-
JAVA8新特性-Stream
Stream 流式数据操作
Java 8 API添加了一个新的抽象称为流Stream,可以让你以一种声明的方式处理数据。让我们写出高效率、干净、简洁的代码。
JAVA8 中 Collection 接口增加了 stream 默认方法。 所以实现了 java.util.Collection 接口的类可以进行流操作
/** * Returns a sequential {@code Stream} with this collection as its source. * * <p>This method should be overridden when the {@link #spliterator()} * method cannot return a spliterator that is {@code IMMUTABLE}, * {@code CONCURRENT}, or <em>late-binding</em>. (See {@link #spliterator()} * for details.) * * @implSpec * The default implementation creates a sequential {@code Stream} from the * collection's {@code Spliterator}. * * @return a sequential {@code Stream} over the elements in this collection * @since 1.8 */ default Stream<E> stream() { return StreamSupport.stream(spliterator(), false); } default Stream<E> parallelStream() { return StreamSupport.stream(spliterator(), true); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
所以Stream 针对的集合, 操作的也是集合元素。配合lambda表达式可以以简洁代码完成对集合的高效的聚合运算
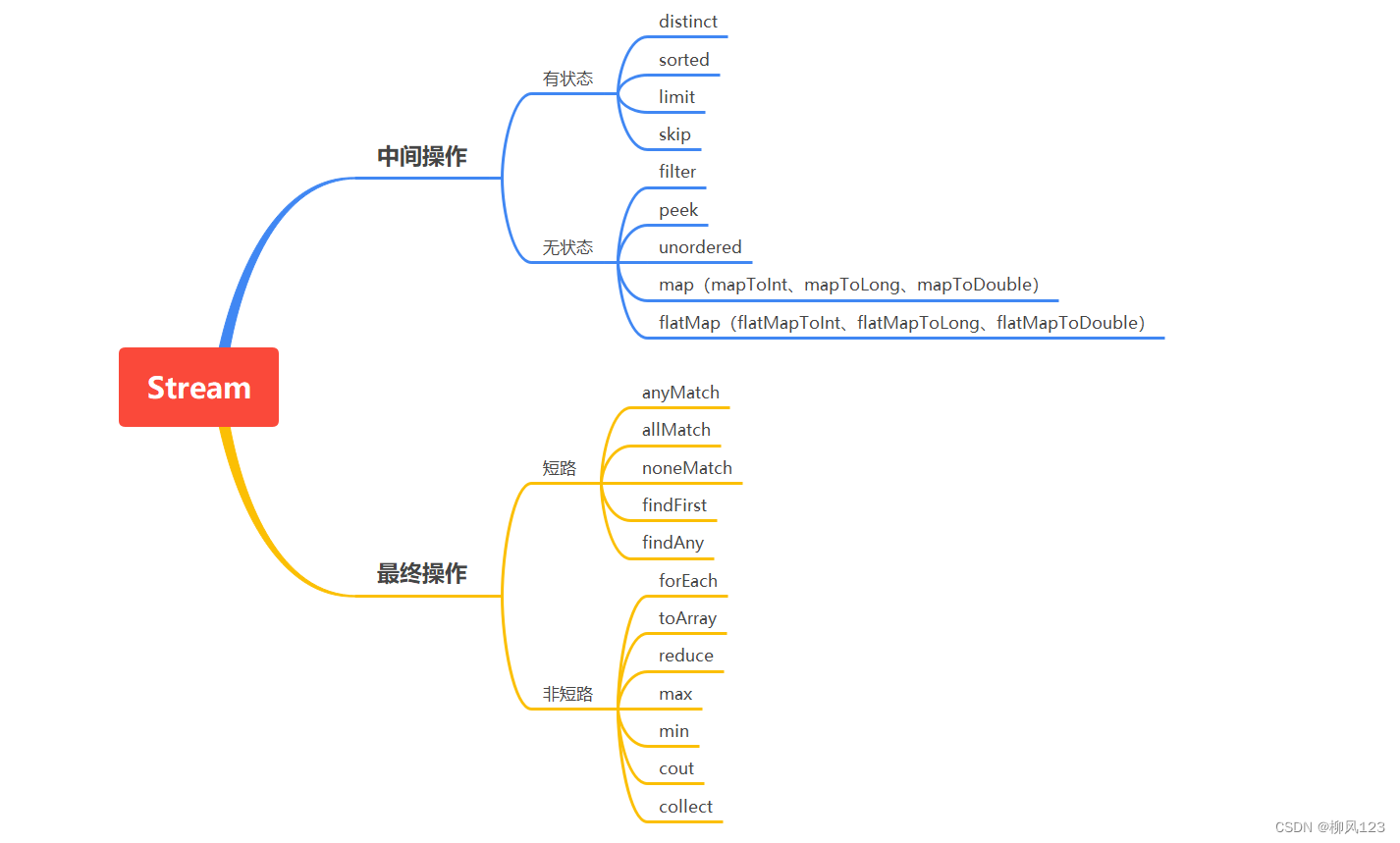
- 中间操作
- 有状态
- 无状态
- 最终操作
- 短路
- 非短路
Stream有几个特性:
- stream不存储数据,而是按照特定的规则对数据进行计算,一般会输出结果。
- stream不会改变数据源,通常情况下会产生一个新的集合或一个值。
- stream具有延迟执行特性,只有调用终端操作时,中间操作才会执行。
中间操作
调用完后,返回一个流(Stream、IntStream、LongStream 、DoubleStream )
Stream<T> filter(Predicate<? super T> predicate); <R> Stream<R> map(Function<? super T, ? extends R> mapper); IntStream mapToInt(ToIntFunction<? super T> mapper); LongStream mapToLong(ToLongFunction<? super T> mapper); DoubleStream mapToDouble(ToDoubleFunction<? super T> mapper); <R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper); IntStream flatMapToInt(Function<? super T, ? extends IntStream> mapper); LongStream flatMapToLong(Function<? super T, ? extends LongStream> mapper); DoubleStream flatMapToDouble(Function<? super T, ? extends DoubleStream> mapper); Stream<T> distinct(); Stream<T> sorted(); Stream<T> sorted(Comparator<? super T> comparator); Stream<T> peek(Consumer<? super T> action); Stream<T> limit(long maxSize); Stream<T> skip(long n);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
filter
Stream<T> filter(Predicate<? super T> predicate);- 1
入参类型是函数是接口 Predicate, 抽象方法
boolean test(T t), 有一个入参,返回类型是Boolean。过滤出,数值大于 3的集合元素
Integer[] integers = new Integer[]{1, 2, 3, 4, 5}; List<Integer> result = Stream.of(integers).filter(num -> num > 3).collect(Collectors.toList()); System.out.println(result);- 1
- 2
- 3
输出结果:
[4, 5]
map
<R> Stream<R> map(Function<? super T, ? extends R> mapper)- 1
参数类型是Function, 是函数型接口,抽象方法
R apply(T t), 接受一个参数,返回结果。入参类型和返回值类型可以不同。String[] strings = new String[]{"1", "2", "3"}; List<Integer> result = Stream.of(strings).map(Integer::valueOf).collect(Collectors.toList()); System.out.println(result);- 1
- 2
- 3
当然我们也可以使用IntSteam。 以下代码等价
result = Stream.of(strings).mapToInt(Integer::valueOf).collect(ArrayList::new, List::add, (left, right) -> left.addAll(right));- 1
peek
Stream<T> peek(Consumer<? super T> action);- 1
入参类型Consumer, 改函数型接口提供的抽象方法
void accept(T t)只有一个入参,没有返回值(void)List<Person> lists = new ArrayList<>(); Person human1 = new Person("human1", 12); Person human2 = new Person("human2", 22); lists.add(human1); lists.add(human2); lists = lists.stream().peek(person -> person.setAge(person.getAge()+10)).collect(Collectors.toList()); System.out.println(lists);- 1
- 2
- 3
- 4
- 5
- 6
- 7
输出结果:
[Person(name=human1, age=22), Person(name=human2, age=32)]
正是因为没有返回值,所有通常peek方法用于处理POJO对象。 当我们试图给集合中的每个元素追加“*”,以下代码功能未生效
String[] strings = new String[]{"1", "2", "3"}; List<String> stringList = Stream.of(strings).peek(str -> str = str.concat("*")).collect(Collectors.toList()); System.out.println(stringList);- 1
- 2
- 3
[1, 2, 3]
flatMap
<R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper);- 1
上面说过Function接口,
R apply(T t)。 Function 返回值类型是Stream。 首先对集合中的每个元素执行mapper操作,mapper操作后返回一个新的Stream,并用所有mapper返回的Stream中的元素组成一个新的Stream作为最终返回结果。String str = "1,2;4,5,6"; List<String> stringList = Stream.of(str.split(";")).flatMap(v-> Stream.of(v.split(","))).collect(Collectors.toList()); System.out.println(stringList);- 1
- 2
- 3
输出结果:
[1, 2, 4, 5, 6]
最终操作(结束操作)
结束操作调用完成后,终止调用,返回最终结果。
void forEach(Consumer<? super T> action); void forEachOrdered(Consumer<? super T> action); Object[] toArray(); <A> A[] toArray(IntFunction<A[]> generator); T reduce(T identity, BinaryOperator<T> accumulator); Optional<T> reduce(BinaryOperator<T> accumulator); <U> U reduce(U identity, BiFunction<U, ? super T, U> accumulator, BinaryOperator<U> combiner); <R> R collect(Supplier<R> supplier, BiConsumer<R, ? super T> accumulator, BiConsumer<R, R> combiner); <R, A> R collect(Collector<? super T, A, R> collector); Optional<T> min(Comparator<? super T> comparator); Optional<T> max(Comparator<? super T> comparator); long count(); boolean anyMatch(Predicate<? super T> predicate); boolean allMatch(Predicate<? super T> predicate); boolean noneMatch(Predicate<? super T> predicate); Optional<T> findFirst(); Optional<T> findAny();- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
collect
<R, A> R collect(Collector<? super T, A, R> collector)- 1
Collectors 工具类, 提供了各种方法,返回Collector
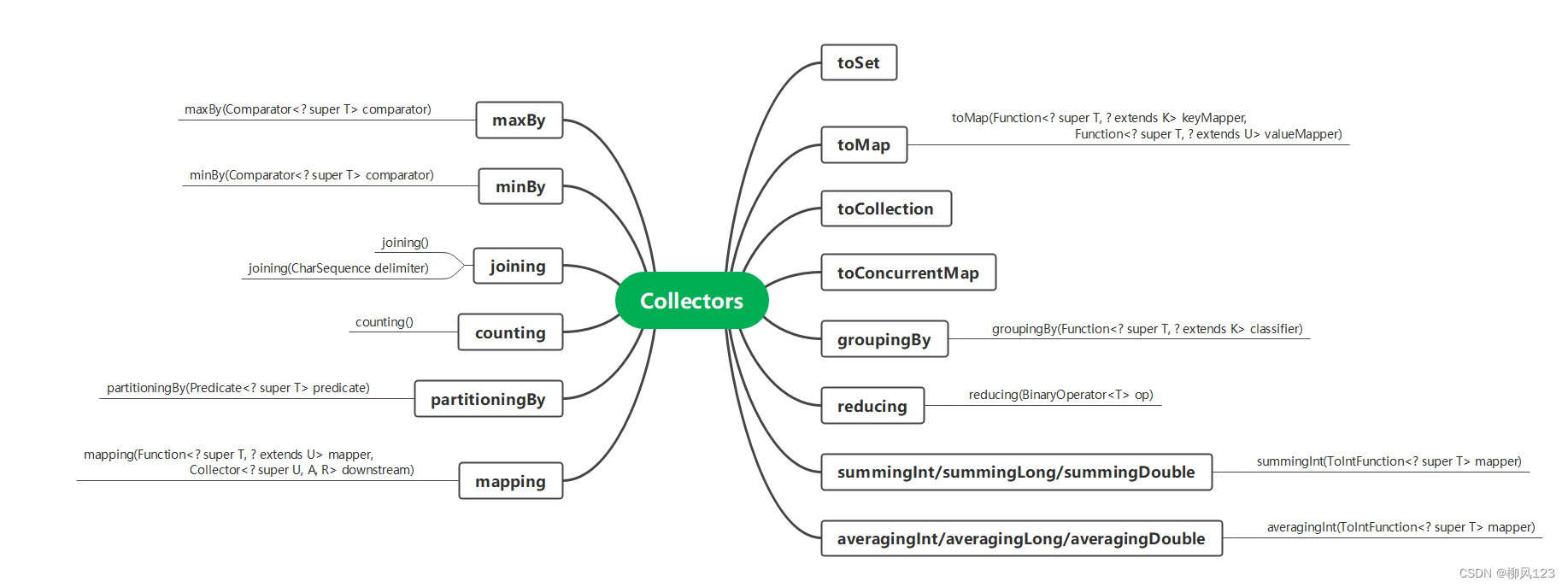
toList
Collector<T, ?, List<T>> toList() { return new CollectorImpl<>((Supplier<List<T>>) ArrayList::new, List::add, (left, right) -> { left.addAll(right); return left; }, CH_ID); }- 1
- 2
- 3
- 4
- 5
扫一眼,大概就知道 toList,返回的是一个ArrayList, 聚合使用 list.add方法。初始化使用 list.addAll方法
List<String>strings = Arrays.asList("abc", "", "bc", "efg", "abcd","", "jkl"); List<String> filtered = strings.stream().filter(string -> !string.isEmpty()).collect(Collectors.toList());- 1
- 2
String mergedString = strings.stream().filter(string -> !string.isEmpty()).collect(Collectors.joining(", ")); System.out.println("合并字符串: " + mergedString);- 1
- 2
生成指定的List类型
Collectors 类中toList 方法没有重载。但是可以通过Collectors.toCollection方法实现。
List<String> strings = Arrays.asList("abc", "", "bc", "efg", "abcd","", "jkl"); List list = strings.stream().collect(Collectors.toCollection(LinkedList::new)); System.out.println(list); System.out.println(list.getClass());- 1
- 2
- 3
- 4
输出结果;
[abc, , bc, efg, abcd, , jkl]
class java.util.LinkedListtoMap
@Data @AllArgsConstructor @NoArgsConstructor public class Person { private String name; private int age; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
List<Person> lists=new ArrayList<>(); Person human1=new Person("human1",12); Person human2=new Person("human2",22); lists.add(human1); lists.add(human2); Map<String, Person> maps = lists.stream().collect(Collectors.toMap(Person::getName,Function.identity())); System.out.println(maps);- 1
- 2
- 3
- 4
- 5
- 6
- 7
{human2=Person(name=human2, age=22), human1=Person(name=human1, age=12)}
Function.identity() 方法总是返回输入的参数。即将输入的集合元素原样返回
/** * Returns a function that always returns its input argument. * * @param <T> the type of the input and output objects to the function * @return a function that always returns its input argument */ static <T> Function<T, T> identity() { return t -> t; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
这个t->t, 实际是Function的lambda表达式的写法。
Function<Person, Person> function1 = new Function<Person, Person>(){ @Override public Person apply(Person person) { return person; } }; // lambda 表达式 Function<Person, Person> function1 = person -> person;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
Key冲突
生成Map时,如果key重复,则会抛出异常 java.lang.IllegalStateException: Duplicate key xxxxx
List<Person> lists=new ArrayList<>(); Person human1=new Person("human1",12); Person human2=new Person("human1",22); lists.add(human1); lists.add(human2); Map<String, Person> maps = lists.stream().collect(Collectors.toMap(Person::getName,Function.identity())); System.out.println(maps);- 1
- 2
- 3
- 4
- 5
- 6
- 7
运行上面的程序会抛出以下错误信息
java.lang.IllegalStateException: Duplicate key human1
Collectors.toMap 方法第三个参数,可以用于控制key相同时如何处理。下面代码的意思是如果key相同,则保留最后一个key-value键值对
Map<String,Object> maps=lists.stream().collect(Collectors.toMap(Person::getName, Person::getAge,(val1,val2)->val2));- 1
调用的方法,
Collector<T, ?, Map<K,U>> toMap(Function<? super T, ? extends K> keyMapper, Function<? super T, ? extends U> valueMapper, BinaryOperator<U> mergeFunction)- 1
- 2
- 3
BinaryOperator 接口继承了函数型接口 BinaryOperator,
@FunctionalInterface public interface BiFunction<T, U, R> { R apply(T t, U u); }- 1
- 2
- 3
- 4
调试代码最总可以看到,调用 Map接口的默认方法
default V merge(K key, V value, BiFunction<? super V, ? super V, ? extends V> remappingFunction) { V oldValue = get(key); V newValue = (oldValue == null) ? value : remappingFunction.apply(oldValue, value); if(newValue == null) { remove(key); } else { put(key, newValue); } return newValue; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
生成指定的Map类型
默认返回的Map类型为HashMap,当然我们可以在生成Map的时候指定我们需要的类型。
Map<String,Object> maps=lists.stream().collect(Collectors.toMap(Person::getName, Person::getAge,(key1,key2)->key2),TreeMap::new); System.out.println(maps instanceof TreeMap);- 1
- 2
输出结果
true
groupingBy
Collector<T, ?, Map<K, List<T>>> groupingBy(Function<? super T, ? extends K> classifier) { return groupingBy(classifier, toList()); } Collector<T, ?, Map<K, D>> groupingBy(Function<? super T, ? extends K> classifier, Collector<? super T, A, D> downstream) { return groupingBy(classifier, HashMap::new, downstream); } Collector<T, ?, M> groupingBy(Function<? super T, ? extends K> classifier, Supplier<M> mapFactory, Collector<? super T, A, D> downstream)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
List<Person> lists = new ArrayList<>(); Person human1 = new Person("human1", 12); Person human2 = new Person("human1", 22); lists.add(human1); lists.add(human2); Map<String, List<Person>> maps = lists.stream().collect(Collectors.groupingBy(Person::getName)); System.out.println(maps);- 1
- 2
- 3
- 4
- 5
- 6
- 7
从上面可以看到, Map 类型是HashMap, List是ArrayList。 我们可以根据需要更改为其他类型。
maps = lists.stream().collect(Collectors.groupingBy(Person::getName, LinkedHashMap::new , Collectors.toCollection(LinkedList::new)));- 1
joining
joining() joining(CharSequence delimiter) joining(CharSequence delimiter, CharSequence prefix, CharSequence suffix)- 1
- 2
- 3
String[] strArray = "1,2,3,4".split(","); String str = Stream.of(strArray).collect(Collectors.joining()); System.out.println("Collectors.joining(): " + str); // 连接集合中的每个元素拼成字符串, 并以“-”为分隔符 str = Stream.of(strArray).collect(Collectors.joining("-")); System.out.println("Collectors.joining(-): "+ str); // 连接集合中的每个元素拼成字符串, 并以“-”为分隔符,元素拼接完成在前后追加 前缀和后缀 str = Stream.of(strArray).collect(Collectors.joining("-", "(", ")")); System.out.println("Collectors.joining(-, (,) ): "+str);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
输出结果:
Collectors.joining(): 1234
Collectors.joining(-): 1-2-3-4
Collectors.joining(-, (,) ): (1-2-3-4)mapping
mapping、reduce、maxBy、minBy 实际上完全可以使用Stream中提供的方法。
Collector<T, ?, R> mapping(Function<? super T, ? extends U> mapper, Collector<? super U, A, R> downstream)- 1
- 2
String[] strings = new String[]{"1", "2", "3"}; Set<Integer> set = Stream.of(strings).collect(Collectors.mapping(Integer::valueOf, Collectors.toSet())); System.out.println(set);- 1
- 2
- 3
使用Stream提供的方法,可读性更好一些。
set = Stream.of(strings).map(Integer::valueOf).collect(Collectors.toSet());- 1
partitioningBy
Collector<T, ?, Map<Boolean, List<T>>> partitioningBy(Predicate<? super T> predicate) { return partitioningBy(predicate, toList()); }- 1
- 2
- 3
Integer[] integers = new Integer[]{1, 2, 3, 4, 5}; Map<Boolean, List<Integer>> result = Stream.of(integers).collect(Collectors.partitioningBy((num) -> num > 2)); System.out.println(result);- 1
- 2
- 3
输出结果:
{false=[1, 2], true=[3, 4, 5]}
从上面的结果可以看出,partitioningBy是特殊的groupingBy。Predicate运算的结果(true/false)作为Map的key
result = Stream.of(integers).collect(Collectors.groupingBy((num) -> num > 2));- 1
reduce
public static void main(String[] args) { List<Integer> numbers = new ArrayList<>(); for (Integer integer = 0;integer<10;integer++){ numbers.add(integer); } // 求和 Optional<Integer> sum = numbers.stream().reduce(Integer::sum); //求最大值 Optional<Integer> max = numbers.stream().reduce(Integer::max); //求最小值 Optional<Integer> min = numbers.stream().reduce(Integer::min); System.out.println(sum.get()); System.out.println(max.orElse(1)); System.out.println(min.orElse(1)); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
45
9
0 -
相关阅读:
PYTHON-模拟练习题目集合
WEB安全基础 - - -命令执行漏洞
ApiPost7使用介绍 | HTTP && Websocket
Java剑指Offer青蛙跳台阶问题
Verilog 实现CDC中单bit 跨时钟域,从慢时钟域到快时钟域
ARMday2
多数网工碌碌无为,都是败在这件事上
node开发微信群聊机器人第⑤章
预约上门系统软件小程序app如何搭建
【编程题】【Scratch四级】2021.12 聪明的小猫
- 原文地址:https://blog.csdn.net/yamadeee/article/details/125554378
