-
C语言指针(习题篇)
🐱作者:一只大喵咪1201
🐱专栏:《C语言学习》
🔥格言:你只管努力,剩下的交给时间!

经过前面四篇文章对指针详细讲解,相信各位小伙伴已经了解到了各种各样的指针以及它们的使用方法,下面本喵带着大家做一些习题来检验下学习成果吧。
🐨指针和数组
🐼一维数组
习题一:
#include <stdio.h> int main() { int a[] = { 1,2,3,4 }; printf("%d\n", sizeof(a)); printf("%d\n", sizeof(a + 0)); printf("%d\n", sizeof(*a)); printf("%d\n", sizeof(a + 1)); printf("%d\n", sizeof(a[1])); printf("%d\n", sizeof(&a)); printf("%d\n", sizeof(*&a)); printf("%d\n", sizeof(&a + 1)); printf("%d\n", sizeof(&a[0])); printf("%d\n", sizeof(&a[0] + 1)); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
我们知道,
一维数组的数组名的本质是数组首元素的地址。
但是有俩个特例- &数组名
- sizeof(数组名)
这俩个特例中,数组名表示的是整个数组。
知道了这个知识点后便可以解决上面的代码,上面代码的输出结果是什么呢?可以自己尝试着做一下。
下面本喵进行一下详细的分析。- 首先创建了一个一维数组
int a[] = { 1,2,3,4 };- 1
该数组有4个元素,每个元素的整型。
printf("%d\n", sizeof(a));- 1
操作符sizeof中的操作数只有数组名,所以此时求的是整个数组所占内存空间的大小,结果是16,也就是16个字节。
printf("%d\n", sizeof(a + 0));- 1
- 操作数是数组名加一个整型0,所以不是单独的一个数组名,此时数组名的本质就是数组首元素的地址。
- 首元素地址加一个0得到的还是首元素的地址。
- 首元素的地址是一个int*类型的指针变量,所以其结果是4或者8,在32位平台上是4,在64位平台上是8。
printf("%d\n", sizeof(*a));- 1
- 操作数是数组名解引用,不是单独的数组名。
- 此时数组名的本质是数组首元素的地址。
- 对首元素地址解引用后得到的是数组中第一个元素。
- 所以它的大小是一个整型的大小,结果是4。
printf("%d\n", sizeof(a + 1));- 1
- 操作数是数组名加整型1,不是单独的数组名
- 此时数组名的本质是数组首元素的地址。
- 加1后变成了数组中第二个元素的地址,也就是元素2的地址。
- 该地址是int*类型的指针变量。
- 所以大小是4或者8个字节(32位平台是4,64位平台是8)。
printf("%d\n", sizeof(a[1]));- 1
- 操作数是数组中下标为1的元素,也就是第二个元素。
- 其大小是4个字节,所以结果是4。
printf("%d\n", sizeof(&a));- 1
- 操作数是&数组名,此时取出的是整个数组的地址。
- 该地址的数据类型是int (*)[4],是一个数组指针变量类型。
- 归根到底还是一个地址,所以结果是4或者8。
printf("%d\n", sizeof(*&a));- 1
- 操作数是*&a。
- 解引用操作符*和取地址操作符&相互抵消,剩下的只有数组名。
- sizeof的操作数只有数组名时,其本质是整个数组。
- 结果是16。
printf("%d\n", sizeof(&a + 1));- 1
- 操作数是&a+1
- &a得到的是整个数组的地址,该指针针的类型是int (*)[4]。
- 加1后跳过了整个数组,指向了内存中下一个int (*)[4]的地址。

- 归根到底还是一个地址,所以结果是4或者8。
printf("%d\n", sizeof(&a[0]));- 1
- 操作数是&a[0]。
- a[0]得到的是数组中的第一个元素,再对其取地址。
- 得到的就是数组首元素的地址。
- 所以结果是4或者8。
printf("%d\n", sizeof(&a[0] + 1));- 1
- 操作数是&a[0]+1。
- &[0]得到的是数组首元素的地址。
- 加1后得到的是数组中第二个元素的地址
- 数据类型是int*类型的指针变量。
- 所以结果是4或者8。
综合上面的分析,由于本喵使用的编译器是32位的,将每行代码所分析的结果注释到对应代码的后面

可以看到输出的结果与我们所分析的一致。🐼字符数组
习题一:
int main() { char arr[] = { 'a','b','c','d','e','f' }; printf("%d\n", sizeof(arr)); printf("%d\n", sizeof(arr + 0)); printf("%d\n", sizeof(*arr)); printf("%d\n", sizeof(arr[1])); printf("%d\n", sizeof(&arr)); printf("%d\n", sizeof(&arr + 1)); printf("%d\n", sizeof(&arr[0] + 1)); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
char arr[] = { 'a','b','c','d','e','f' };- 1
这是一个字符数组,数组中有6个元素。
printf("%d\n", sizeof(arr));- 1
- 操作数是数组名。
- 此时数组名的本质是整个数组。
- 所以结果是整个数组的大小,结果是6。
printf("%d\n", sizeof(arr + 0));- 1
- 操作数是arr+0
- 并不是一个单独的数组名,此时数组名的本质是数组首元素的地址
- 加0后仍然是数组首元素的地址
- 该地址是char*类型的指针
- 结果是4或者8
printf("%d\n", sizeof(*arr));- 1
- 操作数是*arr,不是单独的数组名
- 此时数组名的本质是数组首元素的地址
- 解引用后得到的是数组中的第一个元素
- 该元素的数据类型是char类型
- 结果是1
printf("%d\n", sizeof(arr[1]));- 1
- 操作数是arr[1]
- 得到是数组中下标为1的元素
- 该元素的数据类型是char类型
- 结果是1
printf("%d\n", sizeof(&arr));- 1
- 操作数是&arr,取出的是整个数组的地址
- 数据类型是char (*)[6],是一个数组指针
- 归跟到底还是一个地址
- 结果是4或者8
printf("%d\n", sizeof(&arr + 1));- 1
- 操作数是&arr+1
- &arr取出的是整个数组的地址,是一个数据类型是char (*)[6]类型的指针
- 加1后跳过了整个数组,指向了下一个char (*)[6]类型数组的地址
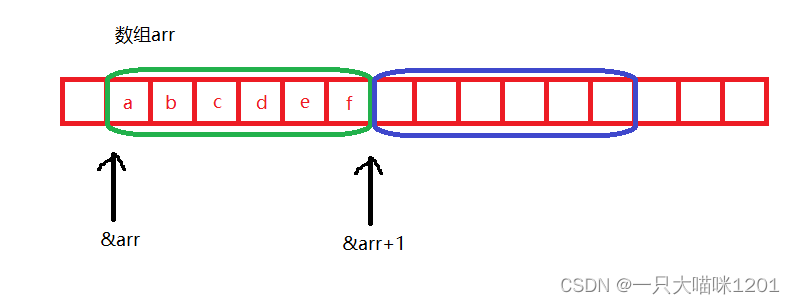
- 下一个数组的地址归根到底还是一个地址
- 结果是4或者8
printf("%d\n", sizeof(&arr[0] + 1));- 1
- 操作数是&arr[0]+1
- &arr[0]得到的是数组首元素的地址
- 加1后得到的是数组中第二个元素的地址
- 数据类型是char*类型的指针
- 所以结果是4
综合上面的分析,由于本喵使用的编译器是32位的,将每行代码所分析的结果注释到对应代码的后面

可以看到输出的结果与我们所分析的一致。习题二:
#include <string.h> int main() { char arr[] = { 'a','b','c','d','e','f' }; printf("%d\n", strlen(arr)); printf("%d\n", strlen(arr + 0)); printf("%d\n", strlen(*arr)); printf("%d\n", strlen(arr[1])); printf("%d\n", strlen(&arr)); printf("%d\n", strlen(&arr + 1)); printf("%d\n", strlen(&arr[0] + 1)); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 这段代码中使用的是strlen()库函数来求字符串的长度。
- strlen库函数的本质是寻找字符串中的字符结束标志\0
- 然后将\0之前的字符个数统计出来
char arr[] = { 'a','b','c','d','e','f' };- 1
这是一个字符数组,有6个元素,每个元素都是char类型的。
printf("%d\n", strlen(arr));- 1
- 实参是arr,并不是特例中的情况
- 此时数组名的本质是数组首元素的地址
- 由于该数组中没有\0,所以strlen函数找不到统计结束的标志
- 所以结果是一个随机数,但是这个随机数一定大于等于6
printf("%d\n", strlen(arr + 0));- 1
- 实参是arr+0
- arr是数组首元素的地址,加0后仍然是数组首元素的地址
- 所以结果与上语句代码的结果一样
printf("%d\n", strlen(*arr));- 1
- 实参是*arr
- 此时的arr是数组首元素的地址
- 解引用后得到的是数组中的第一个元素,也就是字符’a’
- 此时将字符a当作是一个地址传参给了strlen库函数
- 因为字符a的ASCII码值是97,所以相当于传参了一个char*类型的指针,其值是97
- 地址为97的内存空间是供内核使用的,用户没有访问权限,所以编译器就会报错。

- 十进制97转化成16进制后便是61
- 报错内容中告诉我们访问地址0x00000061时发生错误
- 就是说这个内存空间是不允许我们访问的
printf("%d\n", strlen(arr[1]));- 1
- 实参是arr[1]
- 得到的是数组中第二个元素,也就是’b’
- 字符b的ASCII码值是98,转化成16进制后是62
- 与上面的代码一样,同样是将62作为地址传给了strlen库函数
- 而0x00000062的内存空间同样是不可访问的,也会报错

printf("%d\n", strlen(&arr));- 1
- 实参是&arr,是特例中的一种情况
- 取出的是整个数组的地址
- 但是整个数组的地址表现形式就是数组首元素的地址,其值与arr一样
- 虽然&arr的数据类型是char (* )[6],但是在传给strlen库函数后会被强制转化成为cahr* 类型的指针
- 所以结果也是一个随机值,结果大于等于6,与第一个输入语句结果相同。
printf("%d\n", strlen(&arr + 1));- 1
- 实参是&arr+1
- &arr取出的是整个数组的地址
- 加一后就跳过了该数组,指向了下一个char (*)[6]类型数组的地址

- 由于并不知道此时指向数组中的元素分布情况,所以得出的结果是一个随机值。
printf("%d\n", strlen(&arr[0] + 1));- 1
- 实参是&arr[0]+1
- &arr[0]得到的是数组首元素的地址
- 加1后得到的是数组第二个元素的地址
- 将此地址传给strlen库函数后,由于没有\0,所以仍然不知道要统计到哪里结束
- 但是这个随机值要必上面的随机值小一个数。
综合上面的分析,将每行代码所分析的结果注释到对应代码的后面

结果与我们所分析的一致。
该代码在指向过程中会报一些警告,我们直接忽略就好了,有兴趣的小伙伴可以尝试修复一下。习题三:
int main() { char arr[] = "abcdef"; printf("%d\n", sizeof(arr)); printf("%d\n", sizeof(arr + 0)); printf("%d\n", sizeof(*arr)); printf("%d\n", sizeof(arr[1])); printf("%d\n", sizeof(&arr)); printf("%d\n", sizeof(&arr + 1)); printf("%d\n", sizeof(&arr[0] + 1)); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
char arr[] = "abcdef";- 1
这是一个字符串数组,数组中有7个元素,每个元素都是char类型。
相当于char arr[] = { 'a','b','c','d','e','f','\0' };- 1
printf("%d\n", sizeof(arr));- 1
- 操作数是arr,只有一个数组名
- 此时arr的本质是整个数组
- 所以结果是7
printf("%d\n", sizeof(arr + 0));- 1
- 操作数是arr+0,不是单独的一个数组名
- 此时arr的本质是数组首元素的地址
- 加0后仍然是数组首元素的地址
- 该地址是char*类型的指针
- 所以结果是4或者8
printf("%d\n", sizeof(*arr));- 1
- 操作数是*arr,不是单独的数组名
- 此时arr的本质是数组首元素的地址
- 解引用后得到的是数组中的第一个元素
- 所以结果是1
printf("%d\n", sizeof(arr[1]));- 1
- 操作数是arr[1]
- 得到的是数组中下标为1的元素,也就是第二个元素
- 所以结果是1
printf("%d\n", sizeof(&arr));- 1
- 操作数是&arr,取出的是整个数组的地址
- 该地址是一个char (*)[7]类型的指针
- 归根到底还是一个指针
- 所以结果是4或者8
printf("%d\n", sizeof(&arr + 1));- 1
- 操作数是&arr+1
- &arr取出的是整个数组的地址
- 加1后跳过了该数组,指向下一个char (*)[7]的地址

- 此时的地址仍然是一个指针
- 所以结果是4或者8
printf("%d\n", sizeof(&arr[0] + 1));- 1
- 操作数是&arr[0]+1
- &arr[0]得到的是数组首元素的地址
- 加1后得到的是数组中第二个元素的地址
- 该地址的是数据类型是char*
- 所以结果是4或者8
综合上面的分析,由于本喵使用的编译器是32位的,将每行代码所分析的结果注释到对应代码的后面

可以看到,与我们所分析的结果一致。
习题四:int main() { char arr[] = "abcdef"; printf("%d\n", strlen(arr)); printf("%d\n", strlen(arr + 0)); printf("%d\n", strlen(*arr)); printf("%d\n", strlen(arr[1])); printf("%d\n", strlen(&arr)); printf("%d\n", strlen(&arr + 1)); printf("%d\n", strlen(&arr[0] + 1)); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
char arr[] = "abcdef";- 1
这是一个数组,有7个元素,每个元素都是char类型。
printf("%d\n", strlen(arr));- 1
- 实参是arr
- 此时的arr的本质是数组首元素地址
- 将arr传参给strlen库函数后,便从这里开始统计字符个数,直到\0结束统计
- 所以结果就是字符的个数,但是不包括\0
- 所以结果是6
printf("%d\n", strlen(arr + 0));- 1
- 实参是arr+0
- 此时arr的本质是数组首元素地址
- 加0后仍然是数组首元素地址
- 所以结果与上面语句的结果一样,也是6
printf("%d\n", strlen(*arr));- 1
- 实参是*arr
- 此时arr的本质是数组首元素地址
- 解引用后得到的是数组中的第一个元素,也就是’a’
- 字符a的ASCII码值是97
- 此时相当于将地址为97的指针传参给类strlen库函数
- 该地址转化成16进制后是0x00000061
- 该地址是不允许访问的,所以在执行的时候会报错
- 具体结果和前面习题中报错的错过一样
printf("%d\n", strlen(arr[1]));- 1
- 实参是arr[1]
- 得到的是数组中第二个元素,也就是’b’
- 字符b的ASCII码值是98
- 同样是相当与将地址98,也就是0x00000062传参给了strlen
- 在执行的时候也会报错
printf("%d\n", strlen(&arr));- 1
- 实参是&arrr,取出的是整个数组的地址
- 此时实参的数据类型是char (*)[7]
- 将该类型的指针传参给strlen库函数后会被强制转换为char*类型的指针
- 虽然是整个数组的地址,但是它的值和数组首元素地址相同
- 所以也是从字符a开始统计字符的个数,直到遇到\0
- 所以结果是6
printf("%d\n", strlen(&arr + 1));- 1
- 实参是&arr+1
- &arr取出的是整个数组的地址
- 加1后跳过了该数组,指向了下一个char (*)[7]类型的地址

- 由于不知道该数组后面的元素分布情况
- 所以结果是一个随机值
printf("%d\n", strlen(&arr[0] + 1));- 1
- 实参是&arr[0]+1
- &arr[0]取出的是数组首元素的地址
- 加1后得到是数组中第二个元素的地址
- 将该地址传参给strlen库函数后
- 便从第二个元素开始统计字符的个数,直到\0结束
- 所以结果是5
综合上面的分析,将每行代码所分析的结果注释到对应代码的后面

可以看到,与我们所分析的结果一致。习题五:
int main() { char* p = "abcdef"; printf("%d\n", sizeof(p)); printf("%d\n", sizeof(p + 1)); printf("%d\n", sizeof(*p)); printf("%d\n", sizeof(p[0])); printf("%d\n", sizeof(&p)); printf("%d\n", sizeof(&p + 1)); printf("%d\n", sizeof(&p[0] + 1)); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
char* p = "abcdef";- 1
- 字符串存在内存中的常量区,它们也有地址
- 该语句是将字符串中字符a的地址符给了指针变量p
printf("%d\n", sizeof(p));- 1
- 操作数是p
- p是一个指针变量
- 其实质是sizeof(char*)
- 所以结果是4或者8
printf("%d\n", sizeof(p + 1));- 1
- 操作数是p+1
- 此时变量p中的值是字符b的地址
- 所以结果是4或者8
printf("%d\n", sizeof(*p));- 1
- 操作数是*p
- p中的值是字符a的地址
- 解引用后得到是字符a
- 所以结果是1
printf("%d\n", sizeof(p[0]));- 1
- 操作数是p[0]
- p[0]可以写成*(p+0)
- p中的值是字符a的地址
- 加0后仍然是a的地址
- 解引用后得到字符a
- 所以结果是1
printf("%d\n", sizeof(&p));- 1
- 操作数是&p
- 数据类型是char** 的一个二级指针
- 归根到底还是一个指针
- 所以结果是4或者8
printf("%d\n", sizeof(&p + 1));- 1
- 操作数是&p+1
- &p得到的是一个二级指针
- 加1后是对二级指针加1,但是它仍然是一个指针
- 所以结果是4或者8
printf("%d\n", sizeof(&p[0] + 1));- 1
- 操作数是&p[0]+1
- p[0]可以写成*(p+0)
- p中的值是字符a的地址
- 加0后仍然是字符a的地址
- 解引用后得到的是字符a
- 再对字符a取地址,得到的是字符a的地址
- 再加1后得到的是字符b的地址
- 仍然是一个地址
- 所以结果是4或者8
综合上面的分析,由于本喵使用的编译器是32位的,将每行代码所分析的结果注释到对应代码的后面

习题六:int main() { char* p = "abcdef"; printf("%d\n", strlen(p)); printf("%d\n", strlen(p + 1)); printf("%d\n", strlen(*p)); printf("%d\n", strlen(p[0])); printf("%d\n", strlen(&p)); printf("%d\n", strlen(&p + 1)); printf("%d\n", strlen(&p[0] + 1)); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
char* p = "abcdef";- 1
同样是将字符a的地址赋值给了指针变量p。
printf("%d\n", strlen(p));- 1
- 实参是p,放的值是字符a的地址
- 传参给strlen库函数后便向后统计字符的个数,直到\0结束,但是不包括\0
- 所以结果是6
printf("%d\n", strlen(p + 1));- 1
- 实参是p+1
- p中的值是字符a的地址
- 加1后就变成了字符b的地址
- 传参给strlen库函数后便从字符b开始统计字符个数,直到\0结束
- 所以结果是5
printf("%d\n", strlen(*p));- 1
- 实参是*p
- p中是字符a的地址
- 解引用后得到的是字符a
- 字符a的ASCII码值是97,转换成16进制后是61
- 相当于将字符a当作地址传参给strlen库函数,也就是传的0x00000061
- 而该地址是不允许用户访问的
- 所以编译的结果会报错

printf("%d\n", strlen(p[0]));- 1
- 实参是p[0]
- 可以写成*(p+0)
- p中放的是字符a的地址
- 加0后仍然是字符a的地址
- 解引用后得到的是字符a
- 所以结果和上面的输出语句是一样的,也会报错
printf("%d\n", strlen(&p));- 1
- 实参是&p
- p中放的是字符a的地址
- 取地址后得到的是一个变量类型为char**的二级指针

- 红色方框是字符串的存放空间
- 蓝色方块是指针变量p,其值是字符a的地址,假设它是0x0012ff40
- 绿色方块是&p,也就是二级指针变量,其值是一级指针变量p的地址,假设是0x0034ff23

本喵使用的编译器是32位的,且是按照小端字节序存储方式存储的 - p变量是一个一级指针变量,其大小是4个字节,里面放的是字符a的地址
- p中的地址在内存中存储的样子如上图中的蓝色框框
- &p得到的是指针变量p的地址,该地址的值与指针变量p中四个字节里低字节序字节的地址相同
- 将该地址传参给strlen库函数后又被强制转换成了char*类型的地址
- 所以每次加1只向后跳一个字节
- 所以再统计的时候会将指针变量p中的值也当作是字符统计,如40,ff,12,当遇到00的时候便结束了统计
- 所以输出的结果是一个随机值
printf("%d\n", strlen(&p + 1));- 1
- 实参是&p+1
- &p和上面的一样,得到的是一个二级指针
- 而加1后就会跳过一个二级指针类型,也就是跳过四个字节

- 此时的二级指针是存放在下一个内存空间中的
- 将该二级指针传参给strlen库函数后,便从此开始统计字符个数
- 由于不知道在哪里停止,所以结果是一个随机值
printf("%d\n", strlen(&p[0] + 1));- 1
- 实参是&p[0]+1
- p[0]可以写成*(p+0)
- p中放的是字符a的地址
- 加0后仍然是a的地址
- 解引用后得到的是字符a
- 再对字符a取地址后加1
- 得到的是字符b的地址
- 将此地址传参给strlen库函数后便开始向后统计字符个数,直到\0结束
- 所以结果是5
注意
- 最后的俩个随机值之间没有必然的联系,都是随机的。
综合上面的分析,由于本喵使用的编译器是32位的,将每行代码所分析的结果注释到对应代码的后面

可以看到,所得结果与我们分析的一致。🐼二维数组
习题一:
int main() { int a[3][4] = { 0 }; printf("%d\n", sizeof(a)); printf("%d\n", sizeof(a[0][0])); printf("%d\n", sizeof(a[0])); printf("%d\n", sizeof(a[0] + 1)); printf("%d\n", sizeof(*(a[0] + 1))); printf("%d\n", sizeof(a + 1)); printf("%d\n", sizeof(*(a + 1))); printf("%d\n", sizeof(&a[0] + 1)); printf("%d\n", sizeof(*(&a[0] + 1))); printf("%d\n", sizeof(*a)); printf("%d\n", sizeof(a[3])); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
int a[3][4] = { 0 };- 1
这是一个三行四列的二维数组,初始化全部为0,每个元素的类型都是整型
printf("%d\n", sizeof(a));- 1
- 操作数是a,单独的数组名
- 此时数组名的本质是整个数组
- 所以结果是整个数组所占内存空间的大小
- 结果是48
printf("%d\n", sizeof(a[0][0]));- 1
- 操作数是a[0][0]
- 得到是第0行第0列的元素
- 所以结果是4
printf("%d\n", sizeof(a[0]));- 1
- 操作数是a[0]
- a[0]只有行标没有列标
- 二维数组可以看成是每个元素是一维数组的一维数组
- a[0]就代表首行数组的数组名
- 由于只有单独的一个数组名,所以代表整个首行数组
- 所以结果是16
printf("%d\n", sizeof(a[0] + 1));- 1
- 操作数是a[0]+1
- a[0]代表的是首行一维数组的数组名,且不是单独的数组名
- a[0]的本质是首行数组的首元素地址
- 加1后得到的是首数组的第二个元素的地址,也就是a[0][1]元素的地址
- 其是一个int*类型的指针变量
- 所以结果是4或者8
printf("%d\n", sizeof(*(a[0] + 1)));- 1
- 操作数是*(a[0]+1)
- 根据上面语句的分析我们知道a[0] +1得到的是第0行第1列的元素的地址
- 解引用后就得到了a[0][1]
- 所以结果是4
printf("%d\n", sizeof(a + 1));- 1
- 操作数是a+1
- 二维数组的数组名的实质是首行元素的地址
- 此时a是一个数组指针,其类型是int (*)[4]
- 加1后指向了第二行元素
- 其类型仍然是int (*)[4]
- 归根到底其还是一个地址
- 所以结果是4或者8
printf("%d\n", sizeof(*(a + 1)));- 1
- 操作数是*(a+1)
- 由对上面语句的分析我们知道a+1得到的是第二行元素的地址
- 对其解引用后得到的是第二行整个一维数组
- 所以其结果就是第二行一维数组的大小
- 结果是16
printf("%d\n", sizeof(&a[0] + 1));- 1
- 操作数是&a[0]+1
- a[0]是首行一维数组的数组名
- 对其取地址&a[0]得到的是整个首行的一维数组的地址,类型是int (*)[4]
- 再加1后得到的是第二行一维数组的地址,同样是一个数组指针
- 归根到底还是指针
- 所以结果是4或者8
printf("%d\n", sizeof(*(&a[0] + 1)));- 1
- 操作数是*(&a[0]+1)
- 根据上面的分析我们知道&a[0]+1得到的是第二行整个一维数组的地址
- 解引用后得到的是第二行的整个一维数组
- 所以结果是第二行数据所占的内存空间
- 结果是16
printf("%d\n", sizeof(*a));- 1
- 操作数是*a,不是单独的数组名
- 此时数组名a的本质是数组首行元素的地址,是一个int (*)[4]类型的指针
- 对首行元素的地址解引用得到的就是首行元素
- 所以结果是16
printf("%d\n", sizeof(a[3]));- 1
- 操作数是a[3]
- a[3]表示的是第四行一维数组的数组名
- 由于代码中的数组是3行4列的,所以这里的第4行已经越界访问

- 数组虽然越界了,但是指向数组只外的那一行也是一个4列的一维数组
- 此时相当于只有数组名单独出现
- 所以结果是16
综合上面的分析,由于本喵使用的编译器是32位的,将每行代码所分析的结果注释到对应代码的后面

可以看到,结果与我们分析的一致。🐨指针笔试题
- 笔试题1:
int main() { int a[5] = { 1, 2, 3, 4, 5 }; int* ptr = (int*)(&a + 1); printf("%d,%d", *(a + 1), *(ptr - 1)); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7

- 绿色框框内是数组a在内存中的分布
- 数组名a是数组首元素的地址,也就是元素1的地址
- &a得到的是整个数组的地址,是一个int (*)[5]的数组指针
- &a+1跳过了整个数组a,指向了后面另一个同样大小的数组
- 将此时的数组指针强制类型转换成为int*的指针,并赋值给指针变量ptr
- 此时ptr-1向左移动了一个int类型,也就是4个字节,指向了元素5的地址
- a的本质是数组首元素的地址
- 加1后得到的是数组中第二个元素的地址,也就是元素2的地址
printf("%d,%d", *(a + 1), *(ptr - 1));- 1
- 对a+1解引用得到的是元素2
- 对ptr-1解引用得到的是元素5
- 所以结果是2,5

与我们所分析的一致。- 笔试题2:
struct Test { int Num; char* pcName; short sDate; char cha[2]; short sBa[4]; }*p = 0x10000000; int main() { printf("%p\n", p + 0x1); printf("%p\n", (unsigned long)p + 0x1); printf("%p\n", (unsigned int*)p + 0x1); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 创建了一个结构体,以32位的机器为例,该结构体所占内存空间大小是20个字节
- 用一个结构体指针变量指向该结构体,此时指针变量p中放的就是结构体所在的地址
printf("%p\n", p + 0x1);- 1
- p中放的是结构体的地址,0x10000000
- 加0x1后相当于加1,跳过的是整个结构体,也就是加20
- 转换成16进制后结果是0x10000014
printf("%p\n", (unsigned long)p + 0x1);- 1
- 将指针变量p强制类型转换位unsigned long类型
- 此时p中的值便不再是结构体的地址,而是一个无符号的长整型数字
- 加0x1后,也就是加1后,就是在进行算术运算
- 所以结果是0x10000001
printf("%p\n", (unsigned int*)p + 0x1);- 1
- 将指针变量p强制类型转换位unsigned int*类型
- 此时p中的值便不再是结构体的地址,而是一个unsgined int*类型的指针变量,它的值是一个指向unsigned int类型数据的地址。
- 加0x1后,也就是加1后,跳过的是一个unsigned int类型的数据,也就是4个字节
- 所以结果是0x10000004

可以看到,与我们分析的结果一致。
在运行过程中会报警告,但是并不影响我们结果的输出。- 笔试题3:
int main() { int a[4] = { 1, 2, 3, 4 }; int* ptr1 = (int*)(&a + 1); int* ptr2 = (int*)((int)a + 1); printf("%x,%x", ptr1[-1], *ptr2); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

- 以VS2019为例
- 按照小端字节序存储方式储存数据
- 是32位的平台
- 如上图,数组名a的本质是数组首元素的地址,指向的是第一个元素的地址
- 又因为是小端字节序储存,所以首元素的地址就是首元素中最低字节01的地址
int* ptr1 = (int*)(&a + 1);- 1
- 原本a的数据类型是int*类型的指针,强制类型转换位整型,此时它的意义便不再是指针,而是一个数字
- 加1后是在进行算术运算,其值增加1
- 将其结果再强制类型转换为int*类型的指针变量
- 此时该指针指向的是第一个元素四个字节中第二低字节序字节的地址,如上图中的00
- 将该地址赋值给指针变量ptr2
int* ptr1 = (int*)(&a + 1);- 1
- &a得到是整个数组的地址
- 加1后跳过的是整个数组,此时该指针指向的是下一个int (*)[4]类型的地址
- 将该指针强制类型转换为int*类型后赋值给指针变量ptr1
printf("%x,%x", ptr1[-1], *ptr2);- 1
- ptr1[-1]可以写成*(ptr1-1)
- ptr1-1得到的值指向数组中的最后一个元素4的地址
- 解引用后得到元素4
- ptr2解引用后得到的是从ptr2开始往后的4个字节组成的int类型的数据
- 由于是小端字节序存储方式
- 所以去出后该int类型的数据是02 00 00 00
- 按照16进制打印
- 所以结果是2000000
- 所以最后的结果是4,2000000

可以看到与我们分析的结果一致。- 笔试题4:
#include <stdio.h> int main() { int a[3][2] = { (0, 1), (2, 3), (4, 5) }; int* p; p = a[0]; printf("%d", p[0]); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
int a[3][2] = { (0, 1), (2, 3), (4, 5) };- 1
- 这是一个三行二列的二维数组,且是不完全初始化,每个元素的类型是int类型
- 在大括号内的内容是逗号表达式
- { (0, 1), (2, 3), (4, 5) }最终给二维数组初始的值是1,3,5
- 第一行的元素是1,3
- 第二行的元素是5,0
- 第三行的元素是0,0
- 此时的a[0]的本质是数组首行一维数组的数组名,也就是第0行第0列元素的地址
- 将该地址赋值给指针变量p
printf("%d", p[0]);- 1
- p[0]可以写成*(p+0)
- p中的值是a[0][0]的地址
- 加0后仍然是该元素的地址
- 解引用后得到的就是该元素
- 所以结果是1

可以看到,结果与我们所分析的一致。- 笔试题5:
int main() { int a[5][5]; int(*p)[4]; p = a; printf("%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

我们知道,二维数组在内存中也是连续存放的- 如上图是二维数组在内存中的分布
int(*p)[4]; p = a;- 1
- 2
- 这里创建了一个数组指针,但是该指针指向的数组是4个元素的,每个元素的类型是int类型的
- 而数组名a的数据类型是int (*)[5]的
- 将a代表的指针强制赋值给数组指针p
- 此时站在p的角度来看,它就是一个有4个元素的数组指针
- p+1会跳过一个4个元素的一维数组,指向原本5个元素数组的最后一个元素的,如上图中的p+1
printf("%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);- 1
- 分析&p[4][2] - &a[4][2]
- p[4][2]可以写成*(*(p+4)+2)
- p中放的是第一个4个元素的数组的地址
- 加4后指向了第4个4个元素的一维数组,如上图中的p+4所指向的位置
- 对p+4解引用后得到的是第4个4个元素的一维数组,也就是这个数组的数组名
- 因为只有数组名可以代表一个数组
- 数组名的本质是数组首元素的地址,所以*(p+2)是该数组首元素的地址
- *(p+4)+2指向的是该数组中的第3个元素
- 再将该地址解引用得到的就是该元素
- 再对该元素取地址得到就是其地址,如上图中的绿色方框所指向的空间
- &a[4][2]得到就是第4行第2列的元素的地址,如上图中黑色方框所指向的空间
- 又因为地址减地址得到的是俩个地址之间的元素个数
- &p[4][2]的值小于&a[4][2]的值
- &p[4][2] - &a[4][2]的结果是-4
- -4在存在中的补码是111111111111111111111111111100
- 按照%p打印,打印出来的就是内存中数的样子,是FFFFFFFC
- 按照%d打印,打印出来的是它的补码,是-4

可以看到,与我们所分析的结果一致。- 笔试题6:
int main() { int a[2][5] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 }; int* ptr1 = (int*)(&a + 1); int* ptr2 = (int*)(*(a + 1)); printf("%d,%d", *(ptr1 - 1), *(ptr2 - 1)); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

- 数组元素的分布如上图
- &a中的a表示的是整个数组
- &a+1就跳过了整个二维数组,指向下一个二维数组,如图中的&a+1所示位置
- 此时的地址强制转换为int*类型的指针,赋值给ptr1
- 数组名a表示的是二维数组首行元素的地址
- a+1后指向的是二维数组第二行元素的地址
- 强制类型转换为int*类型的指针,赋值给ptr2
- 此时,ptr1-1指向的是数字10所在的空间,ptr2-1指向的是数字5指向的空间
- 解引用后得到的结果分别是10和5

可以看到,与我们分析的结果一致。- 笔试题7:
#include <stdio.h> int main() { char* a[] = { "work","at","alibaba" }; char** pa = a; pa++; printf("%s\n", *pa); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

- 3个字符串存储在常量区,如图中的红色框所示
- 创建了一个指针数组,该数组有3个元素,每个元素的类型都是char*类型
- 将3个字符串各自首字符的地址放在指针数组a中,如图中蓝色框所示
- 创建一个二级指针变量pa
- 此时数组a的数组名是数组首元素的地址,它的类型是一个二级指针
- 将数组首元素地址赋值给pa
- pa++是将pa中的值加1,此时pa中的值就是数组中第二个元素的地址
- 对pa解引用得到数组中的第二个元素,该元素是第二个字符串首字符的地址
- 打印字符串从这里开始
- 所以打印的结果是at

可以看到,和我们分析的一致。- 笔试题8:
int main() { char* c[] = { "ENTER","NEW","POINT","FIRST" }; char** cp[] = { c + 3,c + 2,c + 1,c }; char*** cpp = cp; printf("%s\n", **++cpp); printf("%s\n", *-- * ++cpp + 3); printf("%s\n", *cpp[-2] + 3); printf("%s\n", cpp[-1][-1] + 1); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11

- 四个字符串存放在常量区,如上图红色框所示
- 创建一个一级指针数组c
- 将四个字符串的首元素地址依次放入数组c中,如上图蓝色框所示
- 再创建一个二级指针数组cp
- 将一级指针数组的4个元素的地址倒序放入二级指针数组cp中,如上图绿色框所示
- 再创建一个三级指针变量pp
- 将二级指针数组cp的首元素地址赋值给三级指针变量cpp,如上图黑色框所示
printf("%s\n", **++cpp);- 1
- ++cpp后,三级指针变量cpp中的值变成了cp+1
- cp+1是二级指针数组cp的第二个元素的地址
- 第一次解引用是对地址cp+1解引用,得到的内容是c+2
- c+2是一级指针数组c的第三个元素的地址
- 第二次解引用相当于对地址c+2解引用,得到的内容是字符串POINT首字符的地址
- 所以打印的结果是字符串POINT
printf("%s\n", *-- * ++cpp + 3);- 1
- ++cpp后,三级指针变量cpp中的值便成了cp+2
- cp+2是二级指针数组cp的第三个元素的地址
- 解引用是对地址cp+2解引用,得到的内容是c+1
- c+1是一级指针数组c的第二个元素的地址
- 再进行自减1后,就是将c+1减1,得到的是c
- c是一级指针数组c的第一个元素
- 再次进行解引用是对地址c进行解引用,得到的是字符串ENTER首字符的地址
- 然后再将该地址加3,得到的是字符串ENTER中字符E的地址
- 所以打印的结果是ER
printf("%s\n", *cpp[-2] + 3);- 1
- cpp[-2]可以写成*(cpp-2)
- cpp-2等价于cp+2-2,得到的结果是cp
- cp是二级指针数组cp中首元素的地址
- 解引用是对地址cp解引用,得到的结果是c+3
- 再次解引用是对地址c+3解引用,得到的结果是字符串FIRST首字符的地址
- 再加3后得到的是字符串FIRST中字符S的地址
- 所以打印的结果是ST
printf("%s\n", cpp[-1][-1] + 1);- 1
- cpp[-1][-1]可以写成*(*(cpp-1)-1)
- 此时cpp中的值仍然是cp+2,因为只有自增才改变了它的值
- cpp-1等价于cp+2-1,结果是cp+1
- 对cp+1进行解引用,得到的结果是c+2
- c+2是一维数组c中第三个元素的地址
- 然后再将c+2-1得到的结果是c+1
- 对c+1解引用得到的结果是字符串NEW首字符的地址
- 再进行加1,得到的是字符串NEW中字符W的地址
- 所以打印的结果是EW

可以看到,与我们分析的结果一致。 -
相关阅读:
【实用工具】frp实现内网穿透
FPGA project : ROM_VGA
flutter 与原生 (iOS-swift)
剑指 Offer II 013. 二维子矩阵的和(Java)
【10. 差分】
7-zip压缩包密码忘记了,怎么破解?
WordPress优化插件多站点管理软件
C++中TCP socket传输文件
js的slice()和splice()
《家庭的觉醒》(二)提升觉悟的日常提示
- 原文地址:https://blog.csdn.net/weixin_63726869/article/details/125613906