-
GoWEB应用性能优化方法与套路
了解存储设备的读写速度
在了解性能优化之前,我们先来了解一下时间单位的换算
1,000 皮秒 = 1纳秒 ns1,000,000 皮秒 = 1微秒 μs1,000,000,000 皮秒 = 1毫秒 ms1,000,000,000,000 皮秒 = 1秒 s
从上图我们可以大概知道高速缓存、主存、SSD硬盘、还有硬盘的读写速度时间参考值和量级
L1 cache reference是 1ns
L2 cache reference是 4ns
Main memory reference是100ns
SSD random readreference是16000ns ≈ 16
μsDisk seek reference是2000000ns≈ 2 ms从上面五个数据来看,我们就能大概知道各种储设备的读写速度以及它们之间的量级之差
优化思路
首先,我们优化怎么先从大头开始优化,这样我们才能获得最大收益
本篇文章的性能优化是指在应用层面逻辑代码优化、标准库、Go runtime的优化
大多数优化集中在应用代码,极少部分优化在标准库和runtime
我们来看一张图
在100ms的情况下,各框架的延迟几乎是持平的,所以在WEB应用层方面,框架对应用性能的影响是微乎其微的
The first test case is to mock 0 ms, 10 ms, 100 ms, 500 ms processing time in handlers.

GitHub - smallnest/go-web-framework-benchmark: Go web framework benchmark

如上图所示,我们把一个Go应用程序,做上述的拆分
第一层的优化的收益通常是最高的,是优化我们的逻辑代码优化
其次是内存使用优化、CPU使用优化和阻塞优化
最后是GC优化、标准库优化、runtime优化
发现问题
首先,我们得知道我们的应用程序可能会在哪里出问题,因此我们要对对程序进行压测
- API压测--对单个api接口进行压测
- 全链路压测--从用户视角进行压测,一个页面通常会对应多个api接口
我们压测要关注的指标
- Request rate--每秒请求数
- Error--请求失败数
- Duration--请求完成时间
- Goroutine数,线程数
- GC频率,gctrace的内容,GC的stw时间
进pprof寻找可能的故障原因,按照不同的情况,选择不同的方案优化
pprof线上也要开启着
压测工具
通常情况下,我们使用以下其中一个工具就可以压测我们的http程序
GitHub - giltene/wrk2: A constant throughput, correct latency recording variant of wrk
GitHub - wg/wrk: Modern HTTP benchmarking tool
GitHub - rakyll/hey: HTTP load generator, ApacheBench (ab) replacement
在公司内的真实环境,我们可以考虑内部压测平台或者第三方压测平台,比如说阿里云
进行全链路压测
分析问题套路
1.排除外部问题
首先在分析问题的过程中,我们要排除掉程序的外部问题,比如依赖的上游服务延迟过高,比如DB、redis、MQ
2.CPU占用过高
看CPU profile,优化占用CPU较多的部分逻辑
3.内存占用过高
首先看内存RSS是多少,gouroutine多少,gouroutine栈占用多少
其次,如果goroutine不多,那么重点关注heap profile中的inuse
最后,定时任务类需要看alloc
4.goroutine数量过多
从profile网页进去看看goroutine都在干什么,查死锁、阻塞等问题
常见的优化办法
CPU使用过高优化
1.应用逻辑导致
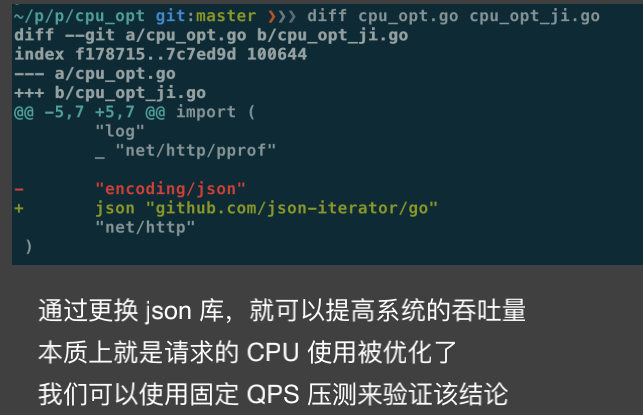
2.GC使用CPU过高

- 调度相关的函数使用CPU过高
- 控制最大goroutine数量
内存使用过高优化
1.goroutine数量过多
使用Goroutine pool限制goroutine的数量,比较推荐的有
2.堆内存占用内存空间过高
- 为不同大小的对象提供不同大小level的sync.Pool
阻塞问题
1.上游系统阻塞
赶紧让上游系统解决!
2.锁阻塞
- 减少临界区范围
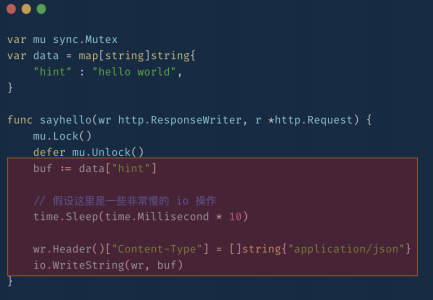

- 降低锁粒度
- 同步改异步
- 日志场景:同步日志->异步日志
Reference1.Numbers Every Programmer Should Know By Year2.GitHub - smallnest/go-web-framework-benchmark: Go web framework benchmark
-
相关阅读:
glide set gif start stop
【信息融合】基于BP神经网络和DS 证据理论实现不确定性信息融合问题附matlab代码
C#开发的PhotoNet看图软件 - 开源研究系列文章 - 个人小作品
Python:实现字符串split函数功能算法(附完整源码)
【Pytorch实用教程】nn.LogSoftmax的详细用法及公式
Dynamsoft Barcode Reader新框架将医疗视觉提升到新水平
常见数字 | 资料分析
CSDN 成为开放原子开源基金会黄金捐赠人,共建中国十万亿技术大生态
openstack 业务组件安装
API阶段测试
- 原文地址:https://blog.csdn.net/qq_37186127/article/details/125533382