-
神经网络中的基本结构--卷积层和最大池化
神经网络中的基本结构
卷积层
torch.nn卷积层 Convolution Layerstorch.nn提供的包 针对场景 nn.Conv1d对由多个输入平面组成的输入信号应用一维卷积。 nn.Conv2d在由多个输入平面组成的输入信号上应用 2D 卷积。 nn.Conv3d对由多个输入平面组成的输入信号应用 3D 卷积。 … … nn.Conv2d 常用于对图像的卷积层
torch.nn.Conv2d( in_channels , out_channels , kernel_size , stride = 1 , padding = 0 , dilation = 1 , groups = 1 , bias = True , padding_mode = ‘zeros’ , device = None , dtype = None )该模块支持TensorFloat32。
-
参数:
-
in_channels :int, 输入图像中的通道数
-
out_channels : int, 卷积产生的通道数
-
kernel_size : (int / tuple),卷积核的大小
-
stride控制互相关、单个数字或元组的步幅。 -
padding控制应用于输入的填充量。它可以是一个字符串 {‘valid’, ‘same’} 或一个整数元组,给出在两边应用的隐式填充量。 -
dilation控制内核点之间的间距;也称为 à trous 算法。很难描述,但是这个链接 很好地可视化了dilation它的作用。 -
groups控制输入和输出之间的连接。in_channels并且out_channels都必须能被 整除groups。例如,- 在 groups=1 时,所有输入都卷积到所有输出。
- 在 groups=2 时,该操作等效于并排有两个卷积层,每个卷积层看到一半的输入通道并产生一半的输出通道,并且随后将两者连接起来。
- 在 groups=
in_channels处,每个输入通道都与自己的一组过滤器
-
对于stride和padding的理解:
- stride: 控制卷积核进行卷积计算下一次跳跃的步幅
- padding: 原3*3大小的数据,padding后在其周围阔充0,=1就是将周围添加一圈0变为5*5大小
in_channels :int, 输入图像中的通道数
out_channels : int, 卷积产生的通道数
对于in、out channels的理解:
in_channels=1,out_channels =1,则卷积层生成一个卷积核进行卷积计算,将卷积计算后的结果作为输出;
in_channels=1,out_channels =2,卷积层会生成两个卷积核,得到两个卷积后的计算结果,将这两个计算后的结果当作一个输出结果进行输出。两个卷积核不一定相等。
简单的示例:
import torch import torchvision from torch import nn from torch.nn import Conv2d from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter dataset = torchvision.datasets.CIFAR10("../DataSet", train=False, transform=torchvision.transforms.ToTensor(), download=True) dataloader = DataLoader(dataset, batch_size=64) # 搭建简单的神经网络 class Tudui(nn.Module): def __init__(self): super(Tudui, self).__init__() # 设置conv1,因为输入图像为彩色图像in_ch=3, 想输出6层out_ch=6,使用卷积核3*3,步幅1,不扩充 self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0) def forward(self, x): x = self.conv1(x) return x writer = SummaryWriter() tudui = Tudui() # print(tudui) for da in dataloader: imgs, targets = da output = tudui(imgs) print(imgs.shape) # torch.Size([64, 3, 32, 32]) print(output.shape) # torch.Size([64, 6, 30, 30]) writer.add_images("input", imgs, step) # torch.Size([64, 6, 30, 30]) -> [xxx, 3, 30, 30] output = torch.reshape(output, (-1, 3, 30, 30)) writer.add_images("output", output, step) step = step + 1 writer.close()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
示例讲解
-
print(imgs.shape) # torch.Size([64, 3, 32, 32])- 64 为
DataLoader(dataset, batch_size=64)中batch_size=64 - 3 是数据集中数据本来的三色通道, 即彩色图像的三通道色
- 32, 32是图片大小32*32
- 64 为
-
print(output.shape) # torch.Size([64, 6, 30, 30])卷积计算之后的形状输出,
- 64 为
DataLoader(dataset, batch_size=64)中batch_size=64 - 6是out_channels=6,
- 30,30 是经过卷积计算后的图像大小,30*30.
- 64 为
池化层
pytorch池化层相关内容的
nn.MaxPool1dApplies a 1D max pooling over an input signal composed of several input planes. nn.MaxPool2dApplies a 2D max pooling over an input signal composed of several input planes. nn.MaxPool3dApplies a 3D max pooling over an input signal composed of several input planes. nn.MaxUnpool1dComputes a partial inverse of MaxPool1d.nn.MaxUnpool2dComputes a partial inverse of MaxPool2d.MaxPool 最大池化,也被成为下采样
MaxUnPool ,上采样
AvgPool,平均池化
…
最常用的是MaxPool2d。
MaxPool2d
torch.nn.MaxPool2d( kernel_size , stride = None , padding = 0 , dilation = 1 , return_indices = False , ceil_mode = False )
参数
- kernel_size – 最大的窗口大小,
- stride——,步幅,窗口的步幅。默认值为
kernel_size- 这一点要和卷积层中的参数进行区分,卷积层中默认为1.
- padding – 要在两边添加隐式零填充
- dilation – 控制窗口中元素步幅的参数,一般不进行设置
- return_indices - 如果
True,将返回最大索引以及输出。torch.nn.MaxUnpool2d以后有用 - ceil_mode – 如果为 True,将使用ceil而不是floor来计算输出形状,默认是False
- ceil:向上取整
- floor:向下取整
参数
kernel_size,stride,padding,dilation可以是:- 单个
int- 在这种情况下,高度和宽度尺寸使用相同的值 - a
tupleof two int – 在这种情况下,第一个int用于高度维度,第二个int用于宽度维度,及(2,3)为 高2,宽3的矩阵
dilation – 控制窗口中元素步幅的参数,相关的空洞卷积
额外引入——空洞卷积
- 标准卷积:以3*3为例,以下分辨率不变与分辨率降低的两个实例;

- 空洞卷积:在3*3卷积核中间填充0,有两种实现方式,第一,卷积核填充0,第二,输入等间隔采样。
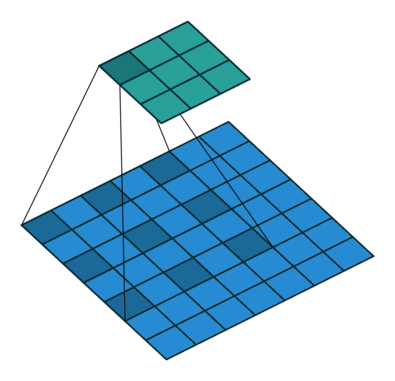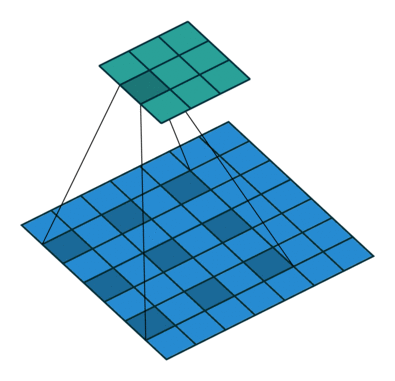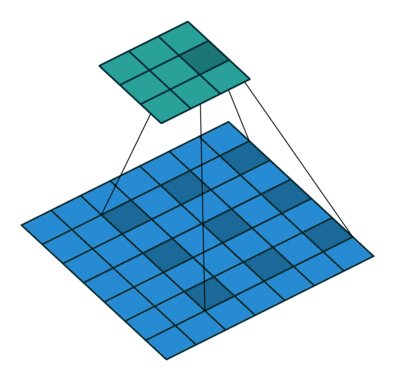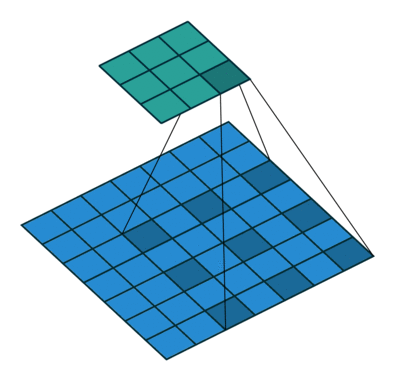
标准卷积与空洞卷积在实现上基本相同,标准卷积可以看做空洞卷积的特殊形式。
空洞卷积的作用
空洞卷积有什么作用呢?
- 扩大感受野:在deep net中为了增加感受野且降低计算量,总要进行降采样(pooling或s2/conv),这样虽然可以增加感受野,但空间分辨率降低了。为了能不丢失分辨率,且仍然扩大感受野,可以使用空洞卷积。这在检测,分割任务中十分有用。一方面感受野大了可以检测分割大目标,另一方面分辨率高了可以精确定位目标。
- **捕获多尺度上下文信息:**空洞卷积有一个参数可以设置dilation rate,具体含义就是在卷积核中填充dilation rate-1个0,因此,当设置不同dilation rate时,感受野就会不一样,也即获取了多尺度信息。多尺度信息在视觉任务中相当重要啊。
从这里可以看出,空洞卷积可以任意扩大感受野,且不需要引入额外参数,但如果把分辨率增加了,算法整体计算量肯定会增加。
池化操作
比如,一个5*5大小的输入图像,池化核大小为3(3*3),stride默认同池化核大小一致。
具体的池化操作,
- 3*3大小的池化,映射到5*5的输入上,从中筛选出3*3范围内最大的值输出

-
stride默认与池化核大小一致,则向后移动,出现如图所示,仅有6个元素被池化核覆盖。
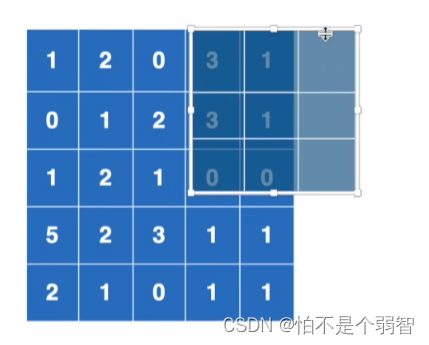
- 当类似情况发生时,参数ceil_mode就发挥作用了,及从这6个数中选取最大值还是将这6个数放弃。
- ceil_mode = True:保留,并将其中最大值输出
- ceil_mode = False:不保留,不从这6个数中选择,并舍弃这6个数
- 当类似情况发生时,参数ceil_mode就发挥作用了,及从这6个数中选取最大值还是将这6个数放弃。
-
最后,逐步完成池化
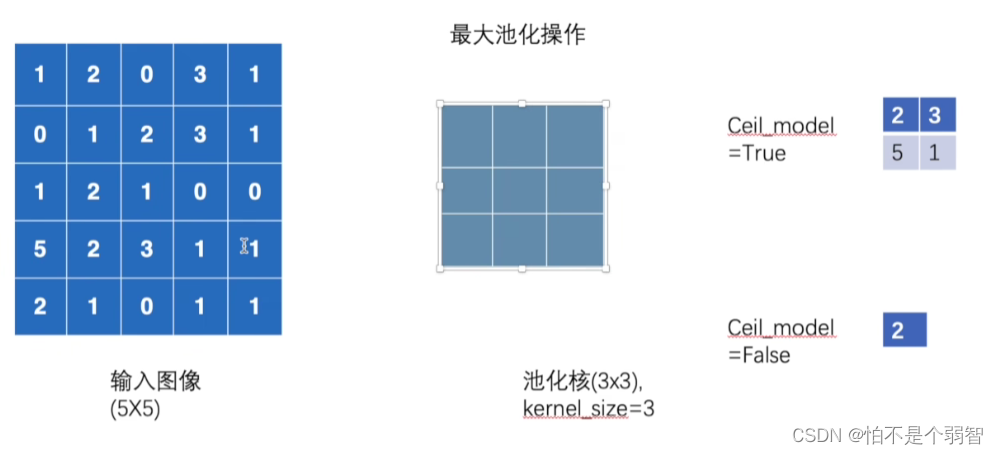
-
具体的代码实现:
import torch from torch import nn from torch.nn import MaxPool2d input = torch.tensor([[1, 2, 0, 3, 1], [0, 1, 2, 3, 1], [1, 2, 1, 0, 0], [5, 2, 3, 1, 1], [2, 1, 0, 1, 1]], dtype=torch.float32) input = torch.reshape(input, (-1, 1, 5, 5)) print(input.shape) class Tudui(nn.Module): def __init__(self): super(Tudui, self).__init__() self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=False) def forward(self, input): output = self.maxpool1(input) return output tudui = Tudui() output = tudui(input) print(output) # 当ceil_mode=False时,输出tensor([[[[2.]]]]) tensor([[[[2., 3.], [5., 1.]]]])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
使用数据集进行池化操作并记录
import torch import torchvision from torch import nn from torch.nn import MaxPool2d from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter dataset = torchvision.datasets.CIFAR10("../data", train=False, download=True, transform=torchvision.transforms.ToTensor()) dataloader = DataLoader(dataset, batch_size=64) class Tudui(nn.Module): def __init__(self): super(Tudui, self).__init__() self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=False) def forward(self, input): output = self.maxpool1(input) return output tudui = Tudui() writer = SummaryWriter("../logs_maxpool") step = 0 for data in dataloader: imgs, targets = data writer.add_images("input", imgs, step) output = tudui(imgs) writer.add_images("output", output, step) step = step + 1 writer.close()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
池化的作用
(1)保留主要特征的同时减少参数和计算量,防止过拟合。
(2)invariance(不变性),这种不变性包括translation(平移),rotation(旋转),scale(尺度)。
Pooling 层说到底还是一个特征选择,信息过滤的过程。也就是说我们损失了一部分信息,这是一个和计算性能的一个妥协,随着运算速度的不断提高,妥协会越来越小。
现在有些网络都开始少用或者不用pooling层了。
各类池化
- 平均池化(avgpooling)可以保留背景信息。在feature map上以窗口的形式进行滑动(类似卷积的窗口滑动),操作为取窗口内的平均值作为结果,经过操作后,feature map降采样,减少了过拟合现象。前向传播就是把一个patch中的值求取平均来做pooling,那么反向传播的过程也就是把某个元素的梯度等分为n份分配给前一层,这样就保证池化前后的梯度(残差)之和保持不变。
- 最大池化(maxpooling)可以提取特征纹理。减少无用信息的影响。maxpooling也要满足梯度之和不变的原则,max pooling的前向传播是把patch中最大的值传递给后一层,而其他像素的值直接被舍弃掉。那么反向传播也就是把梯度直接传给前一层某一个像素,而其他像素不接受梯度,也就是为0。所以max pooling操作和mean pooling操作不同点在于需要记录下池化操作时到底哪个像素的值是最大,也就是max id,这个变量就是记录最大值所在位置的,因为在反向传播中要用到。
- 全局池化(global pooling)来获取全局上下文关系。不以窗口的形式取均值,而是以feature map为单位进行均值化。即一个feature map输出一个值。
-
-
相关阅读:
奉加微蓝牙芯片PHY6222,支持mesh,SRAM、可选128K-8M
Activiti可视化流程管理器
AD PCB常用系统快捷键及自定义快捷键
JVM内存模型:PC程序计数器
ERP采购收货在标准成本和移动平均价下的差别
【嵌入式】限幅电路和钳位电路 利用二极管的单向导电性
django configparser.NoSectionError: No section: ‘Samples
【ROS进阶篇】第五讲 ROS中的TF坐标变换
【无人机】四轴无人机的轨迹进行可视化和动画处理(Matlab代码实现)
acwing KMP算法java版实现
- 原文地址:https://blog.csdn.net/qq_40127785/article/details/125608172
