-
探索数据库,中文字段排序,到底是什么
问题描述:在数据库中,中文字段的排序,升序降序,后面到底比的是什么呢?
使用的工具:
mysql数据库,jdk自带的native2ascii.exe
说说native2ascii工具的使用:

是安装jdk后自带的编码转换器,配置好系统环境变量后,可以在任意位置调用它。
打开命令行,输入:native2ascii 回车 可以进行汉字转unicode编码。
还可以将 .txt 等文本文档转为指定的编码,这里不演示了。
准备一张表,一些数据

直接开始,首先按姓名排序试试

结果,张皓是第一个,秦思在最后,并不是想象中的按拼音或者笔画排序
分析:张皓在张非前面,说明 ‘皓’ 大于 ‘非’
验证:底层比的是unicode编码大小
 原来如此:
原来如此: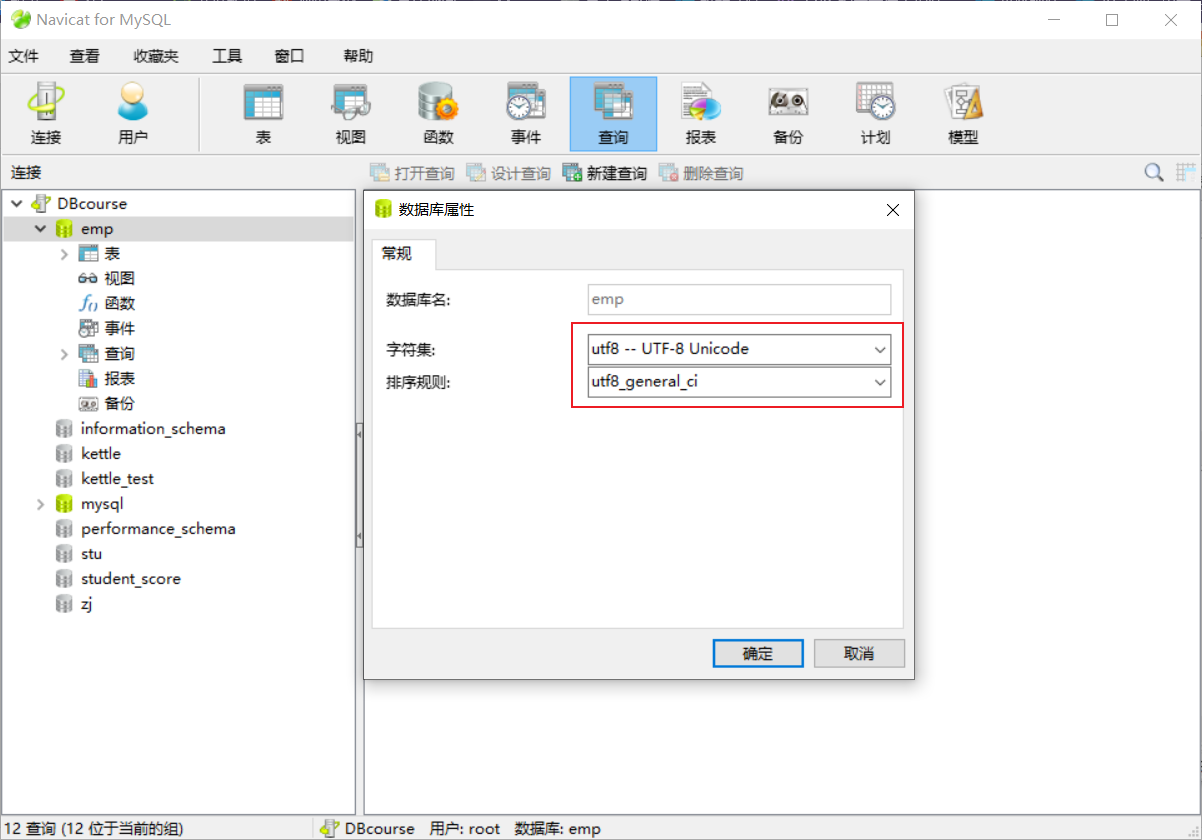
延申出来一个问题:将数据库的编码换成gbk,是否满足排序规则,依然按照编码的大小排序
新建一个gbk编码的数据库,键表,插入数据:
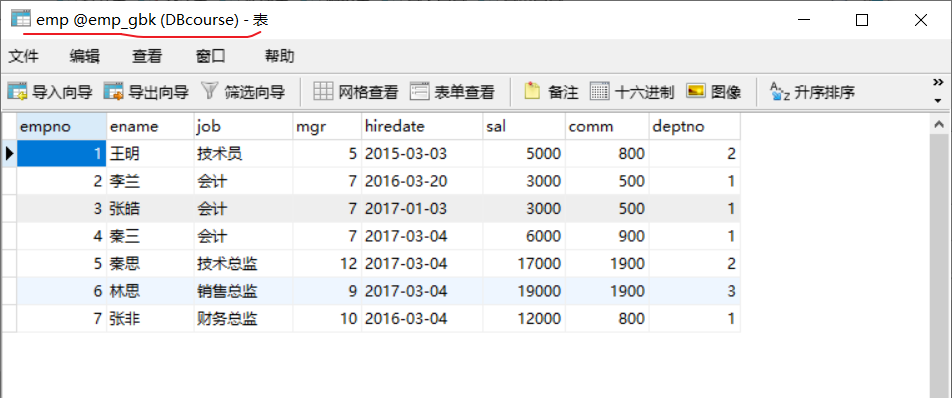
排序:发现顺序和刚才的编码不一样
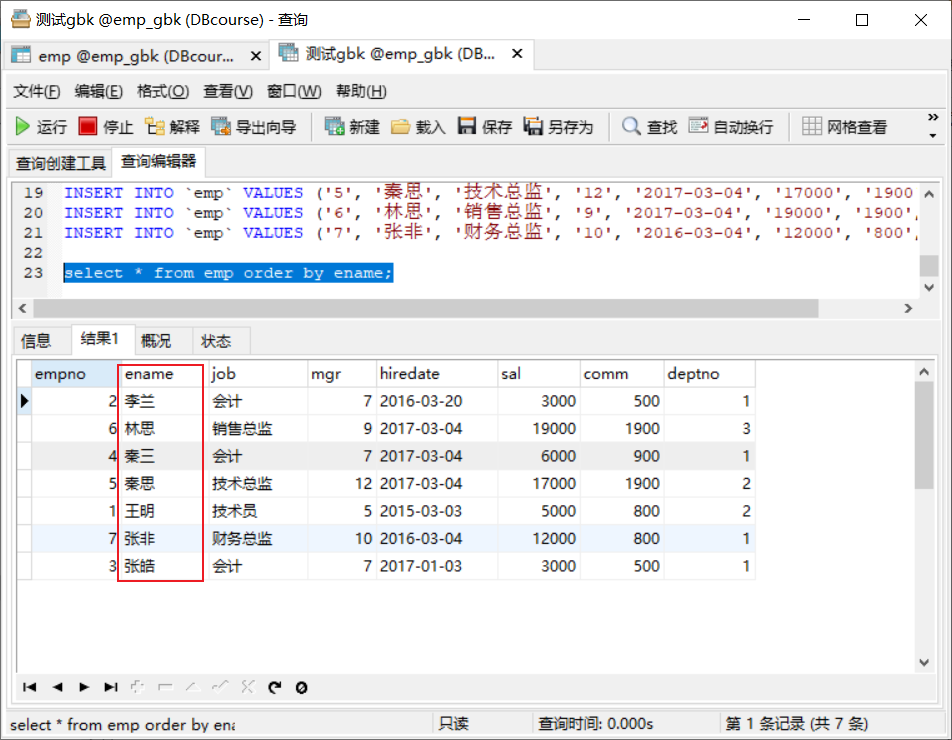
验证:使用在线工具获取汉字的gbk编码
http://mytju.com/classcode/tools/encode_gb2312.asp
李C0EE兰C0BC
林C1D6思CBBC
秦C7D8三C8FD秦C7D8思CBBC
王CDF5明C3F7
张D5C5非B7C7
张D5C5皓F0A9结论:按照拼音排序,第一个字相同就比第二个字,依次进行。。。
关于gbk编码的具体排序细则,有兴趣的,我单独写一篇博客
-
相关阅读:
OCCT v11.0.16 x64 电脑硬件检测烤鸡软件中文
Linux系统命令——通过端口确认进程及路径方法
深入解析Spring Boot的常用注解和组件(上)
java实现中介者模式
SpringBoot-组件配置/自动配置原理/Lombok
Centos7安装Gitlab--gitlab--ee版
方舟生存进化是什么游戏?好不好玩
Gem5模拟器学习之旅——翻译自官网
Mybatis 缓存原理
【淘宝API开发系列】获取商品详情,商品评论、卖家订单接口
- 原文地址:https://blog.csdn.net/Ipkiss_Yongheng/article/details/125886499