-
Observability:如何使用 Elastic Agents 把定制的日志摄入到 Elasticsearch 中
在我之前的文章 “Observability:使用 Elastic Agent 来摄入日志及指标 - Elastic Stack 8.0”,我详细地描述了如何安装 Elasticsearch,Stack 及 Elastic Agents 来采集系统日志及指标。很多开发者可能会有疑问,在我们的实际使用中,我们更多的可能是需要采集定制的应用日志,而不是系统日志。那么在这个时候,我们该如何使用 Elastic Agents 来把这些日志摄入呢?在以前的系统中,我们可以使用如下的几种方式来采集日志:

- 我们可以直接使用 Beats 把数据传入到 Elasticsearch 中。对数据的处理,我们可以使用 Beats 的 processors 来处理数据,或者通过 Elasticsearch 集群的 ingest nodes 来处理数据。
- 我们可以通过 Beats => Logstash => Elasticsearch。针对这种情况,我们可以分别在 Beats,Logstash 或者 Elasticsearch 集群的 ingest nodes 来处理数据。
- 我们可以直接使用各种编程语言来直接向 Elasticsearch 集群进行写入。我们可以使用 Elasticsearch 集群的 ingest nodes 来处理数据。
在今天的文章里,我们来详细地描述如何使用 Elastic Agents 把应用中的定制日志摄入到 Elasticsearch 中并进行分析。在今天的演示中,我将使用如下测试环境:

我将使用 Elastic Stack 8.3 来进行安装并展示。
准备日志
为了方便,我们使用我之前的一个教程写的文章里的例子来生成日志。我使用 Python 应用来生成日志。请参考文章 “Beats: 使用 Filebeat 进行日志结构化 - Python”。我们按照如下的步骤在 Ubuntu OS 的机器上来运行应用:
- liuxg@liuxgu:~/python/logs$ pwd
- /home/liuxg/python/logs
- liuxg@liuxgu:~/python/logs$ ls
- createlogs.py createlogs_1.py createlogs_2.py filebeat_json.yml json_logs test.log
- liuxg@liuxgu:~/python/logs$ python createlogs_2.py
- liuxg@liuxgu:~/python/logs$ cat json_logs
- {"user_name": "arthur", "id": 42, "verified": false, "event": "logged_in"}
- {"user_name": "arthur", "id": 42, "verified": true, "event": "changed_state"}
可以看出来在我的应用目录里会生成一个叫做 json_logs 的文件。它的内容如上所示。上面的文档路径及文件名将在下面的配置中要用到。我们的日志路径是:
/home/liuxg/python/logs/json_logs安装
在进行下面的练习之前,我们必须安装好 Elasticsearch 及 Kibana。我们可以参考之前的文章:
我们按照上面的要求进行安装 Elasticsearch 及 Kibana。为了能够让 fleet 正常工作,内置的 API service 必须启动。我们必须为 Elasticsearch 的配置文件 config/elasticsearch.yml 文件配置:
xpack.security.authc.api_key.enabled: true配置完后,我们再重新启动 Elasticsearch。针对 Kibana,我们也需要做一个额外的配置。我们需要修改 config/kibana.yml 文件。在这个文件的最后面,添加如下的一行:
- xpack.encryptedSavedObjects.encryptionKey: 'fhjskloppd678ehkdfdlliverpoolfcr'
如果你不想使用上面的这个设置,你可以使用如下的方式来获得:
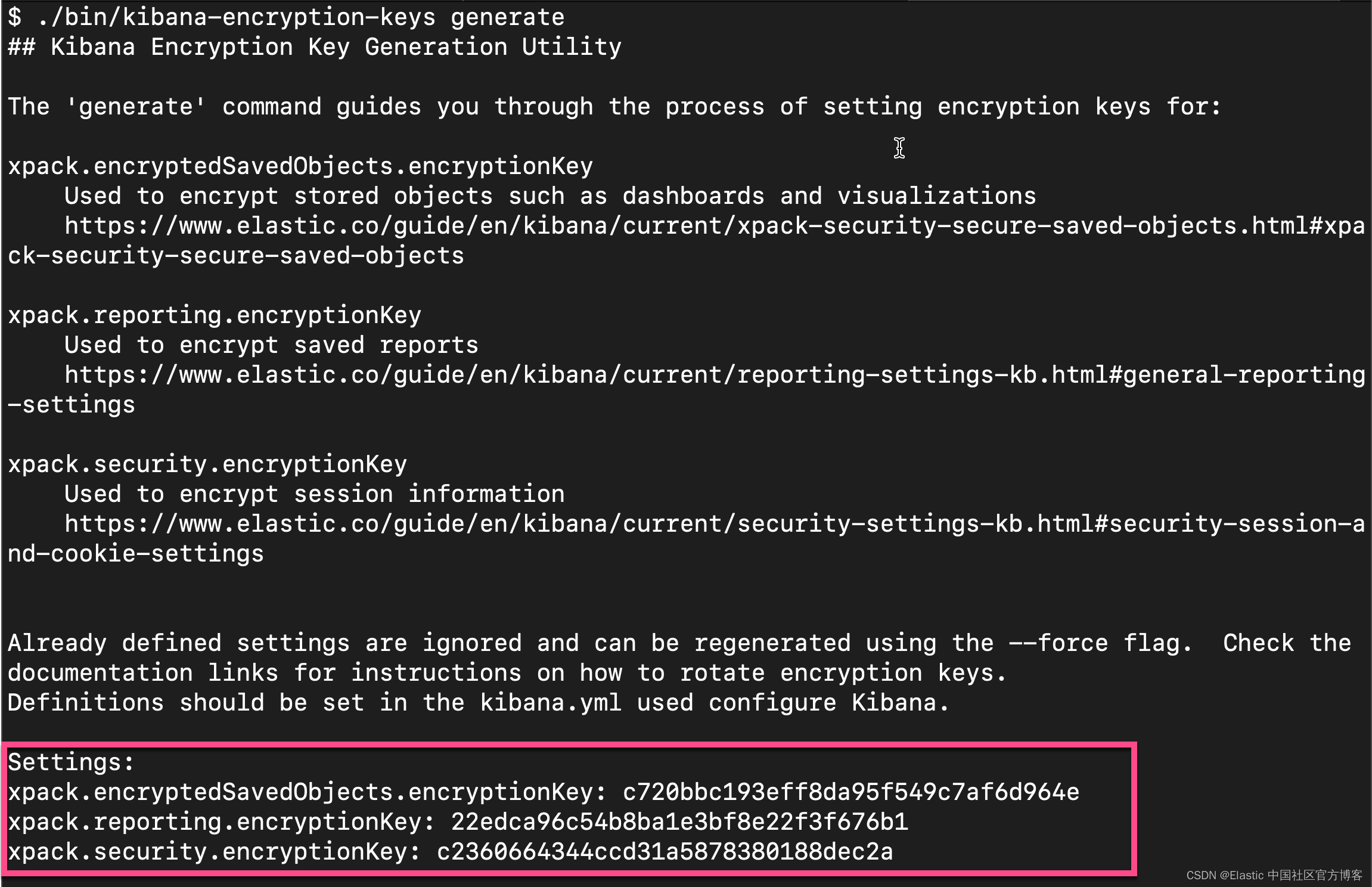
从上面的输出中,我们可以看出来,有三个输出的 key。我们可以把这三个同时拷贝,并添加到 config/kibana.yml 文件的后面。当然,我们也可以只拷贝其中的一个也可。我们再重新启动 Kibana。
这样我们对 Elasticsearch 及 Kibana 的配置就完成。 针对 Elastic Stack 8.0 以前的版本安装,请阅读我之前的文章 “Observability:如何在最新的 Elastic Stack 中使用 Fleet 摄入 system 日志及指标”。
除此之外,Kibana 需要 Internet 连接才能从 Elastic Package Registry 下载集成包。 确保 Kibana 服务器可以连接到https://epr.elastic.co 的端口 443 上 。如果你的环境有网络流量限制,有一些方法可以解决此要求。 有关详细信息,请参阅气隙环境。
目前,Fleet 只能被具有 superuser role 的用户所使用。
配置 Fleet
使用 Kibana 中的 Fleet 将日志、指标和安全数据导入 Elastic Stack。第一次使用 Fleet 时,你可能需要对其进行设置并添加 Fleet Server。在做配置之前,我们首先来查看一下有没有任何的 integration 被安装:

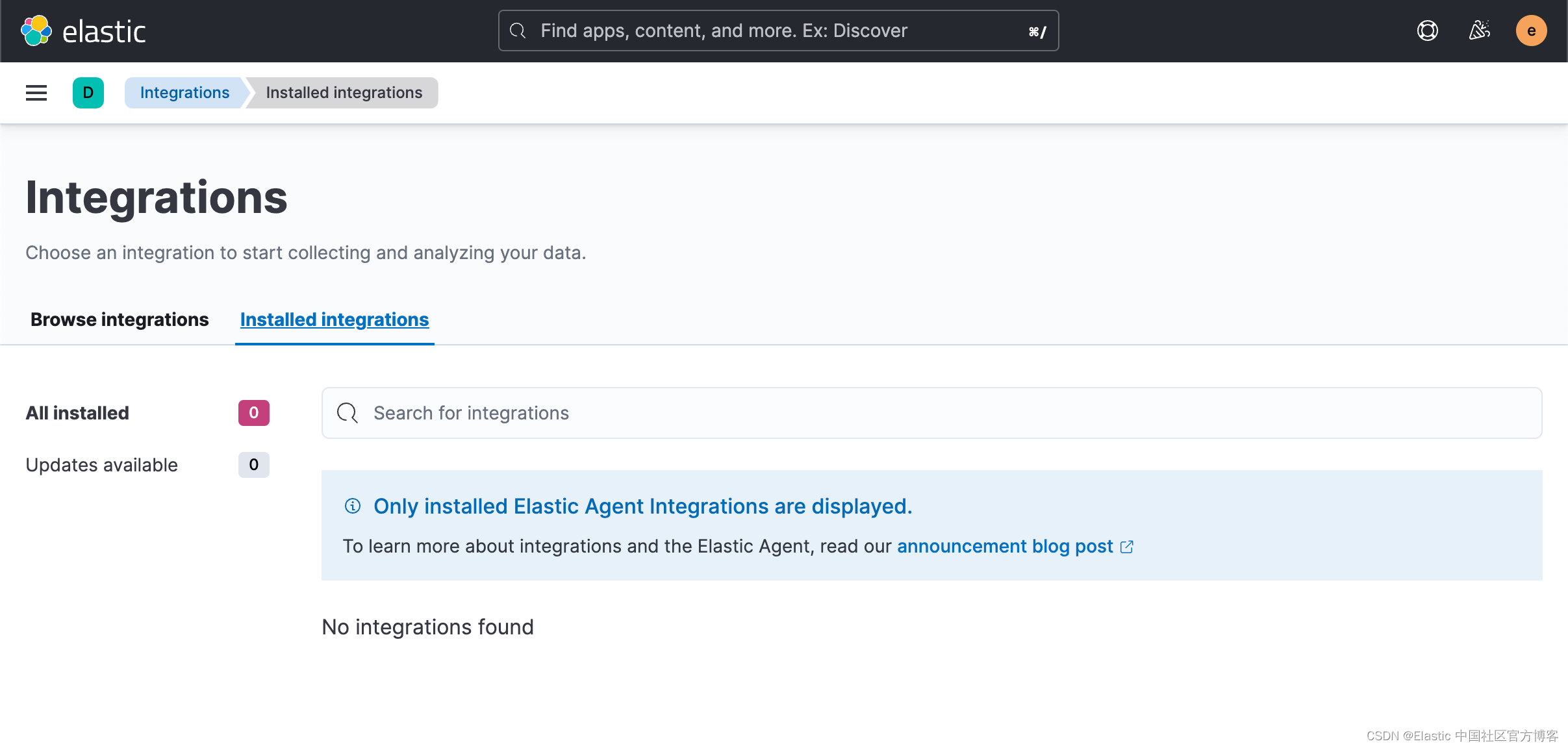 从上面我们可以看出来没有任何安装的 integrations。
从上面我们可以看出来没有任何安装的 integrations。我们打开 Fleet 页面:





我们接下来添加 Agent:

 上面显示我们的 Fleet Sever policy 被成功地创建了。我们需要把我们的 Fleet Server 安装到 Ubuntu OS 机器上。
上面显示我们的 Fleet Sever policy 被成功地创建了。我们需要把我们的 Fleet Server 安装到 Ubuntu OS 机器上。 
我们的目标机器是 Linux OS。我们点击上面的拷贝按钮,并在 Linux OS 上进行安装:
- curl -L -O https://artifacts.elastic.co/downloads/beats/elastic-agent/elastic-agent-8.3.0-linux-x86_64.tar.gz
- tar xzvf elastic-agent-8.3.0-linux-x86_64.tar.gz
- cd elastic-agent-8.3.0-linux-x86_64
- sudo ./elastic-agent install \
- --fleet-server-es=https://192.168.0.3:9200 \
- --fleet-server-service-token=AAEAAWVsYXN0aWMvZmxlZXQtc2VydmVyL3Rva2VuLTE2NTY1Njg5MTE1NTk6clBaX1pidXNTdTZXc2Fvb0ROcXVhUQ \
- --fleet-server-policy=fleet-server-policy \
- --fleet-server-es-ca-trusted-fingerprint=764021beb30446365d829986a362ffba82d03f4ff7861839a60f7951b8e83e7a
我们按照 Kibana 中的提示来安装:


等过一段时间,我们可以看到这个运用于 192.168.0.4 机器上的 Agents 的状态也变为 healthy:

由于我们的 Elastic Agent 和 Fleet Server 是在一个服务器上运行的,所以,我们直接在 Fleet Server Policy 里添加我们想要的 integration。如果你的 Elastic Agent 可以运行于另外的一个机器上,而不和 Fleet Server 在同一个机器上,你可以创建一个新的 policy,比如 logs。然后让 agent 赋予给这个 新创建的 policy。
我们直接在这个 Fleet Server Policy 里添加一个叫做 custom log 的集成:



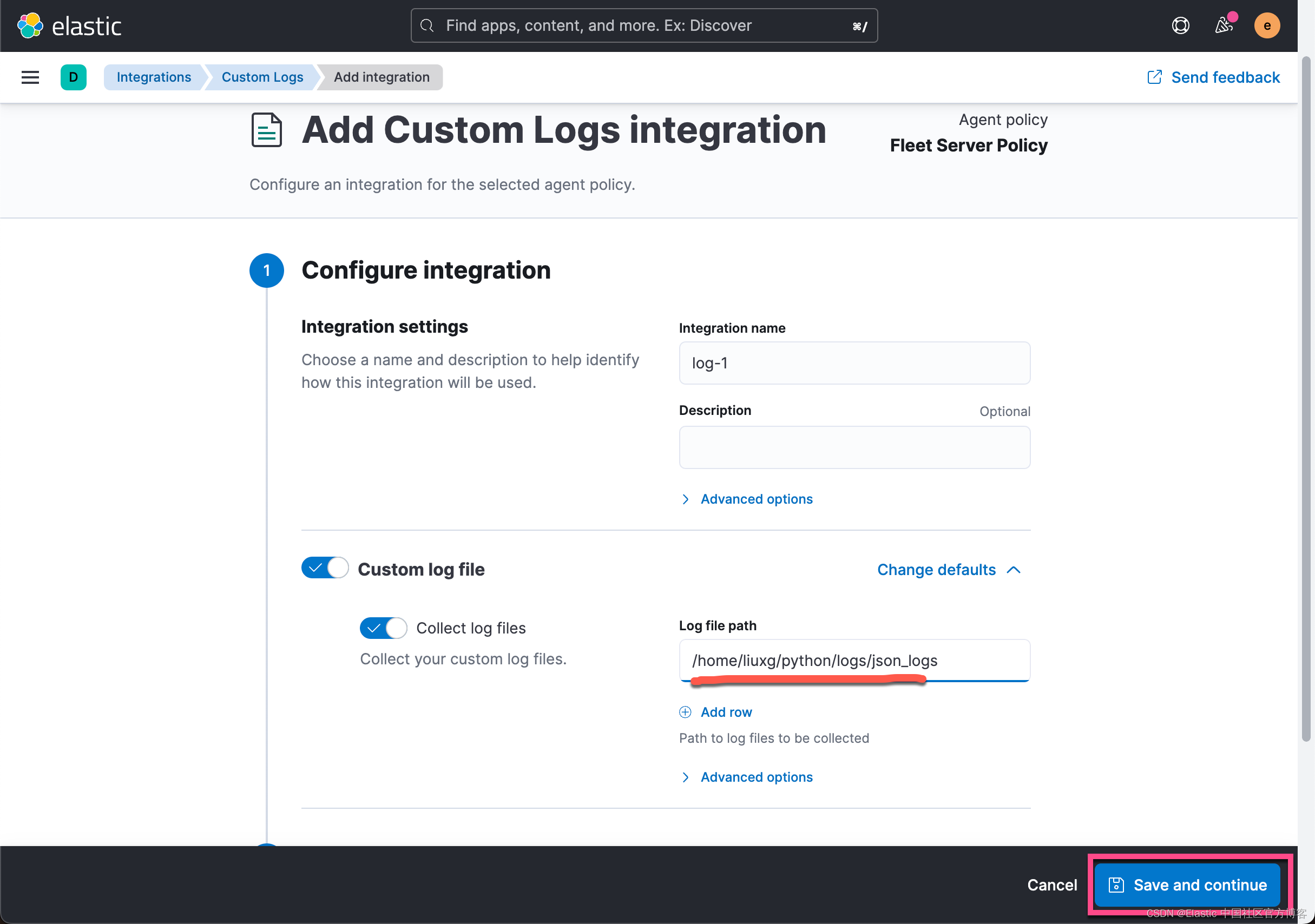
在上面,我们把 Ubuntu OS 上的日志的路径添加进去:


在上面,我们可以看到新增加的 log-1 集成。
如果你之前已经生成过 json_logs 日志文件,我们可以删除当前目录的文件,并再次生成该文件:
- liuxg@liuxgu:~/python/logs$ pwd
- /home/liuxg/python/logs
- liuxg@liuxgu:~/python/logs$ ls
- createlogs.py createlogs_1.py createlogs_2.py filebeat_json.yml json_logs test.log
- liuxg@liuxgu:~/python/logs$ rm json_logs
- liuxg@liuxgu:~/python/logs$ python createlogs_2.py
我们接下来回到 Discover 去查看:

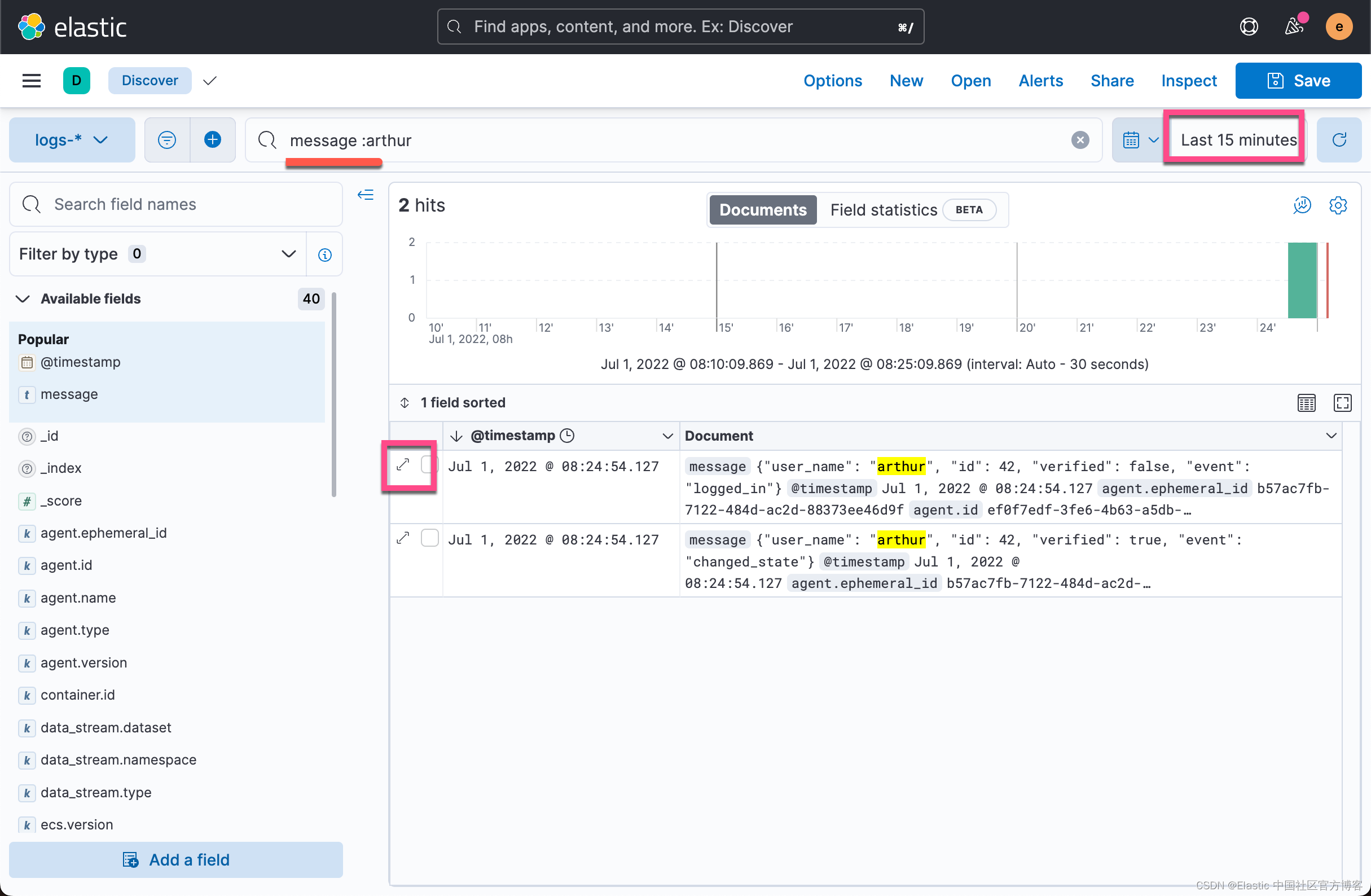
在搜索框中输入 json_logs,我们发现在过去 15分钟之内有两个新摄入的文档。我们再次查看 message 的内容:

显然,我们可以看到 message 字段显示的就是我们之前在日志中的信息。它是一个 JSON 格式的信息。这个虽然好,但是它不是结构化的日志信息。我们想要的是 user_name 为文档的一个字段,id 为另外一个字段这样的结构化信息。在之前的 Filebeat 中,我们可以轻松地使用 Filebeat 所提供的 processors 或者就像如同在文章 “Beats: 使用 Filebeat 进行日志结构化 - Python” 使用的那样。我们可以使用 Filebeat input type 所提供的固有功能来完成。再者,我们还可以使用 Elasticsearch 集群的 ingest node 来完成。
那么针对我们目前的 Elastic Agent 摄入方式,我们该如何结构化这个 message 信息呢?答案是使用 ingest pipeline。
我们在 Kibana 的 Dev Tools 中创建如下的 ingest pipeline:
- POST _ingest/pipeline/_simulate
- {
- "pipeline": {
- "description": "structure a JSON format message",
- "processors": [
- {
- "json": {
- "field": "message",
- "target_field": "json_fields"
- }
- }
- ]
- },
- "docs": [
- {
- "_source": {
- "message": "{\"user_name\": \"arthur\", \"id\": 42, \"verified\": false, \"event\": \"logged_in\"}"
- }
- }
- ]
- }
在上面,我们通过 _simulate 来测试我们的 pipeline:
- {
- "docs": [
- {
- "doc": {
- "_index": "_index",
- "_id": "_id",
- "_source": {
- "json_fields": {
- "verified": false,
- "id": 42,
- "event": "logged_in",
- "user_name": "arthur"
- },
- "message": """{"user_name": "arthur", "id": 42, "verified": false, "event": "logged_in"}"""
- },
- "_ingest": {
- "timestamp": "2022-07-01T00:03:30.040008Z"
- }
- }
- }
- ]
- }
如上所示,我们的 josn processor 能够非常出色地完成 message 的结构化,并把结构化的信息保存于一个叫做 json_fields 的字段中。在完成上面的模拟后,我们使用如下的命令来创建一个 pipeline:
- PUT _ingest/pipeline/message_structure
- {
- "description": "structure a JSON format message",
- "processors": [
- {
- "json": {
- "field": "message",
- "target_field": "json_fields"
- }
- }
- ]
- }
在上面,我们创建了一个叫做 message_structure 的 ingest pipeline。
我们接下来展示如何在 custom logs 里来使用这个 ingest pipeline。我们重新打开 log-1 集成:


如上所示,我们在 Custom congfiguration 里填写 pipeline 的定义。点击上面的 Save integration:
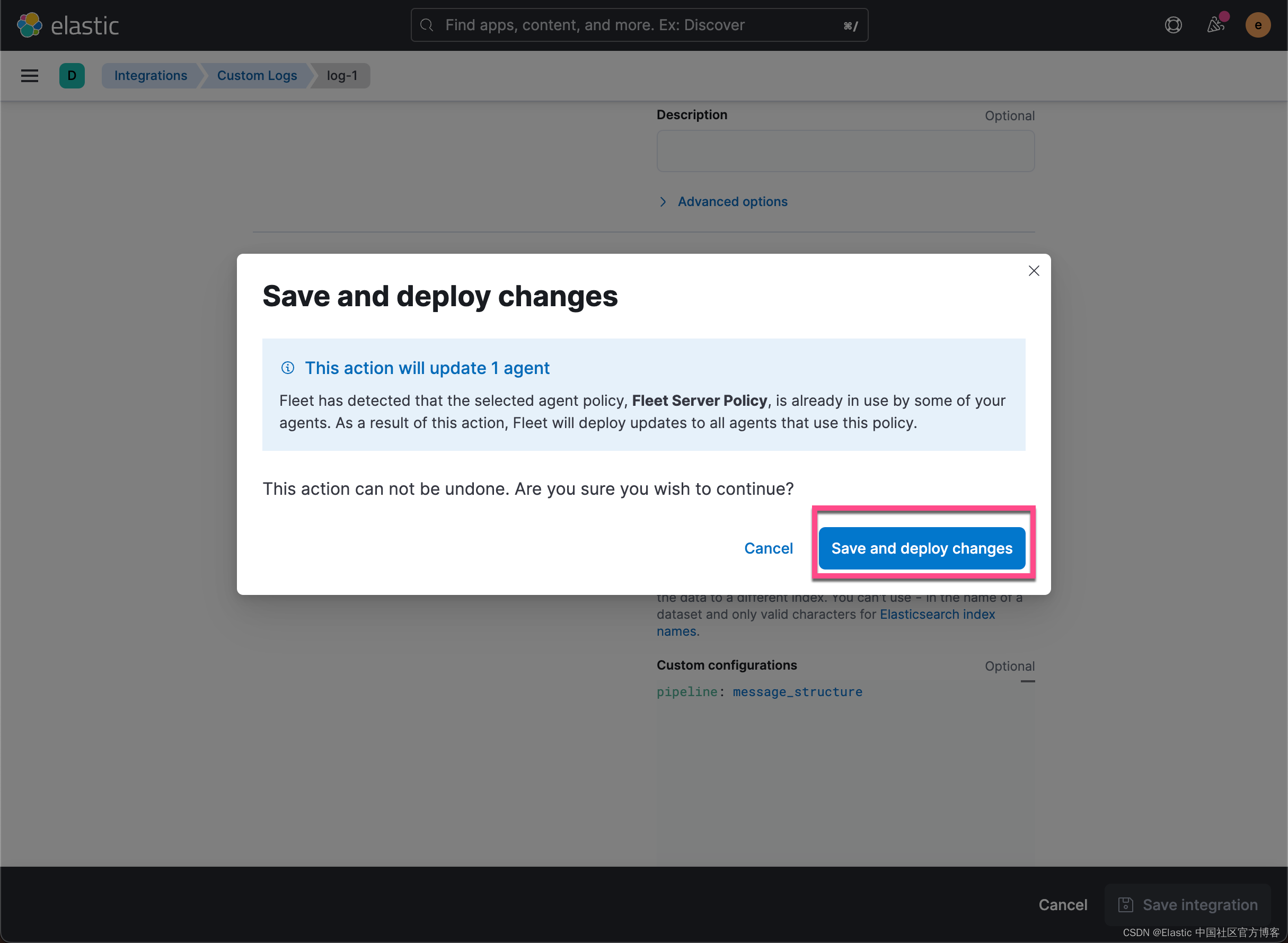

上面显示,我们的更新完毕。
我们接下来再次删除在日志目录下的 json_logs 文件,并再次运行 python 应用:
- liuxg@liuxgu:~/python/logs$ pwd
- /home/liuxg/python/logs
- liuxg@liuxgu:~/python/logs$ ls
- createlogs.py createlogs_1.py createlogs_2.py filebeat_json.yml json_logs test.log
- liuxg@liuxgu:~/python/logs$ rm json_logs
- liuxg@liuxgu:~/python/logs$ python createlogs_2.py
我们再次回到 Discover 界面来进行查看:
我们可以看到最新的日志信息被收集起来了。我们展开该文档进行查看:

我们可以看到 message 的信息被结构化了,并且保存于一个叫做 json_fields 的字段中。
好了,今天我的分享就写到这里。希望对大家从 Beats 转换到 Elastic Agents 的使用提供一个平滑的过度。在未来,Elastic 更推崇 Elastic Agents 的使用虽然之前的 Beats 方式还可以继续使用。使用 Elastic Agents 可以使我们的 Agents 更容易集中管理。
-
相关阅读:
SpringBoot实现SSMP整合
后端跨域解决方案
计算机毕业设计(附源码)python职业高中智慧教学系统
http和https的区别
AI推介-大语言模型LLMs论文速览(arXiv方向):2024.03.10-2024.03.15
广东有哪些媒体邀约资源-电视台央媒网媒
Google Earth Engine(GEE)——
一些性能优化的东西
什么?MySQL 8.0 会同时修改两个ib_logfilesN 文件?
List类的超详细解析!(超2w+字)
- 原文地址:https://blog.csdn.net/UbuntuTouch/article/details/125536634
