-
5.过拟合,dropout,正则化
过拟合


过拟合导致测试误差变大:
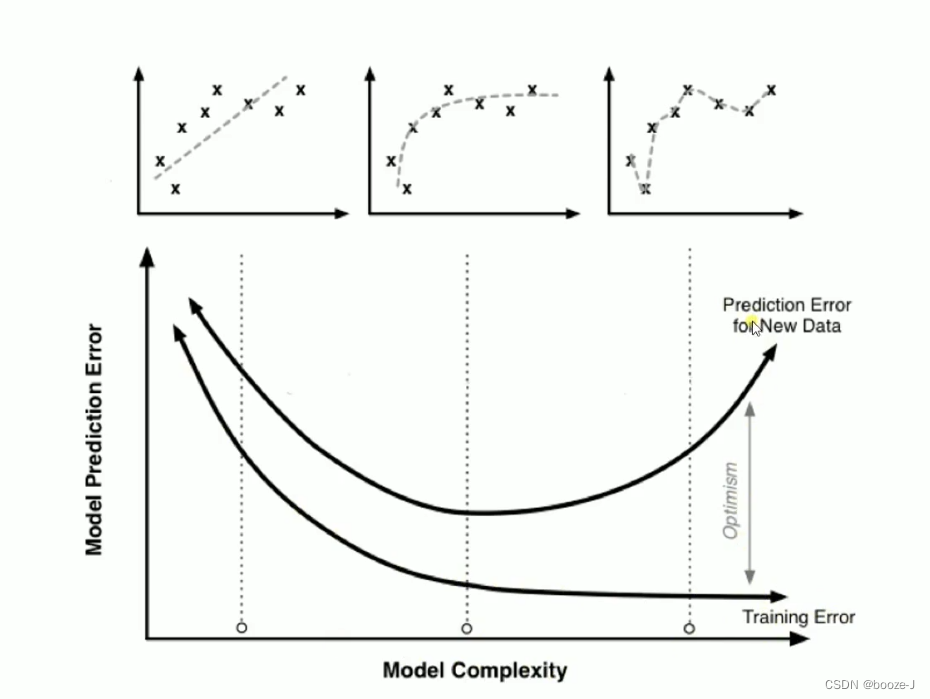
可以看到图中随着模型结构的越来越复杂,训练集的误差越来越小,测试集的误差先变小后变大,过拟合导致测试误差变大。
比较好的情况是训练误差和测试误差这两条线比较接近。防止过拟合
1.增大数据集
数据挖掘领域流行着这样一句话,“有时候拥有更多的数据胜过一个好的模型”。一般来说更多的数据参与训练,训练得到的模型就越好。如果数据太少,而我们构建的神经网络又太复杂的话就比较容易产生过拟合的现象。
2.Early stopping
在训练模型的时候,我们往往会设置一个比较大的选代次数。Early stopping便是一种提前结束训练的策略用来防止过拟合。
一般的做法是记录到目前为止最好的validation accuracy,当连续10个Epoch没有达到最佳accuracy时,则可以认为accuracy不再提高了。此时便可以停止迭代了(Early Stopping)。
3.Dropout
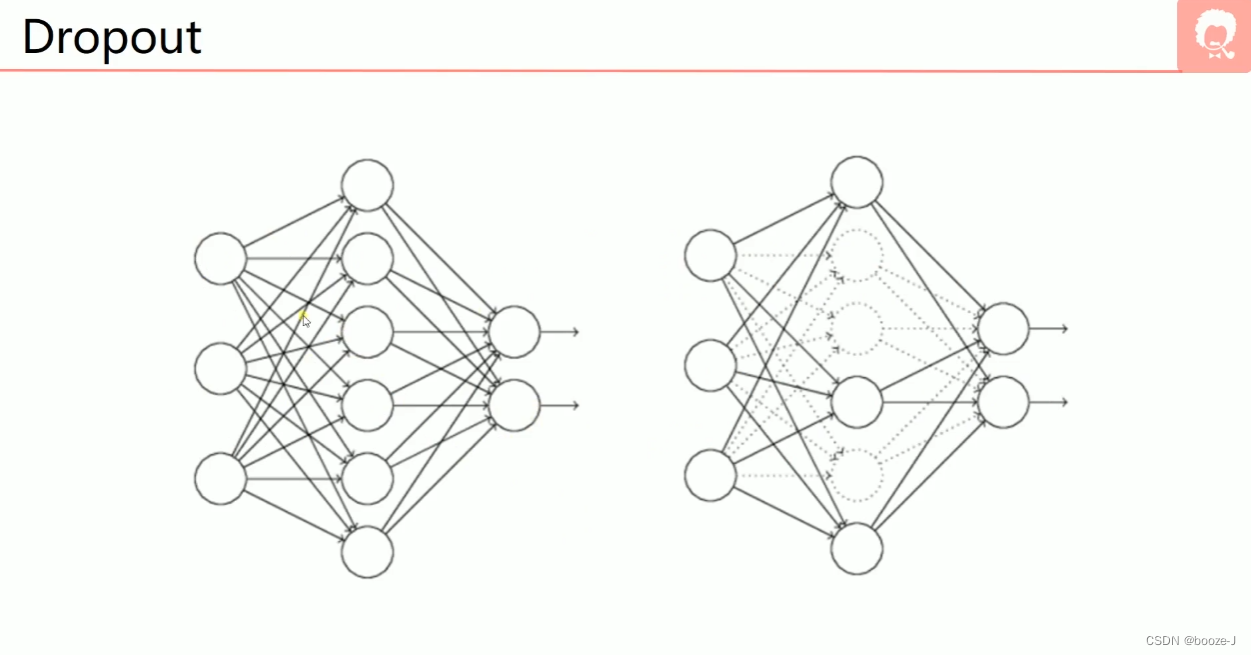
每次训练的时候,都会随机的去关闭一些神经元,关闭的意思并不是去掉,而是这些画虚线的神经元不参与训练。注意一般训练完,测试模型的时候,是使用所有神经元,不会进行dropout。4.正则化
C0代表原始的代价函数,n代表样本的个数, λ \lambda λ就是正则项系数,权衡正则项与C0项的比重。
L1正则化: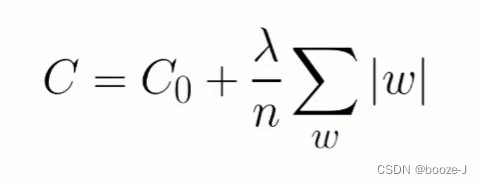
L1正则化可以达到模型参数稀疏化的效果。L2正则化:

L2正则化可以使得模型的权值衰减,使模型参数值都接近于0。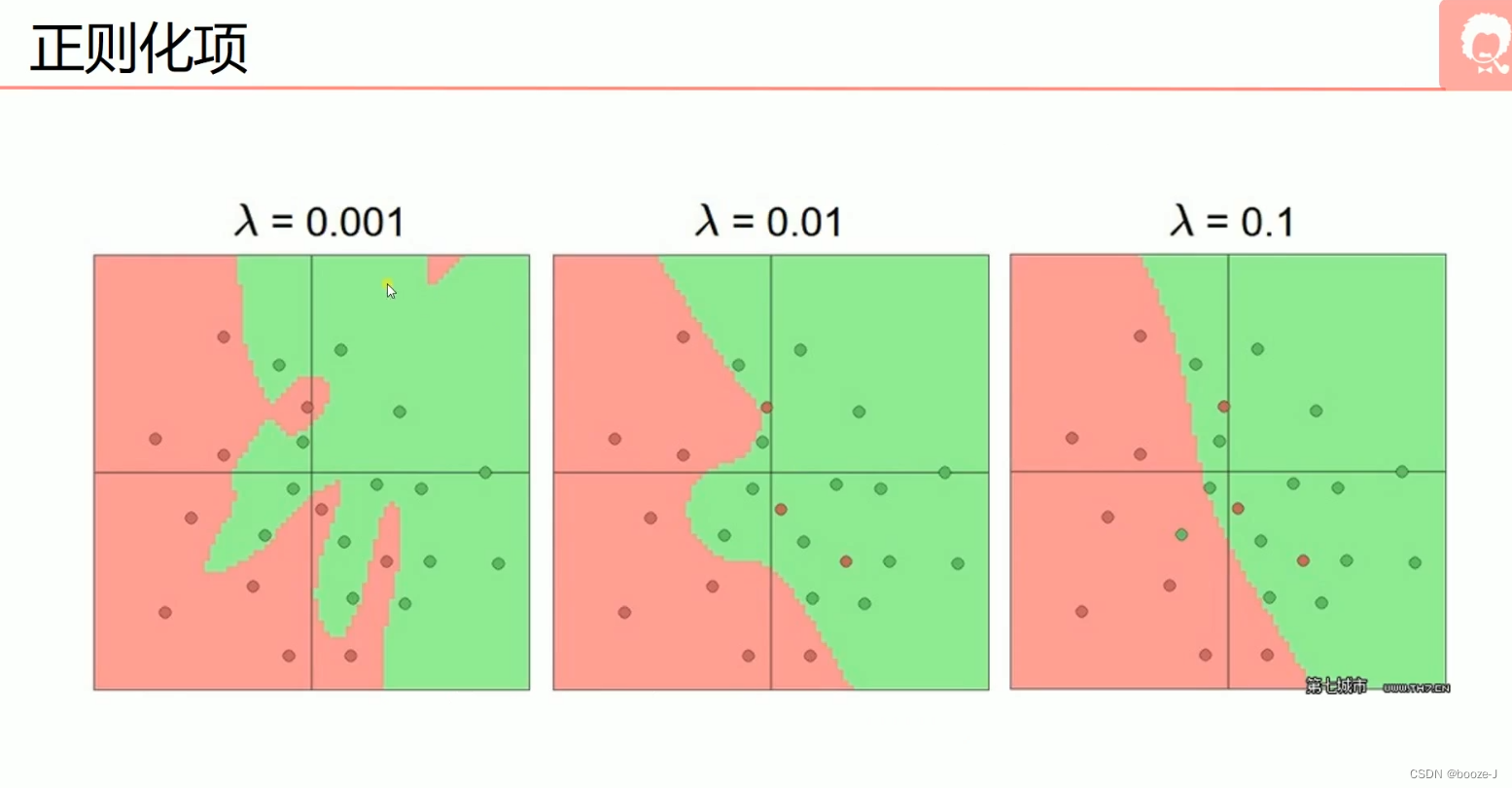
当 λ \lambda λ=0.001时,出现了过拟合现象,当 λ \lambda λ=0.01时,有较轻微的过拟合,当 λ \lambda λ=0.1的时候没有出现过拟合现象。 -
相关阅读:
一个简单的HTML网页 故宫学生网页设计作品 dreamweaver作业静态HTML网页设计模板 旅游景点网页作业制作
Windows 查找端口占用及端口范围详解
Dapr 远程调试之 Nocalhost
红外遥控视力自动检测系统的设计与实现
如何快速上手一个新项目?
(done) 两个矩阵 “相似” 是什么意思?
Masa Blazor in Blazor Day
php file_get_contents https 请求 伪造user_agent
软件开发人员 Kubernetes 入门指南|Part 2
图解关系数据库设计思想,这也太形象了
- 原文地址:https://blog.csdn.net/booze_/article/details/125632017