-
Swin Transformer算法解读
目录
本文参考:论文详解:Swin Transformer - 知乎
一、Swin-Transformer整体架构
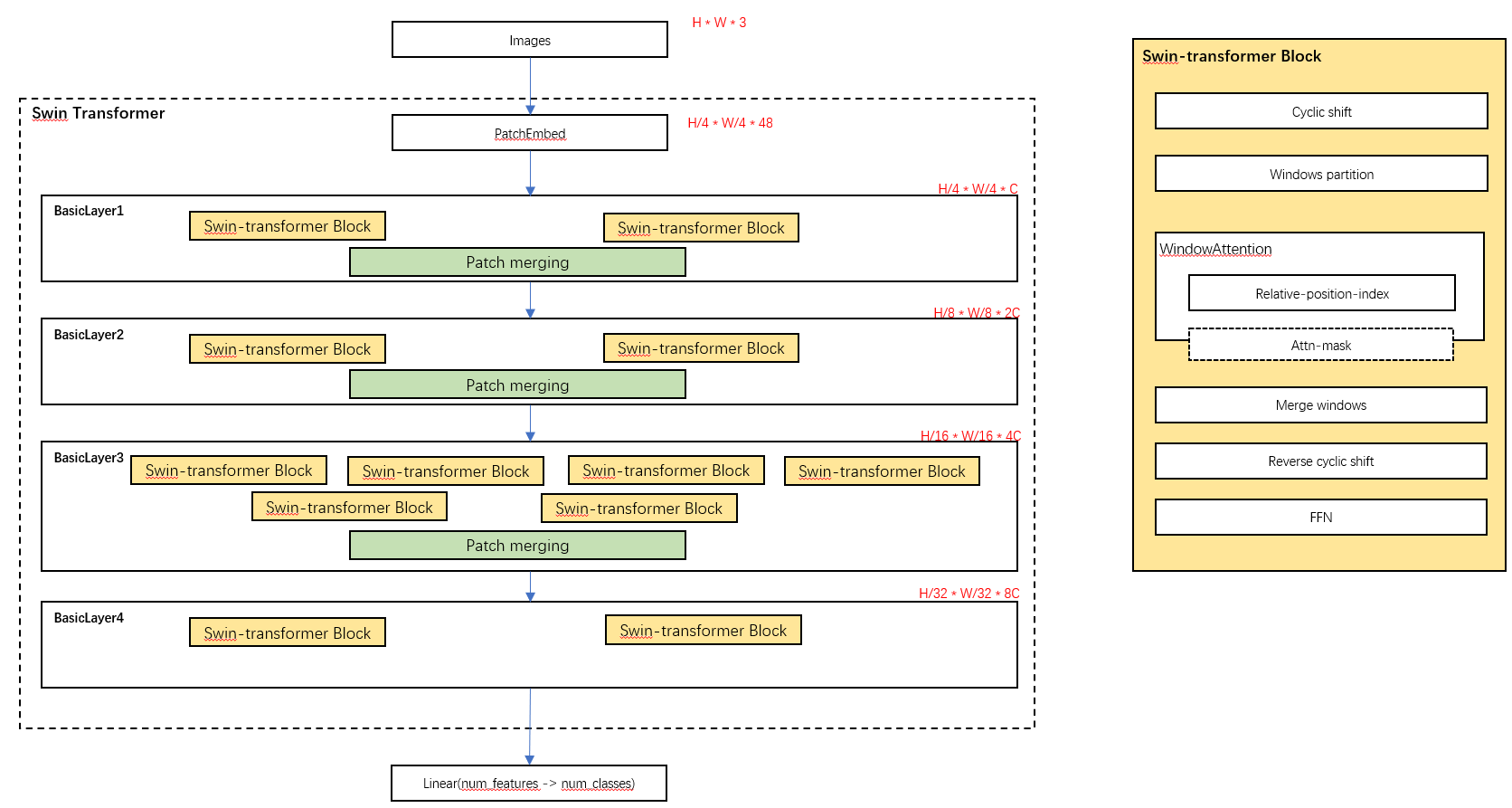
整个模型采取层次化的设计,除了最后一个BasicLayer外,每个BasicLayer都会在最后通过Patch Merging层缩小输出特征图的分辨率,进行下采样(比如avgPooling池化)操作,像CNN一样逐层扩大感受野,以便获取到全局的信息。
二、Patch Embedding
在进入Block前,需要通过patch_size为4的卷积层将图片切成一个个patch,然后嵌入向量Embedding,将embedding_size转变为96(可以将CV中图片的通道数理解为NLP中token的词嵌入长度)。
这里通过二维卷积层,将stride,kernel_size设置为patch_size大小,设定输出通道来确定嵌入向量的大小。最后将H,W维度展开,并移动到第一维度。

输入的H=W=224是在dataloader阶段的transform中完成图片Height和Width调整的。
三、Swin-Transformer Block
传统的Transformer是基于全局来计算注意力的,因此计算复杂度十分高。而Swin Transfomer则将注意力的计算限制在每个窗口内,进而减少了计算量。

Window Attention是在每个窗口下计算注意力的,为了更好地和其他window进行信息交互,Swin Transformer还引入了shifted window 操作。左边是没有重叠的window attention,而右边则是将窗口进行移位的Shift Window Attention。可以看到移位后的窗口包含了原本相邻窗口的元素。但这也引入了一个新问题,即window的个数翻倍了,由原本4个窗口变成了9个窗口。在实际代码里,通过对特征图位移,并给Attention设置mask来间接实现的。能在保持原有的windows个数下,最后的计算结果等价。
(1)cyclic shift特征图移位操作
代码里面对特征图移位是通过torch.roll来实现的。
 ->(步骤1)
->(步骤1)  ->(步骤2)
->(步骤2) 
步骤1:torch.roll(a, shifts=-1, dims=0)
步骤2:torch.roll(b, shifts=-1, dims=1)
如果需要reverse cyclic shift的话只需要把参数shifts设置为对应的正数值。
(2)window partition/reverse
window partition函数是用于对张量划分窗口,指定窗口大小。将原本的张量从B H W C划分成num_windows * B, window_size, window_size, C。其中num_windows=H*W/(window_size*window_size),即窗口的个数。而window reverse函数则是对应的逆过程。

(3)Window Attention
(3.1)计算公式

需要在原始计算Attention的公式中的QK时加入相对位置编码。
Q,K,V.shape=[numWindows*B, num_heads, window_size*window_size, head_dim]
Window_size*window_size即NLP中token的个数
Head_dim = embedding_dim / num_heads,即NLP中token的词嵌入向量的维度
QKT计算出来的Attention张量的形状为[numWindows*B, num_heads, Q_tokens, K_tokens]
其中,Q_tokens=K_tokens=window_size * window_size
(3.2)相对位置索引
首先说下 绝对位置索引
Token的长度为window_size*window_size,当window_size=2时,每个token用二维的坐标(x, y)表示,即标记window_size中每个点的绝对位置索引。
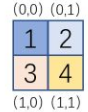
第一个token的query对所有token的attention如下:

因此:

第i行 表示 第i个token的query对所有的token的key的attention
然后说下 相对位置索引

所以QKT的相对位置索引为:

由于最终我们希望使用一维的位置坐标x+y代替二维的位置坐标(x,y),为了避免(1,2)(2,1)两个坐标转为一维时均为3,我们之后对相对位置索引进行了一些线性变换,使得能通过一维的位置坐标唯一映射到一个二维的位置坐标。整体的变换思路示例如下:

上面计算的是相对位置索引,而不是相对位置偏置参数。真正使用到的可训练参数保存在relative position bias table表里的,这个表的长度等于(2*window_size-1) * (2*window_size-1)。这个长度和相对位置索引的最大值是一致的。relative position bias table是需要训练得到的。
(4)Attention Mask
通过设置合理的mask,让shifted window attention在与window attention相同的窗口个数下,达到等价的计算结果。
首先我们对Shift Window后的每个窗口都给上index,如下图所示:

第一次shift window的时候,H=W=56,以window_size=7划分窗口,则可以划分8*8=64个窗口。Shift_size = window_size // 2 = 3。
假设window_size=2,shift_size=1,则可以得到如下结果:

我们在计算Attention的时候,让具有相同index QK进行计算,而忽略不同index QK计算结果。

(5)merge windows

四、patch merging (down sample)
该模块的作用是做降采样,用于缩小分辨率,调整通道数进而形成层次化的设计,同时也能节省一定运算量。
每次降采样是2倍,因此在行方向和列方向上,间隔2选取元素。
然后拼接在一起作为一整个张量,最后展开。此时通道数维度会变成原先的4倍(因为H,W各缩小2倍),此时再通过一个全连接再调整通道维度为原来的2倍。
下面是一个示意图(输入张量N=1,H=W=8, C=1)


五、Transformer Block核心逻辑图


-
相关阅读:
什么是泛型?
【算法】滑动窗口破解长度最小子数组
【Redis】Zset 有序集合内部编码方式
新风机小助手-风压变速器
Docker2(感谢狂神)
上下架和橱窗推荐如何设置,优化过程需要注意的地方
Adobe Illustrator——原创设计的宝藏软件
js中的同步任务、异步任务、宏任务、微任务
最短路径专题8 交通枢纽 (Floyd求最短路 )
「SpringCloud」09 Bus消息总线
- 原文地址:https://blog.csdn.net/benben044/article/details/125622747