和执行初始化方法 singletonFactories 三级缓存,单例Bean工厂,二级缓存中存储的就是从这个工厂中获取到的对象 在源码
DefaultSingletonBeanRegistry中的体现:
3.2 单例循环依赖
单例循环依赖,也就是上面例子中演示的情况,按照实例创建过程分析,当我们创建一个对象 A 时,必定会调用
getBean()方法,而该方法存在 2 种情况:- 缓存中没有,需要创建新的Bean;
- 从缓存中获取到已经被创建的对象。
从缓存中获取对象,调用
getSingleton()方法如下:
当第一次创建 A 时,必然一、二、三级缓存中都没有数据,然后进入单例情况下创建 Bean,如下:

重新调用重载的
getSingleton(String beanName, ObjectFactory singletonFactory)方法,如下:
可以看到先会把 A 添加到一个表示正在创建的 Set 集合中,而传入的函数
singletonFactory,实际调用的就是createBean()方法,在该方法中,进入真正做事的方法doCreateBean(),在该方法中会先调用createBeanInstance()进行实例化,具体过程在上篇文章中已经讲过,这里不在赘述。通过 debug 模式可以看到,此时的 A 是一个半成品对象,因为还没有属性填充,如下:

实例化之后应该就是属性填充和初始化,但在这之前 Spring 为循环依赖做了处理,有这么一个判断:
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences && isSingletonCurrentlyInCreation(beanName));第一个条件默认就是单例的,
allowCircularReferences默认值也是 true,isSingletonCurrentlyInCreation也是 true 因为 A 还没有完全实例化,因此还在 Set 容器中,所以earlySingletonExposure = true,即会进入下面的代码:
继续进入
addSingletonFactory方法:
可以看到,就是把创建的半成品实例 A 放入了三级缓存,但这里只是添加了一个工厂,通过这个工厂
ObjectFactory的getObject方法可以得到一个对象,而这个对象实际上就是通过getEarlyBeanReference这个方法创建的。那么, 什么时候会去调用这个工厂的getObject方法呢 ?这个时候就要到创建 B 的流程了。什么时候去创建 B 呢?
因为在 A 实例化的过程中会收集被
@Autowried注入的属性,所以 A 在实例化之后就要去属性填充注入实例 B,而这个属性的注入过程中就会去调用 B 的getBean方法,而这时 B 在缓存中也是没有的,所以又会走一遍 A 的流程。debug 如下:

这个时候的 B 也是一个半成品实例的状态,因为还没有进行属性填充和初始化,所以 B 接着往下走,开始进行属性填充
populateBean。而 B 又循环依赖了 A,所以会再次调用
getBean方法去获取实例 A,在上面的分析中我们已经知道此时的 A 已经被创建提前暴露在三级缓存中,尽管此时的 A 还没有初始化,所以当调用getBean的时候又会进入getSingleton去获取 Bean。
现在来回答上面的问题,什么时候会调用这个
getObject,没错,就是在这里调用,调用的方法就是getEarlyBeanReference,看看这个方法:
实际上就是对 BeanPostProcessor 的类型做处理,然后调用
SmartInstantiationAwareBeanPostProcessor#getEarlyBeanReference(),而该方法的实现只有 2 个,如下:
进入这两个实现类,InstantiationAwareBeanPostProcessorAdapter 明显直接返回了这个Bean,相当于什么都没做,也就是说只用二级缓存就能解决了,为什么还要从三级缓存中在拿出来?这就要看另外一个实现类了。

而另外一个就是 AbstractAutoProxyCreator,从名字就可以知道是用来做 AOP 代理的,这也是 为什么需要三级缓存而不是二级缓存 ,因为有的时候我们可能需要的是代理Bean,而不是真正的实例Bean。
为什么是三级缓存,不是二级缓存,实际二级缓存就是可以解决循环依赖的问题,但是,Spring 还有一个 aop,当有 bean 需要实例化,在实例化的最终阶段会检查该对象是否有被代理,若被代理则需要生成代理对象,所以,Spring 将三级缓存中的 ObjectFactory 设计成返回代理对象,那如果有多个对象B,C,D等等依赖 A,ObjectFactory就不必要生成多个代理对象,只需要从二级缓存中获取之前生成的代理对象即可,所以需要三级缓存。

但这里 暂不考虑代理 的情况,也就是说这里直接返回的就是之前创建出来的半成品实例 A 并且从 三级缓存 放到了 二级缓存 中,并把 A 注入到 B 中,因此目前 B 的状态为:
B 已经完全实例化,即属性填充和初始化都已完成,此时再回到
getSingleton(String beanName, ObjectFactory singletonFactory)方法:
那么 A 的状态呢?在 B 完全实例化之后,B 中已经有了 A 的引用,debug如下:
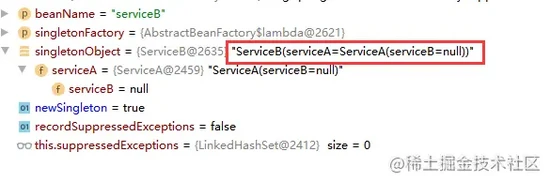
可以看到 B 中有了 A,但实例 A 中的
B = null,这是因为 A 还没有完成属性填充(因为被 B 给打断了),而这个时候 A 再去进行属性填充 B,当调用 B 的getObject的时候发现一级缓存中已经有了 B 的实例,因此直接把 B 注入到 A 中,然后完成了 A 的实例化,同样在进入getSingleton方法把实例 A 添加到一级缓存中,从而解决了循环依赖。3.3 单例构造函数循环依赖
除了上面的注入方式,还有构造器的注入方式,如下:
A
@Data @Component public class ServiceA { private ServiceB serviceB; public ServiceA(ServiceB serviceB) { this.serviceB = serviceB; } }B
@Data @Component public class ServiceB { private ServiceA serviceA; public ServiceB(ServiceA serviceA) { this.serviceA = serviceA; } }当启动容器的时候发现直接报错了:

这是为什么呢?
之前讲过构造器的注入方式,会在实例化 A 的时候会去实例化 B,而此时都还没有添加到缓存中去,所以会报错。

3.4 多例循环依赖
对于多例的情况,Spring 直接抛出了异常,如下:

可以看到在
doGetBean中,Spring直接是抛出了异常,我们看看这个多例的情况是在哪里赋值的。还是在
doGetBean中:
可以看到在
createBean之前先调用了beforePrototypeCreation方法,即把这个 Bean 放入到多例的正在被创建的 Bean 的一个ThreadLocal 中去。
如果我们按照单例的模式来走,当 A 创建的时候,把 A 放进ThreadLocal中去,然后去创建 B,由于B依赖于A,又会去调用 getBean ,此时发现ThreadLocal中已经存在 A 了,于是就抛出异常。
至于为什么,想想其实可以理解, 多例情况下每次的三级缓存都是不一样的 ,我找哪一个呢?所以找不到对应的三级缓存,校验的时候肯定会发生异常。
4. 总结
简单来说,Spring解决了单例情况下的循环依赖,在不考虑AOP的情况下,大致步骤如下:
-
A 实例化时依赖 B,于是 A 先放入三级缓存,然后去实例化 B;
-
B 进行实例化,把自己放到三级缓存中,然后发现又依赖于 A,于是先去查找缓存,但一级二级都没有,在三级缓存中找到了。
- 然后把三级缓存里面的 A 放到二级缓存,然后删除三级缓存中的 A;
- 然后 B 注入半成品的实例 A 完成实例化,并放到一级缓存中;
-
然后回到 A,因为 B 已经实例化完成并存在于一级缓存中,所以直接从一级缓存中拿取,然后注入B,完成实例化,再将自己添加到一级缓存中。
对于存在 AOP 代理的循环依赖,下次再说。

-
-
相关阅读:
防止F12调试的JS代码
Spring AOP
搭建高可用k8s
Easily Import and Export Annotations from PDFs
ElasticSearch之分布式模型介绍,选主,脑裂
Mac上安装Java的JDK多版本管理软件jEnv
制作.a静态库 (封盒)
大数据学习——安装hive
使用环形缓冲区ringbuffer实现串口数据接收
文心一言 vs gpt-4 全面横向比较
- 原文地址:https://blog.csdn.net/m0_71777195/article/details/125907547