-
RDD的创建方式
原创申明: 未经许可,禁止以任何形式转载,若要引用,请标注链接地址
全文共计4654字,阅读大概需要3分钟
欢迎关注我的个人公众号:不懂开发的程序猿1. 实验室名称:
大数据实验教学系统
2. 实验项目名称:
RDD的创建方式
3. 实验学时:
4. 实验原理:
在调用任何transformation或action操作之前,必须先要有一个RDD。Spark提供了创建RDDs的三种方法。一种方法是将现有的集合并行化。另一种方法是加载外部存储系统中的数据集,比如文件系统。第三种方法是在现有RDD上进行转换来得到新的RDD。
使用程序中的集合创建RDD,主要用于进行测试,可以在实际部署到集群运行之前,自己使用集合构造测试数据,来测试后面的spark应用的流程。
使用HDFS文件创建RDD,应该是最常用的生产环境处理方式,主要可以针对HDFS上存储的大数据,进行离线批处理操作。5. 实验目的:
掌握Spark基于内存创建RDD的方法。
掌握Spark基于外部存储创建RDD的方法。6. 实验内容:
1、读取内存数据,构造RDD。
2、读取外部存储数据,构造RDD。7. 实验器材(设备、虚拟机名称):
硬件:x86_64 ubuntu 16.04服务器
软件:JDK 1.8,Spark-2.3.2,Hadoop-2.7.3,zeppelin-0.8.1,Scala-2.11.118. 实验步骤:
8.1 启动Spark集群
在终端窗口下,输入以下命令,启动Spark集群:
1. $ cd /opt/spark 2. $ ./sbin/start-all.sh- 1
- 2
然后使用
jps命令查看进程,确保Spark的Master进程和Worker进程已经启动。8.2 启动zeppelin服务器
在终端窗口下,输入以下命令,启动zeppelin服务器:
1. $ zeppelin-daemon.sh start- 1
然后使用
jps命令查看进程,确保zeppelin服务器已经启动。8.3 创建notebook文档
1、首先启动浏览器,在地址栏中输入以下url地址,连接zeppelin服务器。
http://localhost:9090
2、如果zeppelin服务器已正确建立连接,则会看到如下的zeppelin notebook首页。
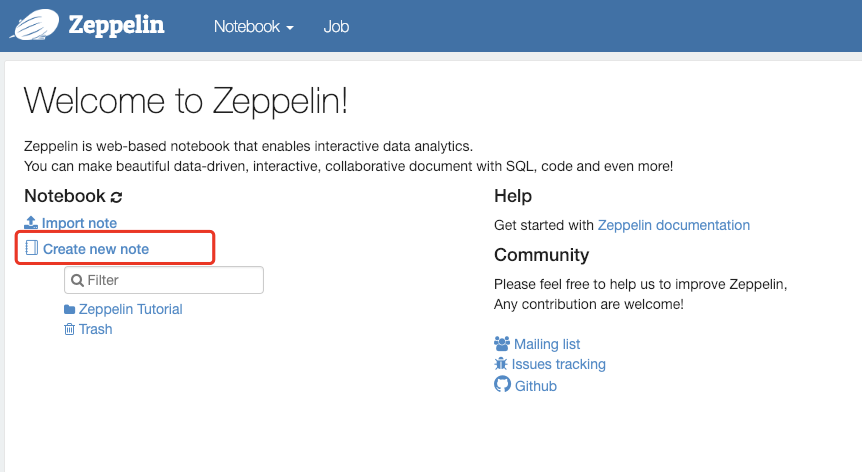
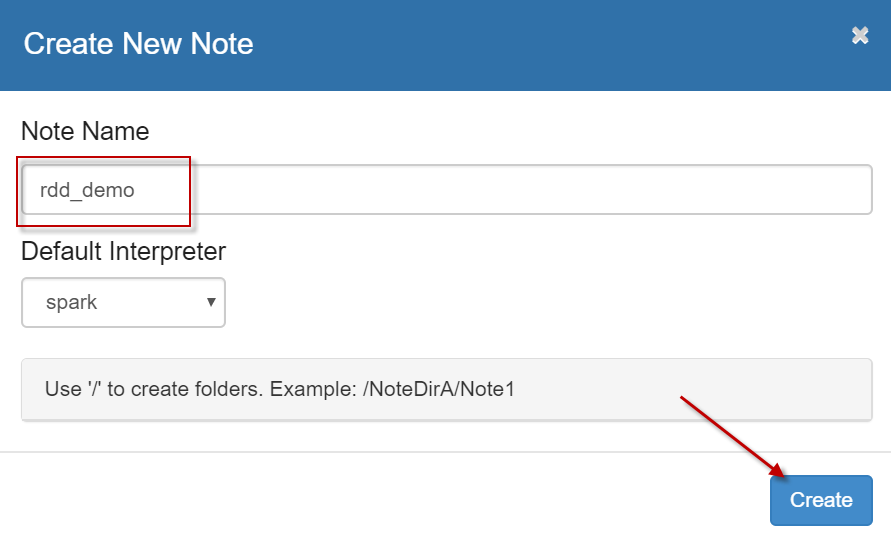
3、点击【
Create new note】链接,创建一个新的笔记本,并命名为”rdd_demo”,解释器默认使用”spark”,如下图所示。
8.4 从内存集合构造RDD
创建RDD的第一种方法是将对象集合并行化,这意味着将其转换为可以并行操作的分布式数据集。对象集合的并行化方法是调用SparkContext类的parallelize方法。
在上一步打开的”rdd_demo” notebook的代码单元中,执行以下代码。
1、从列表中并行化构造RDD。1. // 定义一个集合 2. val list1 = List(1,2,3,4,5,6,7,8,9,10) 3. 4. // 构造RDD 5. val rdd1 = sc.parallelize(list1) 6. 7. // 将集合返回到Driver端 8. rdd1.collect- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
将光标放在代码单元中任意位置,然后同时按下【shift+enter】键,执行以上代码。输出结果如下所示。
list1: List[Int] = List(1, 2, 3, 4, 5, 6, 7, 8, 9, 10) rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:27 res5: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)- 1
- 2
- 3
从上面的输出可以看出,zeppelin会显示每一行代码的执行结果。
2、也可以像下面这样快速创建list,然后由list创建RDD。1. val list2 = List.range(1,11) 2. val rdd2 = sc.parallelize(list2) 3. rdd2.collect- 1
- 2
- 3
将光标放在代码单元中任意位置,然后同时按下【shift+enter】键,执行以上代码。输出结果如下所示:
list2: List[Int] = List(1, 2, 3, 4, 5, 6, 7, 8, 9, 10) rdd2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[1] at parallelize at <console>:27 res9: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)- 1
- 2
- 3
3、也可以像下面这样使用数组创建RDD。
1. val strList = Array("明月几时有","把酒问青天","不知天上宫阙","今夕是何年") 2. val strRDD = sc.parallelize(strList) 3. strRDD.collect- 1
- 2
- 3
将光标放在代码单元中任意位置,然后同时按下【shift+enter】键,执行以上代码。输出结果如下所示。
strList: Array[String] = Array(明月几时有, 把酒问青天, 不知天上宫阙, 今夕是何年) strRdd: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[3] at parallelize at <console>:27 res14: Array[String] = Array(明月几时有, 把酒问青天, 不知天上宫阙, 今夕是何年)- 1
- 2
- 3
- 4
8.5 读取外部存储数据,构造RDD
创建RDD的第二种方法是从存储系统读取数据集,存储系统可以是本地计算机文件系统、HDFS、Cassandra、Amazon S3等等。
请按下面的步骤操作,加载HDFS中数据存储并构造RDD。
1. 启动HDFS集群。在Linux终端窗口下,键入以下命令,启动HDFS集群。1. $ start-dfs.sh- 1
然后使用jps命令查看进程,确保HDFS集群已经启动。
2、将本地数据上传至HDFS上。在Linux终端窗口下,键入以下命令。1. $ hdfs dfs -mkdir -p /data/dataset/ 2. $ hdfs dfs -put /data/dataset/resources /data/dataset/- 1
- 2
以上命令会将/data/dataset/下的resources文件夹上传到HDFS的/data/spark_demo/目录下。在resources文件夹中包含有不同类型的数据文件。可以使用以下命令查看。
1. $ hdfs dfs -ls /data/dataset/resources- 1
可以看到,在HDFS的/data/spark_demo/resources/下已经有了各种类型的数据文件:
Found 9 items -rw-r—r— 1 root supergroup 130 2019-07-05 10:40 /data/dataset/resources/employees.json -rw-r—r— 1 root supergroup 240 2019-07-05 10:40 /data/dataset/resources/full_user.avsc -rw-r—r— 1 root supergroup 5812 2019-07-05 10:41 /data/dataset/resources/kv1.txt -rw-r—r— 1 root supergroup 49 2019-07-05 10:41 /data/dataset/resources/people.csv -rw-r—r— 1 root supergroup 73 2019-07-05 10:41 /data/dataset/resources/people.json -rw-r—r— 1 root supergroup 32 2019-07-05 10:41 /data/dataset/resources/people.txt -rw-r—r— 1 root supergroup 185 2019-07-05 10:41 /data/dataset/resources/user.avsc -rw-r—r— 1 root supergroup 334 2019-07-05 10:41 /data/dataset/resources/users.avro -rw-r—r— 1 root supergroup 615 2019-07-05 10:41 /data/dataset/resources/users.parquet- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
3、加载HDFS上存储的txt文本文件,构造一个RDD。在zeppelin中执行如下代码。
1. // 定义HDFS上文件的存储路径 2. val hdfsFile = "/data/dataset/resources/people.txt" 3. 4. // 使用SparkContext的textFile方法,加载文本文件并构造RDD 5. // 注意:传入的参数是要加载的HDFS上的数据文件路径 6. val lines = sc.textFile(hdfsFile) 7. 8. // 返回RDD所有元素到Driver端 9. lines.collect()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
将光标放在代码单元中任意位置,然后同时按下【shift+enter】键,执行以上代码。输出结果如下所示:
hdfsFile: String = /data/dataset/resources/people.txt lines: org.apache.spark.rdd.RDD[String] = /data/dataset/resources/people.txt MapPartitionsRDD[4] at textFile at <console>:30 res14: Array[String] = Array(Michael, 29, Andy, 30, Justin, 19)- 1
- 2
- 3
9. 实验结果及分析:
实验结果运行准确,无误
10. 实验结论:
经过本节实验的学习,通过学习RDD的创建方式,进一步巩固了我们的Spark基础。
11. 总结及心得体会:
在调用任何transformation或action操作之前,必须先要有一个RDD。Spark提供了创建RDDs的三种方法。一种方法是将现有的集合并行化。另一种方法是加载外部存储系统中的数据集,比如文件系统。第三种方法是在现有RDD上进行转换来得到新的RDD。
本次实验演示了前两种构造RDD的方法。12、 实验知识测试
1、SparkContext通过哪个方法来加载外部的数据集(){C}
A、map()
B、text()
C、textFile()
D、read()13、实验拓展
1. 在本实验环境的HDFS中,存在如下的数据文件:/data/spark_demo/resources/people.csv。请在Zeppelin中编写Spark代码,加载该CSV文件构造RDD。

-
相关阅读:
基于vue+node.js+zigbee的蔬菜大棚温湿度物联网监控系统
2023年全球及中国小分子化药CDMO市场发展概况分析:CDMO市场有望进一步扩大[图]
Linux进程(三)--进程切换&命令行参数
Java基础 --- 线程同步 synchronized关键字
深度优先搜索和广度优先搜索
义乌外贸新趋势:跨境电商引领“内外兼修”
DM达梦数据库的使用以及数据迁移工具的使用
Elasticsearch(三) Python 使用 elasticsearch 的基本操作
MQTT 具备那些特征?
【无标题】
- 原文地址:https://blog.csdn.net/qq_44807756/article/details/125552183