-
[python] 使用 Selenium 和 chromedirver 抓取网页
1 没有使用 JavaScript 的网页抓取方法
例如如下的网页:
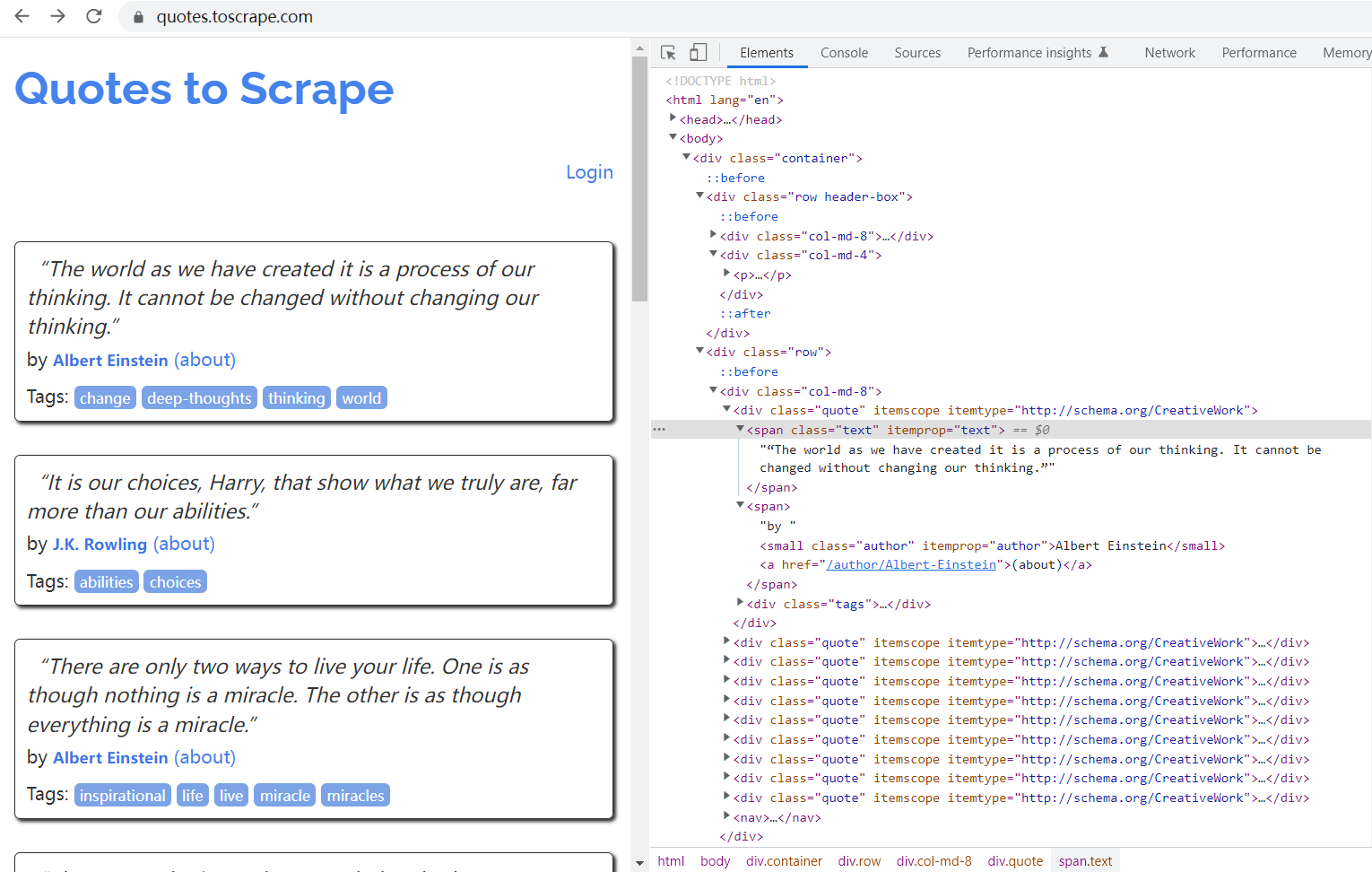
1.1 安装 BeautifulSoup 库
1.2 代码例子
app.py:
import requests from pages.quotes_page import QuotesPage page_content = requests.get("https://quotes.toscrape.com/").content page = QuotesPage(page_content) for quote in page.quotes: print(quote)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
BeautifulSoup 的使用:
from bs4 import BeautifulSoup from locators.quotes_page_locators import QuotesPageLocators from parsers.quote import QuoteParser class QuotesPage: def __init__(self, page): self.soup = BeautifulSoup(page, 'html.parser') @property def quotes(self): locator = QuotesPageLocators.QUOTE quote_tags = self.soup.select(locator) return [QuoteParser(e) for e in quote_tags]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
quote.py, 即 parser,解析含有单个quote的HTML:
from locators.quote_locators import QuoteLocators class QuoteParser: """ Given one of the specific quote divs, find out the data about the quote (quote content, author, tags). """ def __init__(self, parent): self.parent = parent def __repr__(self): return f'<Quote {self.content} by {self.author}>' @property def content(self): locator = QuoteLocators.CONTENT return self.parent.select_one(locator).string @property def author(self): locator = QuoteLocators.AUTHOR return self.parent.select_one(locator).string @property def tags(self): locator = QuoteLocators.TAGS # select all available individual tags return [e.string for e in self.parent.select(locator)]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
2 抓取使用了 JavaScript 的网页
这些网页需要执行 JavaScript 才能生成需要的内容,如下的网页:
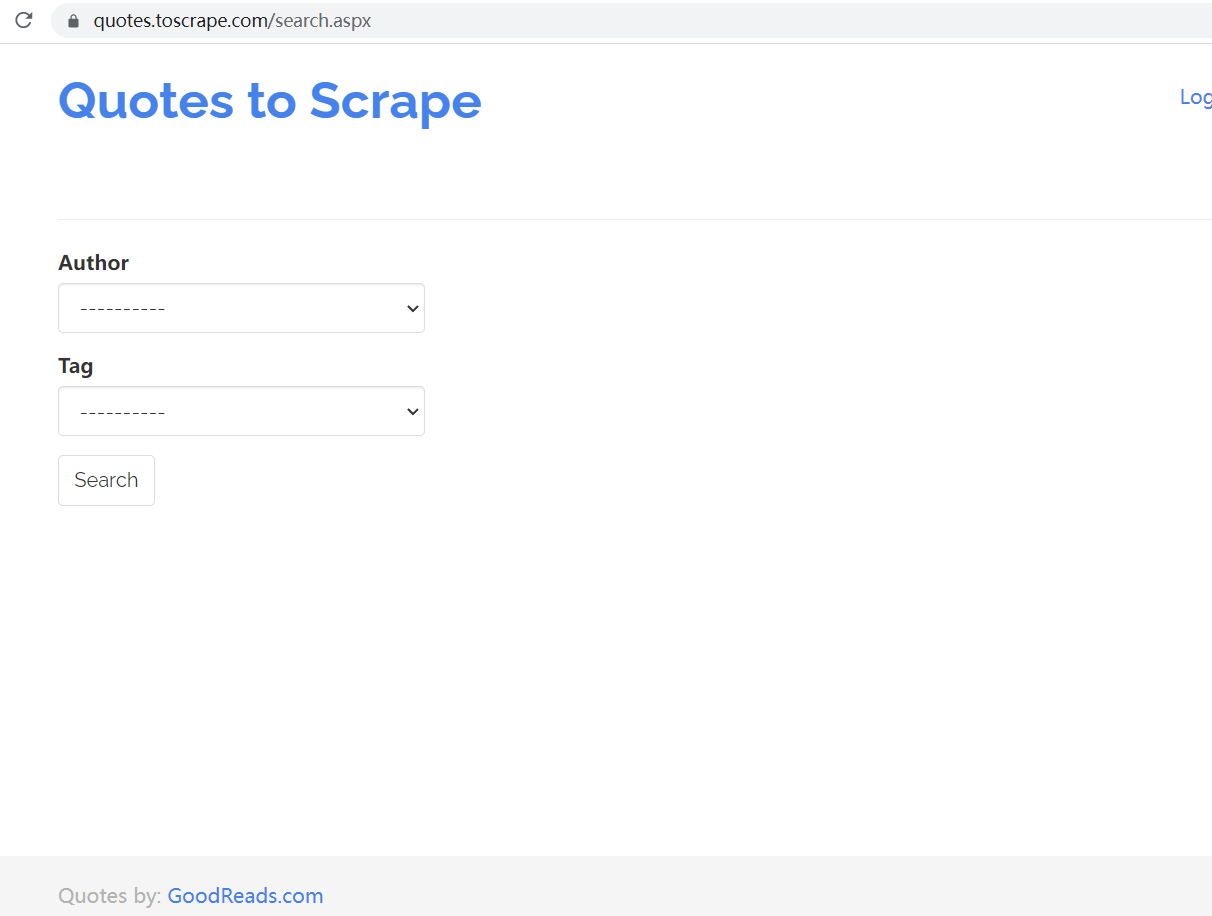
需要执行 3 步操作才能获得 quote,首先需要选择 author,然后选择 tag,最后点击 search 按钮,才会显示相应的 quote: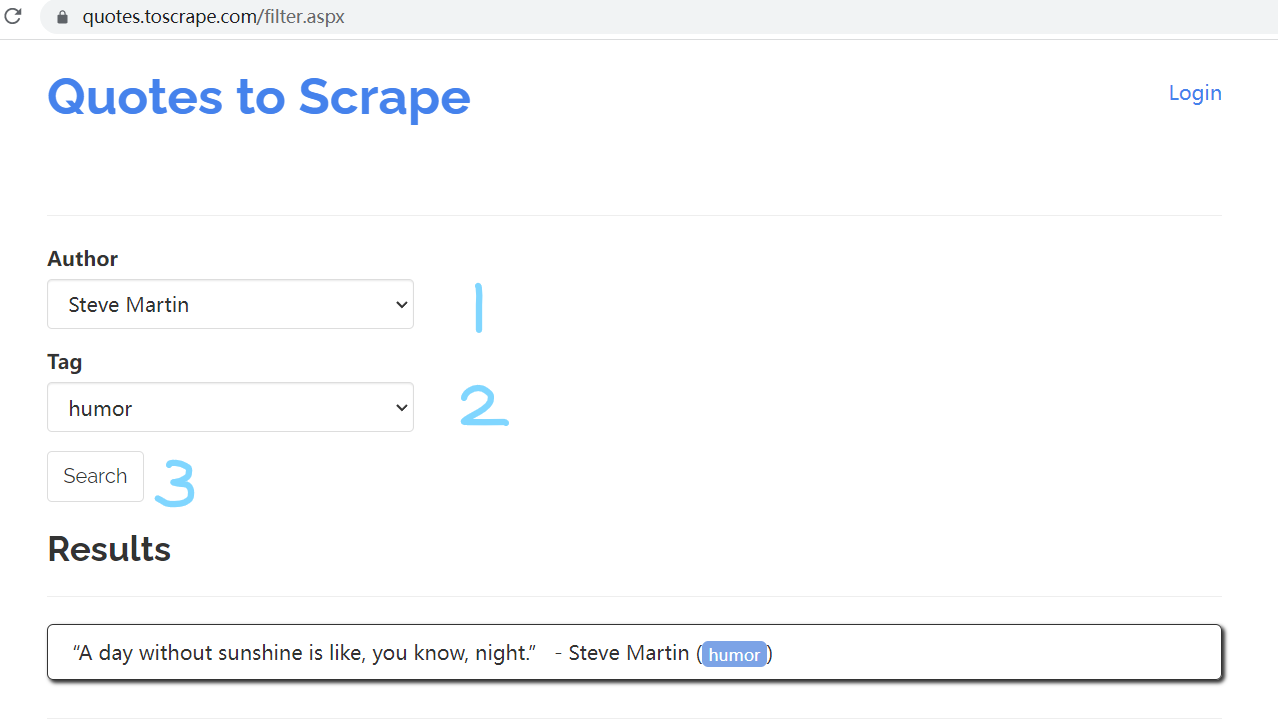
使用 Selenium 和 chromedriver 可以使用代码执行这些原本需要手动才能完成的操作,然后再抓取相应的网页数据,实现浏览器自动化。2.1 下载 chromedriver
https://chromedriver.chromium.org/downloads
下载前,需要chekc自己使用的chrome的版本,例如 chrome 103, chrome 104 都对应不同的 chromedriver,要选择正确的版本。2.2 chromedriver 压缩包解压
然后将 chromedriver.exe 放置在某个位置,将来要使用其所在路径。
2.3 安装 Selenium
当前的最新版本是 4.3.0,安装的是这个版本,不同的版本,API 也会变化。
2.4 代码例子 app.py:
from selenium import webdriver from selenium.webdriver.chrome.service import Service from pages.quotes_page import QuotesPage chrome = webdriver.Chrome(service=Service("chromedriver.exe")) chrome.get("https://quotes.toscrape.com/search.aspx") page = QuotesPage(chrome) author = input("Enter the author you'd like quotes from: ") page.select_author(author) tags = page.get_available_tags() print("Select one of these tags: [{}]".format(' | '.join(tags))) selected_tag = input("Enter your tag: ") page.select_tag(selected_tag) page.search_button.click() print(page.quotes)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
测试界面:
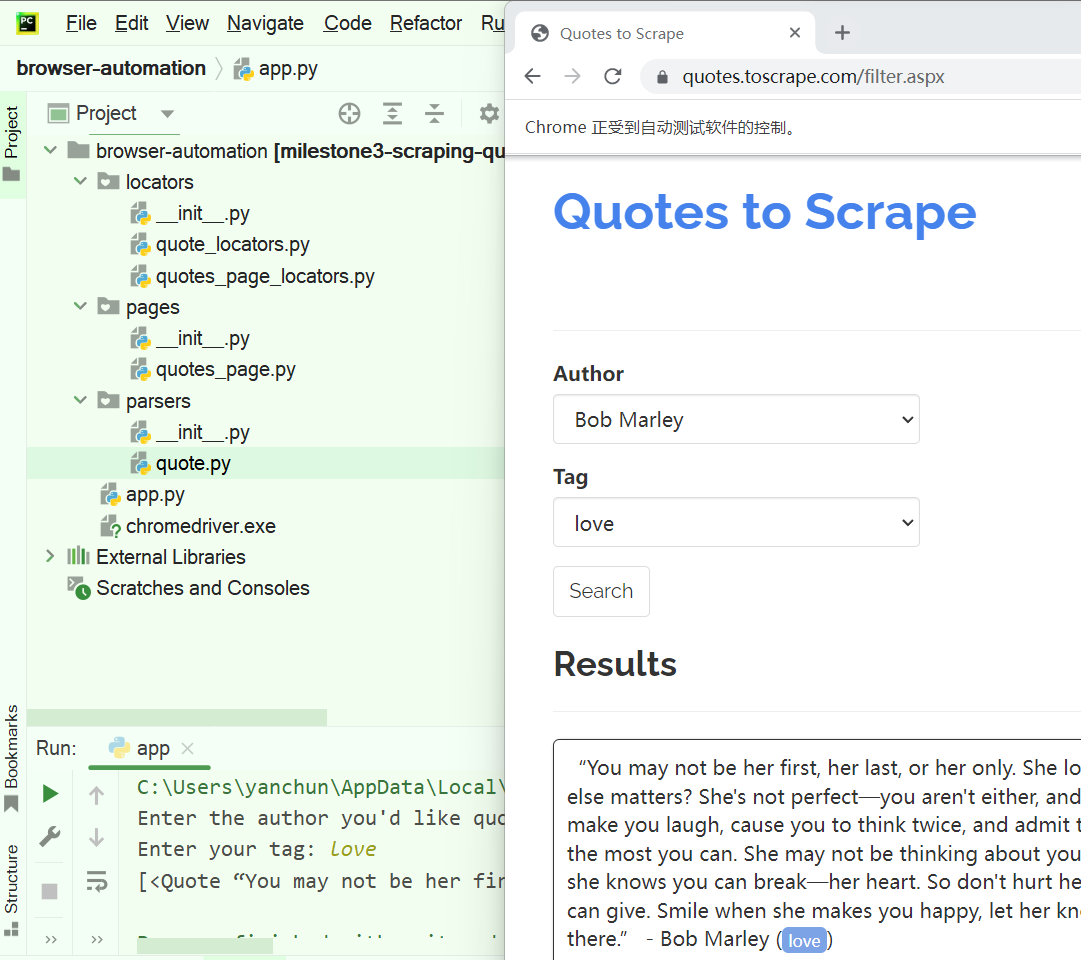
无论使用 BeautifulSoup 还是 使用 Selenium 抓取网页,都是要分析 HTML 文件,再使用 CSS selector 定位 HTML 代码中需要的数据,再调用 library 中的函数读取数据。
-
相关阅读:
温故而知新十(C++)
Q701二叉搜索树的插入操作-递归法-刷leetcode日记
BI行业分析思维框架 - 环保行业分析(三)三层经营分析框架
详解 Spark 核心编程之 RDD 持久化
灯具行业MES解决方案,实现产品的正反向追溯
DAY 69 rsync远程同步
SpringBoot测试用例设置随机数据
相机标定计算内参数:每次拍照,相机和标定板都可以变换位置吗?
Mysql 分布式序列算法
【Linux基本指令(2)】几十条指令快速入手Linux/深入理解什么是指令
- 原文地址:https://blog.csdn.net/ftell/article/details/125564322
