本系列Netty源码解析文章基于 4.1.56.Final版本

本文笔者来为大家介绍下Netty的核心引擎Reactor的运转架构,希望通过本文的介绍能够让大家对Reactor是如何驱动着整个Netty框架的运转有一个全面的认识。也为我们后续进一步介绍Netty关于处理网络请求的整个生命周期的相关内容做一个前置知识的铺垫,方便大家后续理解。
那么在开始本文正式的内容之前,笔者先来带着大家回顾下前边文章介绍的关于Netty整个框架如何搭建的相关内容,没有看过笔者前边几篇文章的读者朋友也没关系,这些并不会影响到本文的阅读,只不过涉及到相关细节的部分,大家可以在回看下。
前文回顾
在《聊聊Netty那些事儿之Reactor在Netty中的实现(创建篇)》一文中,我们介绍了Netty服务端的核心引擎主从Reactor线程组的创建过程以及相关核心组件里的重要属性。在这个过程中,我们还提到了Netty对各种细节进行的优化,比如针对JDK NIO 原生Selector做的一些优化,展现了Netty对性能极致的追求。最终我们创建出了如下结构的Reactor。
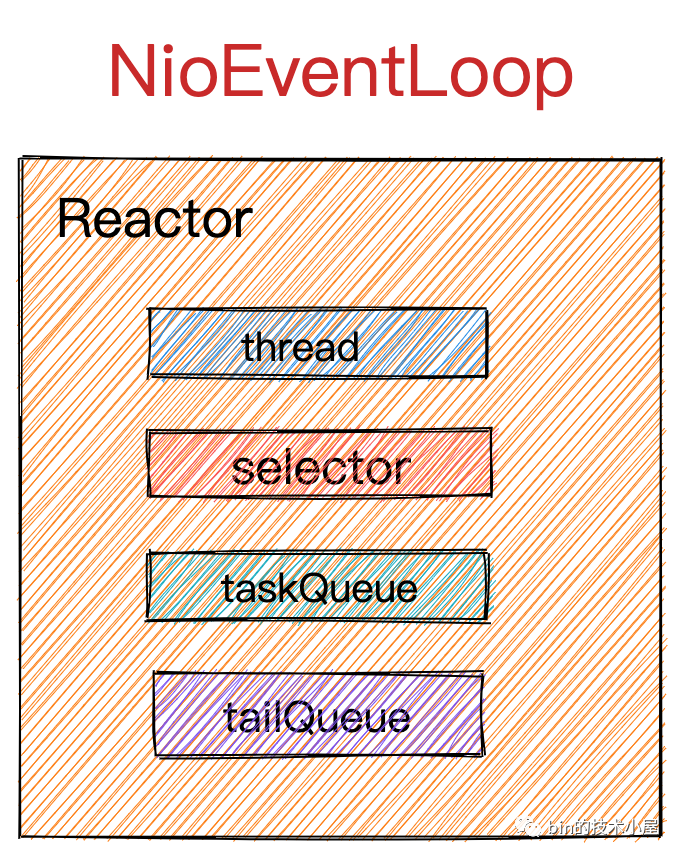
在上篇文章《详细图解Netty Reactor启动全流程》中,我们完整地介绍了Netty服务端启动的整个流程,并介绍了在启动过程中涉及到的ServerBootstrap相关的属性以及配置方式。用于接收连接的服务端NioServerSocketChannel的创建和初始化过程以及其类的继承结构。其中重点介绍了NioServerSocketChannel向Reactor的注册过程以及Reactor线程的启动时机和pipeline的初始化时机。最后介绍了NioServerSocketChannel绑定端口地址的整个流程。在这个过程中我们了解了Netty的这些核心组件是如何串联起来的。
当Netty启动完毕后,我们得到了如下的框架结构:
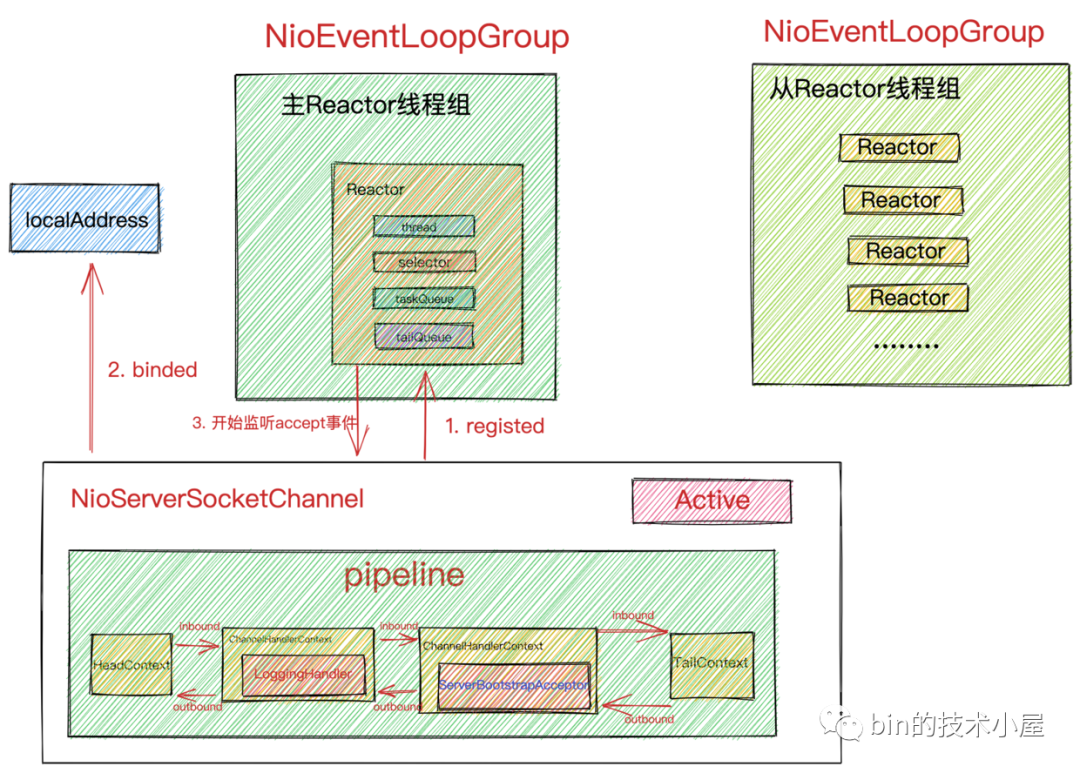
主Reactor线程组中管理的是NioServerSocketChannel用于接收客户端连接,并在自己的pipeline中的ServerBootstrapAcceptor里初始化接收到的客户端连接,随后会将初始化好的客户端连接注册到从Reactor线程组中。
从Reactor线程组主要负责监听处理注册其上的所有客户端连接的IO就绪事件。
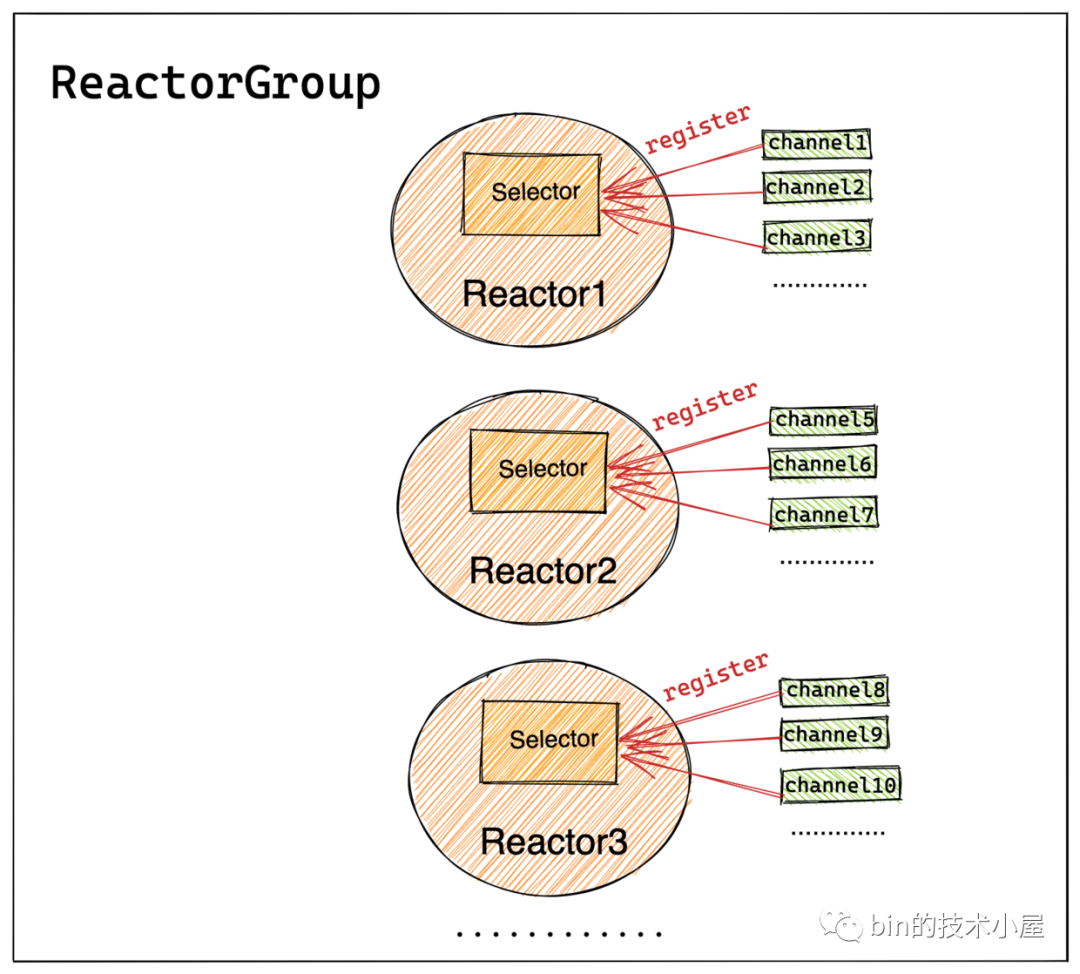
其中一个Channel只能分配给一个固定的Reactor。一个Reactor负责处理多个Channel上的IO就绪事件,这样可以将服务端承载的全量客户端连接分摊到多个Reactor中处理,同时也能保证Channel上IO处理的线程安全性。Reactor与Channel之间的对应关系如下图所示:
以上内容就是对笔者前边几篇文章的相关内容回顾,大家能回忆起来更好,回忆不起来也没关系,一点也不影响大家理解本文的内容。如果对相关细节感兴趣的同学,可以在阅读完本文之后,在去回看下。
我们言归正传,正式开始本文的内容,笔者接下来会为大家介绍这些核心组件是如何相互配合从而驱动着整个Netty Reactor框架运转的。
当Netty Reactor框架启动完毕后,接下来第一件事情也是最重要的事情就是如何来高效的接收客户端的连接。
那么在探讨Netty服务端如何接收连接之前,我们需要弄清楚Reactor线程的运行机制,它是如何监听并处理Channel上的IO就绪事件的。
本文相当于是后续我们介绍Reactor线程监听处理ACCEPT事件,Read事件,Write事件的前置篇,本文专注于讲述Reactor线程的整个运行框架。理解了本文的内容,对理解后面Reactor线程如何处理IO事件会大有帮助。
我们在Netty框架的创建阶段和启动阶段无数次的提到了Reactor线程,那么在本文要介绍的运行阶段就该这个Reactor线程来大显神威了。
经过前边文章的介绍,我们了解到Netty中的Reactor线程主要干三件事情:
-
轮询注册在
Reactor上的所有Channel感兴趣的IO就绪事件。 -
处理
Channel上的IO就绪事件。 -
执行Netty中的异步任务。
正是这三个部分组成了Reactor的运行框架,那么我们现在来看下这个运行框架具体是怎么运转的~~
Reactor线程的整个运行框架
大家还记不记得笔者在《聊聊Netty那些事儿之从内核角度看IO模型》一文中提到的,IO模型的演变是围绕着"如何用尽可能少的线程去管理尽可能多的连接"这一主题进行的。
Netty的IO模型是通过JDK NIO Selector实现的IO多路复用模型,而Netty的IO线程模型为主从Reactor线程模型。
根据《聊聊Netty那些事儿之从内核角度看IO模型》一文中介绍的IO多路复用模型我们很容易就能理解到Netty会使用一个用户态的Reactor线程去不断的通过Selector在内核态去轮训Channel上的IO就绪事件。
说白了Reactor线程其实执行的就是一个死循环,在死循环中不断的通过Selector去轮训IO就绪事件,如果发生IO就绪事件则从Selector系统调用中返回并处理IO就绪事件,如果没有发生IO就绪事件则一直阻塞在Selector系统调用上,直到满足Selector唤醒条件。
以下三个条件中只要满足任意一个条件,Reactor线程就会被从Selector上唤醒:
-
当Selector轮询到有IO活跃事件发生时。
-
当Reactor线程需要执行的
定时任务到达任务执行时间deadline时。 -
当有
异步任务提交给Reactor时,Reactor线程需要从Selector上被唤醒,这样才能及时的去执行异步任务。
这里可以看出Netty对
Reactor线程的压榨还是比较狠的,反正现在也没有IO就绪事件需要去处理,不能让Reactor线程在这里白白等着,要立即唤醒它,转去处理提交过来的异步任务以及定时任务。Reactor线程堪称996典范一刻不停歇地运作着。
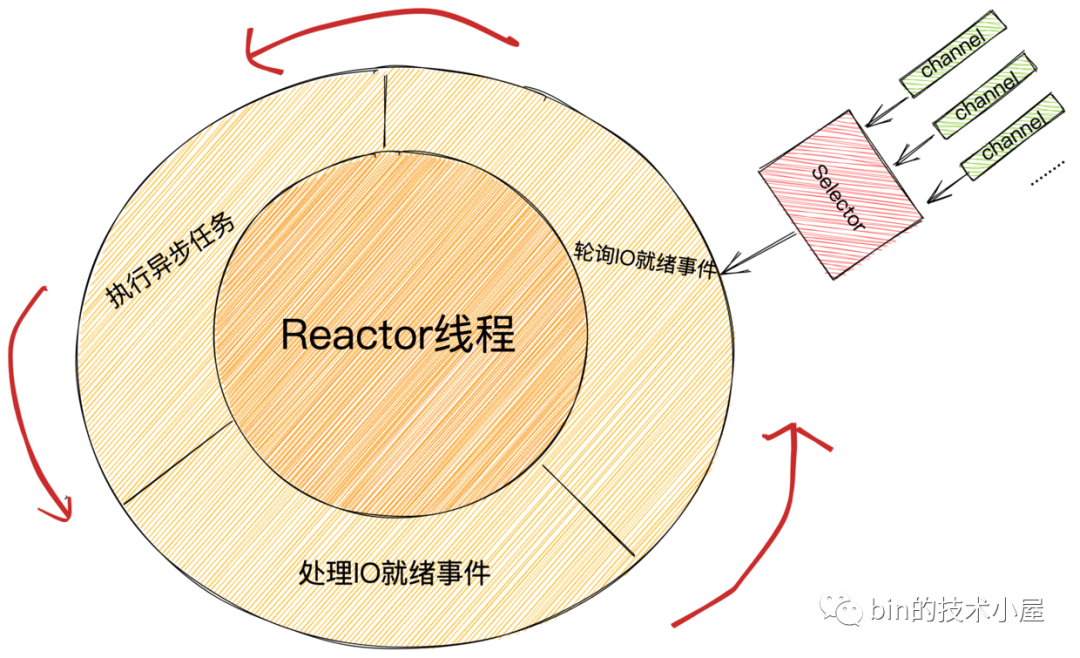
在了解了Reactor线程的大概运行框架后,我们接下来就到源码中去看下它的核心运转框架是如何实现出来的。
由于这块源码比较庞大繁杂,所以笔者先把它的运行框架提取出来,方便大家整体的理解整个运行过程的全貌。
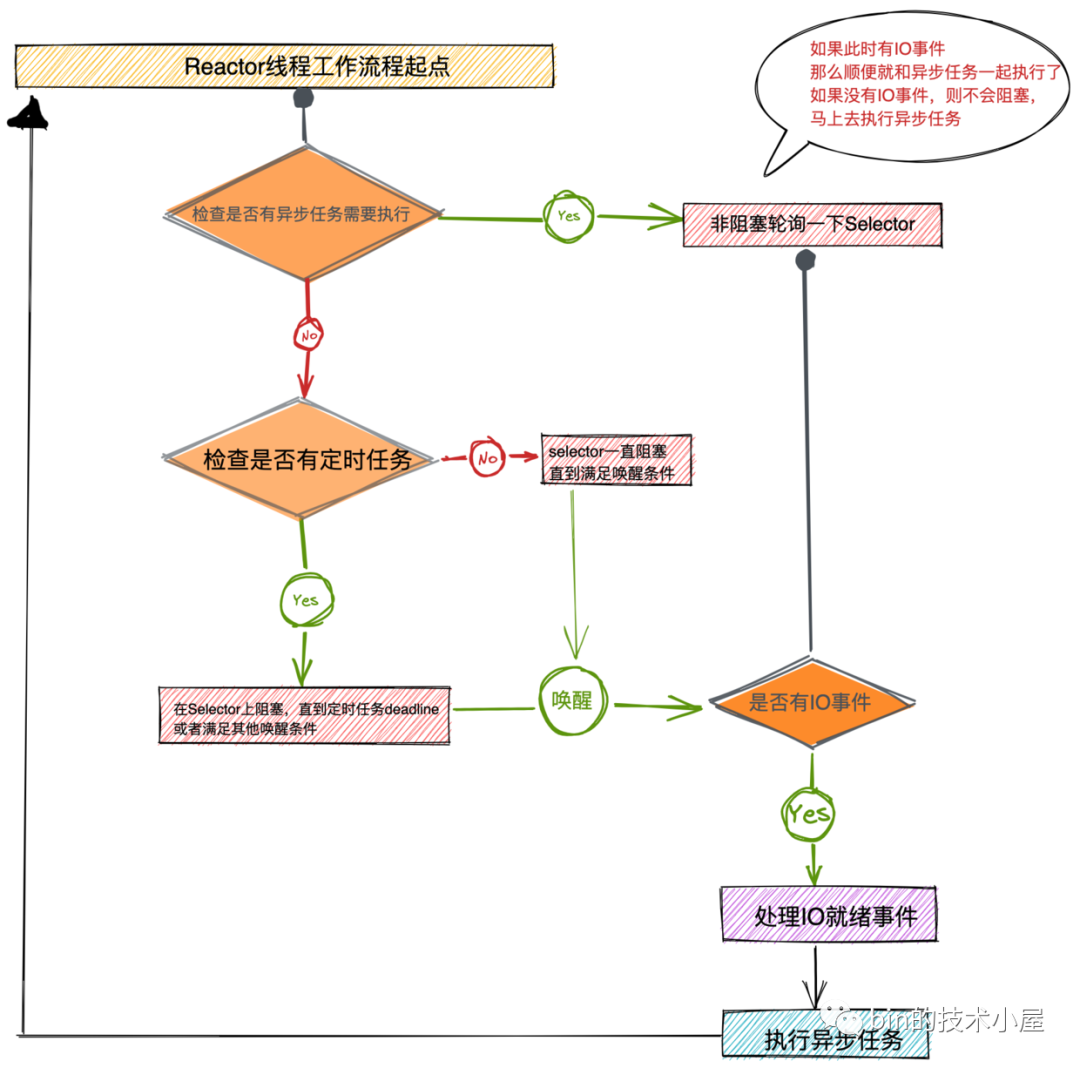
上图所展示的就是Reactor整个工作体系的全貌,主要分为如下几个重要的工作模块:
-
Reactor线程在Selector上阻塞获取IO就绪事件。在这个模块中首先会去检查当前是否有异步任务需要执行,如果有异步需要执行,那么不管当前有没有IO就绪事件都不能阻塞在Selector上,随后会去非阻塞的轮询一下Selector上是否有IO就绪事件,如果有,正好可以和异步任务一起执行。优先处理IO就绪事件,在执行异步任务。
-
如果当前没有异步任务需要执行,那么Reactor线程会接着查看是否有定时任务需要执行,如果有则在Selector上阻塞直到定时任务的到期时间deadline,或者满足其他唤醒条件被唤醒。如果没有定时任务需要执行,Reactor线程则会在Selector上一直阻塞直到满足唤醒条件。
-
当Reactor线程满足唤醒条件被唤醒后,首先会去判断当前是因为有IO就绪事件被唤醒还是因为有异步任务需要执行被唤醒或者是两者都有。随后Reactor线程就会去处理IO就绪事件和执行异步任务。
-
最后Reactor线程返回循环起点不断的重复上述三个步骤。
以上就是Reactor线程运行的整个核心逻辑,下面是笔者根据上述核心逻辑,将Reactor的整体代码设计框架提取出来,大家可以结合上边的Reactor工作流程图,从总体上先感受下整个源码实现框架,能够把Reactor的核心处理步骤和代码中相应的处理模块对应起来即可,这里不需要读懂每一行代码,要以逻辑处理模块为单位理解。后面笔者会将这些一个一个的逻辑处理模块在单独拎出来为大家详细介绍。
@Override
protected void run() {
//记录轮询次数 用于解决JDK epoll的空轮训bug
int selectCnt = 0;
for (;;) {
try {
//轮询结果
int strategy;
try {
//根据轮询策略获取轮询结果 这里的hasTasks()主要检查的是普通队列和尾部队列中是否有异步任务等待执行
strategy = selectStrategy.calculateStrategy(selectNowSupplier, hasTasks());
switch (strategy) {
case SelectStrategy.CONTINUE:
continue;
case SelectStrategy.BUSY_WAIT:
// NIO不支持自旋(BUSY_WAIT)
case SelectStrategy.SELECT:
核心逻辑是有任务需要执行,则Reactor线程立马执行异步任务,如果没有异步任务执行,则进行轮询IO事件
default:
}
} catch (IOException e) {
................省略...............
}
执行到这里说明满足了唤醒条件,Reactor线程从selector上被唤醒开始处理IO就绪事件和执行异步任务
/**
* Reactor线程需要保证及时的执行异步任务,只要有异步任务提交,就需要退出轮询。
* 有IO事件就优先处理IO事件,然后处理异步任务
* */
selectCnt++;
//主要用于从IO就绪的SelectedKeys集合中剔除已经失效的selectKey
needsToSelectAgain = false;
//调整Reactor线程执行IO事件和执行异步任务的CPU时间比例 默认50,表示执行IO事件和异步任务的时间比例是一比一
final int ioRatio = this.ioRatio;
这里主要处理IO就绪事件,以及执行异步任务
需要优先处理IO就绪事件,然后根据ioRatio设置的处理IO事件CPU用时与异步任务CPU用时比例,
来决定执行多长时间的异步任务
//判断是否触发JDK Epoll BUG 触发空轮询
if (ranTasks || strategy > 0) {
if (selectCnt > MIN_PREMATURE_SELECTOR_RETURNS && logger.isDebugEnabled()) {
logger.debug("Selector.select() returned prematurely {} times in a row for Selector {}.",
selectCnt - 1, selector);
}
selectCnt = 0;
} else if (unexpectedSelectorWakeup(selectCnt)) { // Unexpected wakeup (unusual case)
//既没有IO就绪事件,也没有异步任务,Reactor线程从Selector上被异常唤醒 触发JDK Epoll空轮训BUG
//重新构建Selector,selectCnt归零
selectCnt = 0;
}
} catch (CancelledKeyException e) {
................省略...............
} catch (Error e) {
................省略...............
} catch (Throwable t) {
................省略...............
} finally {
................省略...............
}
}
}
折叠 从上面提取出来的Reactor的源码实现框架中,我们可以看出Reactor线程主要做了下面几个事情:
- 通过
JDK NIO Selector轮询注册在Reactor上的所有Channel感兴趣的IO事件。对于NioServerSocketChannel来说因为它主要负责接收客户端连接所以监听的是OP_ACCEPT事件,对于客户端NioSocketChannel来说因为它主要负责处理连接上的读写事件所以监听的是OP_READ和OP_WRITE事件。
这里需要注意的是netty只会自动注册
OP_READ事件,而OP_WRITE事件是在当Socket写入缓冲区以满无法继续写入发送数据时由用户自己注册。
-
如果有异步任务需要执行,则立马停止轮询操作,转去执行异步任务。这里分为两种情况:
-
既有
IO就绪事件发生,也有异步任务需要执行。则优先处理IO就绪事件,然后根据ioRatio设置的执行时间比例决定执行多长时间的异步任务。这里Reactor线程需要控制异步任务的执行时间,因为Reactor线程的核心是处理IO就绪事件,不能因为异步任务的执行而耽误了最重要的事情。 -
没有
IO就绪事件发生,但是有异步任务或者定时任务到期需要执行。则只执行异步任务,尽可能的去压榨Reactor线程。没有IO就绪事件发生也不能闲着。
这里第二种情况下只会执行
64个异步任务,目的是为了防止过度执行异步任务,耽误了最重要的事情轮询IO事件。 -
-
在最后Netty会判断本次
Reactor线程的唤醒是否是由于触发了JDK epoll 空轮询 BUG导致的,如果触发了该BUG,则重建Selector。绕过JDK BUG,达到解决问题的目的。
正常情况下Reactor线程从Selector中被唤醒有两种情况:
- 轮询到有IO就绪事件发生。
- 有异步任务或者定时任务需要执行。
而JDK epoll 空轮询 BUG会在上述两种情况都没有发生的时候,Reactor线程会意外的从Selector中被唤醒,导致CPU空转。
JDK epoll 空轮询 BUG:https://bugs.java.com/bugdatabase/view_bug.do?bug_id=6670302
好了,Reactor线程的总体运行结构框架我们现在已经了解了,下面我们来深入到这些核心处理模块中来各个击破它们~~
1. Reactor线程轮询IO就绪事件
在《聊聊Netty那些事儿之Reactor在Netty中的实现(创建篇)》一文中,笔者在讲述主从Reactor线程组NioEventLoopGroup的创建过程的时候,提到一个构造器参数SelectStrategyFactory 。
public NioEventLoopGroup(
int nThreads, Executor executor, final SelectorProvider selectorProvider) {
this(nThreads, executor, selectorProvider, DefaultSelectStrategyFactory.INSTANCE);
}
public NioEventLoopGroup(int nThreads, Executor executor, final SelectorProvider selectorProvider,
final SelectStrategyFactory selectStrategyFactory) {
super(nThreads, executor, selectorProvider, selectStrategyFactory, RejectedExecutionHandlers.reject());
}
Reactor线程最重要的一件事情就是轮询IO就绪事件,SelectStrategyFactory 就是用于指定轮询策略的,默认实现为DefaultSelectStrategyFactory.INSTANCE。
而在Reactor线程开启轮询的一开始,就是用这个selectStrategy 去计算一个轮询策略strategy ,后续会根据这个strategy 进行不同的逻辑处理。
@Override
protected void run() {
//记录轮询次数 用于解决JDK epoll的空轮训bug
int selectCnt = 0;
for (;;) {
try {
//轮询结果
int strategy;
try {
//根据轮询策略获取轮询结果 这里的hasTasks()主要检查的是普通队列和尾部队列中是否有异步任务等待执行
strategy = selectStrategy.calculateStrategy(selectNowSupplier, hasTasks());
switch (strategy) {
case SelectStrategy.CONTINUE:
continue;
case SelectStrategy.BUSY_WAIT:
// NIO不支持自旋(BUSY_WAIT)
case SelectStrategy.SELECT:
核心逻辑是有任务需要执行,则Reactor线程立马执行异步任务,如果没有异步任务执行,则进行轮询IO事件
default:
}
} catch (IOException e) {
................省略...............
}
................省略...............
}
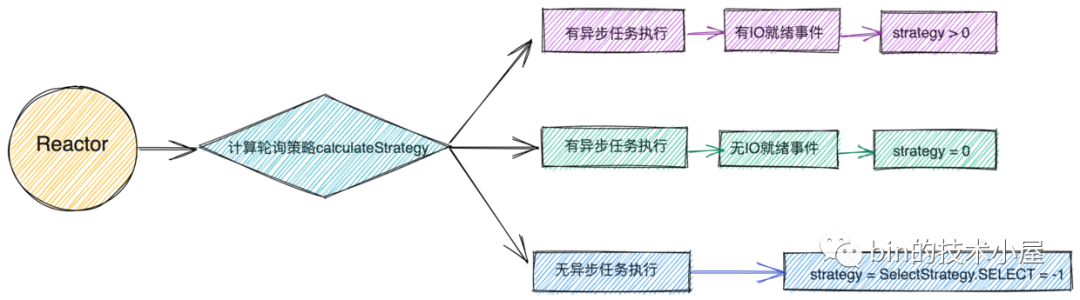
折叠 下面我们来看这个轮询策略strategy 具体的计算逻辑是什么样的?
1.1 轮询策略
public interface SelectStrategy {
/**
* Indicates a blocking select should follow.
*/
int SELECT = -1;
/**
* Indicates the IO loop should be retried, no blocking select to follow directly.
*/
int CONTINUE = -2;
/**
* Indicates the IO loop to poll for new events without blocking.
*/
int BUSY_WAIT = -3;
int calculateStrategy(IntSupplier selectSupplier, boolean hasTasks) throws Exception;
}
我们首先来看下Netty中定义的这三种轮询策略:
-
SelectStrategy.SELECT:此时没有任何异步任务需要执行,Reactor线程可以安心的阻塞在Selector上等待IO就绪事件的来临。 -
SelectStrategy.CONTINUE:重新开启一轮IO轮询。 -
SelectStrategy.BUSY_WAIT:Reactor线程进行自旋轮询,由于NIO 不支持自旋操作,所以这里直接跳到SelectStrategy.SELECT策略。
下面我们来看下轮询策略的计算逻辑calculateStrategy :
final class DefaultSelectStrategy implements SelectStrategy {
static final SelectStrategy INSTANCE = new DefaultSelectStrategy();
private DefaultSelectStrategy() { }
@Override
public int calculateStrategy(IntSupplier selectSupplier, boolean hasTasks) throws Exception {
/**
* Reactor线程要保证及时的执行异步任务
* 1:如果有异步任务等待执行,则马上执行selectNow()非阻塞轮询一次IO就绪事件
* 2:没有异步任务,则跳到switch select分支
* */
return hasTasks ? selectSupplier.get() : SelectStrategy.SELECT;
}
}
- 在
Reactor线程的轮询工作开始之前,需要首先判断下当前是否有异步任务需要执行。判断依据就是查看Reactor中的异步任务队列taskQueue和用于统计信息任务用的尾部队列tailTask是否有异步任务。
@Override
protected boolean hasTasks() {
return super.hasTasks() || !tailTasks.isEmpty();
}
protected boolean hasTasks() {
assert inEventLoop();
return !taskQueue.isEmpty();
}
- 如果
Reactor中有异步任务需要执行,那么Reactor线程需要立即执行,不能阻塞在Selector上。在返回前需要再顺带调用selectNow()非阻塞查看一下当前是否有IO就绪事件发生。如果有,那么正好可以和异步任务一起被处理,如果没有,则及时地处理异步任务。
这里Netty要表达的语义是:首先Reactor线程需要优先保证
IO就绪事件的处理,然后在保证异步任务的及时执行。如果当前没有IO就绪事件但是有异步任务需要执行时,Reactor线程就要去及时执行异步任务而不是继续阻塞在Selector上等待IO就绪事件。
private final IntSupplier selectNowSupplier = new IntSupplier() {
@Override
public int get() throws Exception {
return selectNow();
}
};
int selectNow() throws IOException {
//非阻塞
return selector.selectNow();
}
- 如果当前
Reactor线程没有异步任务需要执行,那么calculateStrategy方法直接返回SelectStrategy.SELECT也就是SelectStrategy接口中定义的常量-1。当calculateStrategy方法通过selectNow()返回非零数值时,表示此时有IO就绪的Channel,返回的数值表示有多少个IO就绪的Channel。
@Override
protected void run() {
//记录轮询次数 用于解决JDK epoll的空轮训bug
int selectCnt = 0;
for (;;) {
try {
//轮询结果
int strategy;
try {
//根据轮询策略获取轮询结果 这里的hasTasks()主要检查的是普通队列和尾部队列中是否有异步任务等待执行
strategy = selectStrategy.calculateStrategy(selectNowSupplier, hasTasks());
switch (strategy) {
case SelectStrategy.CONTINUE:
continue;
case SelectStrategy.BUSY_WAIT:
// NIO不支持自旋(BUSY_WAIT)
case SelectStrategy.SELECT:
核心逻辑是有任务需要执行,则Reactor线程立马执行异步任务,如果没有异步任务执行,则进行轮询IO事件
default:
}
} catch (IOException e) {
................省略...............
}
................处理IO就绪事件以及执行异步任务...............
}
折叠 从默认的轮询策略我们可以看出selectStrategy.calculateStrategy只会返回三种情况:
-
返回 -1:switch逻辑分支进入SelectStrategy.SELECT分支,表示此时Reactor中没有异步任务需要执行,Reactor线程可以安心的阻塞在Selector上等待IO就绪事件发生。 -
返回 0:switch逻辑分支进入default分支,表示此时Reactor中没有IO就绪事件但是有异步任务需要执行,流程通过default分支直接进入了处理异步任务的逻辑部分。 -
返回 > 0:switch逻辑分支进入default分支,表示此时Reactor中既有IO就绪事件发生也有异步任务需要执行,流程通过default分支直接进入了处理IO就绪事件和执行异步任务逻辑部分。
现在Reactor的流程处理逻辑走向我们清楚了,那么接下来我们把重点放在SelectStrategy.SELECT分支中的轮询逻辑上。这块是Reactor监听IO就绪事件的核心。
1.2 轮询逻辑
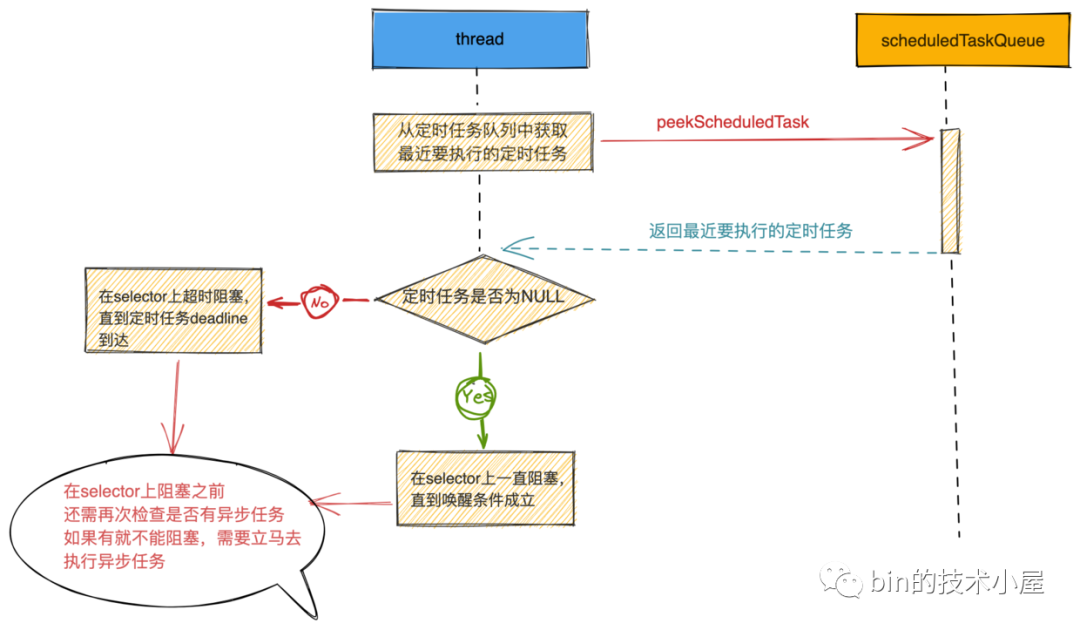
case SelectStrategy.SELECT:
//当前没有异步任务执行,Reactor线程可以放心的阻塞等待IO就绪事件
//从定时任务队列中取出即将快要执行的定时任务deadline
long curDeadlineNanos = nextScheduledTaskDeadlineNanos();
if (curDeadlineNanos == -1L) {
// -1代表当前定时任务队列中没有定时任务
curDeadlineNanos = NONE; // nothing on the calendar
}
//最早执行定时任务的deadline作为 select的阻塞时间,意思是到了定时任务的执行时间
//不管有无IO就绪事件,必须唤醒selector,从而使reactor线程执行定时任务
nextWakeupNanos.set(curDeadlineNanos);
try {
if (!hasTasks()) {
//再次检查普通任务队列中是否有异步任务
//没有的话开始select阻塞轮询IO就绪事件
strategy = select(curDeadlineNanos);
}
} finally {
// 执行到这里说明Reactor已经从Selector上被唤醒了
// 设置Reactor的状态为苏醒状态AWAKE
// lazySet优化不必要的volatile操作,不使用内存屏障,不保证写操作的可见性(单线程不需要保证)
nextWakeupNanos.lazySet(AWAKE);
}
流程走到这里,说明现在Reactor上没有任何事情可做,可以安心的阻塞在Selector上等待IO就绪事件到来。
那么Reactor线程到底应该在Selector上阻塞多久呢??
在回答这个问题之前,我们在回顾下《聊聊Netty那些事儿之Reactor在Netty中的实现(创建篇)》一文中在讲述Reactor的创建时提到,Reactor线程除了要轮询Channel上的IO就绪事件,以及处理IO就绪事件外,还有一个任务就是负责执行Netty框架中的异步任务。
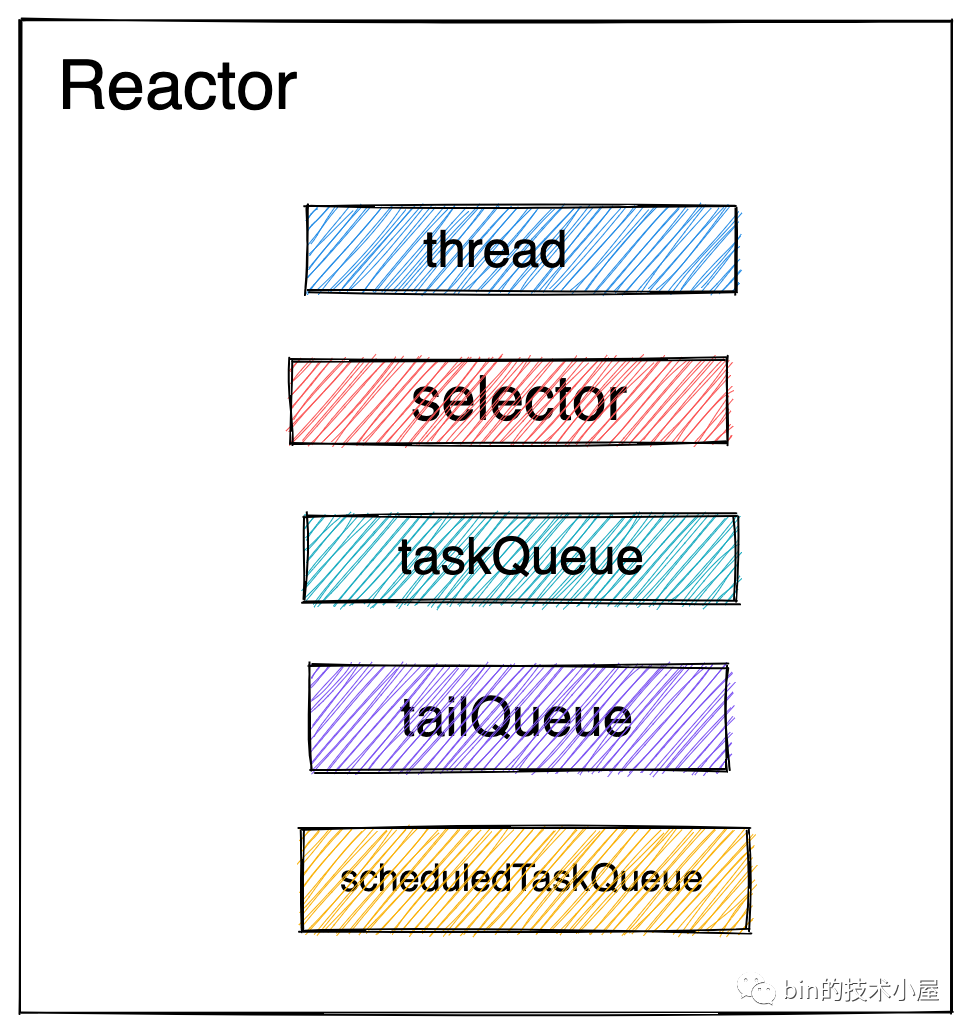
而Netty框架中的异步任务分为三类:
-
存放在普通任务队列
taskQueue中的普通异步任务。 -
存放在尾部队列
tailTasks中的用于执行统计任务等收尾动作的尾部任务。 -
还有一种就是这里即将提到的
定时任务。存放在Reactor中的定时任务队列scheduledTaskQueue中。
从ReactorNioEventLoop类中的继承结构我们也可以看出,Reactor具备执行定时任务的能力。
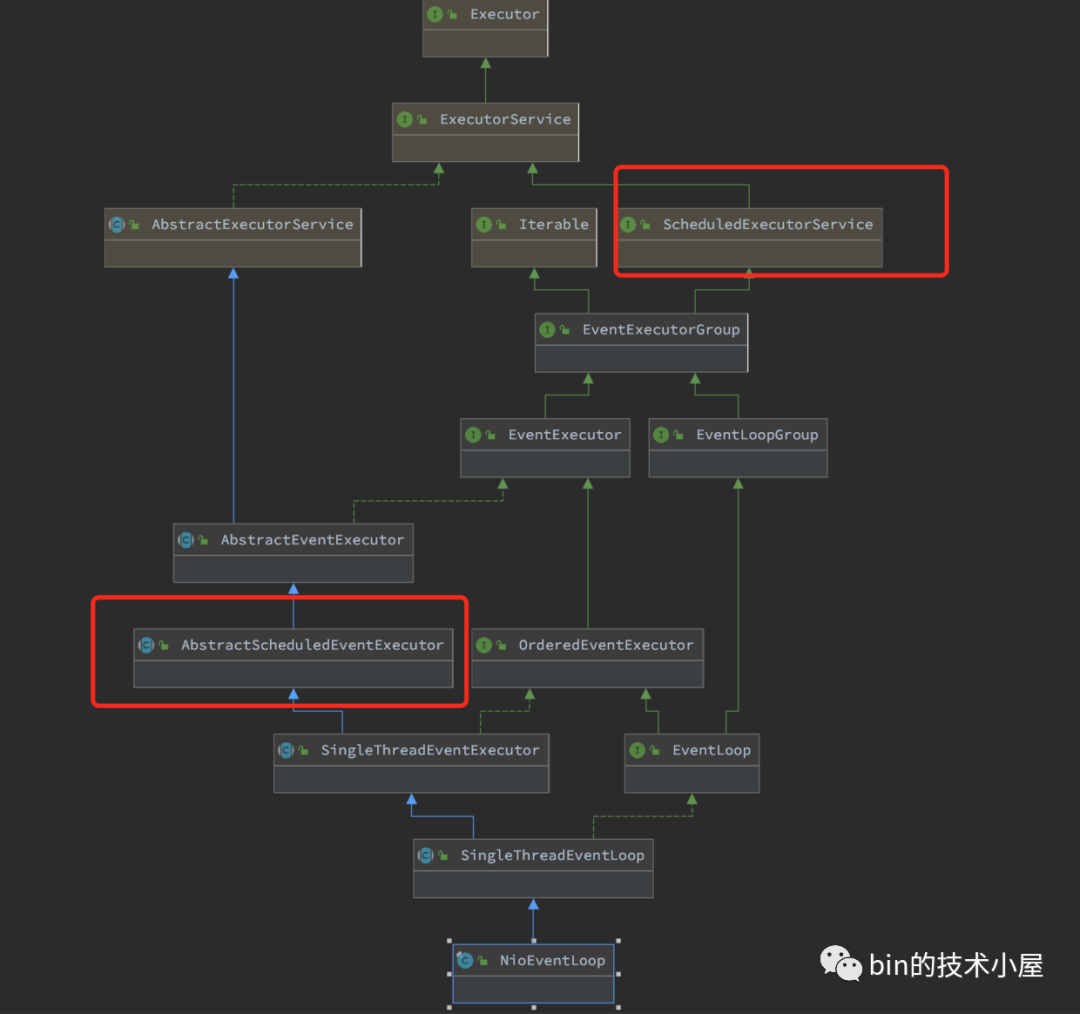
既然Reactor需要执行定时任务,那么它就不能一直阻塞在Selector上无限等待IO就绪事件。
那么我们回到本小节一开始提到的问题上,为了保证Reactor能够及时地执行定时任务,Reactor线程需要在即将要执行的的第一个定时任务deadline到达之前被唤醒。
所以在Reactor线程开始轮询IO就绪事件之前,我们需要首先计算出来Reactor线程在Selector上的阻塞超时时间。
1.2.1 Reactor的轮询超时时间
首先我们需要从Reactor的定时任务队列scheduledTaskQueue 中取出即将快要执行的定时任务deadline。将这个deadline作为Reactor线程在Selector上轮询的超时时间。这样可以保证在定时任务即将要执行时,Reactor现在可以及时的从Selector上被唤醒。
private static final long AWAKE = -1L;
private static final long NONE = Long.MAX_VALUE;
// nextWakeupNanos is:
// AWAKE when EL is awake
// NONE when EL is waiting with no wakeup scheduled
// other value T when EL is waiting with wakeup scheduled at time T
private final AtomicLong nextWakeupNanos = new AtomicLong(AWAKE);
long curDeadlineNanos = nextScheduledTaskDeadlineNanos();
if (curDeadlineNanos == -1L) {
// -1代表当前定时任务队列中没有定时任务
curDeadlineNanos = NONE; // nothing on the calendar
}
nextWakeupNanos.set(curDeadlineNanos);
public abstract class AbstractScheduledEventExecutor extends AbstractEventExecutor {
PriorityQueue<ScheduledFutureTask<?>> scheduledTaskQueue;
protected final long nextScheduledTaskDeadlineNanos() {
ScheduledFutureTask<?> scheduledTask = peekScheduledTask();
return scheduledTask != null ? scheduledTask.deadlineNanos() : -1;
}
final ScheduledFutureTask<?> peekScheduledTask() {
Queue<ScheduledFutureTask<?>> scheduledTaskQueue = this.scheduledTaskQueue;
return scheduledTaskQueue != null ? scheduledTaskQueue.peek() : null;
}
}
nextScheduledTaskDeadlineNanos 方法会返回当前Reactor定时任务队列中最近的一个定时任务deadline时间点,如果定时任务队列中没有定时任务,则返回-1。
NioEventLoop中nextWakeupNanos 变量用来存放Reactor从Selector上被唤醒的时间点,设置为最近需要被执行定时任务的deadline,如果当前并没有定时任务需要执行,那么就设置为Long.MAX_VALUE一直阻塞,直到有IO就绪事件到达或者有异步任务需要执行。
1.2.2 Reactor开始轮询IO就绪事件
if (!hasTasks()) {
//再次检查普通任务队列中是否有异步任务, 没有的话 开始select阻塞轮询IO就绪事件
strategy = select(curDeadlineNanos);
}
在Reactor线程开始阻塞轮询IO就绪事件之前还需要再次检查一下是否有异步任务需要执行。
如果此时恰巧有异步任务提交,就需要停止IO就绪事件的轮询,转去执行异步任务。如果没有异步任务,则正式开始轮询IO就绪事件。
private int select(long deadlineNanos) throws IOException {
if (deadlineNanos == NONE) {
//无定时任务,无普通任务执行时,开始轮询IO就绪事件,没有就一直阻塞 直到唤醒条件成立
return selector.select();
}
long timeoutMillis = deadlineToDelayNanos(deadlineNanos + 995000L) / 1000000L;
return timeoutMillis <= 0 ? selector.selectNow() : selector.select(timeoutMillis);
}
如果deadlineNanos == NONE,经过上小节的介绍,我们知道NONE
表示当前Reactor中并没有定时任务,所以可以安心的阻塞在Selector上等待IO就绪事件到来。
selector.select()调用是一个阻塞调用,如果没有IO就绪事件,Reactor线程就会一直阻塞在这里直到IO就绪事件到来。这里占时不考虑前边提到的JDK NIO Epoll的空轮询BUG.
读到这里那么问题来了,此时Reactor线程正阻塞在selector.select()调用上等待IO就绪事件的到来,如果此时正好有异步任务被提交到Reactor中需要执行,并且此时无任何IO就绪事件,而Reactor线程由于没有IO就绪事件到来,会继续在这里阻塞,那么如何去执行异步任务呢??

解铃还须系铃人,既然异步任务在被提交后希望立马得到执行,那么就在提交异步任务的时候去唤醒Reactor线程。
//addTaskWakesUp = true 表示 当且仅当只有调用addTask方法时 才会唤醒Reactor线程
//addTaskWakesUp = false 表示 并不是只有addTask方法才能唤醒Reactor 还有其他方法可以唤醒Reactor 默认设置false
private final boolean addTaskWakesUp;
private void execute(Runnable task, boolean immediate) {
boolean inEventLoop = inEventLoop();
addTask(task);
if (!inEventLoop) {
//如果当前线程不是Reactor线程,则启动Reactor线程
//这里可以看出Reactor线程的启动是通过 向NioEventLoop添加异步任务时启动的
startThread();
.....................省略...................
}
if (!addTaskWakesUp && immediate) {
//io.netty.channel.nio.NioEventLoop.wakeup
wakeup(inEventLoop);
}
}
对于execute方法我想大家一定不会陌生,在上篇文章《详细图解Netty Reactor启动全流程》中我们在介绍Reactor线程的启动时介绍过该方法。
在启动过程中涉及到的重要操作Register操作,Bind操作都需要封装成异步任务通过该方法提交到Reactor中执行。
这里我们将重点放在execute方法后半段wakeup逻辑部分。
我们先介绍下和wakeup逻辑相关的两个参数boolean immediate和boolean addTaskWakesUp。
-
immediate:表示提交的task是否需要被立即执行。Netty中只要你提交的任务类型不是LazyRunnable类型的任务,都是需要立即执行的。immediate = true -
addTaskWakesUp :true表示当且仅当只有调用addTask方法时才会唤醒Reactor线程。调用别的方法并不会唤醒Reactor线程。
在初始化NioEventLoop时会设置为false,表示并不是只有addTask方法才能唤醒Reactor线程还有其他方法可以唤醒Reactor线程,比如这里的execute方法就会唤醒Reactor线程。
针对execute方法中的这个唤醒条件!addTaskWakesUp && immediate,netty这里要表达的语义是:当immediate参数为true的时候表示该异步任务需要立即执行,addTaskWakesUp 默认设置为false 表示不仅只有addTask方法可以唤醒Reactor,还有其他方法比如这里的execute方法也可以唤醒。但是当设置为true时,语义就变为只有addTask才可以唤醒Reactor,即使execute方法里的immediate = true也不能唤醒Reactor,因为执行的是execute方法而不是addTask方法。
private static final long AWAKE = -1L;
private final AtomicLong nextWakeupNanos = new AtomicLong(AWAKE);
protected void wakeup(boolean inEventLoop) {
if (!inEventLoop && nextWakeupNanos.getAndSet(AWAKE) != AWAKE) {
//将Reactor线程从Selector上唤醒
selector.wakeup();
}
}
当nextWakeupNanos = AWAKE时表示当前Reactor正处于苏醒状态,既然是苏醒状态也就没有必要去执行 selector.wakeup()重复唤醒Reactor了,同时也能省去这一次的系统调用开销。
在《1.2小节 轮询逻辑》开始介绍的源码实现框架里Reactor被唤醒之后执行代码会进入finally{...}语句块中,在那里会将nextWakeupNanos设置为AWAKE。
try {
if (!hasTasks()) {
strategy = select(curDeadlineNanos);
}
} finally {
// 执行到这里说明Reactor已经从Selector上被唤醒了
// 设置Reactor的状态为苏醒状态AWAKE
// lazySet优化不必要的volatile操作,不使用内存屏障,不保证写操作的可见性(单线程不需要保证)
nextWakeupNanos.lazySet(AWAKE);
}
这里Netty用了一个
AtomicLong类型的变量nextWakeupNanos,既能表示当前Reactor线程的状态,又能表示Reactor线程的阻塞超时时间。我们在日常开发中也可以学习下这种技巧。
我们继续回到Reactor线程轮询IO就绪事件的主线上。
private int select(long deadlineNanos) throws IOException {
if (deadlineNanos == NONE) {
//无定时任务,无普通任务执行时,开始轮询IO就绪事件,没有就一直阻塞 直到唤醒条件成立
return selector.select();
}
long timeoutMillis = deadlineToDelayNanos(deadlineNanos + 995000L) / 1000000L;
return timeoutMillis <= 0 ? selector.selectNow() : selector.select(timeoutMillis);
}
当deadlineNanos不为NONE,表示此时Reactor有定时任务需要执行,Reactor线程需要阻塞在Selector上等待IO就绪事件直到最近的一个定时任务执行时间点deadline到达。
这里的deadlineNanos表示的就是Reactor中最近的一个定时任务执行时间点deadline,单位是纳秒。指的是一个绝对时间。
而我们需要计算的是Reactor线程阻塞在Selector的超时时间timeoutMillis,单位是毫秒,指的是一个相对时间。
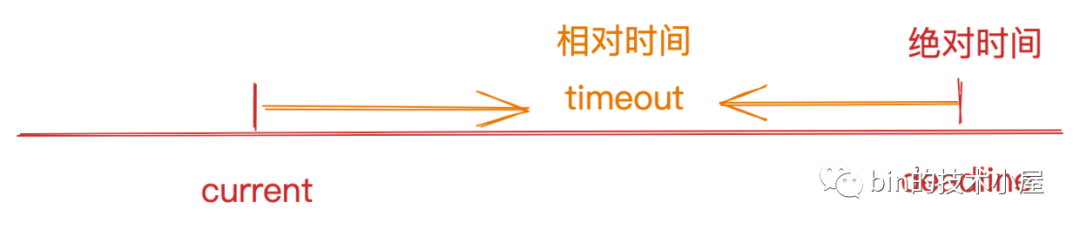
所以在Reactor线程开始阻塞在Selector上之前,我们需要将这个单位为纳秒的绝对时间deadlineNanos转化为单位为毫秒的相对时间timeoutMillis。
private int select(long deadlineNanos) throws IOException {
if (deadlineNanos == NONE) {
//无定时任务,无普通任务执行时,开始轮询IO就绪事件,没有就一直阻塞 直到唤醒条件成立
return selector.select();
}
long timeoutMillis = deadlineToDelayNanos(deadlineNanos + 995000L) / 1000000L;
return timeoutMillis <= 0 ? selector.selectNow() : selector.select(timeoutMillis);
}
这里大家可能会好奇,通过deadlineToDelayNanos方法计算timeoutMillis的时候,为什么要给deadlineNanos在加上0.995毫秒呢??
大家想象一下这样的场景,当最近的一个定时任务的deadline即将在5微秒内到达,那么这时将纳秒转换成毫秒计算出的timeoutMillis 会是0。
而在Netty中timeoutMillis = 0 要表达的语义是:定时任务执行时间已经到达deadline时间点,需要被执行。
而现实情况是定时任务还有5微秒才能够到达deadline,所以对于这种情况,需要在deadlineNanos在加上0.995毫秒凑成1毫秒不能让其为0。
所以从这里我们可以看出,
Reactor在有定时任务的情况下,至少要阻塞1毫秒。
public abstract class AbstractScheduledEventExecutor extends AbstractEventExecutor {
protected static long deadlineToDelayNanos(long deadlineNanos) {
return ScheduledFutureTask.deadlineToDelayNanos(deadlineNanos);
}
}
final class ScheduledFutureTask<V> extends PromiseTask<V> implements ScheduledFuture<V>, PriorityQueueNode {
static long deadlineToDelayNanos(long deadlineNanos) {
return deadlineNanos == 0L ? 0L : Math.max(0L, deadlineNanos - nanoTime());
}
//启动时间点
private static final long START_TIME = System.nanoTime();
static long nanoTime() {
return System.nanoTime() - START_TIME;
}
static long deadlineNanos(long delay) {
//计算定时任务执行deadline 去除启动时间
long deadlineNanos = nanoTime() + delay;
// Guard against overflow
return deadlineNanos < 0 ? Long.MAX_VALUE : deadlineNanos;
}
}
这里需要注意一下,在创建定时任务时会通过deadlineNanos方法计算定时任务的执行deadline,deadline的计算逻辑是当前时间点+任务延时delay-系统启动时间。这里需要扣除系统启动的时间。
所以这里在通过deadline计算延时delay(也就是timeout)的时候需要在加上系统启动的时间 : deadlineNanos - nanoTime()
当通过deadlineToDelayNanos 计算出的timeoutMillis <= 0时,表示Reactor目前有临近的定时任务需要执行,这时候就需要立马返回,不能阻塞在Selector上影响定时任务的执行。当然在返回执行定时任务前,需要在顺手通过selector.selectNow()非阻塞轮询一下Channel上是否有IO就绪事件到达,防止耽误IO事件的处理。真是操碎了心~~
当timeoutMillis > 0时,Reactor线程就可以安心的阻塞在Selector上等待IO事件的到来,直到timeoutMillis超时时间到达。
timeoutMillis <= 0 ? selector.selectNow() : selector.select(timeoutMillis)
当注册在Reactor上的Channel中有IO事件到来时,Reactor线程就会从selector.select(timeoutMillis)调用中唤醒,立即去处理IO就绪事件。
这里假设一种极端情况,如果最近的一个定时任务的deadline是在未来很远的一个时间点,这样就会使timeoutMillis的时间非常非常久,那么Reactor岂不是会一直阻塞在Selector上造成 Netty 无法工作?
笔者觉得大家现在心里应该已经有了答案,我们在《1.2.2 Reactor开始轮询IO就绪事件》小节一开始介绍过,当Reactor正在Selector上阻塞时,如果此时用户线程向Reactor提交了异步任务,Reactor线程会通过execute方法被唤醒。
流程到这里,Reactor中最重要也是最核心的逻辑:轮询Channel上的IO就绪事件的处理流程我们就讲解完了。
当Reactor轮询到有IO活跃事件或者有异步任务需要执行时,就会从Selector上被唤醒,下面就到了该介绍Reactor被唤醒之后是如何处理IO就绪事件以及如何执行异步任务的时候了。
Netty毕竟是一个网络框架,所以它会优先去处理Channel上的IO事件,基于这个事实,所以Netty不会容忍异步任务被无限制的执行从而影响IO吞吐。
Netty通过ioRatio变量来调配Reactor线程在处理IO事件和执行异步任务之间的CPU时间分配比例。
下面我们就来看下这个执行时间比例的分配逻辑是什么样的~~~
2. Reactor处理IO与处理异步任务的时间比例分配
无论什么时候,当有IO就绪事件到来时,Reactor都需要保证IO事件被及时完整的处理完,而ioRatio主要限制的是执行异步任务所需用时,防止Reactor线程处理异步任务时间过长而导致 I/O 事件得不到及时地处理。
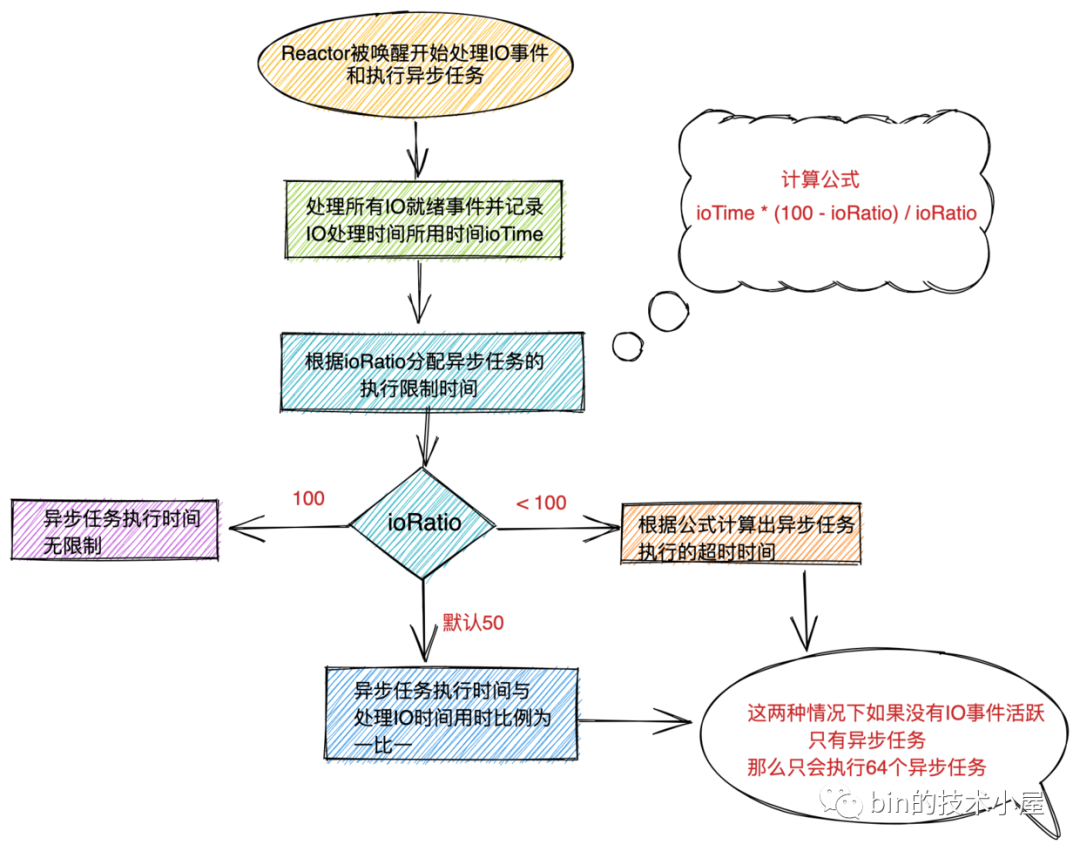
//调整Reactor线程执行IO事件和执行异步任务的CPU时间比例 默认50,表示执行IO事件和异步任务的时间比例是一比一
final int ioRatio = this.ioRatio;
boolean ranTasks;
if (ioRatio == 100) { //先一股脑执行IO事件,在一股脑执行异步任务(无时间限制)
try {
if (strategy > 0) {
//如果有IO就绪事件 则处理IO就绪事件
processSelectedKeys();
}
} finally {
// Ensure we always run tasks.
//处理所有异步任务
ranTasks = runAllTasks();
}
} else if (strategy > 0) {//先执行IO事件 用时ioTime 执行异步任务只能用时ioTime * (100 - ioRatio) / ioRatio
final long ioStartTime = System.nanoTime();
try {
processSelectedKeys();
} finally {
// Ensure we always run tasks.
final long ioTime = System.nanoTime() - ioStartTime;
// 限定在超时时间内 处理有限的异步任务 防止Reactor线程处理异步任务时间过长而导致 I/O 事件阻塞
ranTasks = runAllTasks(ioTime * (100 - ioRatio) / ioRatio);
}
} else { //没有IO就绪事件处理,则只执行异步任务 最多执行64个 防止Reactor线程处理异步任务时间过长而导致 I/O 事件阻塞
ranTasks = runAllTasks(0); // This will run the minimum number of tasks
}
折叠 - 当
ioRatio = 100时,表示无需考虑执行时间的限制,当有IO就绪事件时(strategy > 0)Reactor线程需要优先处理IO就绪事件,处理完IO事件后,执行所有的异步任务包括:普通任务,尾部任务,定时任务。无时间限制。
strategy的数值表示IO就绪的Channel个数。它是前边介绍的io.netty.channel.nio.NioEventLoop#select方法的返回值。
- 当
ioRatio设置的值不为100时,默认为50。需要先统计出执行IO事件的用时ioTime,根据ioTime * (100 - ioRatio) / ioRatio计算出,后面执行异步任务的限制时间。也就是说Reactor线程需要在这个限定的时间内,执行有限的异步任务,防止Reactor线程由于处理异步任务时间过长而导致I/O 事件得不到及时地处理。
默认情况下,执行
IO事件用时和执行异步任务用时比例设置的是一比一。
ioRatio设置的越高,则Reactor线程执行异步任务的时间占比越小。
要想得到Reactor线程执行异步任务所需的时间限制,必须知道执行IO事件的用时ioTime然后在根据ioRatio计算出执行异步任务的时间限制。
那如果此时并没有IO就绪事件需要Reactor线程处理的话,这种情况下我们无法得到ioTime,那怎么得到执行异步任务的限制时间呢??
在这种特殊情况下,Netty只允许Reactor线程最多执行64个异步任务,然后就结束执行。转去继续轮训IO就绪事件。核心目的还是防止Reactor线程由于处理异步任务时间过长而导致I/O 事件得不到及时地处理。
默认情况下,当
Reactor有异步任务需要处理但是没有IO就绪事件时,Netty只会允许Reactor线程执行最多64个异步任务。
现在我们对Reactor处理IO事件和异步任务的整体框架已经了解了,下面我们就来分别介绍下Reactor线程在处理IO事件和异步任务的具体逻辑是什么样的?
3. Reactor线程处理IO就绪事件
//该字段为持有selector对象selectedKeys的引用,当IO事件就绪时,直接从这里获取
private SelectedSelectionKeySet selectedKeys;
private void processSelectedKeys() {
//是否采用netty优化后的selectedKey集合类型 是由变量DISABLE_KEY_SET_OPTIMIZATION决定的 默认为false
if (selectedKeys != null) {
processSelectedKeysOptimized();
} else {
processSelectedKeysPlain(selector.selectedKeys());
}
}
看到这段代码大家眼熟吗??

不知大家还记不记得我们在《聊聊Netty那些事儿之Reactor在Netty中的实现(创建篇)》一文中介绍Reactor NioEventLoop类在创建Selector的过程中提到,出于对JDK NIO Selector中selectedKeys 集合的插入和遍历操作性能的考虑Netty将自己用数组实现的SelectedSelectionKeySet 集合替换掉了JDK NIO Selector中selectedKeys 的HashSet实现。
public abstract class SelectorImpl extends AbstractSelector {
// The set of keys with data ready for an operation
// //IO就绪的SelectionKey(里面包裹着channel)
protected Set<SelectionKey> selectedKeys;
// The set of keys registered with this Selector
//注册在该Selector上的所有SelectionKey(里面包裹着channel)
protected HashSet<SelectionKey> keys;
...............省略...................
}
Netty中通过优化开关DISABLE_KEY_SET_OPTIMIZATION 控制是否对JDK NIO Selector进行优化。默认是需要优化。
在优化开关开启的情况下,Netty会将创建的SelectedSelectionKeySet 集合保存在NioEventLoop的private SelectedSelectionKeySet selectedKeys字段中,方便Reactor线程直接从这里获取IO就绪的SelectionKey。
在优化开关关闭的情况下,Netty会直接采用JDK NIO Selector的默认实现。此时NioEventLoop的selectedKeys字段就会为null。
忘记这段的同学可以在回顾下《聊聊Netty那些事儿之Reactor在Netty中的实现(创建篇)》一文中关于
Reactor的创建过程。
经过对前边内容的回顾,我们看到了在Reactor处理IO就绪事件的逻辑也分为两个部分,一个是经过Netty优化的,一个是采用JDK 原生的。
我们先来看采用JDK 原生的Selector的处理方式,理解了这种方式,在看Netty优化的方式会更加容易。
3.1 processSelectedKeysPlain
我们在《聊聊Netty那些事儿之Reactor在Netty中的实现(创建篇)》一文中介绍JDK NIO Selector的工作过程时讲过,当注册在Selector上的Channel发生IO就绪事件时,Selector会将IO就绪的SelectionKey插入到Set<SelectionKey> selectedKeys集合中。
这时Reactor线程会从java.nio.channels.Selector#select(long)调用中返回。随后调用java.nio.channels.Selector#selectedKeys获取IO就绪的SelectionKey集合。
所以Reactor线程在调用processSelectedKeysPlain方法处理IO就绪事件之前需要调用selector.selectedKeys()去获取所有IO就绪的SelectionKeys。
processSelectedKeysPlain(selector.selectedKeys())
private void processSelectedKeysPlain(Set<SelectionKey> selectedKeys) {
if (selectedKeys.isEmpty()) {
return;
}
Iterator<SelectionKey> i = selectedKeys.iterator();
for (;;) {
final SelectionKey k = i.next();
final Object a = k.attachment();
//注意每次迭代末尾的keyIterator.remove()调用。Selector不会自己从已选择键集中移除SelectionKey实例。
//必须在处理完通道时自己移除。下次该通道变成就绪时,Selector会再次将其放入已选择键集中。
i.remove();
if (a instanceof AbstractNioChannel) {
processSelectedKey(k, (AbstractNioChannel) a);
} else {
@SuppressWarnings("unchecked")
NioTask<SelectableChannel> task = (NioTask<SelectableChannel>) a;
processSelectedKey(k, task);
}
if (!i.hasNext()) {
break;
}
//目的是再次进入for循环 移除失效的selectKey(socketChannel可能从selector上移除)
if (needsToSelectAgain) {
selectAgain();
selectedKeys = selector.selectedKeys();
// Create the iterator again to avoid ConcurrentModificationException
if (selectedKeys.isEmpty()) {
break;
} else {
i = selectedKeys.iterator();
}
}
}
}
折叠 3.1.1 获取IO就绪的Channel
Set<SelectionKey> selectedKeys集合里面装的全部是IO就绪的SelectionKey,注意,此时Set<SelectionKey> selectedKeys的实现类型为HashSet类型。因为我们这里首先介绍的是JDK NIO 原生实现。
通过获取HashSet的迭代器,开始逐个处理IO就绪的Channel。
Iterator<SelectionKey> i = selectedKeys.iterator();
final SelectionKey k = i.next();
final Object a = k.attachment();
大家还记得这个SelectionKey中的attachment属性里存放的是什么吗??
在上篇文章《详细图解Netty Reactor启动全流程》中我们在讲NioServerSocketChannel向Main Reactor注册的时候,通过this指针将自己作为SelectionKey的attachment属性注册到Selector中。这一步完成了Netty自定义Channel和JDK NIO Channel的绑定。

public abstract class AbstractNioChannel extends AbstractChannel {
//channel注册到Selector后获得的SelectKey
volatile SelectionKey selectionKey;
@Override
protected void doRegister() throws Exception {
boolean selected = false;
for (;;) {
try {
selectionKey = javaChannel().register(eventLoop().unwrappedSelector(), 0, this);
return;
} catch (CancelledKeyException e) {
...............省略....................
}
}
}
}
而我们也提到SelectionKey就相当于是Channel在Selector中的一种表示,当Channel上有IO就绪事件时,Selector会将Channel对应的SelectionKey返回给Reactor线程,我们可以通过返回的这个SelectionKey里的attachment属性获取到对应的Netty自定义Channel。
对于客户端连接事件(
OP_ACCEPT)活跃时,这里的Channel类型为NioServerSocketChannel。
对于客户端读写事件(Read,Write)活跃时,这里的Channel类型为NioSocketChannel。
当我们通过k.attachment()获取到Netty自定义的Channel时,就需要把这个Channel对应的SelectionKey从Selector的就绪集合Set<SelectionKey> selectedKeys中删除。因为Selector自己不会主动删除已经处理完的SelectionKey,需要调用者自己主动删除,这样当这个Channel再次IO就绪时,Selector会再次将这个Channel对应的SelectionKey放入就绪集合Set<SelectionKey> selectedKeys中。
i.remove();
3.1.2 处理Channel上的IO事件
if (a instanceof AbstractNioChannel) {
processSelectedKey(k, (AbstractNioChannel) a);
} else {
@SuppressWarnings("unchecked")
NioTask<SelectableChannel> task = (NioTask<SelectableChannel>) a;
processSelectedKey(k, task);
}
从这里我们可以看出Netty向SelectionKey中的attachment属性附加的对象分为两种:
-
一种是我们熟悉的
Channel,无论是服务端使用的NioServerSocketChannel还是客户端使用的NioSocketChannel都属于AbstractNioChannel。Channel上的IO事件是由Netty框架负责处理,也是本小节我们要重点介绍的 -
另一种就是
NioTask,这种类型是Netty提供给用户可以自定义一些当Channel上发生IO就绪事件时的自定义处理。
public interface NioTask<C extends SelectableChannel> {
/**
* Invoked when the {@link SelectableChannel} has been selected by the {@link Selector}.
*/
void channelReady(C ch, SelectionKey key) throws Exception;
/**
* Invoked when the {@link SelectionKey} of the specified {@link SelectableChannel} has been cancelled and thus
* this {@link NioTask} will not be notified anymore.
*
* @param cause the cause of the unregistration. {@code null} if a user called {@link SelectionKey#cancel()} or
* the event loop has been shut down.
*/
void channelUnregistered(C ch, Throwable cause) throws Exception;
}
NioTask和Channel其实本质上是一样的都是负责处理Channel上的IO就绪事件,只不过一个是用户自定义处理,一个是Netty框架处理。这里我们重点关注Channel的IO处理逻辑
private void processSelectedKey(SelectionKey k, AbstractNioChannel ch) {
//获取Channel的底层操作类Unsafe
final AbstractNioChannel.NioUnsafe unsafe = ch.unsafe();
if (!k.isValid()) {
......如果SelectionKey已经失效则关闭对应的Channel......
}
try {
//获取IO就绪事件
int readyOps = k.readyOps();
//处理Connect事件
if ((readyOps & SelectionKey.OP_CONNECT) != 0) {
int ops = k.interestOps();
//移除对Connect事件的监听,否则Selector会一直通知
ops &= ~SelectionKey.OP_CONNECT;
k.interestOps(ops);
//触发channelActive事件处理Connect事件
unsafe.finishConnect();
}
//处理Write事件
if ((readyOps & SelectionKey.OP_WRITE) != 0) {
ch.unsafe().forceFlush();
}
//处理Read事件或者Accept事件
if ((readyOps & (SelectionKey.OP_READ | SelectionKey.OP_ACCEPT)) != 0 || readyOps == 0) {
unsafe.read();
}
} catch (CancelledKeyException ignored) {
unsafe.close(unsafe.voidPromise());
}
}
折叠 - 首先我们需要获取
IO就绪Channel底层的操作类Unsafe,用于对具体IO就绪事件的处理。
这里可以看出,Netty对
IO就绪事件的处理全部封装在Unsafe类中。比如:对OP_ACCEPT事件的具体处理逻辑是封装在NioServerSocketChannel中的UnSafe类中。对OP_READ或者OP_WRITE事件的处理是封装在NioSocketChannel中的Unsafe类中。
- 从
Selectionkey中获取具体IO就绪事件 readyOps。
SelectonKey中关于IO事件的集合有两个。一个是interestOps,用于记录Channel感兴趣的IO事件,在Channel向Selector注册完毕后,通过pipeline中的HeadContext节点的ChannelActive事件回调中添加。下面这段代码就是在ChannelActive事件回调中Channel在向Selector注册自己感兴趣的IO事件。
public abstract class AbstractNioChannel extends AbstractChannel {
@Override
protected void doBeginRead() throws Exception {
// Channel.read() or ChannelHandlerContext.read() was called
final SelectionKey selectionKey = this.selectionKey;
if (!selectionKey.isValid()) {
return;
}
readPending = true;
final int interestOps = selectionKey.interestOps();
/**
* 1:ServerSocketChannel 初始化时 readInterestOp设置的是OP_ACCEPT事件
* 2:SocketChannel 初始化时 readInterestOp设置的是OP_READ事件
* */
if ((interestOps & readInterestOp) == 0) {
//注册监听OP_ACCEPT或者OP_READ事件
selectionKey.interestOps(interestOps | readInterestOp);
}
}
}
另一个就是这里的readyOps,用于记录在Channel感兴趣的IO事件中具体哪些IO事件就绪了。
Netty中将各种事件的集合用一个int型变量来保存。
-
用
&操作判断,某个事件是否在事件集合中:(readyOps & SelectionKey.OP_CONNECT) != 0,这里就是判断Channel是否对Connect事件感兴趣。 -
用
|操作向事件集合中添加事件:interestOps | readInterestOp -
从事件集合中删除某个事件,是通过先将要删除事件取反
~,然后在和事件集合做&操作:ops &= ~SelectionKey.OP_CONNECT
Netty这种对空间的极致利用思想,很值得我们平时在日常开发中学习~~
现在我们已经知道哪些Channel现在处于IO就绪状态,并且知道了具体哪些类型的IO事件已经就绪。
下面就该针对Channel上的不同IO就绪事件做出相应的处理了。
3.1.2.1 处理Connect事件
Netty客户端向服务端发起连接,并向客户端的Reactor注册Connect事件,当连接建立成功后,客户端的NioSocketChannel就会产生Connect就绪事件,通过前面内容我们讲的Reactor的运行框架,最终流程会走到这里。
if ((readyOps & SelectionKey.OP_CONNECT) != 0) {
int ops = k.interestOps();
ops &= ~SelectionKey.OP_CONNECT;
k.interestOps(ops);
//触发channelActive事件
unsafe.finishConnect();
}
如果IO就绪的事件是Connect事件,那么就调用对应客户端NioSocketChannel中的Unsafe操作类中的finishConnect方法处理Connect事件。这时会在Netty客户端NioSocketChannel中的pipeline中传播ChannelActive事件。
最后需要将OP_CONNECT事件从客户端NioSocketChannel所关心的事件集合interestOps中删除。否则Selector会一直通知Connect事件就绪。
3.1.2.2 处理Write事件
关于Reactor线程处理Netty中的Write事件的流程,笔者后续会专门用一篇文章来为大家介绍。本文我们重点关注Reactor线程的整体运行框架。
if ((readyOps & SelectionKey.OP_WRITE) != 0) {
ch.unsafe().forceFlush();
}
这里大家只需要记住,OP_WRITE事件的注册是由用户来完成的,当Socket发送缓冲区已满无法继续写入数据时,用户会向Reactor注册OP_WRITE事件,等到Socket发送缓冲区变得可写时,Reactor会收到OP_WRITE事件活跃通知,随后在这里调用客户端NioSocketChannel中的forceFlush方法将剩余数据发送出去。
3.1.2.3 处理Read事件或者Accept事件
if ((readyOps & (SelectionKey.OP_READ | SelectionKey.OP_ACCEPT)) != 0 || readyOps == 0) {
unsafe.read();
}
这里可以看出Netty中处理Read事件和Accept事件都是由对应Channel中的Unsafe操作类中的read方法处理。
服务端NioServerSocketChannel中的Read方法处理的是Accept事件,客户端NioSocketChannel中的Read方法处理的是Read事件。
这里大家只需记住各个
IO事件在对应Channel中的处理入口,后续文章我们会详细分析这些入口函数。
3.1.3 从Selector中移除失效的SelectionKey
//用于及时从selectedKeys中清除失效的selectKey 比如 socketChannel从selector上被用户移除
private boolean needsToSelectAgain;
//目的是再次进入for循环 移除失效的selectKey(socketChannel可能被用户从selector上移除)
if (needsToSelectAgain) {
selectAgain();
selectedKeys = selector.selectedKeys();
// Create the iterator again to avoid ConcurrentModificationException
if (selectedKeys.isEmpty()) {
break;
} else {
i = selectedKeys.iterator();
}
}
在前边介绍Reactor运行框架的时候,我们看到在每次Reactor线程轮询结束,准备处理IO就绪事件以及异步任务的时候,都会将needsToSelectAgain 设置为false。
那么这个needsToSelectAgain 究竟是干嘛的?以及为什么我们需要去“Select Again”呢?
首先我们来看下在什么情况下会将needsToSelectAgain 这个变量设置为true,通过这个设置的过程,我们是否能够从中找到一些线索?
我们知道Channel可以将自己注册到Selector上,那么当然也可以将自己从Selector上取消移除。
在上篇文章中我们也花了大量的篇幅讲解了这个注册的过程,现在我们来看下Channel的取消注册。
public abstract class AbstractNioChannel extends AbstractChannel {
//channel注册到Selector后获得的SelectKey
volatile SelectionKey selectionKey;
@Override
protected void doDeregister() throws Exception {
eventLoop().cancel(selectionKey());
}
protected SelectionKey selectionKey() {
assert selectionKey != null;
return selectionKey;
}
}
Channel取消注册的过程很简单,直接调用NioChannel的doDeregister 方法,Channel绑定的Reactor会将其从Selector中取消并停止监听Channel上的IO事件。
public final class NioEventLoop extends SingleThreadEventLoop {
//记录Selector上移除socketChannel的个数 达到256个 则需要将无效的selectKey从SelectedKeys集合中清除掉
private int cancelledKeys;
private static final int CLEANUP_INTERVAL = 256;
/**
* 将socketChannel从selector中移除 取消监听IO事件
* */
void cancel(SelectionKey key) {
key.cancel();
cancelledKeys ++;
// 当从selector中移除的socketChannel数量达到256个,设置needsToSelectAgain为true
// 在io.netty.channel.nio.NioEventLoop.processSelectedKeysPlain 中重新做一次轮询,将失效的selectKey移除,
// 以保证selectKeySet的有效性
if (cancelledKeys >= CLEANUP_INTERVAL) {
cancelledKeys = 0;
needsToSelectAgain = true;
}
}
}
- 调用
JDK NIO SelectionKey的APIcancel方法,将Channel从Selector中取消掉。SelectionKey#cancel方法调用完毕后,此时调用SelectionKey#isValid将会返回false。SelectionKey#cancel方法调用后,Selector会将要取消的这个SelectionKey加入到Selector中的cancelledKeys集合中。
public abstract class AbstractSelector extends Selector {
private final Set<SelectionKey> cancelledKeys = new HashSet<SelectionKey>();
void cancel(SelectionKey k) {
synchronized (cancelledKeys) {
cancelledKeys.add(k);
}
}
}
-
当
Channel对应的SelectionKey取消完毕后,Channel取消计数器cancelledKeys会加1,当cancelledKeys = 256时,将needsToSelectAgain设置为true。 -
随后在
Selector的下一次轮询过程中,会将cancelledKeys集合中的SelectionKey从Selector中所有的KeySet中移除。这里的KeySet包括Selector用于存放就绪SelectionKey的selectedKeys集合,以及用于存放所有注册的Channel对应的SelectionKey的keys集合。
public abstract class SelectorImpl extends AbstractSelector {
protected Set<SelectionKey> selectedKeys = new HashSet();
protected HashSet<SelectionKey> keys = new HashSet();
.....................省略...............
}
我们看到Reactor线程中对needsToSelectAgain 的判断是在processSelectedKeysPlain方法处理IO就绪的SelectionKey的循环体中进行判断的。
之所以这里特别提到needsToSelectAgain 判断的位置,是要让大家注意到此时Reactor正在处理本次轮询的IO就绪事件。
而前边也说了,当调用SelectionKey#cancel方法后,需要等到下次轮询的过程中Selector才会将这些取消的SelectionKey从Selector中的所有KeySet集合中移除,当然这里也包括就绪集合selectedKeys 。
当在本次轮询期间,假如大量的Channel从Selector中取消,Selector中的就绪集合selectedKeys 中依然会保存这些Channel对应SelectionKey直到下次轮询。那么当然会影响本次轮询结果selectedKeys的有效性。
所以为了保证Selector中所有KeySet的有效性,需要在Channel取消个数达到256时,触发一次selectNow,目的是清除无效的SelectionKey。
private void selectAgain() {
needsToSelectAgain = false;
try {
selector.selectNow();
} catch (Throwable t) {
logger.warn("Failed to update SelectionKeys.", t);
}
}
到这里,我们就对JDK 原生 Selector的处理方式processSelectedKeysPlain方法就介绍完了,其实 对IO就绪事件的处理逻辑都是一样的,在我们理解了processSelectedKeysPlain方法后,processSelectedKeysOptimized方法对IO就绪事件的处理,我们理解起来就非常轻松了。
3.2 processSelectedKeysOptimized
Netty默认会采用优化过的Selector对IO就绪事件的处理。但是处理逻辑是大同小异的。下面我们主要介绍一下这两个方法的不同之处。
private void processSelectedKeysOptimized() {
// 在openSelector的时候将JDK中selector实现类中得selectedKeys和publicSelectKeys字段类型
// 由原来的HashSet类型替换为 Netty优化后的数组实现的SelectedSelectionKeySet类型
for (int i = 0; i < selectedKeys.size; ++i) {
final SelectionKey k = selectedKeys.keys[i];
// 对应迭代器中得remove selector不会自己清除selectedKey
selectedKeys.keys[i] = null;
final Object a = k.attachment();
if (a instanceof AbstractNioChannel) {
processSelectedKey(k, (AbstractNioChannel) a);
} else {
@SuppressWarnings("unchecked")
NioTask<SelectableChannel> task = (NioTask<SelectableChannel>) a;
processSelectedKey(k, task);
}
if (needsToSelectAgain) {
selectedKeys.reset(i + 1);
selectAgain();
i = -1;
}
}
}
-
JDK NIO 原生 Selector存放IO就绪的SelectionKey的集合为HashSet类型的selectedKeys。而Netty为了优化对selectedKeys 集合的遍历效率采用了自己实现的SelectedSelectionKeySet类型,从而用对数组的遍历代替用HashSet的迭代器遍历。 -
Selector会在每次轮询到IO就绪事件时,将IO就绪的Channel对应的SelectionKey插入到selectedKeys集合,但是Selector只管向selectedKeys集合放入IO就绪的SelectionKey,当SelectionKey被处理完毕后,Selector是不会自己主动将其从selectedKeys集合中移除的,典型的管杀不管埋。所以需要Netty自己在遍历到IO就绪的 SelectionKey后,将其删除。- 在
processSelectedKeysPlain中是直接将其从迭代器中删除。 - 在
processSelectedKeysOptimized中将其在数组中对应的位置置为Null,方便垃圾回收。
- 在
-
在最后清除无效的
SelectionKey时,在processSelectedKeysPlain中由于采用的是JDK NIO 原生的Selector,所以只需要执行SelectAgain就可以,Selector会自动清除无效Key。
但是在processSelectedKeysOptimized中由于是Netty自己实现的优化类型,所以需要Netty自己将SelectedSelectionKeySet数组中的SelectionKey全部清除,最后在执行SelectAgain。
好了,到这里,我们就将Reactor线程如何处理IO就绪事件的整个过程讲述完了,下面我们就该到了介绍Reactor线程如何处理Netty框架中的异步任务了。
4. Reactor线程处理异步任务
Netty关于处理异步任务的方法有两个:
-
一个是无超时时间限制的
runAllTasks()方法。当ioRatio设置为100时,Reactor线程会先一股脑的处理IO就绪事件,然后在一股脑的执行异步任务,并没有时间的限制。 -
另一个是有超时时间限制的
runAllTasks(long timeoutNanos)方法。当ioRatio != 100时,Reactor线程执行异步任务会有时间限制,优先一股脑的处理完IO就绪事件统计出执行IO任务耗时ioTime。根据公式ioTime * (100 - ioRatio) / ioRatio)计算出Reactor线程执行异步任务的超时时间。在超时时间限定范围内,执行有限的异步任务。
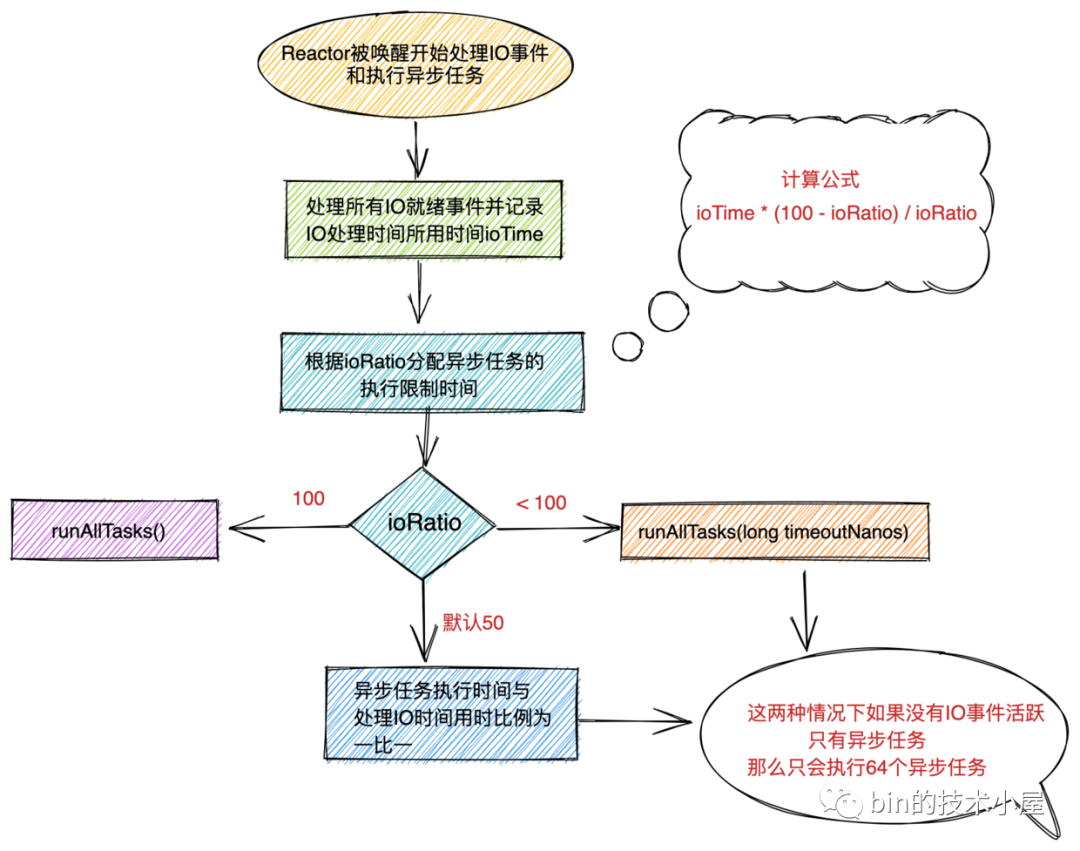
下面我们来分别看下这两个执行异步任务的方法处理逻辑:
4.1 runAllTasks()
protected boolean runAllTasks() {
assert inEventLoop();
boolean fetchedAll;
boolean ranAtLeastOne = false;
do {
//将到达执行时间的定时任务转存到普通任务队列taskQueue中,统一由Reactor线程从taskQueue中取出执行
fetchedAll = fetchFromScheduledTaskQueue();
if (runAllTasksFrom(taskQueue)) {
ranAtLeastOne = true;
}
} while (!fetchedAll); // keep on processing until we fetched all scheduled tasks.
if (ranAtLeastOne) {
lastExecutionTime = ScheduledFutureTask.nanoTime();
}
//执行尾部队列任务
afterRunningAllTasks();
return ranAtLeastOne;
}
Reactor线程执行异步任务的核心逻辑就是:
-
先将到期的
定时任务一股脑的从定时任务队列scheduledTaskQueue中取出并转存到普通任务队列taskQueue中。 -
由
Reactor线程统一从普通任务队列taskQueue中取出任务执行。 -
在
Reactor线程执行完定时任务和普通任务后,开始执行存储于尾部任务队列tailTasks中的尾部任务。
下面我们来分别看下上述几个核心步骤的实现:
4.1.1 fetchFromScheduledTaskQueue
/**
* 从定时任务队列中取出达到deadline执行时间的定时任务
* 将定时任务 转存到 普通任务队列taskQueue中,统一由Reactor线程从taskQueue中取出执行
*
* */
private boolean fetchFromScheduledTaskQueue() {
if (scheduledTaskQueue == null || scheduledTaskQueue.isEmpty()) {
return true;
}
long nanoTime = AbstractScheduledEventExecutor.nanoTime();
for (;;) {
//从定时任务队列中取出到达执行deadline的定时任务 deadline <= nanoTime
Runnable scheduledTask = pollScheduledTask(nanoTime);
if (scheduledTask == null) {
return true;
}
if (!taskQueue.offer(scheduledTask)) {
// taskQueue没有空间容纳 则在将定时任务重新塞进定时任务队列中等待下次执行
scheduledTaskQueue.add((ScheduledFutureTask<?>) scheduledTask);
return false;
}
}
}
- 获取当前要执行
异步任务的时间点nanoTime
final class ScheduledFutureTask<V> extends PromiseTask<V> implements ScheduledFuture<V>, PriorityQueueNode {
private static final long START_TIME = System.nanoTime();
static long nanoTime() {
return System.nanoTime() - START_TIME;
}
}
- 从定时任务队列中找出
deadline <= nanoTime的异步任务。也就是说找出所有到期的定时任务。
protected final Runnable pollScheduledTask(long nanoTime) {
assert inEventLoop();
//从定时队列中取出要执行的定时任务 deadline <= nanoTime
ScheduledFutureTask<?> scheduledTask = peekScheduledTask();
if (scheduledTask == null || scheduledTask.deadlineNanos() - nanoTime > 0) {
return null;
}
//符合取出条件 则取出
scheduledTaskQueue.remove();
scheduledTask.setConsumed();
return scheduledTask;
}
- 将
到期的定时任务插入到普通任务队列taskQueue中,如果taskQueue已经没有空间容纳新的任务,则将定时任务重新塞进定时任务队列中等待下次拉取。
if (!taskQueue.offer(scheduledTask)) {
scheduledTaskQueue.add((ScheduledFutureTask<?>) scheduledTask);
return false;
}
fetchFromScheduledTaskQueue方法的返回值为true时表示到期的定时任务已经全部拉取出来并转存到普通任务队列中。
返回值为false时表示到期的定时任务只拉取出来一部分,因为这时普通任务队列已经满了,当执行完普通任务时,还需要在进行一次拉取。
当到期的定时任务从定时任务队列中拉取完毕或者当普通任务队列已满时,这时就会停止拉取,开始执行普通任务队列中的异步任务。
4.1.2 runAllTasksFrom
protected final boolean runAllTasksFrom(Queue<Runnable> taskQueue) {
Runnable task = pollTaskFrom(taskQueue);
if (task == null) {
return false;
}
for (;;) {
safeExecute(task);
task = pollTaskFrom(taskQueue);
if (task == null) {
return true;
}
}
}
-
首先
runAllTasksFrom 方法的返回值表示是否执行了至少一个异步任务。后面会赋值给ranAtLeastOne变量,这个返回值我们后续会用到。 -
从普通任务队列中拉取
异步任务。
protected static Runnable pollTaskFrom(Queue<Runnable> taskQueue) {
for (;;) {
Runnable task = taskQueue.poll();
if (task != WAKEUP_TASK) {
return task;
}
}
}
Reactor线程执行异步任务。
protected static void safeExecute(Runnable task) {
try {
task.run();
} catch (Throwable t) {
logger.warn("A task raised an exception. Task: {}", task, t);
}
}
4.1.3 afterRunningAllTasks
if (ranAtLeastOne) {
lastExecutionTime = ScheduledFutureTask.nanoTime();
}
//执行尾部队列任务
afterRunningAllTasks();
return ranAtLeastOne;
如果Reactor线程执行了至少一个异步任务,那么设置lastExecutionTime,并将ranAtLeastOne标识返回。这里的ranAtLeastOne标识就是runAllTasksFrom方法的返回值。
最后执行收尾任务,也就是执行尾部任务队列中的尾部任务。
@Override
protected void afterRunningAllTasks() {
runAllTasksFrom(tailTasks);
}
4.2 runAllTasks(long timeoutNanos)
这里在处理异步任务的核心逻辑还是和之前一样的,只不过就是多了对超时时间的控制。
protected boolean runAllTasks(long timeoutNanos) {
fetchFromScheduledTaskQueue();
Runnable task = pollTask();
if (task == null) {
//普通队列中没有任务时 执行队尾队列的任务
afterRunningAllTasks();
return false;
}
//异步任务执行超时deadline
final long deadline = timeoutNanos > 0 ? ScheduledFutureTask.nanoTime() + timeoutNanos : 0;
long runTasks = 0;
long lastExecutionTime;
for (;;) {
safeExecute(task);
runTasks ++;
//每运行64个异步任务 检查一下 是否达到 执行deadline
if ((runTasks & 0x3F) == 0) {
lastExecutionTime = ScheduledFutureTask.nanoTime();
if (lastExecutionTime >= deadline) {
//到达异步任务执行超时deadline,停止执行异步任务
break;
}
}
task = pollTask();
if (task == null) {
lastExecutionTime = ScheduledFutureTask.nanoTime();
break;
}
}
afterRunningAllTasks();
this.lastExecutionTime = lastExecutionTime;
return true;
}
折叠 -
首先还是通过
fetchFromScheduledTaskQueue 方法从Reactor中的定时任务队列中拉取到期的定时任务,转存到普通任务队列中。当普通任务队列已满或者到期定时任务全部拉取完毕时,停止拉取。 -
将
ScheduledFutureTask.nanoTime() + timeoutNanos作为Reactor线程执行异步任务的超时时间点deadline。 -
由于系统调用
System.nanoTime()需要一定的系统开销,所以每执行完64个异步任务的时候才会去检查一下执行时间是否到达了deadline。如果到达了执行截止时间deadline则退出停止执行异步任务。如果没有到达deadline则继续从普通任务队列中取出任务循环执行下去。
从这个细节又可以看出Netty对性能的考量还是相当讲究的
流程走到这里,我们就对Reactor的整个运行框架以及如何轮询IO就绪事件,如何处理IO就绪事件,如何执行异步任务的具体实现逻辑就剖析完了。
下面还有一个小小的尾巴,就是Netty是如何解决文章开头提到的JDK NIO Epoll 的空轮询BUG的,让我们一起来看下吧~~~
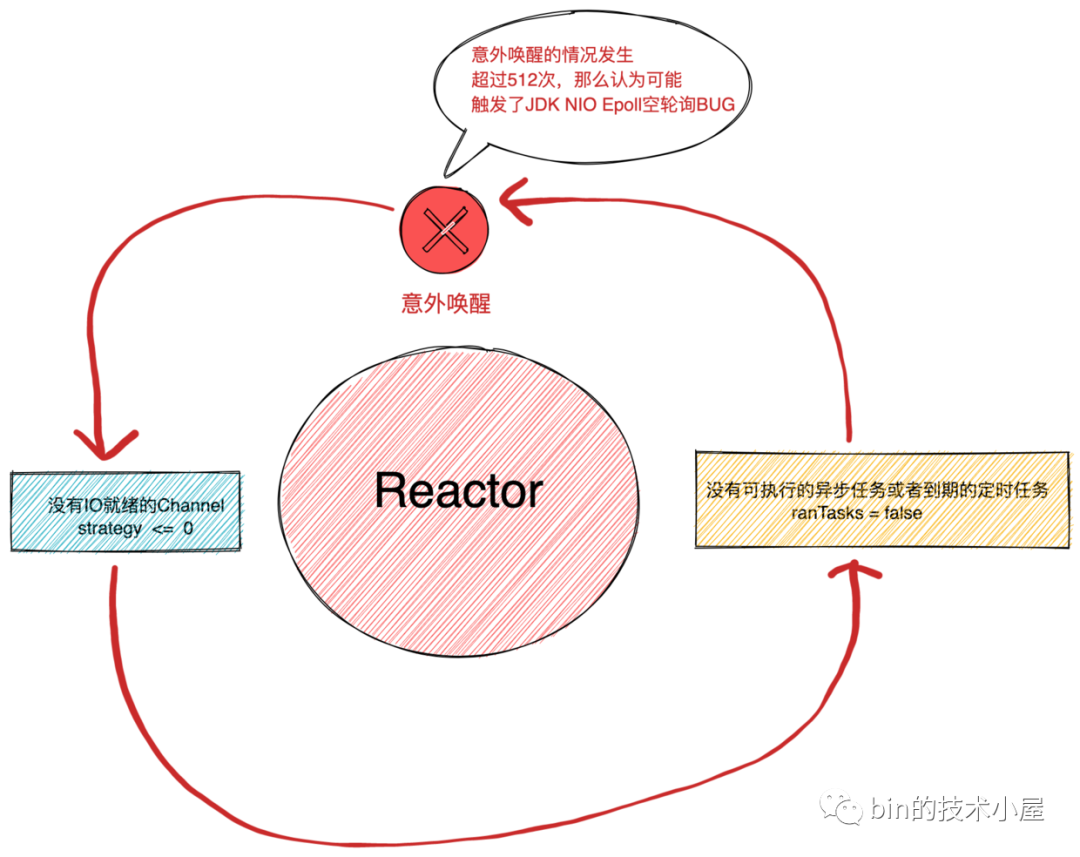
5. 解决JDK Epoll空轮询BUG
前边提到,由于JDK NIO Epoll的空轮询BUG存在,这样会导致Reactor线程在没有任何事情可做的情况下被意外唤醒,导致CPU空转。
其实Netty也没有从根本上解决这个JDK BUG,而是选择巧妙的绕过这个BUG。
下面我们来看下Netty是如何做到的。
if (ranTasks || strategy > 0) {
if (selectCnt > MIN_PREMATURE_SELECTOR_RETURNS && logger.isDebugEnabled()) {
logger.debug("Selector.select() returned prematurely {} times in a row for Selector {}.",
selectCnt - 1, selector);
}
selectCnt = 0;
} else if (unexpectedSelectorWakeup(selectCnt)) { // Unexpected wakeup (unusual case)
//既没有IO就绪事件,也没有异步任务,Reactor线程从Selector上被异常唤醒 触发JDK Epoll空轮训BUG
//重新构建Selector,selectCnt归零
selectCnt = 0;
}
在Reactor线程处理完IO就绪事件和异步任务后,会检查这次Reactor线程被唤醒有没有执行过异步任务和有没有IO就绪的Channel。
-
boolean ranTasks这时候就派上了用场,这个ranTasks正是前边我们在讲runAllTasks方法时提到的返回值。用来表示是否执行过至少一次异步任务。 -
int strategy正是JDK NIO Selector的select方法的返回值,用来表示IO就绪的Channel个数。
如果ranTasks = false 并且 strategy = 0这代表Reactor线程本次既没有异步任务执行也没有IO就绪的Channel需要处理却被意外的唤醒。等于是空转了一圈啥也没干。
这种情况下Netty就会认为可能已经触发了JDK NIO Epoll的空轮询BUG
int SELECTOR_AUTO_REBUILD_THRESHOLD = SystemPropertyUtil.getInt("io.netty.selectorAutoRebuildThreshold", 512);
private boolean unexpectedSelectorWakeup(int selectCnt) {
..................省略...............
/**
* 走到这里的条件是 既没有IO就绪事件,也没有异步任务,Reactor线程从Selector上被异常唤醒
* 这种情况可能是已经触发了JDK Epoll的空轮询BUG,如果这种情况持续512次 则认为可能已经触发BUG,于是重建Selector
*
* */
if (SELECTOR_AUTO_REBUILD_THRESHOLD > 0 &&
selectCnt >= SELECTOR_AUTO_REBUILD_THRESHOLD) {
// The selector returned prematurely many times in a row.
// Rebuild the selector to work around the problem.
logger.warn("Selector.select() returned prematurely {} times in a row; rebuilding Selector {}.",
selectCnt, selector);
rebuildSelector();
return true;
}
return false;
}
- 如果
Reactor这种意外唤醒的次数selectCnt超过了配置的次数SELECTOR_AUTO_REBUILD_THRESHOLD,那么Netty就会认定这种情况可能已经触发了JDK NIO Epoll空轮询BUG,则重建Selector(将之前注册的所有Channel重新注册到新的Selector上并关闭旧的Selector),selectCnt计数归0。
SELECTOR_AUTO_REBUILD_THRESHOLD默认为512,可以通过系统变量-D io.netty.selectorAutoRebuildThreshold指定自定义数值。
- 如果
selectCnt小于SELECTOR_AUTO_REBUILD_THRESHOLD,则返回不做任何处理,selectCnt继续计数。
Netty就这样通过计数Reactor被意外唤醒的次数,如果计数selectCnt达到了512次,则通过重建Selector 巧妙的绕开了JDK NIO Epoll空轮询BUG。
我们在日常开发中也可以借鉴Netty这种处理问题的思路,比如在项目开发中,当我们发现我们无法保证彻底的解决一个问题时,或者为了解决这个问题导致我们的投入产出比不高时,我们就该考虑是不是应该换一种思路去绕过这个问题,从而达到同样的效果。*解决问题的最高境界就是不解决它,巧妙的绕过去~~~~~!!*
总结
本文花了大量的篇幅介绍了Reactor整体的运行框架,并深入介绍了Reactor核心的工作模块的具体实现逻辑。
通过本文的介绍我们知道了Reactor如何轮询注册在其上的所有Channel上感兴趣的IO事件,以及Reactor如何去处理IO就绪的事件,如何执行Netty框架中提交的异步任务和定时任务。
最后介绍了Netty如何巧妙的绕过JDK NIO Epoll空轮询的BUG,达到解决问题的目的。
提炼了新的解决问题的思路:解决问题的最高境界就是不解决它,巧妙的绕过去~~~~~!!
好了,本文的内容就到这里了,我们下篇文章见~~~~~
欢迎关注公众号:bin的技术小屋