-
MindSpore论文解读 | 自此告别互信息:用于跨模态行人重识别的变分蒸馏技术

MindSpore作为一个端边云协同的的全场景AI开源框架,为开发者带来编程更简单、调试更轻松、性能更卓越、部署更灵活、使用更安全的体验,2020.3.28开源来得到数五十万以上的下载量,走入100+高校教学,拥有数量众多的开发者,在AI计算中心,云、CT、消费者1+8+N等端边云全场景逐步广泛引用,是Gitee指数最高的开源软件。欢迎大家参与开源贡献、模型众智合作、行业创新与应用、算法创新、学术合作、AI书籍合作等,贡献您在云侧、端侧、边侧以及安全领域的应用案例。
基于MindSpore的AI顶会论文越来越多,MindSpore社区会不定期挑选一些优秀的论文来推送和解读,希望更多的学术界专家跟MindSpore合作,一起推动原创AI研究,MindSpore社区会持续支撑好AI原创和AI应用,本次我们选择了来自国内高校在CVPR2021的一篇论文进行解读,感谢谢老师团队投稿。
研究背景
研究背景介绍:信息瓶颈(Information Bottleneck, IB)是一种信息论指导下的表征学习方法,在本世纪初由Naftali Tishby等人提出,其核心目标为提纯对任务有帮助的判别性信息,同时消除输入中包含的冗余信息。虽然其理念十分先进,但实践中存在诸多缺陷,严重限制了其有效性和应用价值。
论文研究方向:此次工作围绕信息瓶颈的三个主要痛点展开,重点解决了高维空间中互信息难以估计、信息瓶颈优化机制中“充分性-简洁性”的权衡、以及对多视图数据乏力等难题。
团队背景介绍:所在团队由吴文俊科学技术奖自然科学奖、上海市科技进步特等奖获得者谢源教授领衔。团队长期从事机器学习、计算机视觉与模式识别等方面的科研工作,有扎实的研究基础和丰富的成果积累(AI与CV顶会年均产出4~8篇,AI与CV顶刊年均产出3~5篇),并形成了一系列自有知识产权的国际领先的科研成果。
论文主要内容简介
论文针对信息瓶颈的优化提出了一种全新、可扩展的解析解,在避免高维空间互信息估算的前提下,对其进行更为精确的拟合。在此基础上,论文将信息瓶颈优化目标等效地简化为一项KL-散度,使其可以在保存判别性信息的同时消除冗余,彻底解决了原有优化机制中“充分性-简洁性”的权衡难题,显著提升了信息瓶颈的实践价值。为提升应对多视图问题的能力,文中通过对涉及多视图变量的互信息进行数次交叉分解,提出一种有效保存视图一致性的方法。在其作用下,表征可以显著提升自身对于视图变化的鲁棒性,从而更好地保存泛化性信息。
论文通过大量、详实的消融实验在实践中验证了理论的正确性,并在与SOTA方法的对比中,以极简的网络结构大幅领先于所有相关方法,证实了理论的有效性。
代码链接
论文链接:
https://arxiv.org/abs/2104.02862
基于MindSpore实现的代码开源链接:
https://gitee.com/mindspore/contrib/tree/master/papers/MVD
算法框架技术要点
论文中所有实验均以标准评测准则开展于SYSU-MM01与RegDB数据集。如图一所示,算法框架(模型)总共包括两部分,即用于处理单一模态两条的modal-specific分支,以及一条同时处理不同模态数据的modal-shared分支。每条分支仅包括一个编码器以及一个信息瓶颈,两者分别采用ResNet-50以及一个三层MLP实现。

图一:算法框架(模型结构图)
实验结果
论文模型在SYSU-MM01数据集以及RegDB数据集上结果分别如下图所示:

图二:论文模型在SYSU-MM01数据集实验结果

图三:论文模型在RegDB数据集实验结果
MindSpore代码实现
代码主要包括以下几个模块构成:数据加载、训练器以及模型框架。
1、数据加载:
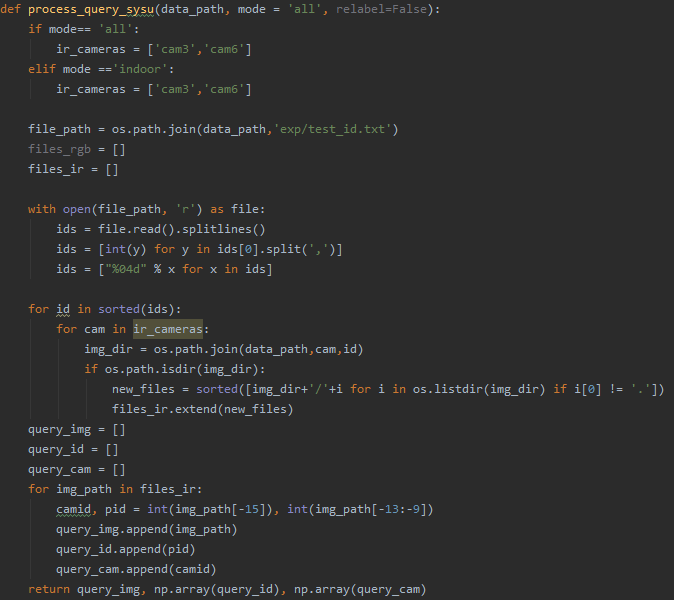
图四:数据加载(SYSU-MM01 query)

图五:数据加载(SYSU-MM01 gallery)
2、训练器:

图六:训练循环
3、模型框架:
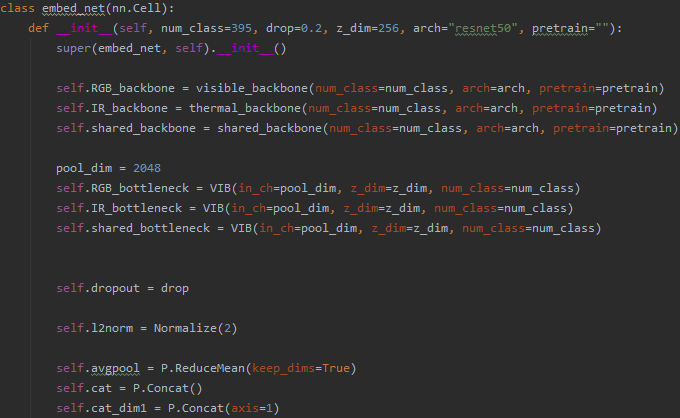
图七:模型总体框架

图八:信息瓶颈结构
总结与展望
论文为互信息拟合提供了一种全新、可扩展的解析解,并以此改进了信息瓶颈的优化机制。虽然方法可以有效解决多视图学习问题,但复杂度会随着视图数量的增长而急剧上升。因此未来工作可以改进方法对于多视图数据的处理,使其在保证有效性的同时,不再受视图数量的限制。
-
相关阅读:
判断时间范围是否重叠(原理)
MySQL基本操作大全
从零学习Python:json和文件操作
Nginx 的安装与使用(入门教程)
VSCode个人设置习惯
MySql
Vue课程48-学习小结
JZ19 正则表达式匹配
JavaSE面试题03:方法的参数传递机制
一文带您了解云渲染
- 原文地址:https://blog.csdn.net/Kenji_Shinji/article/details/125622822