-
执行ls /dev/pts为什么这么慢?
一、问题背景
服务器的安全agent新增了一个扫描插件,插件上线以后,DBA反馈客户端访问Redis出现了耗时高的情况。
赶紧开始救火啦~
二、问题排查
1. 止损和初步定位
联系安全回滚,赶紧把新上的插件下掉,看起来服务是恢复了。
通过atop查看当时插件的执行情况,发现插件运行时CPU占用100%,看起来是这个引起的Redis耗时增加。
对程序Debug一下,发现是下面的代码耗时较长:

这里引入了一个第三库”github.com/shirou/gopsutil/v3/process” 来遍历进程。

在获取TTY的时候,有明显阻塞。
看下这个库的源码,发现三方库内部会打开 /dev/pts 文件。
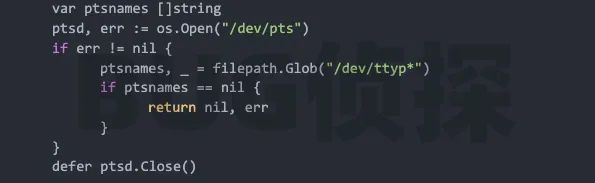
在发生问题的服务器上手动执行一下看看?

果然也很慢!
2. devpts是个啥?
devpts类似proc,是内存文件系统,里面保存了虚拟终端文件。
做个简单的测试便于大家了解:
-
在本地电脑打开两个终端,分别通过ssh登录到同一台服务器上。
-
在其中一个终端执行:

-
在另一个终端可以看到hello显示出来啦~

3. 根因分析
我们看到实际/dev/pts目录下的文件并不多,并且这是个内存文件系统,为什么执行会这么慢呢?
先用strace看下:

可以发现是getdents系统调用耗时较高,如何从这个入手继续向下分析呢?
是时候祭出神器:eBPF了!
什么是eBPF?简单来说eBPF是一个通用执行引擎,可基于此开发性能分析工具、软件定义网络等诸多场景。我们可以基于它定义自己的用户程序,来实现类似内核模块的功能,但是无需重新编译内核。
我们基于Python的bcc模块来实现eBPF程序
BCC (BPF Compiler Collection) 是基于 Linux eBPF 特性的内核跟踪及调试工具。
简单定义一个分析内核函数耗时的脚本,这个脚本的目的是跟踪ls命令相关的系统函数耗时。

比如我们可以通过下面的方式运行脚本,通过输出时间戳作差得到函数执行的耗时。

持续追踪下去,getdents -> ksys_getdents64 -> iterate_dir -> dcache_readdir -> next_positive,最终定位到是next_positive函数耗时较高。
来看一下next_positive函数的定义,里面是一个链表遍历,可能是链表太长导致的问题。

三、问题复现和结论
实际链表不应该这么长,这是一个内核Bug吗?
为了验证问题,我们选择了一批服务器来测试。这批服务器内核版本是4.19,分为三个小版本:4.19.12、4.19.72、4.19.84,实际测试只有4.19.12版本内核存在ls /dev/pts耗时高的问题。
查看内核commit历史记录,发现了一个相关提交:

终端退出时调用d_delete方法,实际并没有删除d_subdirs链表中的元素。这样链表就会持续增加,最终导致了此问题。
问题如何复现?上面的commit里已经给出了方法,重复执行命令python -c 'import pty; pty.spawn(["ls", "/dev/pts"])',经过一段时间可以感觉到ls /dev/pts命令明显变慢了,同时可以通过systemtap验证链表长度的增加。
总结
这是一个内核Bug,影响范围是4.7.5 ~ 4.19.31。安全上线插件后,反复执行ls /dev/pts导致链表持续增加,遍历链表时服务器CPU占用高,影响Redis服务响应耗时。
如何优化?
首先我们修改了第三方库,去掉了遍历/dev/pts目录的部分逻辑,这部分实际上我们是不需要的。
另外对异常机器的内核版本进行升级,理论上升级到 > 4.19.31的版本就可以,实际我们升级到了4.19.84(当前线上有在用的稳定版本)。
四、参考文章

-
-
相关阅读:
凛冬已至,望各位早日背上行囊出发
基于ZLMediaKit的GB28181视频平台demo
uniapp web-view调整修改高度设置
如何使用 DataAnt 监控 Apache APISIX
130 行代码搞定核酸统计,程序员在抗疫期间的大能量
BUUCTF中的web
Killing LeetCode [946] 验证栈序列
# Vue3 setup 函数
如何在一个pycharm项目中创建jupyter notebook文件,并切换到conda环境中
Spring:AOP事务管理(14)
- 原文地址:https://blog.csdn.net/BUG_zhentan/article/details/125893974