-
用于持续医疗监测的无袖带血压估计算法【翻译】
用于持续医疗监测的无袖带血压估计算法
摘要
持续的血压监测可以提供有关个人健康状况的宝贵信息。然而,传统的BP测量使用的是不方便的袖带式仪器,这阻碍了对BP的连续监测。本文提出了一种基于脉搏到达时间(PAT)的高效算法,用于连续且无袖带地估计收缩压(SBP)、舒张压(DBP)和平均动脉压(MAP)值。方法:该框架通过对生命信号的处理和提取两类特征来估计BP值,这两类特征分别基于生理参数和基于生命信号的整体表示。最后,采用回归算法进行BP估计。该算法不需要标定,工作可靠,同时提出了一种可选的标定程序,进一步提高了系统的精度。结果:使用医疗器械先进协会(AAMI)和英国高血压学会(BHS)标准,对提议的方法在大约1000个受试者中进行了评估。该方法在DBP和MAP值的估计方面符合AAMI标准。对于BHS协议,DBP的估计结果为A级,MAP的估计结果为B级。结论:我们得出结论,使用PAT结合来自生命信号的信息特征,可以以一种无创的方式准确可靠地估计血压。意义:结果表明,提出的无袖式血压估计算法有可能使移动医疗设备持续监测BP。
简介
根据世界卫生组织(WHO)的报告,高血压患病率在男性和女性中分别为24%和20.5%,[1]。不幸的是,高血压患者大多没有意识到自己的疾病,而它却悄无声息地损害着他们的身体内部器官(如大脑、眼睛、肾脏、内脏),因此被称为“沉默的杀手[2]”。为了准确诊断和治疗高血压,持续测量血压(BP)是必要的。血压是心率(HR)频率的周期性信号,通常在一个有限的范围内。血压在最大值和最小值之间波动,分别称为收缩压(SBP)和舒张压(DBP)。如果在休息状态下,收缩压(SBP)和舒张压(DBP)分别超过140毫米汞柱和90毫米汞柱,就被称为高血压[1]。平均动脉压(Mean Arterial Pressure, MAP)是一个心动周期内BP信号的平均值,是BP信号的另一种描述。血压受许多因素的影响,如饮食、运动、精神状况、压力等,因此,随着时间的推移,它会发生很大的变化。因此,为了帮助医生诊断和有效控制患者的高血压,持续监测血压就显得至关重要。
传统的无创血压测量方法是使用水银血压计[3]。这种方法是护士将可充气的袖口套在病人的手臂上,然后进行充气。充分充气后,他/她慢慢地放气,同时听有节奏的声音。第一次听到这种声音时,血液开始在血管内流动,这表明收缩压。当声音减弱时,袖带的压力等于舒张压。袖口使这种方法不方便,特别是在公共场所可能会感染细菌。此外,由于不便,使用充气袖套可以防止连续监测。
最近,在文献中,为了实现连续监测BP的目标,无袖带BP测量方法受到了极大的关注。实现这一目标的最突出的方法将在续集中描述。
使用脉冲波速(PWV)是最常用的方法。PWV是压力波在容器中的传播速度。该方法基于弹性管道中流体的波传播理论。另一方面,在许多研究中,脉冲传输时间(Pulse Transit Time, PTT),即心跳传递到身体外周的时间间隔,被用于估计PWV。Ahmad et al.[5]和Xuan et al.[6]表明BP和PTT之间存在显著的相关性,但这种相关性依赖于许多参数,而这些参数在个体[7]、[4]之间存在差异。许多其他的工作试图用PTT[8],[9],[10]拟合BP估计的回归模型,但都不满足标准标准。Wong等[11]研究了不同情况下个体BP与PTT之间的相关性。他们在6个月内调查了正常受试者的血压和PTT之间的相关性。Gesche等人[12]提出了一种校准程序来消除这种依赖性。然而,这种校准仅对短时间间隔[13]可靠。虽然基于校准的方法不能可靠地替代传统的BP测量装置,但它们适用于短时间间隔的BP监测,如运动试验[14]。
尽管其优点,基于PWV的方法面临着一些困难,如依赖于个别生理参数,这需要详细的校准程序。这一问题阻碍了基于PWV的BP测量方法获得现有卫生保健标准的批准,因为这些标准不允许校准程序。因此,基于PWV的方法在实际中无法替代传统的BP测量方法。
这项工作提出了一种新的方法,利用各种机器学习和信号处理算法,以实现医疗监测系统中准确和连续的BP估计。综上所述,在对PPG和ECG信号去噪后,提取它们的信息特征,最后将这些特征作为回归模型的输入,由回归模型估计BP值。
本论文的其余部分组织如下:第二节解释了血管系统中血液流动的物理背景。第三节介绍了提出的无袖扣BP估计方法。第四节更详细地解释了算法的基于校准和不需要校准的变化。第五部分对研究结果进行了论证,并与卫生标准和其他工作进行了比较。最后,第七部分对本文进行了总结。
背景
血管系统可以建模为连接的弹性管,其中血液流动。在接下来的两个小节中,我们将简要地讨论动脉壁的理论和性质以及波在动脉中传播的物理。
血管壁
动脉壁由内皮、弹性蛋白、胶原蛋白和平滑肌4层组成。内皮细胞作为血管内血流的管壁,对动脉壁力学性能的影响很小。弹性蛋白具有相当的弹性特性,可对动脉壁产生张力。胶原蛋白比弹性蛋白更硬,一旦动脉壁被拉伸,胶原蛋白就会产生张力。平滑肌通过产生张力来调节动脉弹性。
由于其性质,弹性蛋白负责在低BP值的动脉弹性;而胶原蛋白在高BP值时显著决定动脉弹性。在外周动脉中,平滑肌在管壁力学中起着重要作用,而在中央动脉中,弹性蛋白的作用更显著。衰老或疾病会导致动脉壁力学特性的强烈变化。与外周动脉相比,衰老对中央动脉的影响更大,因为它用胶原蛋白[15]取代了弹性蛋白。
波在动脉中的传播
压力波在血管系统中的传播可以用具有类似于动脉壁力学特性的管道内的压力波的传播来模拟。压力波从近端通过管道传播,经过一段时间后到达远端,称为PTT。中心动脉管壁弹性模量E与管内压力 P P P有关
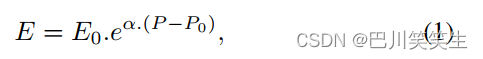
其中 E 0 、 P 0 、 α E_{0}、P_{0}、α E0、P0、α为受试者特定参数[16]。柔度( C C C)定义为用 P P P表示的管截面变化率。通过写出质量守恒方程和动量守恒方程并求解,我们发现C是P的函数,由下式可知

其中 P 0 , P 1 P_{0}, P_{1} P0,P1和 A m A_{m} Am在[7]个体中是不同的。通过写出具有这些特性的弹性管内的波传播方程(求导见[17]),得到下列方程

其中 L = ρ / A L = ρ/A L=ρ/A, ρ ρ ρ是血液密度。由(3)可知,PWV等于 1 / L C ( P ) 1/\sqrt{LC(P)} 1/LC(P)。因此,PTT是压力波通过长度为 l l l的管的时间间隔,定义为
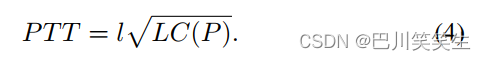
由式(2)和式(L)代入 C ( P ) C(P) C(P),式(4)可重新表示为:

实际上,(5)描述了PTT与P之间的关系,其中 P 0 、 P 1 、 A m 、 A P_{0}、P_{1}、A_{m}、A P0、P1、Am、A是个体特有的参数, l l l与测量PTT的实验设置有关。
文献中普遍采用的方法是进一步简化(5)式,假设C§为常数[18],利用标定程序近似研究对象特定参数。然而,许多研究人员认为这种简化限制了这种方法的准确性,并强制执行一个详细的校准程序[12]。为了解决这个问题,在第三节中,我们提出了一种新的方法,它使用机器学习算法来近似BP-PTT关系
脉冲到达时间(PAT),定义为心脏电激活到脉搏压力到达远端点之间的时间间隔,可用来测量PTT。换句话说,PAT除了包括心脏电激活和机械运动之间的时间间隔外,还包括PTT。虽然,用PAT代替PTT会降低DBP的估计精度[19],但在文献中,由于其测量[7]方便,被广泛用作近端参考。
为了无创测量近端和远端PTT(或PAT)值,可以使用各种生命信号,如光电体积描记仪(PPG)、心电图(ECG),以及其他信号,如心冲击描记图(BCG)、心震图(SCG),[7]。在这项工作中,由于ECG和PPG信号记录的大型数据库的可用性,这是机器学习所需的,我们使用ECG作为近端参考,而PPG作为远端参考(见第III-A节)。然而,利用其他信号,尤其是SCG和BCG信号作为近时参考,可能会潜在地提高所提方法估计DBP的准确性(更多信息请参阅[19])。
方法
图1给出了本文提出的无袖BP估计算法的基本框图,该算法包括以下步骤:i)缓冲心电和PPG信号作为算法的主要输入ii)对心电和PPG信号进行预处理,包括去除伪影和去噪iii)从预处理信号中提取信息特征iv)降低提取特征的维数v)无校准回归,最后vi)可选的校准步骤。这些块将在下面的小节中详细阐述。
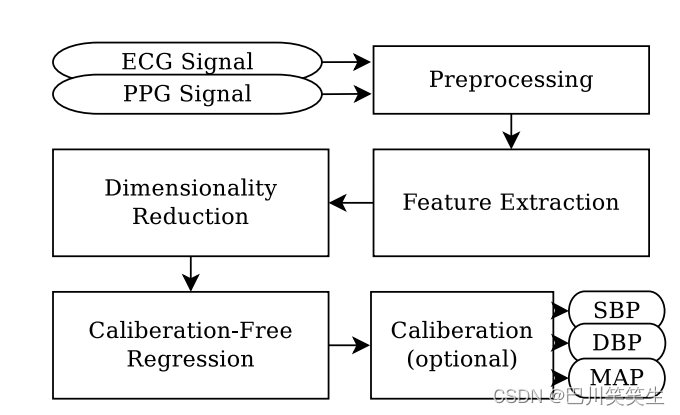
图1所示。提出的无袖带BP估计方法的框图。
数据集
在这项工作中,使用Physionet的重症监护多参数智能监测(MIMIC) II(版本3,2015年9月访问)在线波形数据库[20]作为心电、PPG信号以及动脉血压(ABP)信号的来源。ABP信号用于计算收缩压和舒张压作为目标值。为了从该源收集所需的原始信号,我们开发了一个数据采集器程序,该程序可以方便地下载和转换带有所需信号的记录。此外,数据收集器程序用适当的数据结构存储它们,即层次数据格式(HDF)[21]。利用这个文件结构不仅加快了存储和检索数据的过程,而且在内存和处理大规模数据库方面也非常有效。产生的数据库字段包括前面提到的ECG、PPG和ABP信号以及采样频率(FS)和作为唯一ID的记录名称,这对未来的区块至关重要。
采集到的数据库由5599个记录部分组成,包含所有ECG、PPG和ABP信号。但是,在去除记录时间不足(少于10分钟)或BP值很高或很低(例如SBP ≥ 180; DBP ≥ 130; SBP ≤ 80; DBP ≤ 60 ),最终的数据库由3663个记录部分组成,与大约1000个独特的主题相关。每个部件都有自己唯一的ID,标识其记录和部件号。在训练和测试过程中使用ID字段,防止训练集和测试集中的主题重叠。图2和表1展示了最终数据库中DBP、MAP、SBP和HR值的分布和范围的一些统计信息。

图2所示。数据库参数的直方图:a) SBP, b) MAP, c) DBP, d) HR
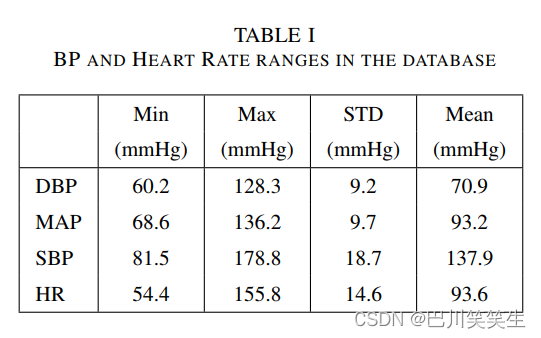
表1 数据库中的血压和心率范围
预处理
为了消除原始信号中噪声和伪影的恶化影响,我们实现了一个预处理块来对信号进行滤波和去噪。在文献中各种预处理方法中,我们分析了有限脉冲响应(FIR)滤波器、无限脉冲响应(IIR)、经验模态分解(EMD)[22]、离散小波分解(DWT)[23]等各种滤波去噪方法的性能。最后,选择小波去噪是因为,与其他方法相比,用小波去噪对重要信号进行预处理具有更好的相位响应、计算复杂度方面的效率更高、对不同信噪比(SNR)甚至非平稳伪影的自适应等优点。
一般来说,有三种主要的干扰源威胁着心电信号的质量:A) 50或60 Hz的电源线噪声几乎是静止的,构成了这些信号中噪声功率的主要百分比。B)信号的基线漂移被认为是呼吸伪迹,在时域上表现为低频分量,它会由于模拟电路的饱和或降低模拟电路的有效精度而降低数字化的精度。C)由肌肉活动引起的高频非平稳噪声。
图3为心电和PPG信号的预处理流程。为了使以下部分对输入信号采样频率的可能变化不受影响,该块首先以1KHz的固定频率对输入信号重新采样,该频率等于高分辨率ECG的采样率。然后,将信号用带有Daubechies 8 (db8)母小波的DWT进行分解,分解到10个分解层(关于最优母小波和分解层选择的详细讨论请参见参考文献[23])。然后,对应于0到0.25 Hz的超低频率范围(与基线漫游相关)和250到500 Hz之间的超高频率(与电源线谐波和肌肉活动伪迹相关)的分量通过归零其分解系数被消除。利用Rigrsure软阈值策略[24]、[25]对剩余分解系数进行常规小波去噪。最后,对分解后的信号进行重构恢复。

图3所示。原始信号预处理流水线
图4显示了该块在采样信号上的性能。从图中可以明显看出,PPG信号的低频基线徘徊和高频电源线对心电信号的干扰明显减少,但信号形态保持不变。
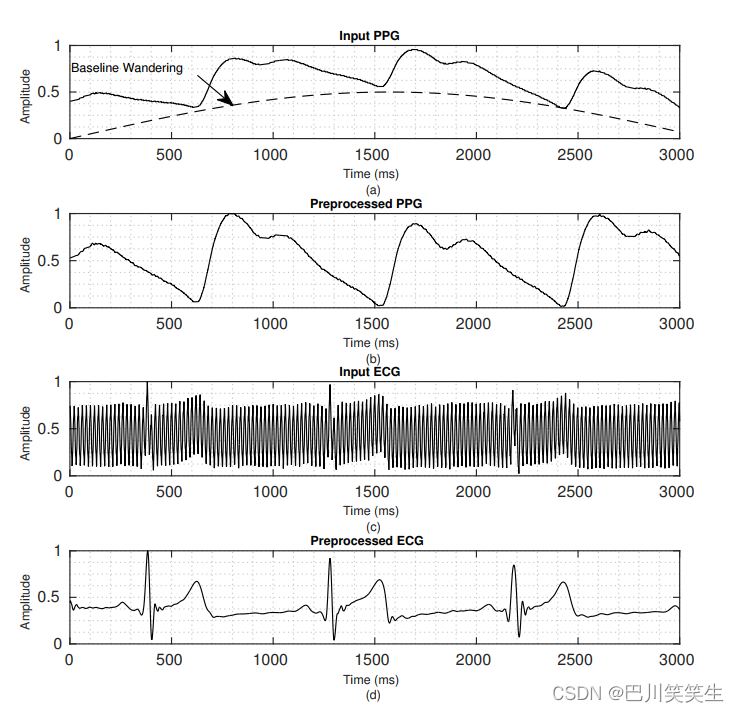
图4所示。在预处理块之前和之后的示例信号。a)原始PPG信号。b)预处理PPG信号。c)原始心电图信号。d)预处理的心电信号。
特征抽取
特征提取块从PPG和ECG信号中提取两种类型的信息特征。第一种是基于生理参数(如心率、增强指数、动脉僵硬指数等)。然而,在第二种类型中,特征向量仅仅是信号形状和时序的表示。由于特征提取是本文提出的无袖带BP估计算法的重要组成部分,将在第四节进行更详细的讨论。
根据来自Physionet组织的官方文件,在MIMIC II数据库中,PPG信号以125Hz的采样率记录,没有对其进行特殊处理。然而,在MIMIC II数据库中,对于心电信号,使用拐点压缩机将心电信号的采样频率从500 Hz降低到125 Hz。因此,与原始信号相比,下采样信号可能最多有大约8 ms的时间抖动[20]。这种现象在很大程度上限制了特征提取器的准确性,从而降低了最终回归模型的性能。为了弥补这一问题,本文提出从每条记录的不同时间窗中提取多个特征向量,然后将其平均,以减少时间抖动效应,该时间抖动效应可建模为高斯噪声。
降维
前一个块中提取的特征是相互关联的,这限制了模型的训练效率,导致需要更多有价值的训练数据。另一方面,将在第IV-A节详细阐述的基于整体的特征是具有相当长的矢量长度的真实信号的一部分。训练回归模型需要大量的训练数据集,而且计算效率很低。减小原始特征向量的长度可以缓解这一问题。为了实现这些优点,本研究利用基本主成分分析(PCA)降维,将约190个与整体特征相关的特征长度减少到15个,同时保留了特征向量98%的能量含量。
回归模型
在创建监督学习任务的数据集时,使用动脉血压(ABP)信号来导出目标SBP和DBP值。实际上,ABP是一个周期信号,它的心率周期和数值等于血管内的瞬时血压。因此,SBP和DBP分别对应连续血压信号(ABP)的最小值和最大值。值得注意的是,虽然ABP信号和本工作中提出的方法都被称为连续BP测量方法,但它们之间连续的含义是不同的。在ABP情况下,连续是指测量频率为毫秒级的瞬时(取决于传感器和采样频率);然而,提出的方法估计BP的估计频率在秒的顺序(取决于受试者的心率),这也可以被认为是连续的。
虽然使用相同的特征向量来估计SBP、DBP和MAP,但这里为每一个目标训练了完全独立的模型。对于回归任务,V-B部分比较了以下四种机器学习算法
正则化线性回归(RLR):对线性回归模型进行训练,通过K-fold交叉验证进行适当的正则化,以评估问题的线性度。众所周知,当特征向量与目标具有较强的非线性关系时,最终训练出的模型并不适用。但是,它们简单,容易训练,不容易出现过拟合,并且,与其他替代方案相比,它们需要更少的训练样本,因此它们更高效,这使得它们的实现更高效。
决策树回归:决策树以树结构的形式构建模型,它由许多决策节点组成,每个节点根据训练好的条件选择一个分支。输入遍历树的决策节点到叶子节点,叶子节点决定最终的预测值。决策树是一种易于理解和解释的模型。然而,在某些问题中,它们可能会创建不能很好地概括的过于复杂的结构,从而表现出较差的性能
支持向量机(SVM):支持向量机是最强大的学习算法之一,它可以创建强大的模型,并具有合理的训练努力和高噪声容忍度。Libsvm库[26]用于使用“RBF内核”机器训练“epsilon-SVR”。通过穷举网格搜索选择超参数,即误分类罚 C C C、核参数 γ \gamma γ和终止准则 ε \varepsilon ε。
自适应Boosting (AdaBoost):与支持向量机相比,自适应Boosting通过将一些弱学习者的输出组合成一个加权和来预测目标值,从而创建一个预测。虽然每个弱学习者都只是一个简单的模型,其预测性能在许多应用中不足,但它们的加权组合的性能可以与使用强学习者的性能相媲美。此外,相对于复杂且强的模型,AdaBoost模型不容易出现过拟合,因此需要的训练样本更少。在这里,由大约1000棵决策树组成的AdaBoost模型使用伟大的Scikit-learn库[27]进行训练。为了训练回归模型,我们使用了带线性损失函数的AdaBoost R2算法[28]。
随机森林回归(RFR):随机森林是一种集成学习方法,其中最终的预测是通过结合一些弱学习者(例如决策树)的预测来创建的。为了具有较低的偏差和合理的低预测方差,每棵树都在训练数据的一个随机子集上训练。在回归问题中,随机森林模型的最终预测是每棵回归树预测的平均值。在这里,对每棵树的最大深度没有限制。通过交叉验证的方法选择最终回归模型中树的数量。这里还使用了Scikit-learn库[27]来进行模型训练。
特征提取与标定方法
正如在第三- c节中简要提到的,从特征提取器得到的特征向量作为回归模型的输入。总的来说,本文提出了两种BP估计方法。在第一种方法中,血压值是基于一个通用的预训练模型估计的,对每个人不进行任何修改(即无校准)。第二种方法是对第一种方法的扩展,在预先训练的无校准模型之上创建校准模型。校准模型的主要功能是对一个固定的通用模型进行改进,通过使用来自几个校准点的信息对每个个体做出更好的预测。下面的小节将讨论每种方法。
无校正集分析法
为了以无袖带的方式估计BP,文献中有各种方法使用PAT以及来自重要信号的其他特征。然而,据我们所知,这是第一种开盒就能工作的设计,与标准指南相比,无需校准就能给出合理的BP估计精度(更多信息请参阅第V节和表IV和V)。
为了实现这一目标,从ECG和PPG信号中提取两组特征。第一个是基于重要信号的生理参数的特征。这些特征的向量大小相对较小,这有助于通过合理的训练计算和使用可行的记录数量来创建模型。这些特征的主要缺点是存在与理想形态和典型形态不同的信号形态样本(见图7),阻碍了从这些样本中准确可靠地提取生理参数。(见图5)
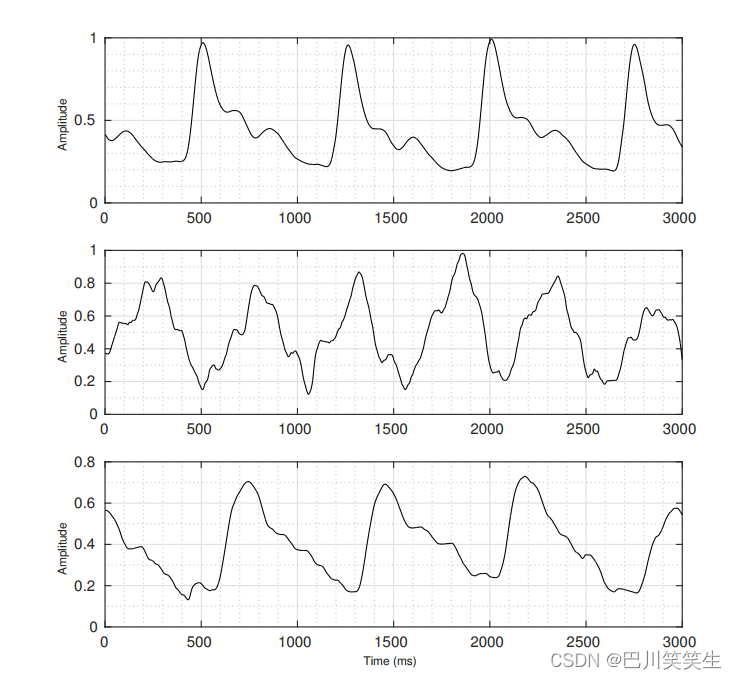
图5所示。真实PPG信号的例子与不适当的形状,以准确提取生理参数。每个子图都演示不同受试者的PPG信号形状。
然而,第二种特征提取方法试图通过提供基于整个信号的表示来自动化参数选择过程。这种方法依靠非线性学习模型来提取信息。与前一种方法相比,该方法对信号形状的变化具有更强的鲁棒性,几乎适用于所有有效信号。这种方法的主要问题是提取的特征向量长度比较大,因此需要更多的训练样本。
生理参数提取:这些特征大部分提取自PPG信号的形状,并借鉴或启发于各种心血管参数。其他的是测量心电图和PPG信号的几个点之间的时移,这实际上与PAT参数的测量有关。这些特性的完整列表如下所示
- PAT特征:PAT值是通过测量心电图r峰与PPG信号上三个点之间的时间间隔得到的,这三个点分别是PPG峰值(PATp)、PPG最小值(PATf)和PPG波形出现最大斜率的点(PATd)。(见图6)

图6所示。计算从心跳脉搏到达手指PPG信号所需时间的PAT。一)心电图信号。b) PPG信号
-
心率:心率是通过测量PPG或ECG信号的峰间间隔来计算的。
-
增强指数(AI):增强是对动脉[29]波反射的衡量,计算方法为收缩期峰值与其后第一个拐点的比值(见图7)。
A I = x y ( 6 ) AI=\frac{x}{y}\quad (6) AI=yx(6)
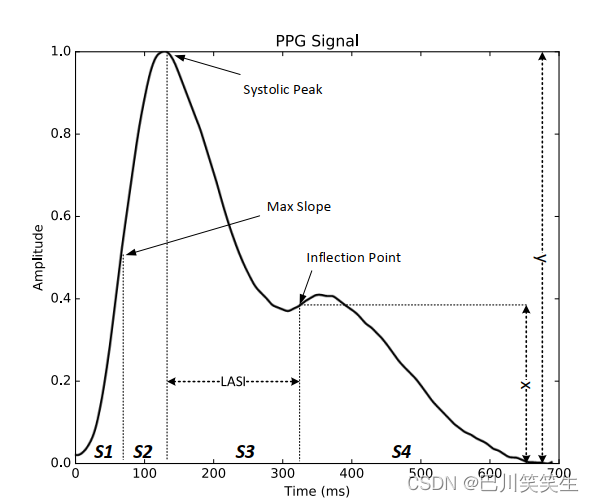
图7所示。PPG信号特征提取
-
大动脉刚度指数(Large Artery Stiffness Index, LASI): LASI是动脉刚度的指标,与收缩期峰值至收缩期峰值后第一个拐点的时间间隔呈负相关。(见图7)
-
拐点面积比(IPA):定义IPA为PPG曲线下各点间面积的比值,在图7中分别用S1、S2、S3、S4表示。通过PPG信号波形中心脏泵浦波与脉搏波反射部分的比值,可以测量动脉系统不同部分之间的阻抗失配情况。因此,IPA可以作为外围总电阻[29]的一个指标。在本文中,直接使用S1、S2、S3和S4区域作为特征。
基于整体的特征提取:这类特征实际上是时域信号在特定区间内的表示。图8显示了提取这些特征的示例。整个基于的特征提取如下

图8所示。基于整体特征的提取。从PPG信号和心电信号中选择适当的峰值,对信号的指定部分进行适当的裁剪和偏移。
- 选择固定大小的ECG和PPG信号间隔作为处理窗口,该间隔足够长,至少包含两个心跳周期。
- 测定心电图和PPG信号的R峰和收缩峰。
- 选取心电图的第一个R峰作为时间参考点,并将PPG信号左移与时间参考点相等。
- 选取PPG的第一个收缩期点作为相应的峰值,然后测量一个PAT候选值。
- 如果所测的PAT值小于预定义的最小可接受的PAT值,则第一收缩期丢弃PPG峰,下一个作为该窗口的第一个PPG峰
- 选择和裁剪PPG第一个和第二个收缩峰之间的PPG信号部分;其他部分为零。
- 将合成的PPG信号部分向左偏移预定义的最小PAT值,并对其重新采样。
应该提醒的是,在训练和测试阶段,每一种“基于参数”和“基于整体”的特征提取方法都可以用来为回归模型创建所需的特征向量(参见第V-A节进行比较)。
标定方法
第IV-A节中提出的方法是完全无需校准的。但是,为了进一步提高无袖带BP估计的精度,提出了标定方法作为系统的可选和补充部分。为了实现这一目标,可以在之前的无校准模型的基础上使用单独的校准模型,这些模型是使用第IV-A节介绍的方法创建的(见图1)。
在创建和评估基于校准的模型时,还采取了以下额外步骤
- 创建一个包含提取的特征、目标值(SBP或DBP)和部件id的数据集。
- 这个数据集被划分为两个更小的数据集。
- 第一个数据集用于无校准模型的训练和评估
- 第二个数据集分为多个组,每个组由特定记录的不同部分组成。
- 在每一组中,使用一种省略的方式,其中一个部分作为校准点,其他部分用于评估最终基于校准的模型。
结果
每个模型的测试是通过10倍的数据集样本分离训练集和测试集来执行的。特别注意的是确保列车和测试数据之间没有重叠。在基于校准的模型的训练和评估中,使用ID字段对每个记录的不同部分进行识别,并分别对每个记录的不同部分进行校准过程和评估。在此基础上,报告了以下结果。
基于参数的方法与基于整体的方法
表2给出了基于参数的方法和基于整体的方法的比较。用灰色背景色表示各特征集和目标集的最佳结果。从表II可以明显看出,在所有情况下,基于参数的特征提取方法的性能都略好于基于整体的方法。然而,这种相当小的优势伴随着基于参数的方法无法高精度地描绘重要的信号点,这可能是由于个体之间信号形状的差异,或者是由于数据记录阶段可能出现的机械或电气故障。(这些信号的示例见图5。)
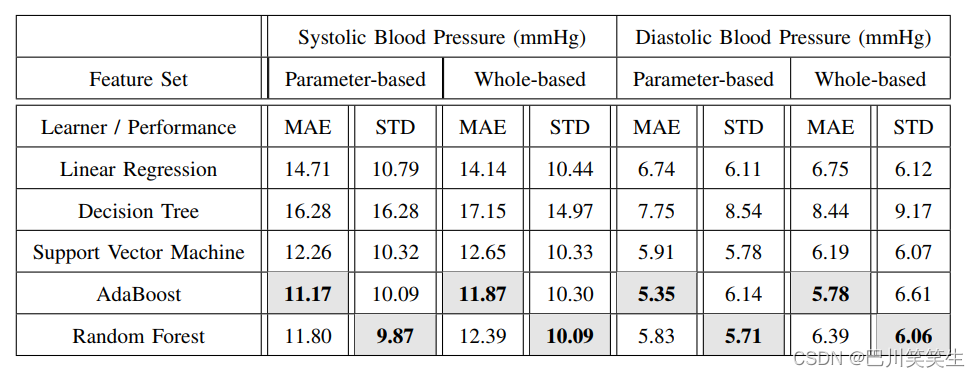
表二 比较两种特征集和各种学习算法的性能。
机器学习算法选择
除了两种特征提取方法的比较外,表II还展示了各种学习方法的性能比较。本次比较包括简单回归模型(线性回归和决策树)、强非线性模型(RBF核支持向量机)以及boosting和ensemble方法。
从表II中可以看出,线性回归算法的BP估计性能远低于使用核机器或集成学习方法等强非线性学习算法的估计性能。因此,从表2的分析可以推断,这个问题存在相当大的非线性和固有的复杂性,需要使用强大的回归算法。特别是在基于整体的方法中,线性回归和决策树几乎不能产生可接受的准确性。另一方面,SVM、AdaBoost和随机森林等其他模型更有前景。考虑到平均绝对误差(MAE)准则,AdaBoost方法优于其他方法。使用Gini重要性[30]检验模型权重,Gini重要性[30]衡量每个特征在树分裂准则总约简方面的重要性。结果表明,与其他特征相比,PATd特征在BP预测中的作用更为显著。
图9和图10是使用AdaBoost模型和基于参数的特征时估计误差的直方图。从估计误差直方图可以看出,误差值在零附近正态分布。与DBP值相比,SBP值的估计误差较大的潜在原因是SBP目标值大约是DBP目标值方差的两倍(同样,见表I)。
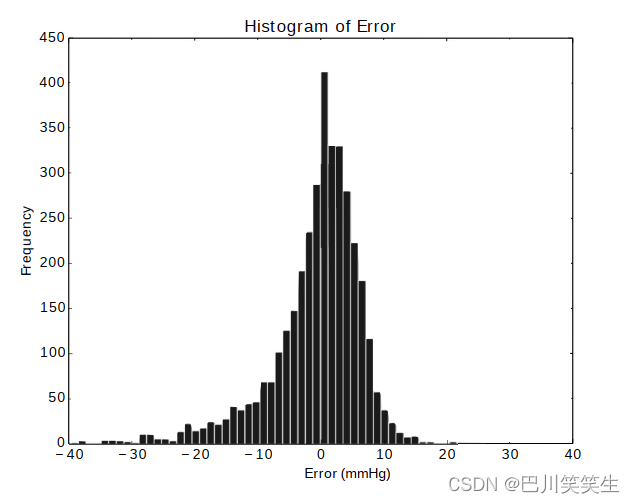
图9所示。AdaBoost回归的DBP误差直方图。
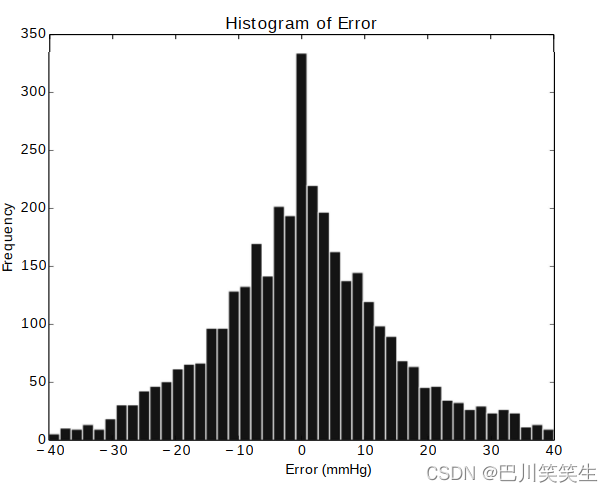
图10所示。AdaBoost回归的SBP误差直方图
图11和图12给出了SBP和DBP目标的Bland-Altman和Regression图。从这些图中可以推断,虽然很大比例的估计值在10毫米汞柱误差线以内;然而,BP值很低或很高的样本估计的准确性不如其他样本。这一问题背后的主要原因是训练数据集中血压非常高或非常低的受试者数量较少,这限制了回归模型在预测不频繁的血压值方面的性能。

图11所示。a) SBP和b) DBP目标的Bland-Altman图使用AdaBoost回归

图12所示。a) SBP和b) DBP目标使用AdaBoost回归的回归图。
无校准与单点校准方法
无校准方法和基于校准方法的比较见表3。在这个比较中,基于参数的特征和AdaBoost回归被用来评价所提出的方法。在这个表中,将每种方法的STD、MAE和输出目标相关®值与其他方法进行比较。从表III可以明显看出,拟议的基于校准的方法在很大程度上优于无校准方法。虽然使用校准可以显著提高BP估计的准确性,但由于目前的卫生保健标准没有建议任何既定的方法,因为它们没有为BP测量设备的校准程序提供任何指导,与这些标准和我们基于校准的结果进行公平的比较是不可能的,[31]。另外值得一提的是,基于校准的方法中受试者数量较少的原因是,这里使用了不包含在无校准模型训练中的独立受试者。此外,我们只选择了信号部分之间BP有较大差异的受试者。
在接下来的几个小节中,我们将重点介绍无需校准的方法来展示我们的结果;然而,应该考虑到这些精度可以通过使用第四- b节中介绍的校准方法大大提高。
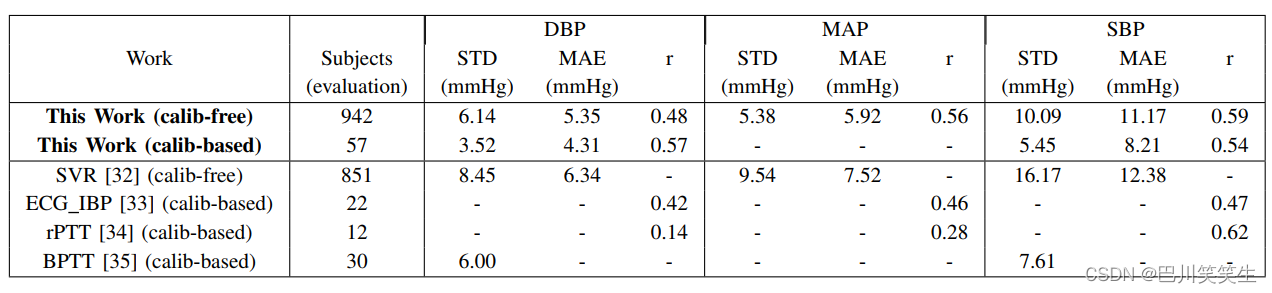
表3与其他工作比较
与其他工作比较
表III还展示了所提出的方法与文献中使用PAT测量值进行BP估计的其他工作之间的比较。为了进行公平的比较,无需校准的方法应该只与它们自己进行比较。考虑到这一点,从表III可以看出,我们的无校准方法与其他方法相比,给出了合理的结果(特别是在STD和r标准中)。还需要注意的是,与其他作品相比,本作品评价的被试人数要多得多,这意味着我们的结果具有更高的统计可靠性。
使用BHS标准进行评估
表4给出了使用英国高血压协会(BHS)标准的基于参数的特征和AdaBoost学习对所提出的方法的评估。BHS根据BP测量装置在三个不同阈值(即5、10和15 mmHg[36])下的累积误差百分比对其进行分级。根据BHS标准,所提出的方法在DBP的估计上符合A级,在MAP值的估计上符合B级。

使用AAMI标准进行评估
表V展示了使用基于参数的特征和随机森林回归与医疗器械进步(AAMI)准则[37]的结果的比较。AAMI要求BP测量设备的ME和STD值分别低于5毫米汞柱和8毫米汞柱。由表V可知,本文方法的ME值远低于可接受的最大ME值。关于STD标准,DBP和MAP的STD值在8 mmHg标准范围内。但是,SBP估计的STD值略超出了AAMI可接受限度。
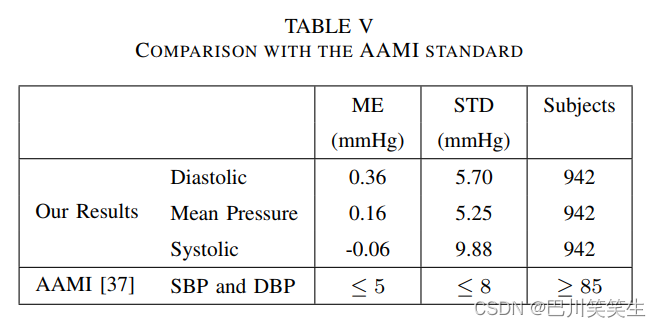
表5与aami标准的比较
值得注意的是,AAMI要求设备在至少85名受试者的统计人群中进行评估;然而,由于在MIMIC数据集中有大量的可用记录(参见第III-A节),我们已经在942个受试者中验证了所提出的方法,这保证了比AAMI要求更高的统计可靠性。在这里,使用随机森林回归而不是AdaBoost的原因是,从表III可以明显看出,随机森林学习方法的结果具有较低的STD值,这是AAMI标准的一个重要标准。
BP分类性能
在许多医疗监测应用中,对BP值的解释优于报告数值BP值。表VI给出了本文算法使用基于参数的特征和AdaBoost学习方法对BP值进行分类的精度。为了衡量算法对BP值的分类性能,为每个SBP和DBP目标定义了三个不同的BP范围,并通过得到每个BP类范围内正确检测的百分比来衡量分类精度。从表VI中可以明显看出,本文方法具有对SBP和DBP值进行准确分类的能力。

表六该算法在bp分类中的准确性
讨论
需要注意的是,本文和许多其他著作使用的MIMIC数据库包含了来自重症监护病房(ICU)的临床数据,这意味着几乎所有的样本都受到药物的影响,这些药物可能会导致血压异常变化。另外,由于使用的是ICU患者的病历资料,本研究中受试者的平均年龄高于总人口的平均年龄。与标准要求(参见V-E和V-F节)相比,这些条件对BP估计系统造成了更大的压力。
作为另一个重要的点,在这项工作中,ECG和PPG信号被用作输入生命信号,因为它们在Physionet MIMIC数据集[20]中可用;然而,使用其他信号(如BCG、SCG等),特别是作为近距离时间参考,可能会产生更准确的BP估计[19]。除了重要信号之外,还有许多特征,包括年龄、体重和身高,这些特征可以添加到重要信号的特征中,从而产生更理想的准确性。
结论及未来工作
在本文中,我们解决了医疗监护系统中持续和无创的BP估计问题。该方法主要包括信号去噪、特征提取和回归阶段。实验结果表明,所提出的BP估计算法在不需要标定程序的情况下可以正常工作。采用BHS和AAMI标准对算法的估计精度进行了评估。根据BHS,我们提出的无标定方法在DBP的估计上为A级,在平均血压的估计上为B级。根据AAMI的说法,DBP和MAP的结果得到了相当大的批准。为了进一步提高估计精度,本文还提出了一种校正方法。
外,还有许多特征,包括年龄、体重和身高,这些特征可以添加到重要信号的特征中,从而产生更理想的准确性。
结论及未来工作
在本文中,我们解决了医疗监护系统中持续和无创的BP估计问题。该方法主要包括信号去噪、特征提取和回归阶段。实验结果表明,所提出的BP估计算法在不需要标定程序的情况下可以正常工作。采用BHS和AAMI标准对算法的估计精度进行了评估。根据BHS,我们提出的无标定方法在DBP的估计上为A级,在平均血压的估计上为B级。根据AAMI的说法,DBP和MAP的结果得到了相当大的批准。为了进一步提高估计精度,本文还提出了一种校正方法。
-
相关阅读:
归并排序(递归法)
网络安全系列-四十二: Suricata之rulesets的激活、更新及动态加载
设计师必备,6个PNG素材网站
边缘计算机的概念和应用,边缘计算发展前景
Arthas 使用以及火焰图
python使用mitmproxy和mitmdump抓包在电脑上抓包(二)
VM安装RedHat7虚机ens33网络不显示IP问题解决
day10.8ubentu流水灯
记一次SQL优化
基于java+SpringBoot+HTML+Mysql音乐网站
- 原文地址:https://blog.csdn.net/qq_16024557/article/details/125600269