-
数据分析案例-基于随机森林算法探索影响人类预期寿命的因素并预测人类预期寿命
目录
1.项目背景
从古到今,人们都希望自己以及家人长寿。长命百岁、寿比南山这些成语也是被大家一直所期望的。随着医疗水平的进步,人的平均寿命在慢慢提升。现在全球平均预期寿命是73.2岁,而在1950年则只有47岁。
平均预期寿命是在一定的年龄别死亡率水平下,活到确切年龄X岁以后,平均还能继续生存的年数,它是衡量一个国家、民族和地区居民健康水平的一个指标。可以反映出一个社会生活质量的高低。社会经济条件、卫生医疗水平限制着人们的寿命。所以不同的社会,不同的时期,人类寿命的长短有着很大的差别;同时,由于体质、遗传因素、生活条件等个人差异,也使每个人的寿命长短相差悬殊。
这个指标与性别、年龄、种族有着紧密的联系,因此常常需要分别计算。平均预期寿命是我们最常用的预期寿命指标,它表明了新出生人口平均预期可存活的年数,是度量人口健康状况的一个重要的指标。
寿命的长短受两方面的制约。一方面,社会经济条件、卫生医疗水平限制着人们的寿命,所以不同的社会,不同的时期,寿命的长短有着很大的差别;另一方面,由于体质、遗传因素、生活条件等个人差异,也使每个人的寿命长短相差悬殊。因此,虽然难以预测具体某个人的寿命有多长,但可以通过科学的方法计算并告知在一定的死亡水平下,预期每个人出生时平均可存活的年数。这就是平均预期寿命。
因此,对于探究影响人类预期寿命的因素以及对预期寿命进行预测有着至关重要的作用。
2.项目简介
2.1项目内容
本项目是世卫组织建立了一段时间内所有国家健康状况的数据集,其中包括预期寿命,成人死亡率等方面的统计数据。使用此数据集,探索各种变量之间的关系,通过数据集建立模型对预期寿命进行预测以及找出对预期寿命的最大影响因素是什么?
本项目主要解决以下问题:
- 最初选择的各种预测因素是否真的影响预期寿命?实际影响预期寿命的预测变量有哪些?
- 预期寿命值低于(<65)的国家是否应该增加其医疗保健支出以改善其平均寿命?
- 婴儿和成人死亡率如何影响预期寿命?
- 是否接受教育对人类寿命有何影响?
- 预期寿命与饮酒是正相关还是负相关?
- 人口稠密的国家的预期寿命是否有降低的趋势?
2.2数据说明
数据集:数据/探索影响预期寿命的因素/Life Expectancy Data.csv
案例来源:https://www.kaggle.com/kumarajarshi/life-expectancy-who
在本项目中,我们考虑了193个国家2000年至2015年的数据进行进一步分析。单个数据文件已合并到一个数据集中。对数据进行初步目视检查时发现有些值缺失。由于数据集来自世界卫生组织,我们没有发现明显的错误。R软件使用Missmap命令处理缺失数据。结果表明,缺失的数据主要集中在人口、乙肝和国内生产总值。缺失的数据来自不太为人所知的国家,如瓦努阿图、汤加、多哥、佛得角等。很难找到这些国家的所有数据,因此决定将这些国家排除在最终模型数据集之外。最终合并的文件(最终数据集)由22列和2938行组成,这意味着20个预测变量。所有的预测变量被分成几个大类:免疫相关因素、死亡率因素、经济因素和社会因素。
所以最终的数据共有2938行,22列

该数据集每个指标名称及其含义说明如表 2‑1所示。
指标名称
指标含义
Hepatitis B
B乙型肝炎
Measles
麻疹
BMI
体重指数
under-five deaths
五岁以下死亡数
Polio
小儿麻痹
Total expenditure
总支出
Diphtheria
白喉病
HIV/AIDS
艾滋病
GDP
国家GDP值
Population
国家人口数
thinness 1-19 years
虚弱1-19年
thinness 5-9 years
虚弱5-9年
Income composition of resources
资源收入构成
Schooling
学校教育
指标名称
指标含义
Country
国家
Year
年份
Status
国家发展:Developing, Developed
Life expectancy
预期寿命
Adult Mortality
成年人死亡数
infant deaths
婴幼儿死亡数
Alcohol
酒精
Percentage expenditure
支出百分比
2.3技术工具
本项目以jupyter notebook为平台,以Python语言为基础,采用pandas进行数据整理和统计分析,用matplotlib、seaborn进行可视化呈现,采用线性回归、随机森林、神经网络三个模型进行预测预期寿命。
3.算法原理
3.1线性回归
一元线性回归是一个主要影响因素作为自变量来解释因变量的变化,在现实问题研究中,因变量的变化往往受几个重要因素的影响,此时就需要用两个或两个以上的影响因素作为自变量来解释因变量的变化,这就是多元回归亦称多重回归。当多个自变量与因变量之间是线性关系时,所进行的回归分析就是多元线性回归。 设y为因变量X1,X2…Xk为自变量,并且自变量与因变量之间为线性关系时,则多元线性回归模型为:
Y=b0+b1x1+…+bkxk+e
其中,b0为常数项,b1,b2…bk为回归系数,b1为X1,X2…Xk固定时,x1每增加一个单位对y的效应,即x1对y的偏回归系数;同理b2为X1,X2…Xk固定时,x2每增加一个单位对y的效应,即,x2对y的偏回归系数,等等。如果两个自变量x1,x2同一个因变量y呈线相关时,可用二元线性回归模型描述为:
y=b0 +b1x1 +b2x2 +e
建立多元线性回归模型时,为了保证回归模型具有优良的解释能力和预测效果,应首先注意自变量的选择,其准则是:
(2)自变量与因变量之间的线性相关必须是真实的,而不是形式上的;
(3)自变量之间应具有一定的互斥性,即自变量之间的相关程度不应高于自变量与因变量之间的相关程度;
(4)自变量应具有完整的统计数据,其预测值容易确定。
3.2神经网络
神经网络(Neural Networks,NN)是由大量的、简单的处理单元(称为神经元)广泛地互相连接而形成的复杂网络系统,它反映了人脑功能的许多基本特征,是一个高度复杂的非线性动力学习系统。神经网络具有大规模并行、分布式存储和处理、自组织、自适应和自学能力,特别适合处理需要同时考虑许多因素和条件的、不精确和模糊的信息处理问题。神经网络的发展与神经科学、数理科学、认知科学、计算机科学、人工智能、信息科学、控制论、机器人学、微电子学、心理学、光计算、分子生物学等有关,是一门新兴的边缘交叉学科。
神经网络的基础在于神经元。
神经元是以生物神经系统的神经细胞为基础的生物模型。在人们对生物神经系统进行研究,以探讨人工智能的机制时,把神经元数学化,从而产生了神经元数学模型。
大量的形式相同的神经元连结在—起就组成了神经网络。神经网络是一个高度非线性动力学系统。虽然,每个神经元的结构和功能都不复杂,但是神经网络的动态行为则是十分复杂的;因此,用神经网络可以表达实际物理世界的各种现象。
神经网络模型是以神经元的数学模型为基础来描述的。人工神经网络(ArtificialNuearlNewtokr)s,是对人类大脑系统的一阶特性的一种描。简单地讲,它是一个数学模型。神经网络模型由网络拓扑.节点特点和学习规则来表示。神经网络对人们的巨大吸引力主要在下列几点:
1.并行分布处理。
2.高度鲁棒性和容错能力。
3.分布存储及学习能力。
4.能充分逼近复杂的非线性关系。
3.3随机森林
随机森林是一种有监督学习算法。就像它的名字一样,它创建了一个森林,并使它拥有某种方式随机性。所构建的“森林”是决策树的集成,大部分时候都是用“bagging”方法训练的。bagging 方法,即 bootstrapaggregating,采用的是随机有放回的选择训练数据然后构造分类器,最后组合学习到的模型来增加整体的效果。简而言之,随机森林建立了多个决策树,并将它们合并在一起以获得更准确和稳定的预测。其一大优势在于它既可用于分类,也可用于回归问题,这两类问题恰好构成了当前的大多数机器学习系统所需要面对的。
随机森林分类器使用所有的决策树分类器以及 bagging 分类器的超参数来控制整体结构。与其先构建 bagging分类器,并将其传递给决策树分类器,我们可以直接使用随机森林分类器类,这样对于决策树而言,更加方便和优化。要注意的是,回归问题同样有一个随机森林回归器与之相对应。
随机森林算法中树的增长会给模型带来额外的随机性。与决策树不同的是,每个节点被分割成最小化误差的最佳指标,在随机森林中我们选择随机选择的指标来构建最佳分割。因此,在随机森林中,仅考虑用于分割节点的随机子集,甚至可以通过在每个指标上使用随机阈值来使树更加随机,而不是如正常的决策树一样搜索最佳阈值。这个过程产生了广泛的多样性,通常可以得到更好的模型。
4.项目实施步骤
从机器学习的分类来讲,这是一个有监督问题中的回归问题。通过训练已有的数据进行未来数据的预测。
4.1理解数据
在jupyter notebook单元格中输入下面程序,导入数据和工具包,并查看数据集的信息、大小,并初步观察头部信息。


查看数据大小

数据共有2938行,22列
查看数据基本信息


查看数值型数据描述

 查看非数值型数据描述
查看非数值型数据描述

4.2数据预处理
在真实世界中,数据通常是不完整的(缺少某些感兴趣的指标值)、不一致的(包含代码或者名称的差异)、极易受到噪声(错误或异常值)的侵扰的。因为数据库太大,而且数据集经常来自多个异种数据源,低质量的数据将导致低质量的挖掘结果。就像一个大厨现在要做美味的蒸鱼,如果不将鱼进行去鳞等处理,一定做不成我们口中美味的鱼。数据预处理就是解决上述所提到的数据问题的可靠方法,因此,在进行数据分析之前我们需要进行数据预处理。
数据预处理一般要遵循以下规则:
1)完整性:单条数据是否存在空值,统计的字段是否完善。
2)全面性:观察某一列的全部数值,通过常识来判断该列是否有问题,比如:数据定义、单位标识、数据本身。
3)合法性:数据的类型、内容、大小的合法性。比如数据中是否存在非ASCII字符,性别存在了未知,年龄超过了150等。
4)唯一性:数据是否存在重复记录,因为数据通常来自不同渠道的汇总,重复的情况是常见的。行数据、列数据都需要是唯一的。
本项目对数据进行数重复值和缺失值处理两种预处理方法,以确保其完整性、全面性与合法性。
4.2.1缺失值处理
首先,通过data.isnull().sum()统计出每个特征的缺失值,运行结果如图 4‑3所示。

我们发现数据缺失值还是挺多的,于是我们调用dropna()函数进行删除缺失值。

4.2.2重复值处理
这里我们直接调用drop_duplicates()进行删除重复值

4.3探索性数据分析
探索性数据分析(Exploratory Data Analysis,EDA)是对数据进行分析并得出规律的一种数据分析方法,是一种利用各种工具和图形技术(如柱状图、直方图等)分析数据的方法。它是一个开放式的过程,在这个过程中,我们可以绘制图表并计算统计数据以便探索我们的数据。
EDA本身很有趣(例如找到两个变量之间的关联),或者他们可以用于通知建模的决策(例如使用哪些功能)。简而言之,EDA的目标是确定我们的数据可以告诉我们什么。与目标相关的变量对模型很有用,因为他们是用于预测目标。简单说就是画图来理解数据,EDA探索性数据分析本质上就是用图画图的方式来理解数据。
4.3.1预期寿命分析
分析每一年人类预期寿命的变化情况

通过图我们发现预期寿命从2001年开始直线下跌,2003年跌到最低,后开始逐年上升,且2009年开始上升速度非常快。通过查阅资料,我们得知在2001年世界多地发生很多自然灾害 以及部分国家的战乱可能导致人类预期寿命下降,2009年以后随着经济、医疗的发展,人类预期寿命开始上升。
4.3.2医疗保健分析

从图中可以看出绝大部分预期寿命值低于(<65)的国家的医疗支出百分比都是很少的,而且我们还可以看出随着支出百分比的增加,预期寿命有增加的趋势,存在正相关关系。故预期寿命值低于(<65)的国家应该增加其医疗保健支出以改善其平均寿命。
4.3.3生活方式分析


从上图我们可以看出预期寿命与酒精相关系数为0.4,较弱的正相关性
预期寿命与虚弱1-19和5-9的相关系数为-0.46,存在负相关关系
预期寿命与收入和教育的相关系数为0.72,0.73,存在着较强的正相关关系
4.3.4教育分析


从图中我们可以看出教育与预期寿命存在着正相关的关系,教育越好的国家预期寿命也就越高;教育与成年死亡数、虚弱1-19和5-9都存在这负相关的关系,说明教育差的国家成年死亡数和虚弱人数也就相对越多
4.3.5死亡率分析


从图中我们可以看出成人死亡率与预期寿命存在较强的负相关关系,说明成人死亡率越高的国家,预期寿命也低,婴儿死亡率与预期寿命存在着较弱的负相关关系,婴儿死亡率对预期寿命影响较小
4.3.6不同国家发展的差异
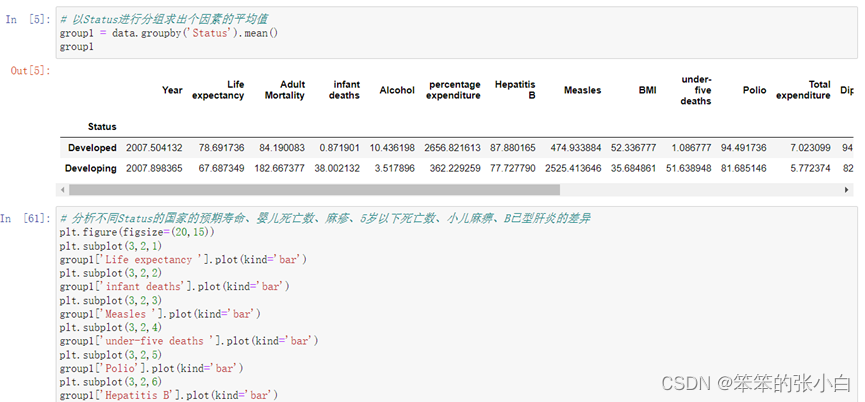

从图中我们可以看出发达国家的预期寿命是高于发展中国家的,婴儿死亡数以及5岁以下死亡数数量发展中国家远超过发达国家,但是小儿麻痹和B已型肝炎的人数是相差不大的
4.4预期寿命预测
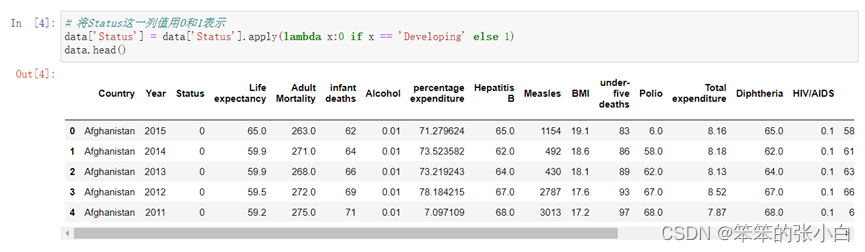
构建建模型之前我们需要将Status这一列的值用0和1代替
接着我们需要划分数据集

最后对数据标准化处理

4.4.1建模及模型预测
1)构建线性回归模型

2)构建神经网络模型

3)构建随机森林模型


通过三个模型的均方误差大小来看,随机森林模型的均方误差最小,故我们选择使用随机森林模型来进行预测。
4.4.2指标重要性排序
经过对上述各个指标与预期寿命关系的分析之后,以及模型的建立与调整,最后按照重要程度对各个指标进行排序。


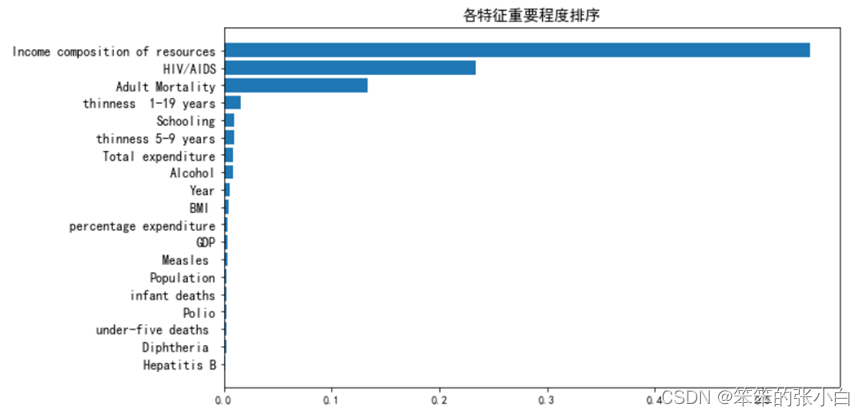
通过结果我们发现,重要程度最大的是资源收入构成,占了一半多,其次是HIV/AIDS艾滋病,最后是成年人死亡数,其他的特征重要程度都很略微,忽略不计。
4.4.3参数优化
在我们确定好了模型之后,我们需要对模型参数进行优化,提高模型的准确率,在这里我们选用网格搜索来进行最优参数的选取。

经过搜索后的最优参数,我们重新对原模型进行训练

我们发现模型的均方误差减小了,说明最优参数改善了模型的准确率。
4.4.4结果预测
最后我们使用模型对预期寿命进行预测

第一列是真实值,第二列是预测值,我们发现绝大部分都预测正确了,误差非常小,模型准确率很高,模型不错。
5.实验总结
5.1结果分析
根据以上分析,得到影响预期寿命最关键的因素:
1)资源收入构成。
2)HIV/AIDS。
3)成年人死亡数。
问题解决:
- 最初选择的各种预测因素是否真的影响预期寿命?实际影响预期寿命的预测变量有哪些?答:否,实际影响预期寿命的变量有资源收入构成、HIV/AIDS和成年人死亡数。
- 预期寿命值低于(<65)的国家是否应该增加其医疗保健支出以改善其平均寿命?答:绝大部分预期寿命值低于(<65)的国家的医疗支出百分比都是很少的,而且我们还可以看出随着支出百分比的增加,预期寿命有增加的趋势,存在正相关关系。故预期寿命值低于(<65)的国家应该增加其医疗保健支出以改善其平均寿命。
- 婴儿和成人死亡率如何影响预期寿命?答:成人死亡率与预期寿命存在较强的负相关关系,说明成人死亡率越高的国家,预期寿命也低;婴儿死亡率与预期寿命存在着较弱的负相关关系,婴儿死亡率对预期寿命影响较小。
- 预期寿命与饮酒是正相关还是负相关?答:预期寿命与酒精相关系数为0.4,较弱的正相关性。
- 是否接受教育对人类寿命有何影响?答:预期寿命与收入和教育的相关系数为0.72,0.73,存在着较强的正相关关系。
- 人口稠密的国家的预期寿命是否有降低的趋势?答:人口数量与预期寿命直接不存在什么关系,从折线图也看不出什么规律,说明人口稠密的国家的预期寿命没有降低的趋势。
5.2改善建议
为了提高预期寿命,给出如下建议:
1)调整改善人的资源收入构成,使得收入结构合理,增强人的满足感。
2)虽然HIV/AIDS的治愈率非常低,仅为0.001%,但是我相信在未来的医疗发展中,肯定改善这种情况,提高治愈率,以消除人对艾滋病的恐慌。
3)控制成年人死亡人数,减少死亡率,这就得需要国家在各种方面来进行防范,比如交通、法律、自然灾害、战争等方面做好改善和防控。
4)国家应该加大对医疗的投入,做好医疗保健,让人们不再为医疗费用而担忧。
5)国家应该增大对教育的投入,保证每一位孩子都能接受平等的教育。
5.3实验心得
通过这次Python项目实战,我学到了许多新的知识,这是一个让我把书本上的理论知识运用于实践中的好机会。原先,学的时候感叹学的资料太难懂,此刻想来,有些其实并不难,关键在于理解。
在这次实战中还锻炼了我其他方面的潜力,提高了我的综合素质。首先,它锻炼了我做项目的潜力,提高了独立思考问题、自我动手操作的潜力,在工作的过程中,复习了以前学习过的知识,并掌握了一些应用知识的技巧等
在此次实战中,我还学会了下面几点工作学习心态:
1)继续学习,不断提升理论涵养。在信息时代,学习是不断地汲取新信息,获得事业进步的动力。作为一名青年学子更就应把学习作为持续工作用心性的重要途径。走上工作岗位后,我会用心响应单位号召,结合工作实际,不断学习理论、业务知识和社会知识,用先进的理论武装头脑,用精良的业务知识提升潜力,以广博的社会知识拓展视野。
2)努力实践,自觉进行主角转化。只有将理论付诸于实践才能实现理论自身的价值,也只有将理论付诸于实践才能使理论得以检验。同样,一个人的价值也是透过实践活动来实现的,也只有透过实践才能锻炼人的品质,彰显人的意志。
3)提高工作用心性和主动性。实习,是开端也是结束。展此刻自我面前的是一片任自我驰骋的沃土,也分明感受到了沉甸甸的职责。在今后的工作和生活中,我将继续学习,深入实践,不断提升自我,努力创造业绩,继续创造更多的价值。
这次Python实战不仅仅使我学到了知识,丰富了经验。也帮忙我缩小了实践和理论的差距。在未来的工作中我会把学到的理论知识和实践经验不断的应用到实际工作中,为实现理想而努力。
-
相关阅读:
LeetCode 2525. 根据规则将箱子分类:优雅解法?
springboot罗亚方舟考研资料库网站设计与实现毕业设计源码302302
STM32-无人机-电机-定时器基础知识与PWM输出原理
由CPU高负载引发内核探索之旅
随便记记第二周
Android Studio 是如何和我们的手机共享剪贴板的
DC150V降压芯片,12V/5A 5V/5Adc-dc高耐压电源IC
酰肼PEG酰肼,HZ-PEG-HZ
[无监督学习] 15.详细图解混合高斯分布
一文带你理解@RefreshScope注解实现动态刷新原理
- 原文地址:https://blog.csdn.net/m0_64336780/article/details/125597722