-
使用spark-submit工具提交Spark作业
原创申明: 未经许可,禁止以任何形式转载,若要引用,请标注链接地址
全文共计2584字,阅读大概需要3分钟
欢迎关注我的个人公众号:不懂开发的程序猿1. 实验室名称:
大数据实验教学系统
2. 实验项目名称:
使用spark-submit工具提交Spark作业
3. 实验学时:
4. 实验原理:
对于数据的批处理,通常采用编写程序、打.jar包提交给集群来执行,这需要使用Spark自带的spark-submit工具。
一般的部署策略是在一个网关机器上提交应用程序,这个机器和Worker机器部署在一个网络中(例如,Standalone模式的集群中的Master节点)。在此部署策略中,client模式更为合适,client模式中的driver直接跟spark-submit进程一起启动,spark-submit进程在此扮演集群中一个client的角色。应用程序的输入输出依赖于控制台,如此一来,这种模式就特别适合关于REPL(例如,Spark shell)的应用程序。
另一种部署策略是,应用程序通过一台远离Worker节点的机器提交(例如,本地或者便携设备),这种情况下,一般使用cluster模式最小化drivers和executors之间的网络延时。注意,cluster模式暂时不支持于Mesos集群或Python应用程序。5. 实验目的:
掌握spark-submit工具的使用。
了解spark-submit的主要参数设置。6. 实验内容:
1、使用spark-submit工具提交Spark自带的样例程序SparkPi程序,计算pi值。
7. 实验器材(设备、虚拟机名称):
硬件:x86_64 ubuntu 16.04服务器
软件:JDK1.8,Spark-2.3.2
在本实验环境中,Spark安装包位于以下位置:/data/software/spark-2.3.2-bin-hadoop2.7.tgz
在本实验环境中,JDK已安装在以下位置:/opt/jdk
在本实验环境中,Hadoop已安装在以下位置:/opt/hadoop器8. 实验步骤:
8.1 了解spark-submit指令的各种参数说明
1、在Linux环境下,可通过”spark-submit —help”命令来了解spark-submit指令的各种参数说明。
在终端窗口下,执行如下的命令,来查看spark-submit的帮助信息:1. $ spark-submit --help- 1
2、spark-submit语法如下:
1. spark-submit [options] <app jar | python file> [app options]- 1
其中options的主要标志参数说明如下:
项目 Value • —master 指定要连接到的集群管理器 • —deploy-mode 是否要在本地(“client”)启动驱动程序,或者在集群中(“cluster”)的一台worker机器上。在client模式下,spark-submit将在spark-submit被调用的机器上运行驱动程序。在cluster模式下,驱动程序会被发送到集群的一个worker节点上去执行。默认是client模式 • —class 应用程序的主类(带有main方法的类),如果运行Java或Scala程序 • —name 应用程序易读的名称,这将显示在Spark的web UI上 • —jars 一系列jar文件的列表,会被上传并设置到应用程序的classpath上。如果你的应用程序依赖于少量的第三方JAR包,可以将它们加到这里(逗号分隔) • —files 一系列文件的列表,会被到应用程序的工作目录。这个标志参数可被用于想要分布到每个节点上的数据文件 • —py-files 一系列文件的列表,会被添加到应用程序的PYTHONPATH。这可以包括.py、.egg或.zip文件 • —executor-memory executor使用的内存数量,以字节为单位。可以指定不同的后缀如”512m”或”15g” • —driver-memory driver进程所使用的内存数量,以字节为单位。可以指定不同的后缀如”512m”或”15g” 8.2 提交SparkPi程序到Spark集群,计算pi值
请按以下步骤操作。
1、启动Spark集群(standalone)模式。打开终端窗口,执行以下命令:1. $ cd /opt/spark 2. $ ./sbin/start-all.sh- 1
- 2
2、在终端窗口中,执行以下命令,提交SparkPi程序到Spark集群上执行:(注意,执行时请把下面命令中的主机名localhost替换为虚拟机实际的主机名):
1. $ ./bin/spark-submit --master spark://localhost:7077 --class org.apache.spark.examples.SparkPi examples/jars/spark-examples_2.11-2.3.2.jar- 1
参数说明:
• —master参数指定要连接的集群管理器,这里是standalone模式
• —calss参数指定要执行的主类名称(带包名的全限定名称)
• 最后一个参数是所提交的.jar包
3、查看执行结果。如下图所示:
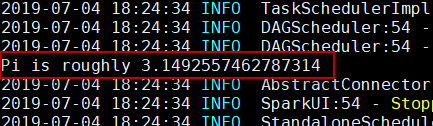
因为有许多输出信息,所以请仔细从中查看执行的计算结果。
9. 实验结果及分析:
实验结果运行准确,无误
10. 实验结论:
经过本节实验的学习,通过学习使用spark-submit工具提交Spark作业,进一步巩固了我们的Spark基础。
11. 总结及心得体会:
对于数据的批处理,通常采用编写程序、打.jar包提交给集群来执行,这需要使用Spark自带的spark-submit工具。

-
相关阅读:
很多人不买特斯拉的原因
透视虎牙斗鱼三季报:游戏直播在各自“求变”中见分晓
pinia 模块划分
数据建模 - 概念模型,逻辑模型,物理模型 的区别以及建模方式
React18入门(第二篇)——React18+Ts项目配置husky、eslint、pretttier、commitLint
专为实现最高性能和效率而设计,SQN3242UCKGTA、SQN3220SC、SQN3220 LTE-A Cat 6 模块【SKY85735-11射频前端】
【Flutter】Flutter 中 sqflite 的基本使用
在 Python 中计算两个 GPS 点之间的距离
CSS 3之 CSS 滤镜
探花交友_第2章-完善个人信息与MongoDB入门
- 原文地址:https://blog.csdn.net/qq_44807756/article/details/125551949