-
BIO、NIO、AIO、多路复用IO
同步阻塞IO(Blocking IO):即传统的IO模型。
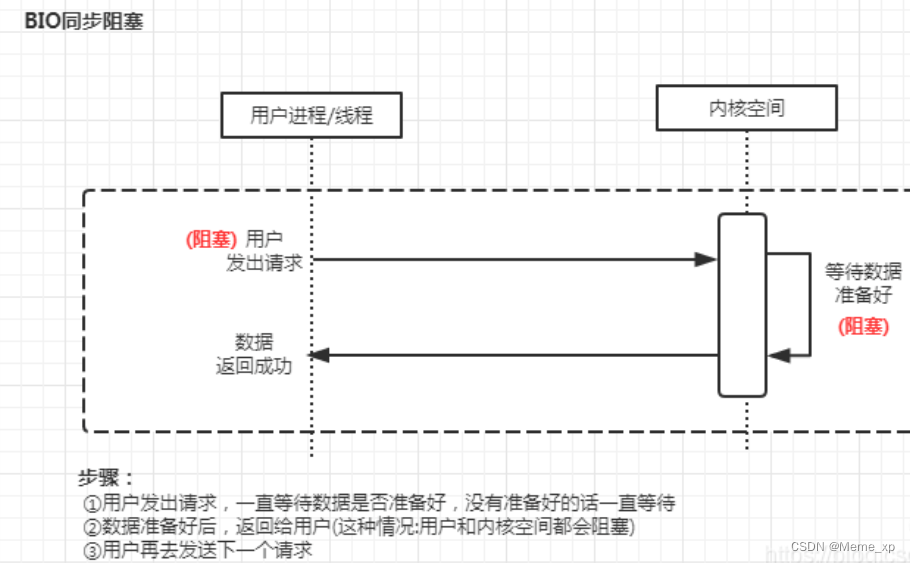
读取时如果数据还没准备好,则阻塞线程。缺点
发生上下文切换,一个线程管理一个io
同步非阻塞IO(Non-blocking IO):默认创建的socket都是阻塞的,非阻塞IO要求socket被设置为NONBLOCK。注意这里所说的NIO并非Java的NIO(New IO)库。
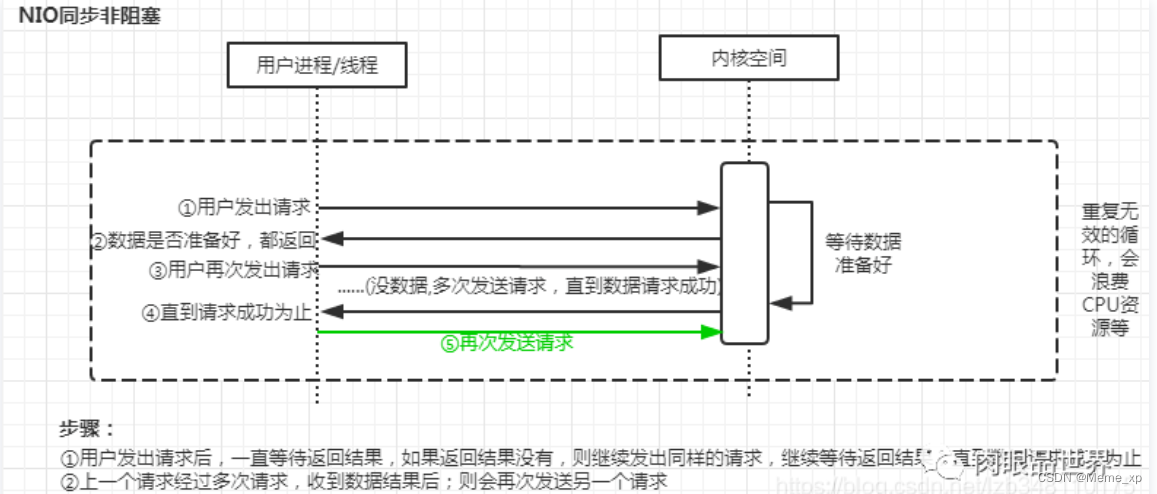
不阻塞,读取时如果还没数据准备好,则返回-1。缺点
如果都多个io,需要一个一个检测,每次检测调用read都会发生上下文切换(read是系统调用,每调用一次就得在用户态和核心态切换一次)第一次读取不到时,不知道应该等待多久再尝试读取一次
多路复用IO(IO Multiplexing):即经典的Reactor设计模式,有时也称为异步阻塞IO,Java中的Selector和Linux中的epoll都是这种模型(Redis单线程为什么速度还那么快,就是因为用了多路复用IO和缓存操作的原因)
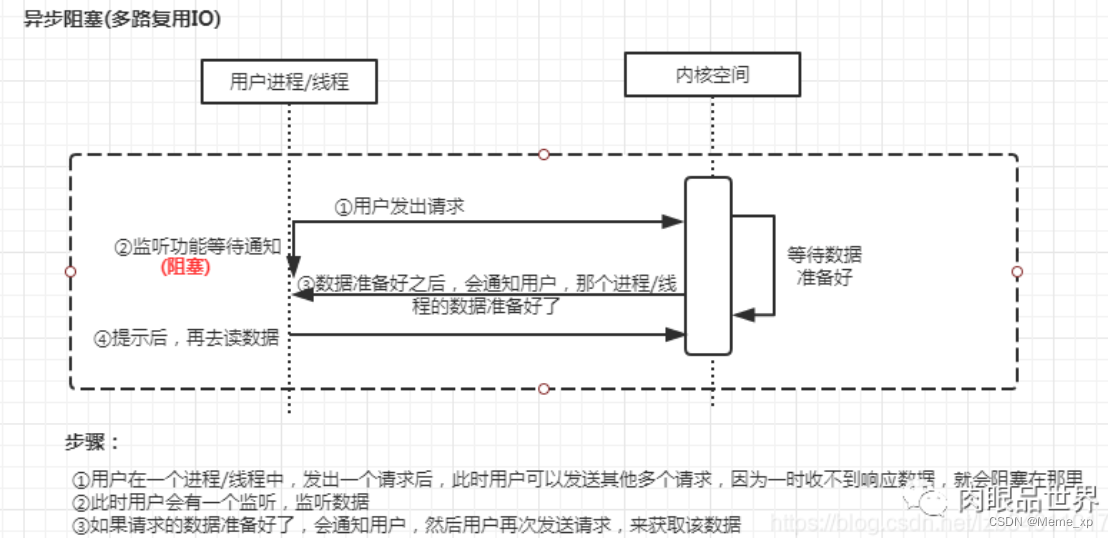
IO多路复用和NIO是要配合一起使用才有实际意义。IO多路复用有select、poll、epoll三种方式。
select select只有一个函数,调用select时,需要将监听句柄和最大等待时间作为参数传递进去,select会发生阻塞,直到一个事件发生了,或者等到最大1秒钟(tv定义了这个时间长度)就返回。
select缺点
1.select返回后要挨个遍历fd,找到被“SET”的那些进行处理2.select是无状态的,即每次调用select,内核都要重新检查所有被注册的fd的状态。select返回后,这些状态就被返回了,内核不会记住它们;到了下一次调用,内核依然要重新检查一遍。于是查询的效率很低
3.select能够支持的最大的fd数组的长度是1024
poll poll优化了select的一些问题,参数变得简单一些,没有了1024的限制。但其他的问题依旧。
poll缺点 依然是无状态的,性能的问题与select差不多一样 应用程序仍然无法很方便的拿到那些“有事件发生的fd“,还是需要遍历所有注册的fd
epoll 使用epoll时,需要先使用函数epoll_create()在内核层创建了一个数据表,接口参数是一个表达要监听事件列表的长度的数值(会动态改变的)。这样一来,不用每次监听都要传一遍fd(传递fd会导致fd数据从用户态复制到内核态)。
创建完数据表,就可以使用另外一个函数epoll_ctl()来管理数据表,对监听的fd执行增删改操作。最后再调用epoll_wait()方法等待事件的发生。epoll优点
为什么epoll的性能比select和poll要强呢?
select和poll每次都需要把完成的fd列表传入到内核,迫使内核每次必须从头扫描到尾。而epoll完全是反过来的。epoll在内核的数据被建立好了之后,每次某个被监听的fd一旦有事件发生,内核就直接标记之。epoll_wait调用时,会尝试直接读取到当时已经标记好的fd列表,如果没有就会进入等待状态。
同时,epoll_wait直接只返回了被触发的fd列表,这样上层应用写起来也轻松愉快,再也不用从大量注册的fd中筛选出有事件的fd了。
epoll除了性能优势,还有一个优点——同时支持水平触发(Level Trigger)和边沿触发(Edge Trigger)。
异步IO(Asynchronous IO):即经典的Proactor设计模式,也称为异步非阻塞IO。
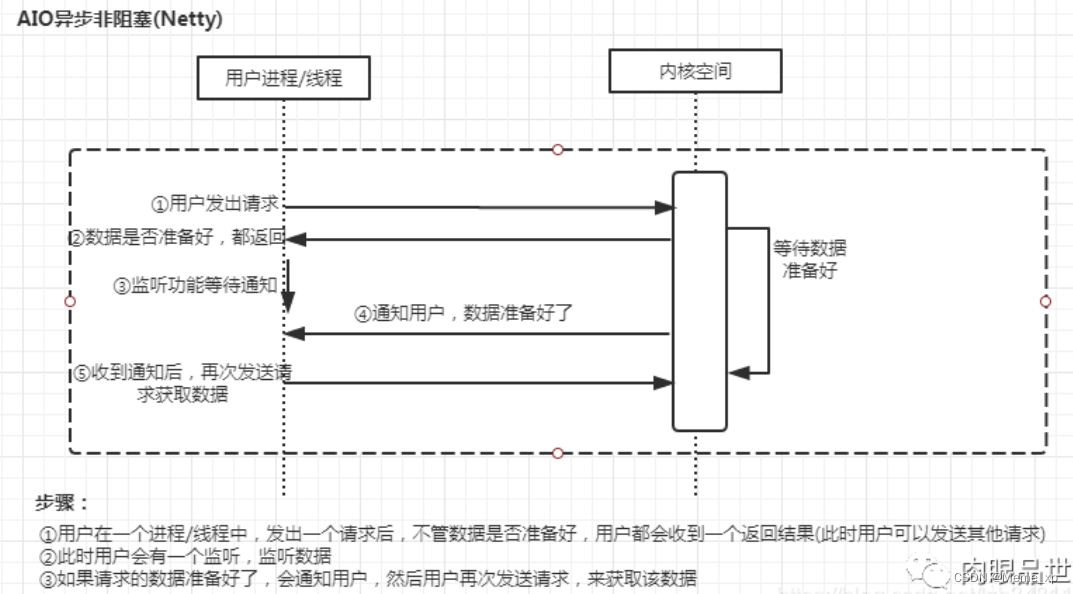
-
相关阅读:
3DCAT实时云渲染赋能聚好看科技,打造3D沉浸式互动视频云平台
Python模块:基本概念、2种导入方法(import与from...import)和使用
Elasticsearch高级检索之使用单个字母数字进行分词N-gram tokenizer(不区分大小写)【实战篇】
freesql自定义sql和参数查询
mysql启动报错The server quit without updating PID file几种解决办法
1.1_4操作系统的运行机制与体系结构
GBase8s数据库SET COLLATION 语句
Sentinel持久限流化化规则到Nacos
想看,但电脑没网怎么办,python教你保存整本成TXT~
接入支付宝沙箱环境
- 原文地址:https://blog.csdn.net/qq_52563729/article/details/125883239