-
Clickhouse 原理
Clickhouse 原理
分区目录的合并过程
当前 CK 版本
select version();-- 21.8.5.7- 1
创建新表
CREATE TABLE dpaas_db.test_gc_part on cluster my_cluster( `tableName` String COMMENT '表名称', `traceId` String COMMENT 'UUID', `type` String COMMENT '消息类型', `scene` String COMMENT '场景', `createTime` datetime default toDateTime(now()) COMMENT '创建时间' ) ENGINE = ReplicatedMergeTree('/clickhouse/my_cluster/dpaas_db/tables/{shard}/test_gc_part/0','{replica}') PARTITION BY toDate(createTime) ORDER BY tableName SETTINGS index_granularity = 8192; CREATE TABLE dpaas_db.test_gc on cluster my_cluster( `tableName` String COMMENT '表名称', `traceId` String COMMENT 'UUID', `type` String COMMENT '消息类型', `scene` String COMMENT '场景', `createTime` datetime default toDateTime(now()) COMMENT '创建时间' ) ENGINE = Distributed('my_cluster','dpaas_db','test_gc_part',rand());- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
查看存储目录
[root@hadoop1 test_gc_part]# pwd /var/lib/clickhouse/data/dpaas_db/test_gc_part [root@hadoop1 test_gc_part]# ll total 8 drwxr-x--- 2 clickhouse clickhouse 4096 Apr 21 19:45 detached -rw-r----- 1 clickhouse clickhouse 1 Apr 21 19:45 format_version.txt [root@hadoop1 test_gc_part]#- 1
- 2
- 3
- 4
- 5
- 6
- 7
插入数据
- 插入一条当天分区的数据
insert into dpaas_db.test_gc_part values('tableName','uuid','type','dataset',now());- 1
发现此时会有一个
20220421_0_0_0的分区- 插入两条明天和后天分区的数据
insert into dpaas_db.test_gc_part values('tableName','uuid','type','dataset',addDays(now(),1)); insert into dpaas_db.test_gc_part values('tableName','uuid','type','dataset',addDays(now(),2));- 1
- 2
发现此时会多两个目录
20220422_0_0_0和20220423_0_0_0- 再插入一条当天分区的数据
insert into dpaas_db.test_gc_part values('tableName','uuid','type','dataset',now());- 1

- 在同时插入10条数据到当天分区里

此时十条数据插入后又新增了一个目录
20220421_2_2_0不过可以看到此时数据没有被合并
- 手动触发合并分区

- 系统后台会定时异步删除合并后的分区(默认8分钟)

- 从表中看效果
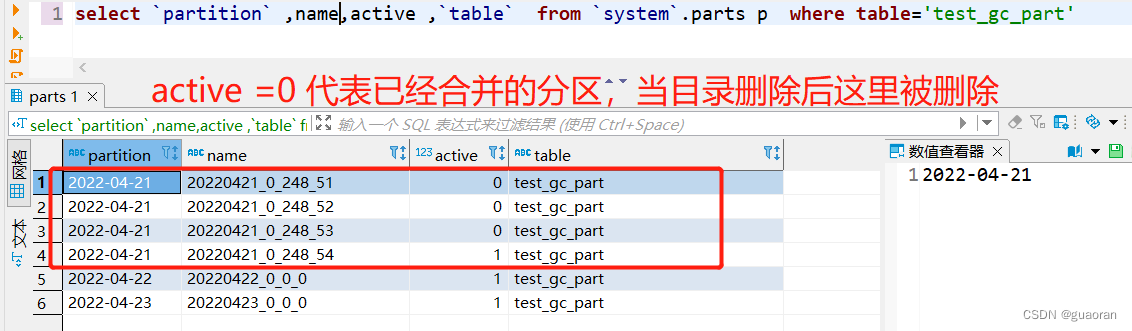
- 最终的效果
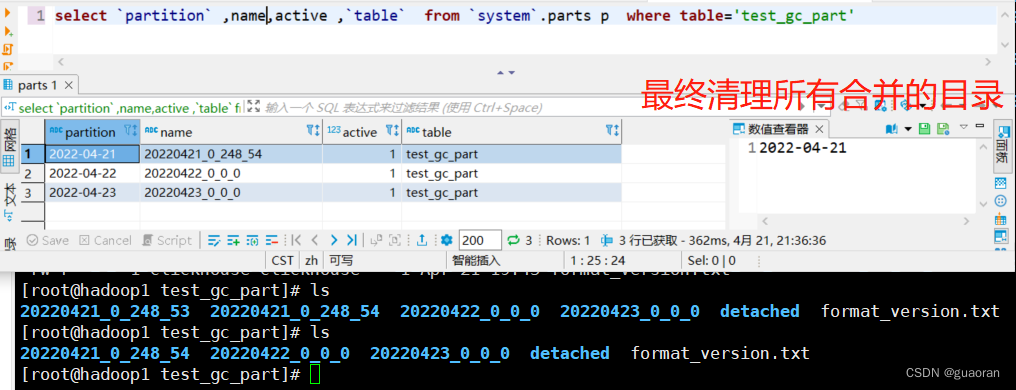
- 在插入两条数据,一条是20220423,一条是20220420
insert into dpaas_db.test_gc_part values('tableName','uuid','type','dataset',addDays(now(),2)); insert into dpaas_db.test_gc_part values('tableName','uuid','type','dataset',addDays(now(),-1));- 1
- 2
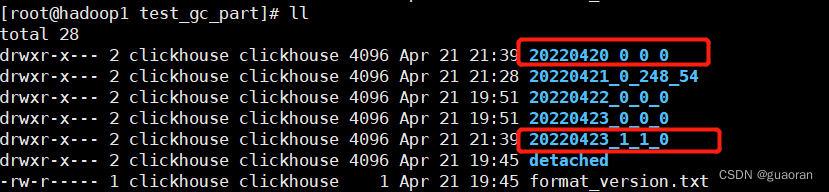
目录规则
20220421_0_2_120220421是当前分区0MinBlockNum 最小数据块编号2MaxBlockNum 最大数据块编号0Level 分区合并的次数
同一分区,MinBlockNum 是递增的,不同分区不递增。默认从0开始
当同一分区目录比较多时,会怎么样?什么时候会出现这种问题?
当插入大批量数据时,如果单批量的条数比较少,会导致合并分区的速度小于插入分区的速度时会报错。
clickhouse,DB::Exception: Too many parts (300). Merges are processing significantly slower than inserts.
分区目录下的文件结构
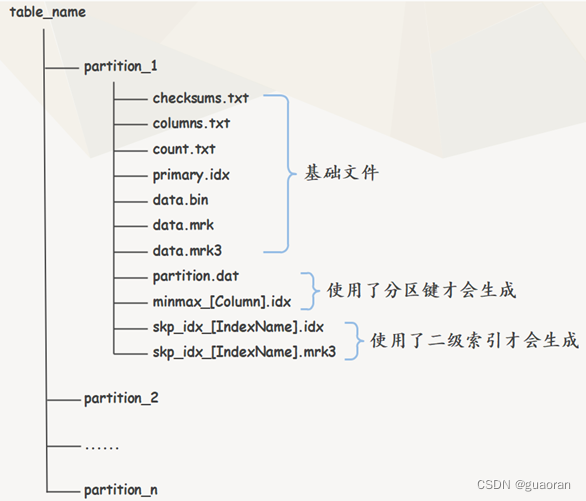
- 真实的结构
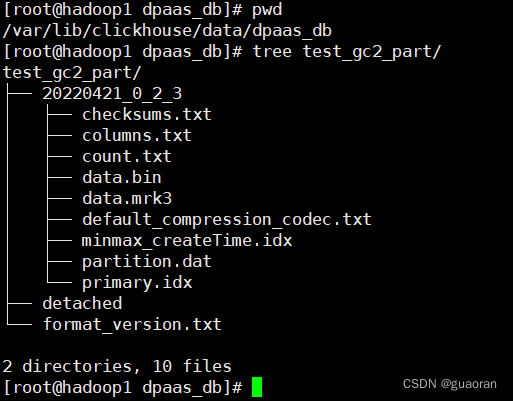
-
checksums.txt:校验文件,使用二进制格式存储。它保存了primary.idx、count.txt文件的size大小和size的hash值。用于快速校验文件的完整性和正确性 -
columns.txt: 列信息文件 -
count.txt:计数文件,当前分区下数据总量。 -
primary.idx:一级索引文件,使用二进制格式存储。用于存放稀疏索引,一张MergeTree表只能声明一次一级索引(通过ORDER BY或者PRIMARY KEY) -
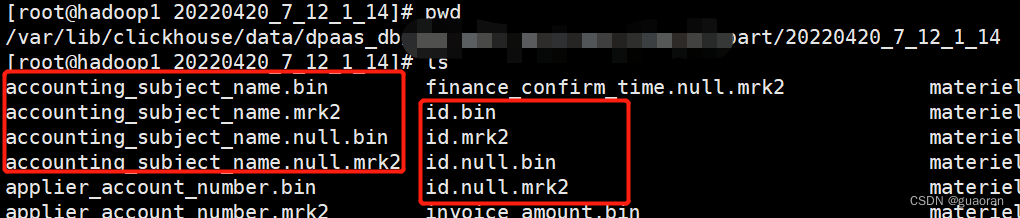
[Column].bin、data.bin: 数据文件,用于存储某一列的数据。使用压缩格式存储。默认LZ4压缩格式-
当字段比较少的时候会将所有字段的
.bin都合并到data.bin里 -
当字段多的时候会单独作为
[Column].bin,例如:id.bin。如果id是Nullable可为空的字段,则还会多出来[Column].null.bin -
data.mark和data.mark2同理
-
-
[Column].mrk、data.mrk: 列字段标记文件,使用二进制格式存储。标记.bin文件中数据的偏移量。这里保存的是稀疏索引与.bin数据文件之间的映射关系。即首先通过稀疏索引(primary.idx)找到对应数据的偏移量信息(.mrk),再通过偏移量直接从.bin文件中读取数据 -
[Column].mrk2、data.mrk2: 如果使用了自适应大小的索引间隔,则标记文件会以.mrk2命名。工作原理和作用与.mrk标记文件相同 -
partition.dat和minmax_[Column].idx:如果使用了 分区键,则会额外生成这两个文件。使用二进制格式存储partition.dat用于保存当前分区下分区表达式最终生成的值minmax_[Column].idx该索引文件用于记录当前分区下分区字段对应原始数据的最小和最大值。- 在这些分区索引的作用下,进行数据查询时能够快速跳过不必要的分区目录,从而减少需要扫描的数据范围
-
skp_idx_[Column].idx、skp_idx_[Column].mrk:如果在建表语句中声明了二级索引,则会额外生成相应的二级索引与标记文件。它们同样也使用二进制存储。二级索引在ClickHouse中又称跳数索引,目前拥有minmax、set、ngrambf_v1和tokenbf_v1四种类型。最终目标与一级稀疏索引相同,都是为了进一步减少所需扫描的数据范围,以加速整个查询过程。
count.txt:计数文件,当前分区下数据总量。-
primary.idx:一级索引文件,使用二进制格式存储。用于存放稀疏索引,一张MergeTree表只能声明一次一级索引(通过ORDER BY或者PRIMARY KEY) -
[Column].bin、data.bin: 数据文件,用于存储某一列的数据。使用压缩格式存储。默认LZ4压缩格式-
当字段比较少的时候会将所有字段的
.bin都合并到data.bin里 -
当字段多的时候会单独作为
[Column].bin,例如:id.bin。如果id是Nullable可为空的字段,则还会多出来[Column].null.bin -
data.mark和data.mark2同理
-
-
[Column].mrk、data.mrk: 列字段标记文件,使用二进制格式存储。标记.bin文件中数据的偏移量。这里保存的是稀疏索引与.bin数据文件之间的映射关系。即首先通过稀疏索引(primary.idx)找到对应数据的偏移量信息(.mrk),再通过偏移量直接从.bin文件中读取数据 -
[Column].mrk2、data.mrk2: 如果使用了自适应大小的索引间隔,则标记文件会以.mrk2命名。工作原理和作用与.mrk标记文件相同 -
partition.dat和minmax_[Column].idx:如果使用了 分区键,则会额外生成这两个文件。使用二进制格式存储partition.dat用于保存当前分区下分区表达式最终生成的值minmax_[Column].idx该索引文件用于记录当前分区下分区字段对应原始数据的最小和最大值。- 在这些分区索引的作用下,进行数据查询时能够快速跳过不必要的分区目录,从而减少需要扫描的数据范围
-
skp_idx_[Column].idx、skp_idx_[Column].mrk:如果在建表语句中声明了二级索引,则会额外生成相应的二级索引与标记文件。它们同样也使用二进制存储。二级索引在ClickHouse中又称跳数索引,目前拥有minmax、set、ngrambf_v1和tokenbf_v1四种类型。最终目标与一级稀疏索引相同,都是为了进一步减少所需扫描的数据范围,以加速整个查询过程。
-
相关阅读:
Linux系统中安装Docker
算法刷题日志 hot100 数组分类
Reparameterization trick(重参数化技巧)
支付宝微信支付业务流程图
【Shell牛客刷题系列】SHELL18 域名进行计数排序处理:正则表达式的升级打怪之旅~
C语言实现循环双链表
PDF如何转word文档
【深度学习】实验13 使用Dropout抑制过拟合
乐观锁和悲观锁区别
无线信道划分
- 原文地址:https://blog.csdn.net/guaoran/article/details/125563005
