-
Redis(10)----AOF持久化
1,前言
有关RDB持久化的可以看这个
除了
RDB持久化功能之外,Redis还提供了AOF(Append Only File)持久化功能。与RDB持久化通过保存数据库中的键值对来记录数据库状态不同,AOF持久化是通过保存Redis服务器所执行的写命令来记录数据库状态的。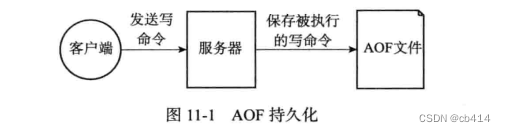
例如执行下面的几条命令:
redis> SET msg "hello" OK redis> SADD fruit "apple" "banana" "cherry" (integer) 3 redis> RPUS numbers 128 256 512 (integer) 3- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
RDB持久化的话,就会将msg、fruit、numbers三个键的键值对保存到RDB文件中;而AOF则会将这三个命令保存到AOF文件中,还原数据库时,再执行这三条命令进行数据还原被写入到
AOF文件中的命令是按照Redis的命令请求协议格式保存的,因为Redis的命令请求格式是纯文本格式,所以可以直接打开AOF文件,例如上面的命令,在AOF文件中会是这样保存的:
的一行的
SELECT命令是服务器自动添加的,其他均是客户端输入的命令2,AOF
2.1,AOF持久化的实现
AOF持久化功能的实现分为三步:- 命令追加:将写命令追加到
AOF缓冲区 - 文件写入:将
AOF缓冲区的内容写入和保存到AOF文件里 - 文件同步:操作系统看似将
AOF缓冲区的内容直接写入到AOF文件中,但实际上,它会先将内容写到一个内存缓冲区中,等到缓冲区满了之后,再一次性写入到AOF文件中
命令追加
当
AOF持久化功能打开时,服务器执行完一个写命令之后,会以协议格式将被执行的写命令追加到服务器状态的aof_buf缓冲区的末尾:struct redisServer{ //... //AOF缓冲区 sds aof_buf; //... };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
例如,执行下面这条命令后:
redis> SET KEY VALUE OK- 1
- 2
会将以下的内容追加到
aof_buf缓冲区末尾: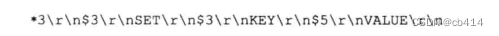
文件的写入与同步
Redis的服务器进程就是一个事件循环,这个事件循环里面存在文件事件与时间事件。- 文件事件负责接收客户端的命令请求,以及向客户端发送命令回复
- 时间事件则负责执行像
serverCron函数(例如RDB持久化功能中通过save设置保存条件,就在这个函数中得到运行)这样需要定时运行的函数
因为服务器在处理文件事件时可能会执行写命令,从而追加一些内容到
aof_buf缓冲区,所以在每次事件循环结束前,需要调用flushAppendOnlyFile函数,考虑是否将aof_buf缓冲区的内容写入和保存到AOF文件中。这个过程可以用以下伪代码表示:def eventLoop(): while True: # 处理文件事件,接受命令请求以及发送命令回复 # 处理命令请求时可能会有新内容被追加到aof_buf缓冲区中 processFileEvents() # 处理时间事件 processTimeEvents() # 考虑是否要将aof_buf中的内容写入和保存到AOF文件中 flushAppendOnlyFile()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
flushAppendOnlyFile函数的行为由服务器配置的appendfsync选项的值设定,这个值决定AOF文件的同步频率在上面有提及到文件同步,操作系统会先将数据写入到内容缓冲区,而非直接写到文件,等到内容缓冲区满了之后,再一次性写入到文件中。这样有助于提高写入效率,但也带来一个问题:如果数据写入到内容缓冲区了,但是在将内容写入到文件之前,计算机停机了,那么保存在内存缓冲区中的数据将会丢失。
appendfsync选项的值flushAppendOnlyFile函数的行为always将 aof_buf缓冲区的所有内容写入并同步到AOF文件everysec将 aof_buf缓冲区的所有内容写入到AOF文件,如果距离上次同步的时间距离超过一秒钟,将对AOF文件再次进行同步,并且有一个专门的线程进行同步no将 aof_buf缓冲区的所有内容写入到AOF文件,但不对AOF文件进行同步,何时同步由操作系统决定如果没有主动为
appendfsync设定值,那么默认值会被设置为:everysec不同的值带来的效率与安全性影响如下:
always:因为在每个事件循环都要进行一次AOF文件同步,所以效率是三种选项之中最低的;但从安全性来讲,是最安全的,因为即使出现停机故障,也只会丢失一个事件循环中产生的命令数据everysec:在每个事件中写入数据到AOF文件,并且每隔一秒就执行一次同步操作,效率足够快,安全性得到保障。因为即使出现故障,也只会丢失这一秒的命令数据no:每个事件循环中将数据写入到AOF文件,但至于何时对AOF文件进行同步则由操作系统决定。有可能在内存中积累一段时间的写入数据,因此这种模式下的单次同步时长通常是最长的;出现故障时,会丢失到上次同步为止的所有数据。
2.2,AOF文件的载入与数据还原
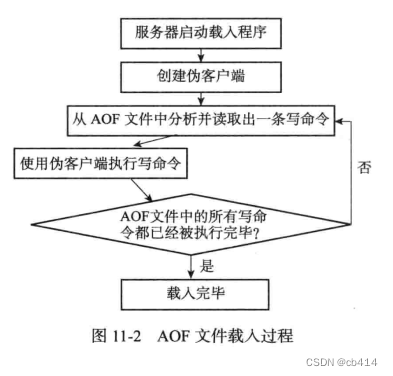
当使用
AOF文件重建数据库时,服务器只需要读入并重新执行一次AOF文件里面保存的命令即可,步骤如下:- 创建一个不带网络连接的伪客户端,因为重建数据库的命令都存在于
AOF文件中,所以不需要使用网络连接 - 从
AOF文件中分析并读取一条写命令 - 使用伪客户端执行被读出的命令
- 一直执行步骤2和步骤3,直到将
AOF文件中的命令处理完为止
2.3,AOF文件重写
因为
AOF文件是通过保存客户端执行的写命令来记录数据库状态,随着服务器的运行,这个文件会越来越庞大,如果不加以控制的话,会对服务器乃至计算机造成影响。并且文件过大,还原数据库时需要的时间就越长。例如执行以下命令:
redis> RPUSH list "A" "B" (integer) 2 redis> RPUSH list "C" (integer) 3 redis> RPUSH list "D" "E" (integer) 5 redis> LPOP list "A" redis> LPOP list "B" redis> RPUS list "F" "G" (integer) 5- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
光是为了记录这个
list键的状态就需要保存六条命令。为了解决
AOF文件体积膨胀的问题,Redis提供了AOF文件重写(rewrite)功能。Redis服务器可以创建一个新的AOF文件来代替现有的AOF文件,新旧两个AOF文件所保存的数据库状态相同,但新的AOF文件不会保存任何浪费空间的冗余命令,所以新的AOF文件体积会比旧的小得多。AOF文件重写不需要对旧的AOF文件进行任何读取,而是读取服务器当前的数据库状态来实现的。以上面的例子为例,执行六条命令后,服务器中就存在了一个列表键,键名
list,值为:[“C”,”D”,”E”,”F”,”G”],服务器可以使用一条命令:RPUSH list “C” ”D” ”E” ”F” ”G”来替代保存在AOF文件中的六条命令。所有类型的键都可以用同样的方式来减少
AOF文件中的命令数量:首先从数据库中读取键现在的值,然后用一条命令去记录键值对,代替之前记录这个键值对的多条命令,这就是AOF文件重写的原理整个重写过程的伪代码如下所示:
def aof_rewrite(new_aof_file_name): # 创建新AOF文件 f=create_file(new_aof_file_name) # 遍历数据库 for db in reidsServer.db: #忽略空数据库 if db.is_empty(): continue #写入SELECT命令,指定数据库号码 f.write_command("SELECT" + db.id) # 遍历数据库中的所有键 for key in db: #忽略已过期的键 if key.is_expired(): continue #根据键的类型对键进行重写 if key.type==String: rewrite_strng(key) elif key.type==List: rewrite_list(key) elif key.type==Hash: rewrite_hash(key) elif key.type==Set: rewrite_set(key) elif key.type==SortedSet: rewrite_sorted_set(key) # 如果键带有过期时间,那么过期时间也要被重写 if key.hava_expire_time(): rewrite_expire_time(key) # 写入完毕,关闭文件 f.close() def rewrite_string(key): # 使用GET命令获取字符串键的值 value=GET(key) # 使用SET命令重写字符串键 f.write_command(SET,key,value) def rewrite_list(key): # 使用LRANGE命令获取列表键包含的所有元素 item1,item2,...,itemN=LRANGE(key,0,-1) # 使用RPUSH命令重写列表键 f.write_command(RPUSH,key,item1,item2,...,itemN) def rewrite_hash(key): # 使用HGETALL命令获取哈希键包含的所有键值对 field1,value1,field2,value2,...fieldN,valueN=HGETALL(key) # 使用HMSET命令重写列表键 f.write_command(HMSET,key,field1,value1,field2,value2,...fieldN,valueN) def rewrite_set(key): # 使用SMEMBERS命令获取集合键包含的所有元素 elem1,elem2,...,elemN=SMEMBERS(key) # 使用SADD命令重写集合键 f.write_command(SADD,key,elem1,elem2,...,elemN) def rewrite_sorted_set(key): # 使用ZRANGE命令获取有序集合键包含的所有元素 member1,score1,member2,score2,...,memberN,scoreN=ZRANGE(key,0,-1,"WITHSCORES") # 使用ZADD命令重写有序集合键 f.write_command(ZADD,key,score1,member1,score2,member2,...,scoreN,memberN) def rewrite_expire_time(key): # 获取毫秒精度的键过期时间戳 timestamp=get_expire_time_in_unixstamp(key) # 使用PEXPIREAT命令重写键的过期时间 f.write_command(PEXPIREAT,key,timestamp)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
在实际中,为了避免在执行命令时造成客户端输入缓冲区溢出,重写程序在处理列表、哈希表、集合、有序集合等四种可能会带有多个元素的键时,会先检查键所包含的元素列表,如果超过了
REDIS_AOF_REWRITE_ITEMS_PER_CMD常量的值,那么重写程序会使用多条命令来记录键的值。比如,假设该常量值为64,并且有一个列表有100个元素,那么重写程序会分为两条命令来存储这100个元素,第一条命令存储前64个,第二条命令存储剩下的元素。
2.4,AOF后台重写
因为重写操作需要进行大量的写入操作,而
Redis服务器使用单个线程来处理命令请求,所以如果由服务器直接调用aof_rewrite函数的话,那么在重写AOF文件期间,服务器无法响应客户端发来的请求。基于此,Redis决定将AOF文件重写放到子进程里执行。这样做的好处:- 子进程进行
AOF重写期间,服务器进程(父进程)可以继续处理命令请求 - 子进程带有服务器进程的数据副本,使用子进程而不是线程,可以在避免使用锁的情况下,保证数据的安全性
使用子进程进行
AOF文件重写,需要考虑一个问题:在子进程进行重写期间,如果客户端继续执行一批写命令,新命令会对数据库状态进行修改,而子进程拿到的又是原先的数据副本,从而使得服务器当前的数据库状态与重写后的AOF文件所保存的数据库状态不一致。为了解决这个问题,
Redis设置了一个AOF重写缓冲区,这个缓冲区会在服务器创建子进程之后开始使用,当Redis服务器执行完一个命令后,它会同时将写命令发送给AOF缓冲区和AOF重写缓冲区。
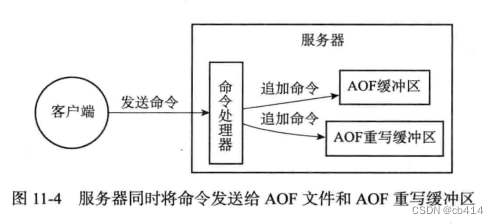
那么在子进程执行
AOF重写期间,服务器进程与子进程做的工作都有:- 执行客户端发来的命令
- 将执行后的写命令追加到
AOF缓冲区,保证了AOF缓冲区的内容会定期被写入和同步到AOF文件 - 将执行后的写命令追加到
AOF重写缓冲区,从创建子进程开始,服务器执行的写命令都会被记录到AOF重写缓冲区中 - 当子进程完成
AOF重写工作后,会向父进程发送一个信号,父进程接收到信号后,会调用一个信号处理函数- 这个信号处理函数会将重写缓冲区的所有内容写入到新的
AOF文件中 - 对新的
AOF文件进行改名,原子地(atomic)覆盖现有的AOF文件,完成新旧AOF文件的替换
- 这个信号处理函数会将重写缓冲区的所有内容写入到新的
这也就是
BGREWRITEAOF命令的实现原理 -
相关阅读:
当Unity实时3D引擎遇上AI虚实交互,Unity要成为元宇宙时代的新引擎
CY7C68013A芯片与FPGA
Trello与Notion的开源替代项目管理利器Focalboard本地安装与远程访问
中缀表达式转后缀表达式
mysql插入记录时违反唯一索引的处理
动态链接库Dll的编写与使用
【0230】PG内核底层事务(transaction)实现原理之基础篇
数据结构--串的基本概念
程序设计与算法(三)C++面向对象程序设计笔记 第九周 标准模板库STL(二)
C++面试八股文:什么是左值,什么是右值?
- 原文地址:https://blog.csdn.net/weixin_41043607/article/details/125618083
