-
Pointnet++的改进
1、PATs: Point Attention Transformers
论文:Modeling Point Clouds with Self-Attention and Gumbel Subset Sampling2019CVPR,上海交大MoE实验室和华为诺亚方舟实验室
本文主要改进了PointNet++中的FPS的部分,使得选取的点更能处理外点,将down sampling的点选取在attention score大的点上。很形象的对比如下图:

接下来就介绍一下本文提出的两个模块。GSA:Group Shuffle Attention
这一块内容主要就是自注意力机制。本文使用了Scaled Dot-Product attention(在上面的博客也提到了),具体的GSA的详见论文中的公式(7)(8)和(11)。
对于点x,对应的特征向量是y,通过y=GSA(f)的变换,得到了点的新的特征向量y。在GSA过程中,参考(7)和(8),仍然是使用f内部的信息,与MLP其实作用是一样的,就是计算新的特征。
GSS:Gumbel Subset Sampling
主要是将Pointnet++中的FPS换成了使用Gumbel Softmax进行计算每个点的重要程度,然后根据这个概率选取down sampling的点。网络结构

从网络结构看,GSA网络类似于Pointnet++中的MLP,GSS相当于FPS。Moments
论文:Momenet: Flavor the Moments in Learning to Classify Shapes本文章提出的方法简单,基本上就是增加网络的输入。将网络的输入由点的坐标(x,y,z)增加到(x,y,z,x2,y2,z2,xy, xz, yz)。基本网络如下:
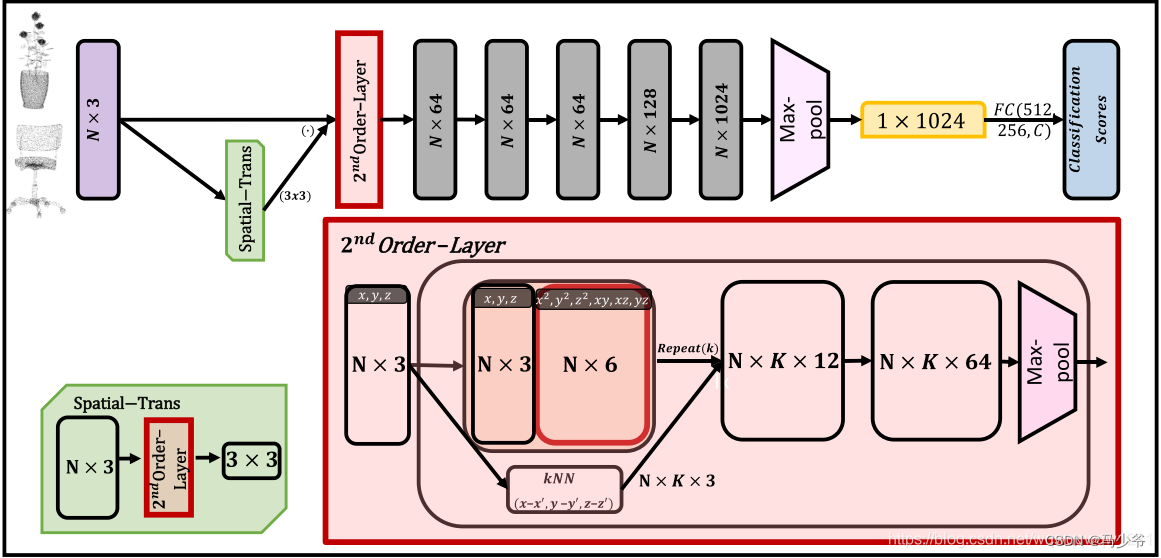
2nd Order-Layer
可以从细节看到2nd Order-Layer其实与Pointnet++非常相似,无非就是还做了人工构造了2nd Order的特征。具体的Spatial-Trans中也加入了2nd Order-Layer。
最后的效果证明,在ModelNet40的数据集上,效果很好。
参考文献:https://blog.csdn.net/wqwqqwqw1231/article/details/104183984
-
相关阅读:
Vulnhub靶机:CEREAL_ 1
【浅学Java】多线程进阶
【LeetCode】链表题总结(持续更新)
前端重新部署如何使用WebWorker优雅地通知用户刷新网页?
[南京大学2022操作系统-P11] 操作系统上的进程 (最小 Linux; fork, execve 和 exit)
k8s部署单点的mysql实例
05【NIO核心组件之Channel】
蓝桥等考C++组别八级003
elasticsearch设置密码
Pangolin安装报错解决
- 原文地址:https://blog.csdn.net/qq_27353621/article/details/125603459