-
微服务架构 | 消息队列 - [常见坑] TBC...
§1 重复消费
§1.1 概念
同一条消息被 comsumer 消费两次
§1.2 成因
中间件本身原因
- 有的队列没有进行控制,一条消息确实可以扔给多个comsumer(其实还是可以通过配置搞定)
人为因素
- 研发人员没有正确配置消息队列,比如没有打开 ACK 机制
- 研发人员在没有搞清队列机制时做的二次开发(实际踩坑,处于生产环境的业务最好严禁萌新自研且没人把关)
不可抗力
- ACK 机制上的异常,比如刚准备 ACK 的时候 comsumer 猝死等
§1.3 解决思路
中间件本身
- 更换技术选型,选用易用性(无脑性更高)的消息中间件
- 了解中间件细节,通过正确配置或二次开发搞定
人为因素(通常造成问题最多的场景)
- 团队统一由一部分研发人员进行相关技术的开发,严禁个人心血来潮(但不用排斥个人探究)
- 统一用于消息开发的组件或模板、统一编码风格、统一培训、定期收集需求升级
- 对工作经验有限的研发人员要有一定的审核机制
不可抗力
- 具体方式有不少,但基本可以概括成通过幂等控制
§1.4 不同消息中间件的相关配置或设置
rabbitMq(指定消费者组)
rabbitMq 通过对 comsumer 进行分组,从 rabbit 的 web 管理端可以查看各个 exchange 的分组情况

web 管理页面会显示为 bindings,这里就是我们说的分组(分组的称呼是根据配置字段来的)

点击可以查看详情,比如消费者数量

涉及到的配置spring: application: name: rabbit-stream-consumer rabbitmq: host: 192.168.3.10 port: 5672 username: guest password: guest cloud: stream: binders: defaultRabbit: type: rabbit bindings: input: destination: studyExchange content-type: application/json binder: defaultRabbit group: studyExchange_main # 关键是这个配置项,我们说的分组也是按这个配置项叫的- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19

kafka(操作 offset)
//TODO start 待迁移
kafka 是一个上限很高但下限很低的消息中间件,从实践中体会,它的易用性相对不高。
这里说的易用性不高是指,相对其他消息中间件,它更需要一定的学习成本,需要了解一些概念,否则很容易错误使用。比如,如下图所示
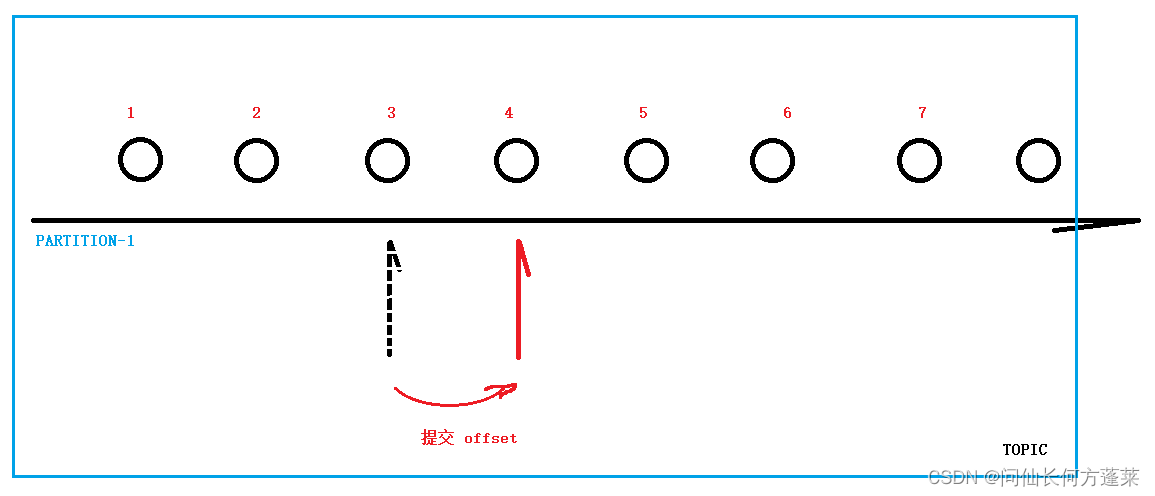
- 通常,我们使用 kafka 是使用它的 发布-订阅主题(Topic 模式)
- topic 中通常包含若干个 partition,作为实际队列(queue),同一个 partition 中的消息可以保证顺序消费
- 每个 partition 最多被一个 comsumer 监听并消费
- 每个 partition 都持有一个 偏移量(offset) 用来标记消息消费的位置
- 当一个消息正常消费后,需要提交 offset 以标记此消息为已消费
kafka 判断一个消息是否被消费,是基于 偏移量(offset)的
kafka 在 springboot 中使用时,是有一个 @KafkaListener 的,用法如下@KafkaListener(topics = {"${kafka.topic.alarm.topic-name}"}, containerFactory = "generalKafkaConsumerFactory") @Override public void listen(ConsumerRecord<String, String> consumerRecord, Acknowledgment ack) { super.listen(consumerRecord, ack); }- 1
- 2
- 3
- 4
- 5
它可以让被注解的方法按 每次消费单条消息并自动提交 offset 的方式消费 topic
但这里的自动提交 offset 是只要方法(比如上面的 listen())执行完就提交,那消费失败靠什么区分呢,靠抛异常。
于是作者所见不止一个团队,远远不止一个研发,各种 throw new Exception(),接着就各种消息丢失
因为只有抛 RunTimeException 时,才会进入重试机制
//TODO end 待迁移默认的 @KafkaListener
kafka 的防止重复消费主要依靠正确提交 offset
kafka 结合 springboot 时,提供了一个相对易用的注解 @KafkaListener
需要注意此注解默认单条消费、自动提交,只有消费过程中抛出 RunTimeException ,才会进入重试机制配合自定义模板或其他二次开发
同时,在某些时候,默认注解不能满足业务场景(毕竟是个百万吞吐量的消息中间件,业务场景花样很多),此时我们可以通过一些简单模板封装或二次开发以满足不同的需要模板1,要求研发人员提供一个 boolean 的返回,除非消费完全正常,否则一律不提交 offset,根据细节有不同处理
此模板实践中可以有效防止研发人员只考虑业务处理而不考虑考虑处理结果(毕竟处理成什么样得返回)public abstract class KafkaLisenterPrototype<T> { protected static Logger logger= LoggerFactory.getLogger(KafkaLisenterPrototype.class); public void listen(ConsumerRecord<String, T> record, Acknowledgment ack) { logger.info("<<>> load msg:" ); boolean processed = false; try { logger.info("<<>> topic:{}, partition:{} loaded" ,record.topic(), record.partition()); T message = record.value(); processed = onMessages(message);//实际处理,会返回一个 boolean 的结果 logger.info("<<>> processed [{}]" ,processed); if(processed){ ack.acknowledge();//手动提交偏移量 logger.info("<<>> offset commited:\n{}" ,message); }else{ logger.info("<<>> offset not commited:\n{}" ,message); throw new RuntimeException("for retry"); } } catch (Exception e ) { logger.error("<<>> exception:" ,e); if(e instanceof RuntimeException) throw e; }finally{ logger.info("<<>> done" ); } } public abstract boolean onMessages(T message); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
模板2,再更复杂的业务中,我们可能需要对 offset 进行更多的操作,以适应更多消费场景
/** * 目的: * 原始的kafkaListener,只支持正常执行完成和异常两种处理结果,分别对应提交offset和重试 * 但是,在复杂场景,需要按具体需求自定义行为时,可能并不友好 * 因此需要更多的对消息执行完之后的操作的指示信息 * * 此类中,使用String类型的值代表这些信息,并预设若干指令,并给出默认的处理方式 postActionHandle * * 扩展思路: * 允许扩展指示信息,并提供扩展宏的指示信息-指示信息执行器容器和指示信息执行器接口 * 优化现有默认处理方式为执行器组(链) * 提供注册指示信息执行器的注解 */ public abstract class PostActionKafkaLisenterPrototype<T> { protected static Logger logger= LoggerFactory.getLogger(PostActionKafkaLisenterPrototype.class); @Resource private KafkaConfig kafkaConfig; @Resource protected KafkaTemplate<String, String> kafkaTemplate; @Resource private AdminClient adminClient; /* ******************************* * PROCESSED 处理成功,提交offset * FAILED 失败,重试,不提交offset * RETRY 重试,自己控制重试时才使用,比如使用重试队列 * IGNORE 忽略,不处理,提交offset,重复消费等场景使用 * DELAY 延时,不满足处理条件时使用,可以直接丢回队列,也可以自定义重试队列,变更重试次数,推荐钩子 * DEAD 死信,直接进入死信队列,没有重试价值时使用 * POSTACTION 钩子,完全自定义,推荐使用简易的命令模式 * 后面会支持自注册的后置处理 ******************************* */ protected static final String IGNORE = "IGNORE"; protected static final String PROCESSED = "PROCESSED"; protected static final String FAILED = "FAILED"; protected static final String DELAY = "DELAY"; protected static final String DEAD = "DEAD"; protected static final String POSTACTION = "POSTACTION"; public void listen(ConsumerRecord<String, T> record, Acknowledgment ack) { logger.info("<<>> load msg:" ); String processed ; logger.info("<<>> {} loaded" ,record.topic()); processed = (null==record.value())?DEAD:onMessages(record.value()); logger.info("<<>> processed [{}]" ,processed); postActionHandle(processed, record, ack); logger.info("<<>> done" ); } protected void postActionHandle(String processed, ConsumerRecord<String, T> record, Acknowledgment ack) { switch (processed){ case IGNORE: ack.acknowledge();//手动提交偏移量 logger.info("post action:offset commit(ignore) {}({},{})", record.topic(),record.partition(),record.offset()); break; case PROCESSED: ack.acknowledge();//手动提交偏移量 logger.info("post action:offset commit(process) {}({},{})",record.topic(),record.partition(),record.offset()); break; case FAILED: logger.info("post action:offset not commited(failed):\n{}",record.value()); throw new KafkaConsumeFailedException(); case DELAY:break; case DEAD: try { if(!adminClient.listTopics().namesToListings().get().containsKey(record.topic()+kafkaConfig.getDlqSuffix())){ logger.error("post action: create DLQ for topic: {}",record.topic()); adminClient.createTopics( Arrays.asList(new NewTopic(record.topic()+kafkaConfig.getDlqSuffix(),record.partition(), (short) 1))); //TODO 若出问题,改为while,直到拿到结果 TimeUnit.MILLISECONDS.sleep(500); kafkaTemplate.send(record.topic()+kafkaConfig.getDlqSuffix(),record.value().toString()); } ack.acknowledge();//手动提交偏移量 logger.info("post action:offset dead {}({},{})",record.topic(),record.partition(),record.offset()); break; } catch (InterruptedException|ExecutionException e) { logger.error("post action offset dead exctption to retry,{}:\n{}",record.topic(),record.value()); postActionHandle(FAILED,record,ack); break; } case POSTACTION:break; default: } } public abstract String onMessages(T message) throws RuntimeException; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
§1.5 不可抗力导致的重复消费处理(幂等)
正确的配置通常可以保证消息中间件在正常条件下正常工作
但一些不可抗力会导致破功,比如- ack 的时候,网络哆嗦了
- 虽然消费成功了,但一些业务上的检查机制认为并没有,于是重新发了消息
- 队列里直接出现了两条一模一样的消息(这个不能算人为因素,因为很可能是上游服务的问题,但在他们解决之前,不能在自己的服务里将错就错)
这些问题通常可以通过幂等解决
幂等解决有两种思路,
一种是真的将消息再完整处理一遍,但再次处理之后与处理了一次之后结果一模一样
另一种是再处理消息前判断消息的状态,跳过已经处理的过的并且结果符合预期的消息第一种难度较大,操作性不强,通常实现第二种思路
第二种思路有两个要点:- 同时最多只能有一个 comsumer 处理某个具体事务(注意脱离开消息,而关注里面的事务)
- 已经处理过的事务不需要在处理一次
大体流程如下

上面的流程其实可以更加复杂,一个简单的例子,红线处添加一个期待处理缓存校验,这可以适应执行条件比较复杂的消息(比如必须其他服务达成某些条件,此消息才有消费的基础)
传送门:
微服务架构 | 组件目录 -
相关阅读:
k8s持久化存储PV、PVC
经验分享丨中小企业如何低成本开发APP
Python 2022年面试题总结
快来手写RPC框架 S1
Golang基础-面向过程篇
Android最全的setContentView源码分析
Mysql使用中的性能优化——索引数对插入操作性能的影响
《动手学深度学习 Pytorch版》 6.6 卷积神经网络
深入URP之Shader篇16: UNITY_BRANCH和UNITY_FLATTEN
什么品牌的蓝牙耳机音质最好?音质好的蓝牙耳机推荐
- 原文地址:https://blog.csdn.net/ZEUS00456/article/details/125843703
