-
【无标题】
前几天的文章中我们提到MAE在时间序列的应用,本篇文章介绍的论文已经将MAE的方法应用到图中,这是来自[KDD2022]的论文GraphMAE: Self-supervised Masked Graph Autoencoders

生成学习与对比学习
自监督学习从大量的无监督数据中挖掘出自己需要的的监督信息。与监督学习相比,它使用来自数据集本身的信息来构建伪标签。而在对比学习[9]方面,自监督学习作为监督学习的补充具有很大的潜力。
自MoCo和SimCLR引入以来,对比学习在图自监督学习领域占据主导地位,其在节点分类和图分类等任务上的表现远远超过生成式自监督学习方法。但是对比学习的成功往往取决于下面的两个因素:
- 高质量的数据扩充。GraphCL[5]探索了几种数据增强方法的有效性,如掩蔽属性、子图采样和随机添加和删除边。但是通过研究发现有效的图数据增强往往依赖于领域知识;例如,随机添加和删除边缘对社交网络中的训练是有利的,但它会会对分子图产生负面影响。所以到目前为止,在图对比学习中还没有普遍有效的数据增强方法。
- 复杂的策略来稳定训练。对比方法通过通用的训练技巧避免模型陷入繁琐的解决方案。GRACE[8]、DGI[7]和GraphCL[5]等方法在训练中使用负采样,而BGRL[6]利用了非对称网络结构和指数移动平均策略。
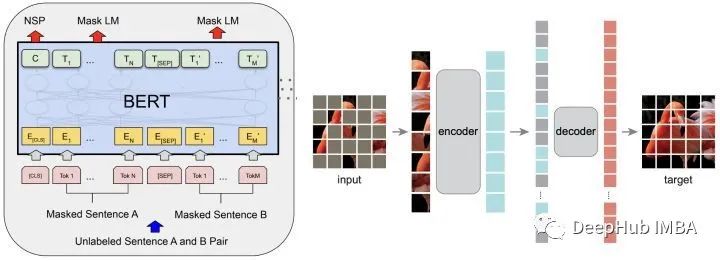
而生成式自监督学习可以避免上述依赖关系。生成式自监督学习能够重构数据本身的特征和信息。在自然语言处理(NLP)中,BERT[3]旨在恢复遮蔽词;在CV (Computer Vision)中,MAE[2]恢复图像的像素点(块)。
对于图,GAE (Graph Autoencoder)重建图的结构信息或节点特征。现有的图数据动编码器大多着眼于链接预测和图数据聚类目标,因此通常会选择重构图数据的结构信息,即邻接矩阵a。所以近年来图数据自编码器的进展远远落后于对比学习,在分类等任务上的表现并不令人满意。节点分类、图分类等任务的SOTA都是基于对比学习的方法。
与以前的图形自编码器不同,GraphMAE通过简单的重建被遮蔽的损坏节点特征,使图自编码器超越对比学习
GraphMAE的关键设计在于以下几个方面:
- 基于遮蔽的节点特征重构。现有的图数据自编码器通常以边缘作为重构目标,但其在下游分类任务中的表现通常较差。
- 以GNN为解码器进行以重建过程。现有的图自编码器通常选择MLP作为解码器,由于大多数图形节点特征是连续的向量,MLP的能力不足以从编码结果重建节点特征。
- 用缩放后的余弦误差作为损失函数来代替MSE。
在21个不同大小的数据集上,GraphMAE在节点分类、图分类和分子性质预测3个任务上的性能进行了评估。实验结果表明,GraphMAE在不依赖数据增强等任何技术的情况下,取得了与当前最优对比学习方法相当甚至超过的结果。
这表明生成式自监督学习仍然有很大的潜力,GraphMAE有助于我们在图生成学习方面的进一步探索。
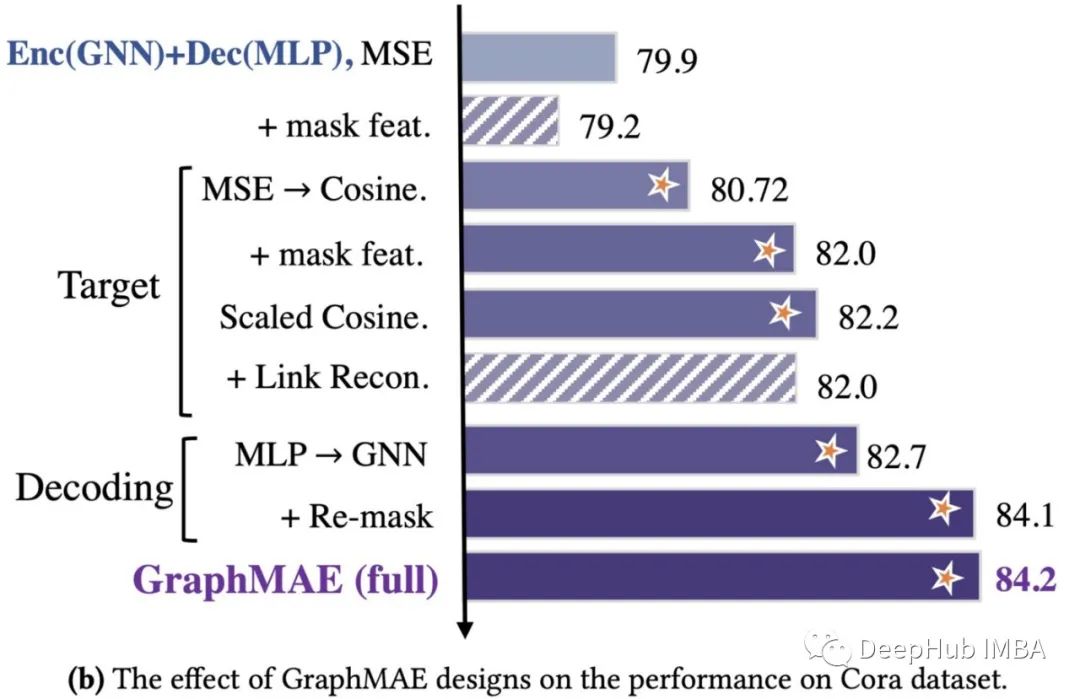

GraphMAE是如何工作的
使用[MASK]重构节点特征
最近关于图自编码器的许多工作都倾向于重建结构和节点特征。这些努力并没有获得像在NLP, CV中所取得的重大进展。在[1]中,通过提取已经训练过的GNN中的信息,可以使MLP在节点分类的性能方面与GNN相媲美。这表明了节点特性在任务(如分类)中的重要性。因此,GraphMAE使用且仅使用重构的特征作为自监督学习的目标,分类任务的实验也表明,重构的节点特征可以提供有效的信息。
具体来说,类似于BERT和MAE,对于一个图,X是它所有节点的特征矩阵。随机选取一部分随机节点,用[MASK]替换其特征。
带复遮蔽掩码的GNN解码器
解码器的作用是将编码器得到的节点表示H映射回输入的节点特征X。它的设计应该取决于重构目标x的语义级别。例如在NLP中,一个相对简单的解码器(如MLP)通常就足够了,因为重构的目标是一个语义丰富的缺失词。在CV中MAE显示,要恢复低语义信息的像素,需要更复杂的解码器(如Transformer模型)。
在图学习中解码器需要重构相对少量的信息高维向量。传统解码器要么不使用神经网络作为解码器,要么使用mlp。这些解码器表现力较差导致编码器获得的节点表示H几乎与输入X相同。
因此GraphMAE采用单层图神经网络作为解码器。GNN解码器可以根据节点周围的节点分布恢复自身的输入特征,而不仅仅是节点本身,因此它可以帮助编码器学习高级信息。
此外GraphMAE使用了一种新的“re-mask”方法。最初采样节点的表示再次用另一个掩码标识[DMASK]替换,即解码器的掩码标识向量。通过重新掩蔽和GNN解码器,模型通过被掩蔽的目标节点的未掩蔽邻居的表示来重建被掩蔽的目标节点。
按比例缩小的余弦误差
不同研究领域的自编码器对重构误差的测量是不同的。在NLP中,预训练的语言模型以交叉熵误差的形式预测掩码令牌id,而CV中的MAE直接使用均方误差(mean square error, MSE)来预测掩码像素。GraphMAE直接重建每个被掩盖节点的原始特征,现有的用于节点特征重建的图自编码器使用均方误差(Mean Squared Error, MSE)作为损失函数。
在论文中提到,在训练中MSE如果被最小化到接近于零是难以优化的,这可能不足以进行有意义的特征重构,所以GraphMAE使用余弦误差来衡量重构效果。引入尺度余弦误差(Scaled Cosine Error,SCE)来进一步改善余弦误差。对于高置信预测,相应的误差通常小于1,当比例因子gamma大于1时,误差会更快地衰减为零,这相当于为不同困难程度的样本调整了权重。给定原始输入特征X和解码器输出Z,缩放后的余弦误差定义为下面的公式:

缩放因子是一个超参数,可以在不同的数据集上调整。缩放误差也可以看作是一个自适应的样本权重调整,其中每个样本的权重调整不同的重建误差(类似于Focal Loss[4])。
实验结果


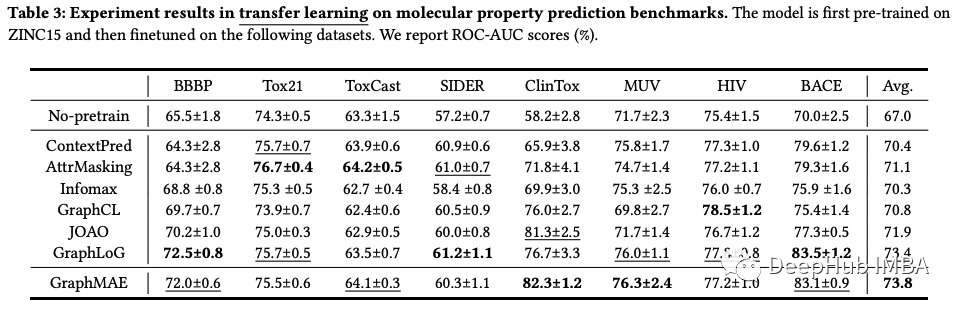
从以上结果来看,GraphMAE在节点分类、图分类和分子性质预测任务上平均优于SOTA对比学习方法。
总结
GraphMAE证明生成式自我监督学习在图表示学习中仍然有很大的潜力。与对比学习相比,GraphMAE不依赖于数据增强等技术。因此生成式自监督学习在未来的图表示学习[2][9]中值得进行更深入的探索。更多的细节可以在论文和代码中找到。
https://avoid.overfit.cn/post/c4b9e590e7464b059fb6d756b3f794e2
本文的一些引用
[1] Shichang Zhang, Yozen Liu, Yizhou Sun, and Neil Shah. 2022. Graph-less Neural 1037 Networks: Teaching Old MLPs New Tricks Via Distillation. In ICLR.
[2] Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Gir- shick. 2021. Masked autoencoders are scalable vision learners. In CVPR.
[3] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In NAACL. 4171–4186
[4] Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. 2017. Focal loss for dense object detection. In ICCV.
[5] Yuning You, Tianlong Chen, Yongduo Sui, Ting Chen, Zhangyang Wang, and 1030 Yang Shen. 2020. Graph contrastive learning with augmentations. In NeurIPS
[6] Shantanu Thakoor, Corentin Tallec, Mohammad Gheshlaghi Azar, Rémi Munos, Petar Veličković, and Michal Valko. 2022. Large-Scale Representation Learning 1000 on Graphs via Bootstrapping. In ICLR.
[7] Petar Veličković, William Fedus, William L Hamilton, Pietro Liò, Yoshua Bengio, and R Devon Hjelm. 2018. Deep Graph Infomax. In ICLR.
[8] Yanqiao Zhu, Yichen Xu, Feng Yu, Qiang Liu, Shu Wu, and Liang Wang. 2020.Deep graph contrastive representation learning. arXiv preprint arXiv:2006.04131 1040 (2020).
[9] Xiao Liu, Fanjin Zhang, Zhenyu Hou, Li Mian, Zhaoyu Wang, Jing Zhang, and Jie Tang. 2021. Self-supervised learning: Generative or contrastive. TKDE (2021).
作者:Shaw99
-
相关阅读:
4.7k Star!全面的C#/.NET/.NET Core学习、工作、面试指南
webpack打包ts的配置及踩坑
电脑重装系统Win10关闭网速限制的方法
Python语言的12个基础知识点小结
Git 笔记 - git diff
五年数据库专家,深入剖析高性能MySQL架构系统,不来后悔一辈子
NodeJS 5分钟 连接MySQL 增删改查
利用开天aPaaS平台实时查询出行城市防疫策略
画法几何及机械制图复习题及答案
微信小程序引入 iconfont 图标
- 原文地址:https://blog.csdn.net/m0_46510245/article/details/125887004