-
CV (3)- Loss Functions and Optimization
本次学习笔记主要记录学习CV时的各种记录,包括李飞飞团队的视频cs231n。作者能力有限,如有错误等,望联系修改,非常感谢!
第一版 2022-07-19 初稿
损失函数

图像分类中各种问题。还有K-NN和线性分类器。

损失函数告知我们当前分类器的好坏。
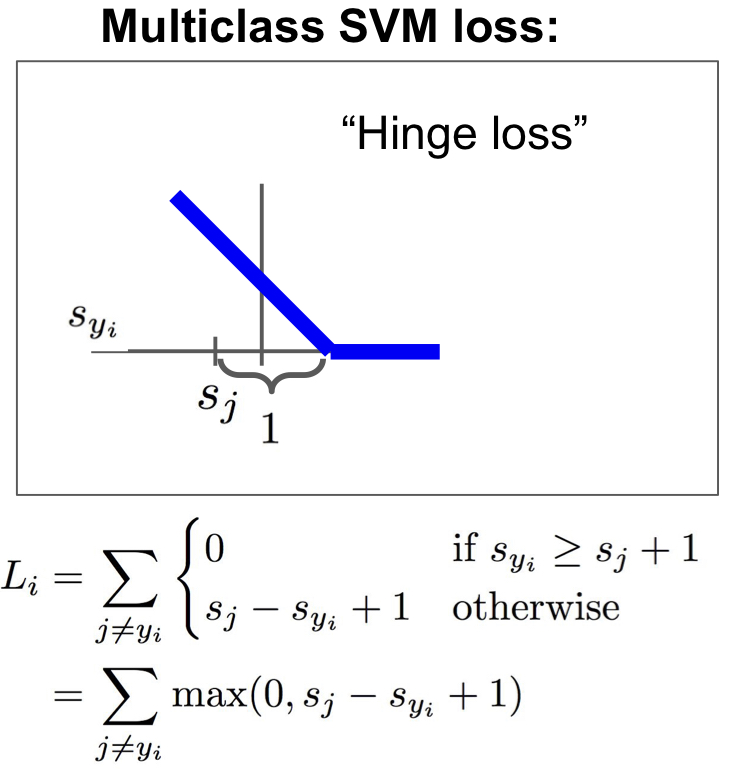
多分类SVM分类器。其中s=f(xi,W),x轴表示s_yi,表示训练样本真实分类的分数,y轴是损失。s_yi表示训练集第i个样本的真实分类的分数。

L_cat = max(0,5.1-3.2+1) + max(0,-1.7-3.2+1) = 2.9,剩下两个类似计算。
为什么选择加1? 其实是在一定程度上是一个任意的选择。1.稍微改变汽车的分数,损失函数会发生什么变化?
不会变化。
2.最小或最大的可能损失?
最小值0,最大值无穷大
3.刚开始初始化W很小,s约为0,损失是什么?
分类数量减1
4.对SVM所有分类求和会发生什么?
损失函数会加1
5.求平均而不是求和呢?
不会改变
6.在max函数上加平方会怎样?
实际上计算了另一种损失函数。

dot()矩阵乘积。


一般加入正则项,选择更简单的W。
奥卡姆剃刀:如果有许多可解释观察结果的假设,应选最简单的。

常见的有L2正则化 和 权值衰减。
加入惩罚项,主要为了减轻模型的复杂度。
L2正则化更能够传递出x中不同元素值的影响,鲁棒性更好。
L1正则化更加倾向于W1相对于W2。

此例子中L1和L2效果撞了。


1.损失L_i最小值0,最大值无穷大;
2.初始项W小,s约为0,损失是什么? 减log©



如何才能真正发现这个W使损失最小化?这就因此最优化。最优化

在山顶时,找如何轻松到达山底。

随机搜索:搜集采样,输入到损失函数,去看效果。

通过随机搜索训练一个线性分类器,准确度只有15.5%。

利用地形可能是个好策略。

所示导数,即斜率,逐步趋于0。梯度就是偏导数组成的向量。


使用微积分。

概括起来:
1.数值梯度:近似,缓慢,书写简单
2.解析梯度:确切,块,易出错
实际上:通常使用解析梯度,但用数值梯度检查实现。称为梯度检查。

步长也叫作学习率,一个重要超参数。
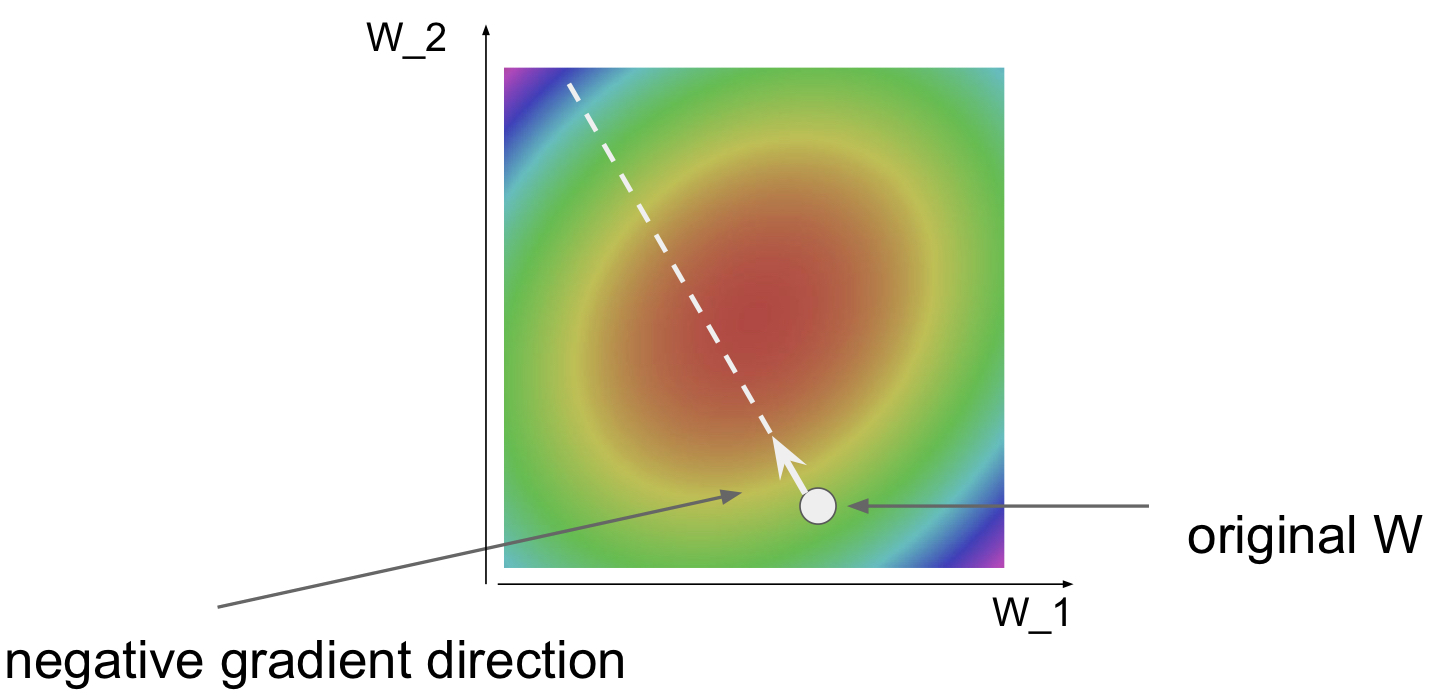
红色区域是我们的目标。

随机梯度下降,减少了每次训练的次数。使用一部分minibatch来估算总和以及实际梯度。


线性分类器就是将原始像素取出,直接传入线性分类器。

动机是 图左无法线性分类,但可采用一个灵活的特征转换。
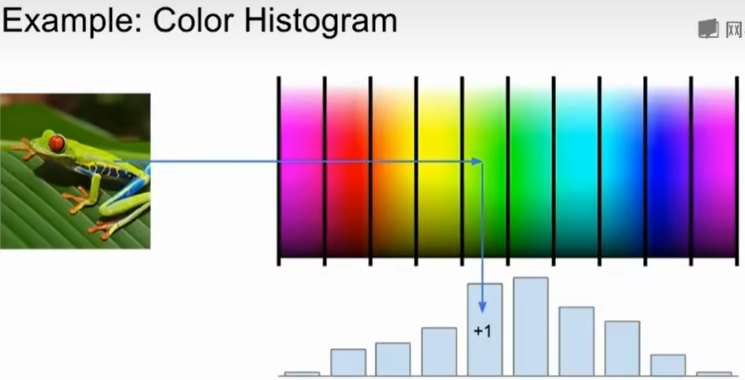
一个特征表示的简单例子:颜色直方图,获取每个像素对应的光谱图。

方向梯度直方图。

词袋,从NLP中获取的灵感。
1.将所有图像分为小块,使用聚类方法将所有小块聚类。
2.编码图像。

-
相关阅读:
开学买哪个牌子的电容笔好?推荐的ipad手写笔
Object.assign和&&
ArcGIS加载免费在线历史影像作为底图(不需要插件)
运行业务项目时,如何管理客户关系?
Flink SQL自定义表值函数(Table Function)
Python并发方案深度对比
rocketmq Listener 消费消息的优雅方式(基于SPEL)
Vue3.X笔记总结
DevOps初学者的指南——阿里出品学习图册带你掌握高薪技术!
硅谷(12)菜单管理
- 原文地址:https://blog.csdn.net/zxq997997/article/details/125876231