-
Flink Cep 源码分析
复合事件处理(Complex Event Processing,CEP)是一种基于动态环境中事件流的分析技术,事件在这里通常是有意义的状态变化,通过分析事件间的关系,利用过滤、关联、聚合等技术,根据事件间的时序关系和聚合关系制定检测规则,持续地从事件流中查询出符合要求的事件序列,最终分析得到更复杂的复合事件。
我们从一个案例开始源码分析之路。
1.案例代码
- Import org.apache.flink.api.common.eventtime.WatermarkStrategy;
- import org.apache.flink.api.java.tuple.Tuple3;
- import org.apache.flink.cep.CEP;
- import org.apache.flink.cep.PatternSelectFunction;
- import org.apache.flink.cep.PatternStream;
- import org.apache.flink.cep.pattern.Pattern;
- import org.apache.flink.streaming.api.TimeCharacteristic;
- import org.apache.flink.streaming.api.datastream.KeyedStream;
- import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
- import java.time.Duration;
- import java.util.Map;
- public class FlinkCepTest {
- public static void main(String[] args) throws Exception {
- StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
- env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
- env.setParallelism(1);
- // 数据源
- KeyedStream<Tuple3<String, Long, String>, String> source = env.fromElements(
- new Tuple3<String, Long, String>("1001", 1656914303000L, "success")
- , new Tuple3<String, Long, String>("1001", 1656914304000L, "fail")
- , new Tuple3<String, Long, String>("1001", 1656914305000L, "fail")
- , new Tuple3<String, Long, String>("1001", 1656914306000L, "success")
- , new Tuple3<String, Long, String>("1001", 1656914307000L, "fail")
- , new Tuple3<String, Long, String>("1001", 1656914308000L, "success")
- , new Tuple3<String, Long, String>("1001", 1656914309000L, "fail")
- , new Tuple3<String, Long, String>("1001", 1656914310000L, "success")
- , new Tuple3<String, Long, String>("1001", 1656914311000L, "fail")
- , new Tuple3<String, Long, String>("1001", 1656914312000L, "fail")
- , new Tuple3<String, Long, String>("1001", 1656914313000L, "success")
- , new Tuple3<String, Long, String>("1001", 1656914314000L, "end")
- ).assignTimestampsAndWatermarks(WatermarkStrategy
- .<Tuple3<String, Long, String>>forBoundedOutOfOrderness(Duration.ofSeconds(1))
- .withTimestampAssigner((event, timestamp) ->{
- return event.f1;
- }))
- .keyBy(e -> e.f0);
- Pattern<Tuple3<String, Long, String>,?> pattern = Pattern
- .<Tuple3<String, Long, String>>begin("begin")
- .where(new Begincondition())
- .followedByAny("middle")
- .where(new Middlecondition())
- .followedBy("end")
- .where(new Endcondition())
- ;
- //TODO 内部构建 PatternStreamBuilder 并返回 PatternStream
- PatternStream patternStream = CEP.pattern(source, pattern);
- patternStream.select(new PatternSelectFunction<Tuple3<String, Long, String>,Map>() {
- @Override
- public Map select(Map map) throws Exception {
- return map;
- }
- }).print();
- env.execute("cep");
- }
- }
2.源码分析
根据上述提供的案例接下来我们分几个模块进行源码解析:Pattern构建,内部包含 NFAFactory,Cepopertor等构建逻辑,数据处理,超时处理,获取数据。
- //TODO 内部构建 PatternStreamBuilder 并返回 PatternStream
- PatternStream patternStream = CEP.pattern(source, pattern);
- PatternStreamBuilder.forStreamAndPattern(inputStream, pattern);
- static <IN> PatternStreamBuilder<IN> forStreamAndPattern(final DataStream<IN> inputStream, final Pattern<IN, ?> pattern) {
- return new PatternStreamBuilder<>(inputStream, pattern, TimeBehaviour.EventTime, null, null);
- }
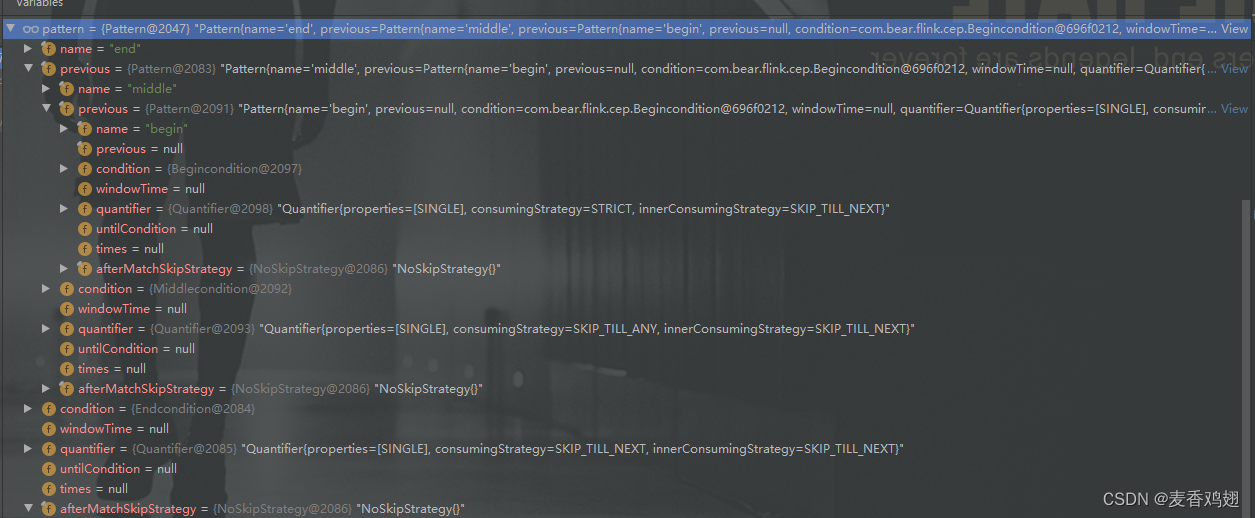
PatternStream.select() 内部会调用 PatternStreamBuilder.build()
- public <R> SingleOutputStreamOperator<R> process(
- final PatternProcessFunction<T, R> patternProcessFunction,
- final TypeInformation<R> outTypeInfo) {
- return builder.build(
- outTypeInfo,
- builder.clean(patternProcessFunction));
- }
org.apache.flink.cep.PatternStreamBuilder#build
- <OUT, K> SingleOutputStreamOperator<OUT> build(
- final TypeInformation<OUT> outTypeInfo,
- final PatternProcessFunction<IN, OUT> processFunction) {
- checkNotNull(outTypeInfo);
- checkNotNull(processFunction);
- //TODO 构造序列化器
- final TypeSerializer<IN> inputSerializer =
- inputStream.getType().createSerializer(inputStream.getExecutionConfig());
- final boolean isProcessingTime = timeBehaviour == TimeBehaviour.ProcessingTime;
- //TODO 判断是否是获取超时结果的 select/flatSelect
- final boolean timeoutHandling = processFunction instanceof TimedOutPartialMatchHandler;
- //TODO 构建 NFAFactory 工厂类
- // 工厂对象还包含了用户所有的State集合
- final NFACompiler.NFAFactory<IN> nfaFactory =
- NFACompiler.compileFactory(pattern, timeoutHandling);
- //TODO 创建 CepOperator
- final CepOperator<IN, K, OUT> operator =
- new CepOperator<>(
- inputSerializer,
- isProcessingTime,
- nfaFactory,
- comparator,
- pattern.getAfterMatchSkipStrategy(),
- processFunction,
- lateDataOutputTag);
- final SingleOutputStreamOperator<OUT> patternStream;
- if (inputStream instanceof KeyedStream) {
- KeyedStream<IN, K> keyedStream = (KeyedStream<IN, K>) inputStream;
- patternStream = keyedStream.transform("CepOperator", outTypeInfo, operator);
- } else {
- KeySelector<IN, Byte> keySelector = new NullByteKeySelector<>();
- patternStream =
- inputStream
- .keyBy(keySelector)
- .transform("GlobalCepOperator", outTypeInfo, operator)
- .forceNonParallel();
- }
- return patternStream;
- }
org.apache.flink.cep.nfa.compiler.NFACompiler#compileFactory 构建 NFACompiler.NFAFactory
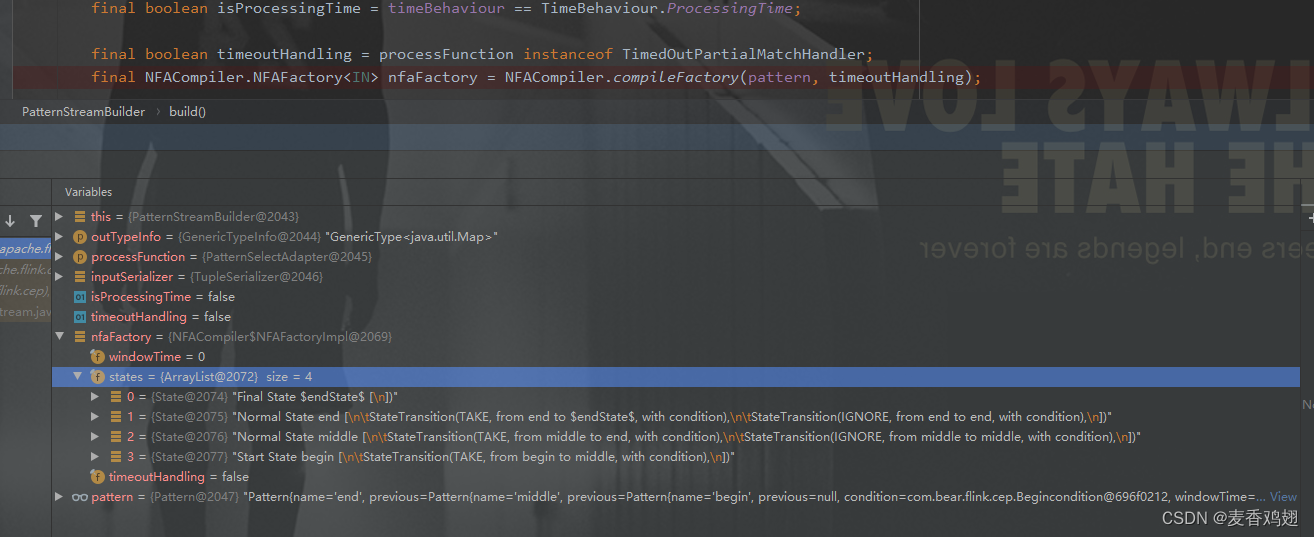
org.apache.flink.cep.operator.CepOperator#open() 初始化逻辑
- @Override
- public void open() throws Exception {
- super.open();
- //TODO 初始化 定时器服务
- timerService =
- getInternalTimerService(
- "watermark-callbacks", VoidNamespaceSerializer.INSTANCE, this);
- //TODO 创建NFA初始化了所有的顶点state和边transition
- // 这个时候的state集合已经初始化完成了
- nfa = nfaFactory.createNFA();
- //TODO 给判断逻辑设置 cep运行环境
- nfa.open(cepRuntimeContext, new Configuration());
- context = new ContextFunctionImpl();
- collector = new TimestampedCollector<>(output);
- cepTimerService = new TimerServiceImpl();
- // metrics
- this.numLateRecordsDropped = metrics.counter(LATE_ELEMENTS_DROPPED_METRIC_NAME);
- }
org.apache.flink.cep.operator.CepOperator#processElement() 接收数据进行处理
- @Override
- public void processElement(StreamRecord<IN> element) throws Exception {
- //TODO 判断当前语义为 ProcessingTime 还是 EventTime
- if (isProcessingTime) {
- if (comparator == null) {
- // there can be no out of order elements in processing time
- NFAState nfaState = getNFAState();
- long timestamp = getProcessingTimeService().getCurrentProcessingTime();
- advanceTime(nfaState, timestamp);
- processEvent(nfaState, element.getValue(), timestamp);
- updateNFA(nfaState);
- } else {
- long currentTime = timerService.currentProcessingTime();
- bufferEvent(element.getValue(), currentTime);
- // register a timer for the next millisecond to sort and emit buffered data
- timerService.registerProcessingTimeTimer(VoidNamespace.INSTANCE, currentTime + 1);
- }
- } else {
- //TODO 获取事件的时间
- long timestamp = element.getTimestamp();
- //TODO 获取数据
- IN value = element.getValue();
- // In event-time processing we assume correctness of the watermark.
- // Events with timestamp smaller than or equal with the last seen watermark are
- // considered late.
- // Late events are put in a dedicated side output, if the user has specified one.
- //TODO 在事件时间处理中,我们假设水印的正确性。
- // 时间戳小于或等于最后看到的水印的事件被认为是迟到的。
- // 如果用户指定了,则将延迟事件放在专用端输出中。
- if (timestamp > timerService.currentWatermark()) {
- // we have an event with a valid timestamp, so
- // we buffer it until we receive the proper watermark.
- //TODO 注册Watermark定时器
- saveRegisterWatermarkTimer();
- //TODO 缓存数据 key为事件时间 value为数据集合
- bufferEvent(value, timestamp);
- } else if (lateDataOutputTag != null) {
- output.collect(lateDataOutputTag, element);
- } else {
- numLateRecordsDropped.inc();
- }
- }
- }
org.apache.flink.cep.operator.CepOperator#onEventTime() 触发计算
- @Override
- public void onEventTime(InternalTimer<KEY, VoidNamespace> timer) throws Exception {
- // 1) get the queue of pending elements for the key and the corresponding NFA,
- // 2) process the pending elements in event time order and custom comparator if exists
- // by feeding them in the NFA
- // 3) advance the time to the current watermark, so that expired patterns are discarded.
- // 4) update the stored state for the key, by only storing the new NFA and MapState iff they
- // have state to be used later.
- // 5) update the last seen watermark.
- //TODO
- // 1)获取键的挂起元素队列和相应的NFA,
- // 2)按照事件时间顺序处理挂起的元素,如果存在自定义比较器,则在NFA中输入它们
- // 3)将时间提前到当前水印,丢弃过期的图案。
- // 4)更新密钥的存储状态,只存储新的 NFA 和 MapState,如果它们有状态要稍后使用。
- // 5)更新最后一次出现的水印。
- // STEP 1
- //TODO 获取优先队列的中的数据
- PriorityQueue<Long> sortedTimestamps = getSortedTimestamps();
- //TODO 用于保存未匹配的完成的状态,和已匹配完成的状态,这里get为空时会初始化
- // 先遍历所有的找到其中为start的state作为下一个可匹配的状态
- NFAState nfaState = getNFAState();
- // STEP 2
- while (!sortedTimestamps.isEmpty()
- && sortedTimestamps.peek() <= timerService.currentWatermark()) {
- long timestamp = sortedTimestamps.poll();
- //TODO 处理超时未匹配的数据
- advanceTime(nfaState, timestamp);
- try (Stream<IN> elements = sort(elementQueueState.get(timestamp))) {
- elements.forEachOrdered(
- event -> {
- try {
- //TODO 将数据排好序(事件时间)以后使用NFA真正的处理逻辑
- processEvent(nfaState, event, timestamp);
- } catch (Exception e) {
- throw new RuntimeException(e);
- }
- });
- }
- elementQueueState.remove(timestamp);
- }
- // STEP 3
- advanceTime(nfaState, timerService.currentWatermark());
- // STEP 4
- updateNFA(nfaState);
- if (!sortedTimestamps.isEmpty() || !partialMatches.isEmpty()) {
- saveRegisterWatermarkTimer();
- }
- }
org.apache.flink.cep.operator.CepOperator#processEvent() 处理数据
- /**
- * Process the given event by giving it to the NFA and outputting the produced set of matched
- * event sequences.
- *
- * @param nfaState Our NFAState object
- * @param event The current event to be processed
- * @param timestamp The timestamp of the event
- */
- private void processEvent(NFAState nfaState, IN event, long timestamp) throws Exception {
- try (SharedBufferAccessor<IN> sharedBufferAccessor = partialMatches.getAccessor()) {
- //TODO 得到匹配上规则的map,map中包含了这个正则的所有数据
- Collection<Map<String, List<IN>>> patterns =
- nfa.process( //TODO 真正的处理逻辑
- sharedBufferAccessor,
- nfaState,
- event,
- timestamp,
- afterMatchSkipStrategy,
- cepTimerService);
- //TODO 这个map包含了匹配上的一个正则,下面会调用用户的select或者flatselect方法,往下游发送
- processMatchedSequences(patterns, timestamp);
- }
- }
org.apache.flink.cep.nfa.NFA#doProcess 开始处理数据
===> 第一条数据为 (1001,1656914303000,success)
当前正在匹配的只有 begin 的state

经过 org.apache.flink.cep.nfa.NFA#computeNextStates 匹配之后
新的匹配中的state 变为两个 同时版本值会递增 同状态+1 下一个状态新增下一级
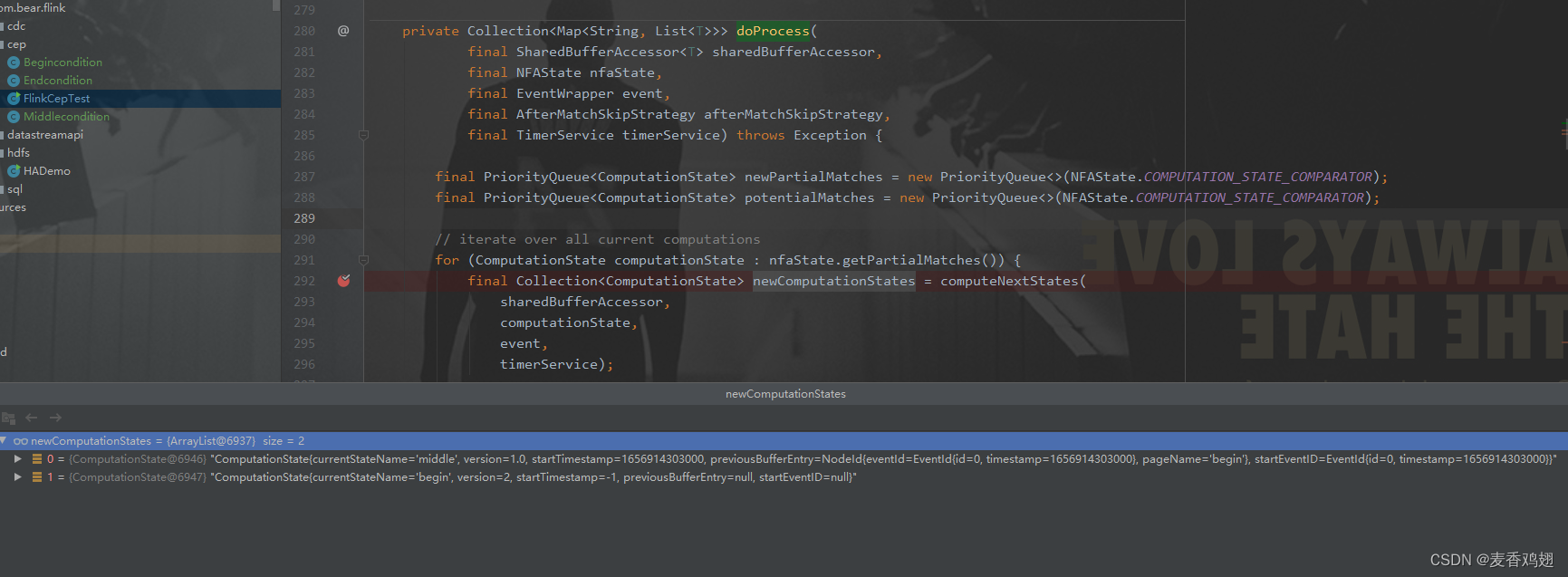
org.apache.flink.cep.operator.CepOperator#processMatchedSequences 判断是否匹配完成输出
===> 第二条数据为 (1001,1656914304000,fail)
经过 org.apache.flink.cep.nfa.NFA#computeNextStates 匹配之后
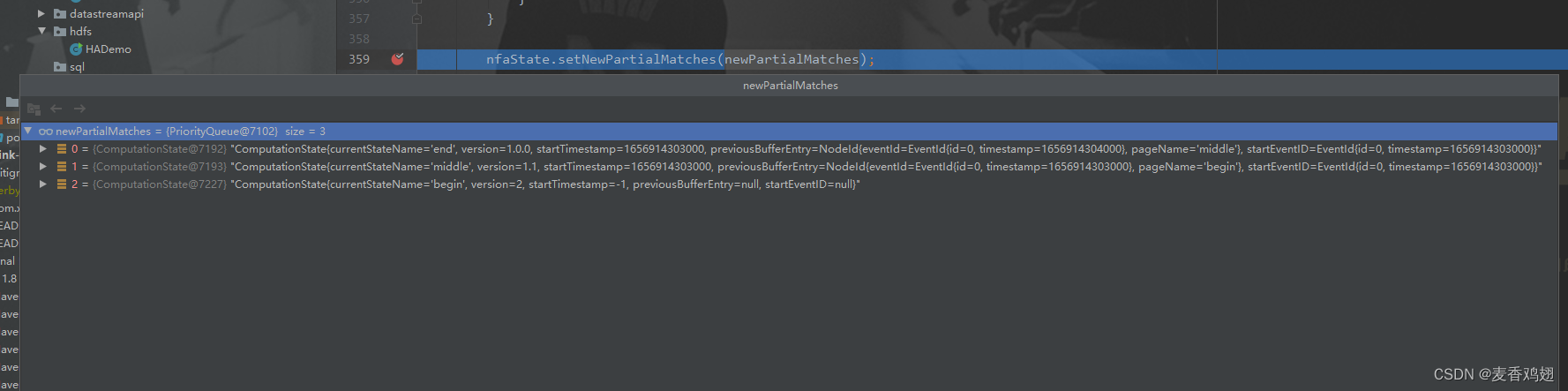
===> 第三数据为 (1001,1656914305000,fail)
经过 org.apache.flink.cep.nfa.NFA#computeNextStates 匹配之后

===> 第四数据为(1001,1656914306000,success)
经过 org.apache.flink.cep.nfa.NFA#computeNextStates 匹配之后
此时当前数据匹配到begin,startState版本+1,并且新增一个middle的状态

===> 第五数据为(1001,1656914307000,end)
经过 org.apache.flink.cep.nfa.NFA#computeNextStates 匹配
正在匹配中的状态变成3个,两个end的state变为完成状态。

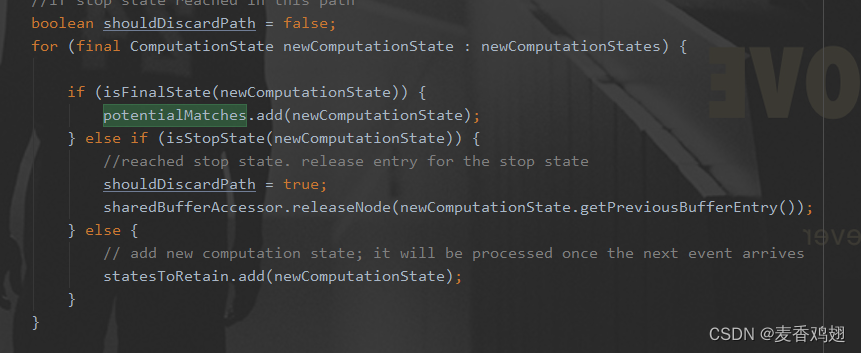
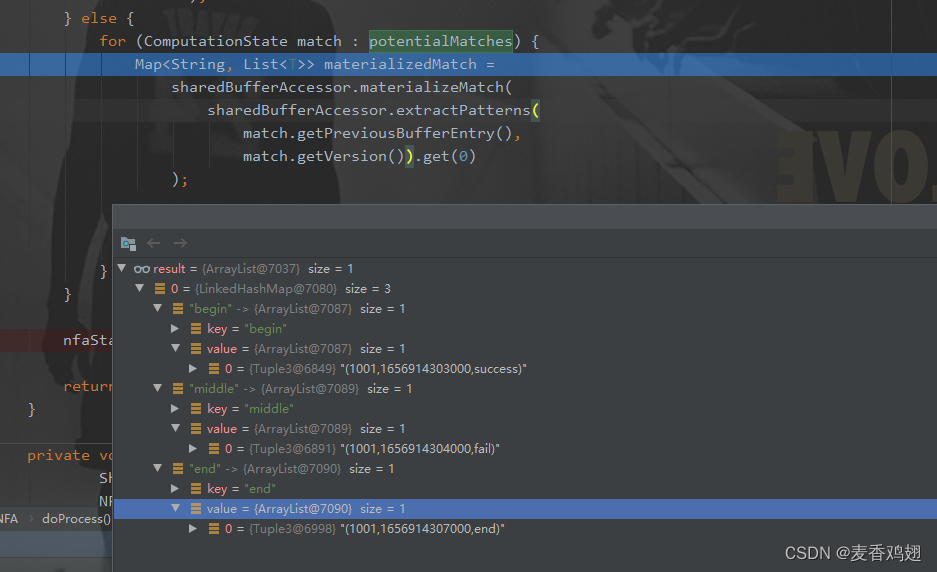
判断匹配到state状态是否为Final状态,是添加到potentialMatches中。
之后遍历从sharedBufferAccessor中获取数据。
SharedBufferAccessor 简介
Flink CEP设计了一个带版本的共享缓冲区。它会给每一次匹配分配一个版本号并使用该版本号来标记在这次匹配中的所有指针。
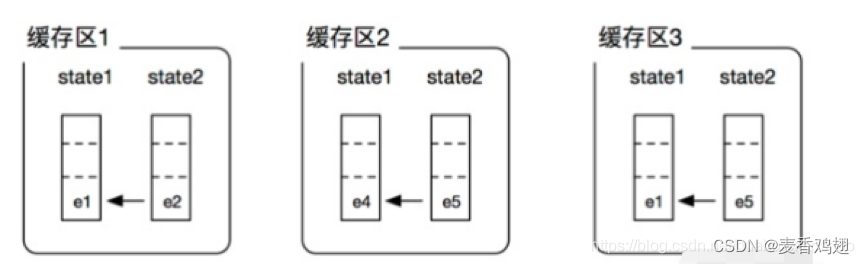
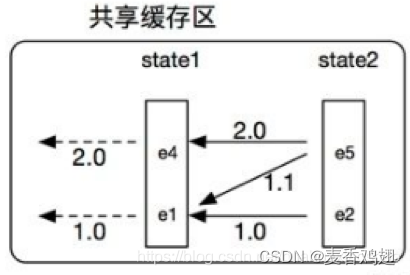
做三个独立的缓冲区实现上是没有问题,但是我们发现缓冲区3状态stat1的堆栈和缓冲区1状态stat1的堆栈是一样的,我们完全没有必要分别占用内存。而且在实际的模式匹配场景下,每个缓冲区独立维护的堆栈中可能会有大量的数据重叠。随着流事件的不断流入,为每个匹配结果独立维护缓存区占用内存会越来越大。所以Flink CEP 提出了共享缓存区的概念(SharedBuffer),就是用一个共享的缓存区来表示上面三个缓存区。
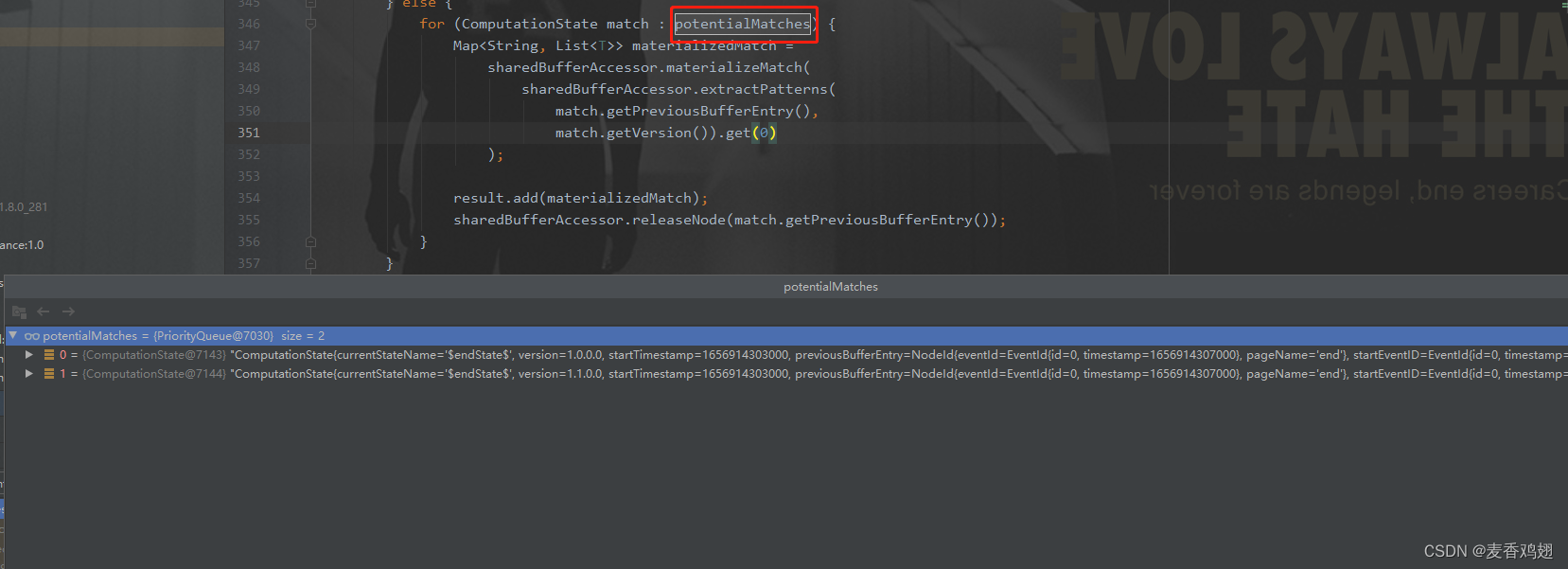
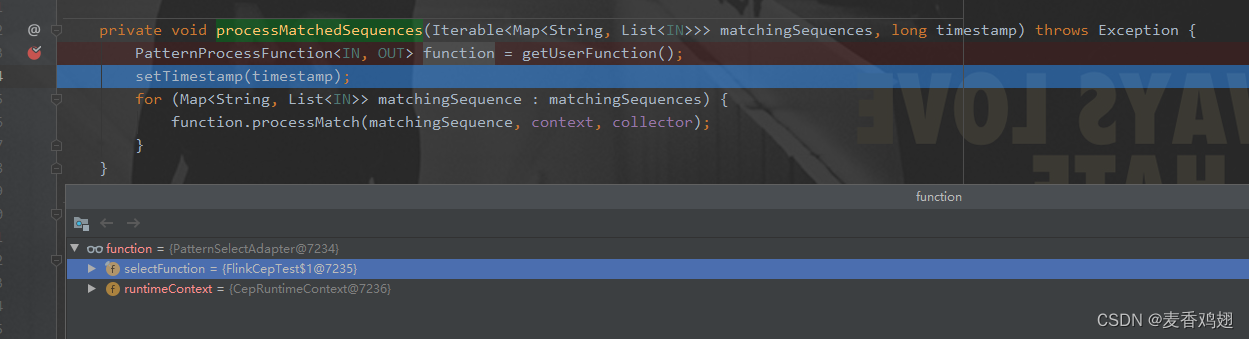
org.apache.flink.cep.operator.CepOperator#processMatchedSequences 处理匹配完成的state

processMatchedSequences内部调用自定义的 select函数 输出满足模式的数据
3.参考链接
-
相关阅读:
Django day08
字符串的使用
三、【VUE-CLI】修改默认配置
uboot引导应用程序
PMP每日一练 | 考试不迷路-11.02(包含敏捷+多选)
EasyPoi
nrf52832 低功耗蓝牙 广播
5G之ULCL
AOP结合注解实现项目中接口调用情况监控
5V摄像机镜头驱动,小云台驱动,低噪步进电机驱动芯片,应用于摄像机 机器人等产品中
- 原文地址:https://blog.csdn.net/qq_20672231/article/details/125615807