-
Python 批量汉字转五笔,Word输出为Excel
背景: 最近在学习五笔,但是对于一个小白来说,在面对大量的汉字的情况下,没办法知道一个个字怎么用五笔打出来,几个就算了,但成百上千个,总不能一个个去查吧,那一天时间都花在了查上,为了方便去记忆学习,就写了个Python程序来对汉字进行批量的转换,再慢慢的去学习。
目的: 将word中的字,转换成excel文件,包含源字、五笔简码,即使word中有上万个字,也仅需几秒完成所有汉字的转换,达到一劳永逸的结果。
最终效果:

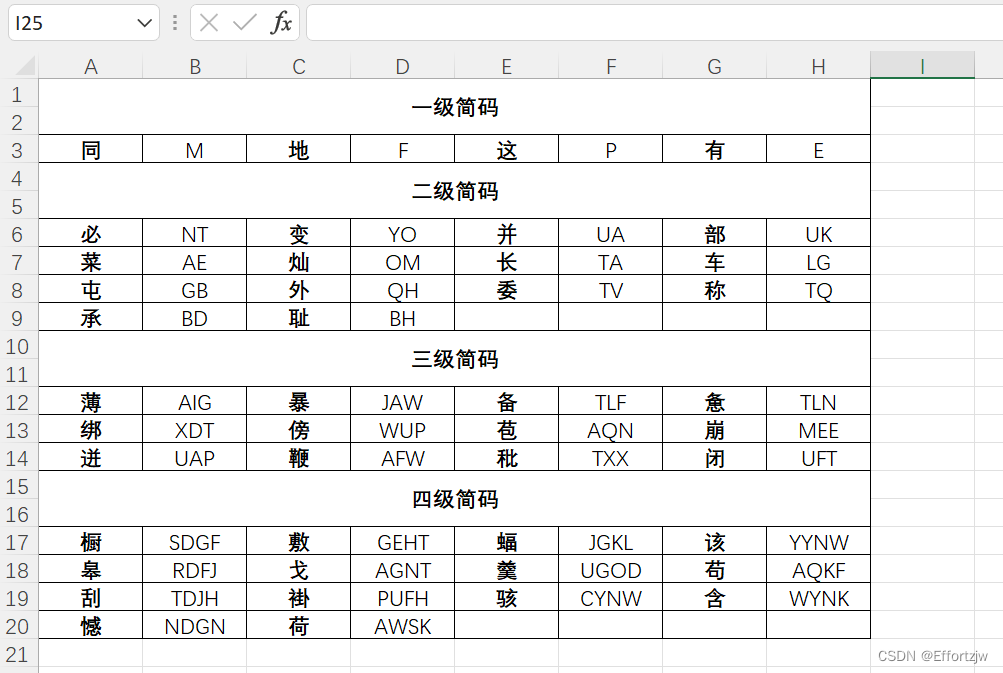
使用到的Python库:
pywubi -> 将汉字转换为五笔
docx -> 处理word文件
openpyxl -> 处理Excel文件安装:
pip3 install pywubi
pip3 install docx
pip3 install openpyxl五笔示例:
from pywubi import wubi print(wubi('我')) >>>['trnt'] # 返回汉字的所有可能的五笔编码 print(wubi('我',multicode=True)) >>>[['trnt', 'trn', 'q']]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
有了以上的示例,那就简单了,想要最简码,只需要处理下所有可能的五笔编码,取最短结果,然后读取Word文件,输出Excel文件,格式再美化一下即可。
源码:
from pywubi import wubi import time import docx import os import openpyxl start_time = time.time() # 处理文字最简码 def hanToWuBi(str): l = len(str[0][0]) ans = str[0][0] for s in str[0]: if len(s) < l: l = len(s) ans = [s, len(s)] #最简码、长度 return ans file=docx.Document('字库.docx') d_ziku = {} for i in file.paragraphs: # 读取Wold中的文字 txt = i.text for t in txt: # 遍历转换 d_ziku[t] = [hanToWuBi(wubi(t,multicode=True))[0].upper(),hanToWuBi(wubi(t,multicode=True))[1]] d_wubi_1 = {} # 一级简码字典 d_wubi_2 = {} # 二级简码字典 d_wubi_3 = {} # 三级简码字典 d_wubi_4 = {} # 四级简码字典 for key in d_ziku.keys(): if d_ziku[key][1] == 1: d_wubi_1[key] = d_ziku[key][0] elif d_ziku[key][1] == 2: d_wubi_2[key] = d_ziku[key][0] elif d_ziku[key][1] == 3: d_wubi_3[key] = d_ziku[key][0] elif d_ziku[key][1] == 4: d_wubi_4[key] = d_ziku[key][0] arr = [] v = [] indexArr = 1 for key in d_wubi_1.keys(): if indexArr % 4 != 0: #4个一行 v = v + [key,d_wubi_1[key]] indexArr += 1 else: v = v + [key, d_wubi_1[key]] arr.append(v) indexArr = 1 v = [] arr.append(v) arr.append(['','','','','','','','']) indexArr = 1 v = [] for key in d_wubi_2.keys(): if indexArr % 4 != 0: v = v + [key,d_wubi_2[key]] indexArr += 1 else: v = v + [key, d_wubi_2[key]] arr.append(v) indexArr = 1 v = [] arr.append(v) arr.append(['','','','','','','','']) v = [] indexArr = 1 for key in d_wubi_3.keys(): if indexArr % 4 != 0: v = v + [key,d_wubi_3[key]] indexArr += 1 else: v = v + [key, d_wubi_3[key]] arr.append(v) indexArr = 1 v = [] arr.append(v) arr.append(['','','','','','','','']) v = [] indexArr = 1 for key in d_wubi_4.keys(): if indexArr % 4 != 0: v = v + [key,d_wubi_4[key]] indexArr += 1 else: v = v + [key, d_wubi_4[key]] arr.append(v) indexArr = 1 v = [] arr.append(v) arr.append(['','','','','','','','']) # 将结果输出到Excel中 wb = openpyxl.load_workbook('字库.xlsx',data_only=True) ws = wb.worksheets[0] for x in arr: ws.append(x) wb.save('字库结果-排序版.xlsx') end_time = time.time() all_time = end_time - start_time print('共执行:%s 秒' % all_time)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
-
相关阅读:
如何PDF转Word文档?两分钟教你三个方法
python安装
基于SSM的住院病人监测预警信息管理系统毕业设计源码021054
Java中如何检测HashMap中是否存在指定Key呢?
刷题11.27
【算法刷题日记之本手篇】微信红包与计算字符串的编辑距离
八股文第十三天
Python滑动窗口算法:滑动窗口算法(4 by 4 sliding window price)
【帧率倍频】基于FPGA的视频帧率倍频系统verilog开发实现
BluePrism里WorkQueue的几种传法和区别
- 原文地址:https://blog.csdn.net/qq_33966519/article/details/125629317