-
ZooKeeper 8:请求处理逻辑与源码分析
prev:ZooKeeper 7:数据读写——原子广播协议ZAB
责任链模式
当客户端需要和 ZooKeeper 服务端进行相互协调通信时,首先要建立该客户端与服务端的连接会话,在会话成功创建后,ZooKeeper 服务端就可以接收来自客户端的请求操作了。
ZooKeeper集群在收到事务性会话请求后,主要依次进行四个部分的处理逻辑:预处理阶段、事务处理阶段、事务执行阶段、响应客户端。这种处理就像流水线一样,也是责任链模式的一种实现。
leader、follower、observer的责任链显然也是不同的。预处理阶段
在预处理阶段,主要是分辨要处理的请求是否是事务性请求,比如创建节点、更新数据、删除节点、创建会话等,这些请求操作都是事务性请求,在执行成功后会对服务器上的数据造成影响。
预处理的相关逻辑是在PrepRequestProcessor类下。PrepRequestProcessor类里面Override了run()函数,起了一个线程,来从submittedRequests里面不停的获取request,submittedRequests是一个LinkedBlockingQueue<Request>类型的阻塞队列:/** * 版本:ZooKeeper 3.8.0 * org.apache.zookeeper.server * PrepRequestProcessor.java * 137行 */ @Override public void run() { LOG.info(String.format("PrepRequestProcessor (sid:%d) started, reconfigEnabled=%s", zks.getServerId(), zks.reconfigEnabled)); try { while (true) { ServerMetrics.getMetrics().PREP_PROCESSOR_QUEUE_SIZE.add(submittedRequests.size()); Request request = submittedRequests.take(); ServerMetrics.getMetrics().PREP_PROCESSOR_QUEUE_TIME .add(Time.currentElapsedTime() - request.prepQueueStartTime); if (LOG.isTraceEnabled()) { long traceMask = ZooTrace.CLIENT_REQUEST_TRACE_MASK; if (request.type == OpCode.ping) { traceMask = ZooTrace.CLIENT_PING_TRACE_MASK; } ZooTrace.logRequest(LOG, traceMask, 'P', request, ""); } if (Request.requestOfDeath == request) { break; } request.prepStartTime = Time.currentElapsedTime(); pRequest(request); } } catch (Exception e) { handleException(this.getName(), e); } LOG.info("PrepRequestProcessor exited loop!"); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
这里调用了pRequest(request)函数来处理请求。pRequest()判断客户端发送的会话请求类型,并执行相应逻辑:
/** * 版本:ZooKeeper 3.8.0 * org.apache.zookeeper.server * PrepRequestProcessor.java * 772行 */ protected void pRequest(Request request) throws RequestProcessorException { // LOG.info("Prep>>> cxid = " + request.cxid + " type = " + // request.type + " id = 0x" + Long.toHexString(request.sessionId)); request.setHdr(null); request.setTxn(null); if (!request.isThrottled()) { pRequestHelper(request); } request.zxid = zks.getZxid(); long timeFinishedPrepare = Time.currentElapsedTime(); ServerMetrics.getMetrics().PREP_PROCESS_TIME.add(timeFinishedPrepare - request.prepStartTime); nextProcessor.processRequest(request); ServerMetrics.getMetrics().PROPOSAL_PROCESS_TIME.add(Time.currentElapsedTime() - timeFinishedPrepare); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
这里的pRequestHelper()函数是一个大switch-case,来很对不同的请求执行不同的处理,例如create请求,会执行pRequest2Txn()的逻辑:
/** * 版本:ZooKeeper 3.8.0 * org.apache.zookeeper.server * PrepRequestProcessor.java * 794行 */ private void pRequestHelper(Request request) throws RequestProcessorException { try { switch (request.type) { case OpCode.createContainer: case OpCode.create: case OpCode.create2: CreateRequest create2Request = new CreateRequest(); pRequest2Txn(request.type, zks.getNextZxid(), request, create2Request, true); break; case OpCode.createTTL: //... //case... }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
在pRequest2Txn(),主要是执行预处理阶段的主要逻辑,这里举一个比较短的例子setData请求:
/** * 版本:ZooKeeper 3.8.0 * org.apache.zookeeper.server * PrepRequestProcessor.java * 320行 */ protected void pRequest2Txn(int type, long zxid, Request request, Record record, boolean deserialize) throws KeeperException, IOException, RequestProcessorException { switch (type) { case OpCode.setData: // 检查会话是否还有效 zks.sessionTracker.checkSession(request.sessionId, request.getOwner()); SetDataRequest setDataRequest = (SetDataRequest) record; if (deserialize) { ByteBufferInputStream.byteBuffer2Record(request.request, setDataRequest); } // 请求的路径 path = setDataRequest.getPath(); validatePath(path, request.sessionId); // 现有数据 nodeRecord = getRecordForPath(path); // 检查ACL是否有操作权限 zks.checkACL(request.cnxn, nodeRecord.acl, ZooDefs.Perms.WRITE, request.authInfo, path, null); // 检查Quota是否达量 zks.checkQuota(path, nodeRecord.data, setDataRequest.getData(), OpCode.setData); int newVersion = checkAndIncVersion(nodeRecord.stat.getVersion(), setDataRequest.getVersion(), path); // 加入处理链路 request.setTxn(new SetDataTxn(path, setDataRequest.getData(), newVersion)); nodeRecord = nodeRecord.duplicate(request.getHdr().getZxid()); nodeRecord.stat.setVersion(newVersion); nodeRecord.stat.setMtime(request.getHdr().getTime()); nodeRecord.stat.setMzxid(zxid); nodeRecord.data = setDataRequest.getData(); nodeRecord.precalculatedDigest = precalculateDigest( DigestOpCode.UPDATE, path, nodeRecord.data, nodeRecord.stat); setTxnDigest(request, nodeRecord.precalculatedDigest); addChangeRecord(nodeRecord); break; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
处理后,会回到pRequest()中,将request交给下一个处理器nextProcessor:ProposalRequestProcessor(集群模式下)。
事物处理器
ProposalRequestProcessor是继PrepRequestProcessor后,责任链模式上的第二个处理器。
实现类是ProposalRequestProcessor,在ProposalRequestProcessor处理器阶段,其内部又分成了三个子流程,分别是:Sync流程、Proposal流程、Commit流程。需要首先解释:observer和follower都被称为为learner:
This class is the superclass of two of the three main actors in a ZK ensemble: Followers and Observers.
ProposalRequestProcessor的从处理主要在initialize()方法和processRequest()方法中。
SyncRequestProcessor和AckRequestProcessor链
SyncRequestProcessor
在ProposalRequestProcessor中,initialize()方法中起了一个syncProcessor的线程:
/** * 版本:ZooKeeper 3.8.0 * org.apache.zookeeper.server.quorum * ProposalRequestProcessor.java * 64行 */ public void initialize() { syncProcessor.start(); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
在这个类型为SyncRequestProcessor的线程中,主要处理的是将请求持久化到磁盘中:
/** * 版本:ZooKeeper 3.8.0 * org.apache.zookeeper.server * SyncRequestProcessor.java * 156行 */ @Override public void run() { //... while (true) { // ... // 不断从queuedRequests中获取request Request si = queuedRequests.poll(pollTime, TimeUnit.MILLISECONDS); // ... if (!si.isThrottled() && zks.getZKDatabase().append(si)) { //... new ZooKeeperThread("Snapshot Thread") { public void run() { try { // 数据落盘 zks.takeSnapshot(); } catch (Exception e) { LOG.warn("Unexpected exception", e); } finally { snapThreadMutex.release(); } } }.start(); //... } else if (toFlush.isEmpty()) { //... // optimization for read heavy workloads // iff this is a read or a throttled request(which doesn't need to be written to the disk), // and there are no pending flushes (writes), then just pass this to the next processor if (nextProcessor != null) { // 交给下一个processor:AckRequestProcessor nextProcessor.processRequest(si); if (nextProcessor instanceof Flushable) { ((Flushable) nextProcessor).flush(); } } continue; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
在这里,将request交给了下一个AckRequestProcessor。
AckRequestProcessor
AckRequestProcessor实现的功能是:在同意Leader的Proposal之后,给Leader回复一个ACK:
/** * 版本:ZooKeeper 3.8.0 * org.apache.zookeeper.server.quorm * AckRequestProcessor.java * 43行 */ public void processRequest(Request request) { QuorumPeer self = leader.self; if (self != null) { request.logLatency(ServerMetrics.getMetrics().PROPOSAL_ACK_CREATION_LATENCY); leader.processAck(self.getId(), request.zxid, null); } else { LOG.error("Null QuorumPeer"); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
ProposalRequestProcessor、CommitProcessor链
ProposalRequestProcessor
在之前的预处理器中,调用了nextProcesser.processRequest(),将请求交给了ProposalRequestProcessor:
/** * 版本:ZooKeeper 3.8.0 * org.apache.zookeeper.server.quorum * ProposalRequestProcessor.java * 68行 */ public void processRequest(Request request) throws RequestProcessorException { /* In the following IF-THEN-ELSE block, we process syncs on the leader. * If the sync is coming from a follower, then the follower * handler adds it to syncHandler. Otherwise, if it is a client of * the leader that issued the sync command, then syncHandler won't * contain the handler. In this case, we add it to syncHandler, and * call processRequest on the next processor. */ // 如果请求是LearnerSyncRequest类型,也就是请求是来自于follower和observer的转发 if (request instanceof LearnerSyncRequest) { // 向Follower发送这个request zks.getLeader().processSync((LearnerSyncRequest) request); // 如果请求来自leader的客户端 } else { if (shouldForwardToNextProcessor(request)) { // 发给下一个处理器:CommitProcessor nextProcessor.processRequest(request); } if (request.getHdr() != null) { // We need to sync and get consensus on any transactions try { zks.getLeader().propose(request); } catch (XidRolloverException e) { throw new RequestProcessorException(e.getMessage(), e); } syncProcessor.processRequest(request); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
CommitProcessor
CommitProcessor用于将来到的commit request和本地已提交的request进行对比。
CommitProcessor是一个多线程的,线程之间使用队列、automatic、wait/notifyAll进行通信和协同。
CommitProcessor相当于一个gateway,决定是否继续当前的流水线操作。同一时刻可以有多个读请求和一个写请求被放通。
首先在processRequest()中,将request加入队列:/** * 版本:ZooKeeper 3.8.0 * org.apache.zookeeper.server.quorum * CommitProcessor.java * 603行 */ @Override public void processRequest(Request request) { if (stopped) { return; } LOG.debug("Processing request:: {}", request); request.commitProcQueueStartTime = Time.currentElapsedTime(); queuedRequests.add(request); // If the request will block, add it to the queue of blocking requests if (needCommit(request)) { queuedWriteRequests.add(request); numWriteQueuedRequests.incrementAndGet(); } else { numReadQueuedRequests.incrementAndGet(); } wakeup(); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
在线程中,不断从队列中取得request,对其进行处理,相关代码在org.apache.zookeeper.server.quorum.CommitProcessor.java 196-421行,代码就不放了,大致逻辑是:
- 主线程:主要是进行线程分发,主要逻辑为不停获取request队列的request,并根据sessionId分发到子线程上,同一个SessionId会被分发到同一个工作线程上;
- 工作线程:CommitWorkRequest类(继承自WorkerService.WorkRequest),核心是ArrayList<ExecutorService>,将request发到下一个processor(如果是leader,会送到Leader.ToBeAppliedRequestProcessor,follower和observer会送到FinalRequestProcessor)
最终处理器
Leader.ToBeAppliedRequestProcessor和FinalRequestProcessor链
Leader.ToBeAppliedRequestProcessor
ToBeAppliedRequestProcessor主要是维护toBeApplied列表,下一个处理器是FinalRequestProcessor。只要Leader会执行这个processor。
处理逻辑非常简单:/** * 版本:ZooKeeper 3.8.0 * org.apache.zookeeper.server.quorum * Leader.java * 1100行 */ public void processRequest(Request request) throws RequestProcessorException { next.processRequest(request); // The only requests that should be on toBeApplied are write // requests, for which we will have a hdr. We can't simply use // request.zxid here because that is set on read requests to equal // the zxid of the last write op. if (request.getHdr() != null) { long zxid = request.getHdr().getZxid(); Iterator<Proposal> iter = leader.toBeApplied.iterator(); if (iter.hasNext()) { Proposal p = iter.next(); if (p.request != null && p.request.zxid == zxid) { iter.remove(); return; } } LOG.error("Committed request not found on toBeApplied: {}", request); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
可以看出,只有写请求才会触发对toBeApplied列表的维护,toBeApplied
的数据结构是ConcurrentLinkedQueue<Proposal>FinalRequestProcessor
FinalRequestProcessor是最后一个处理器(It is always at the end of a RequestProcessor chain)。
FinalRequestProcessor处理器:- 检查outstandingChanges队列中请求的有效性,若发现这些请求已经落后于当前正在处理的请求,那么直接从outstandingChanges队列中移除
- 将事务实际提交。之前之前的请求处理仅仅将事务请求记录到了事务日志中,而内存数据库中的状态尚未改变,因此,需要将事务变更应用到内存数据库
- 回复客户端
主要逻辑代码主要在org.apache.zookeeper.server.FinalRequestProcessor.java 的147-643行
不同角色的请求链
在上面可以看出,很显然,集群中的leader、follower、observer都会有自己的请求链来执行不同的处理逻辑。单机模式的ZooKeeper也会有自己单独的请求链。
在不同的Server中的setupRequestProcessors()方法来定义好自己的请求链Leader的请求链
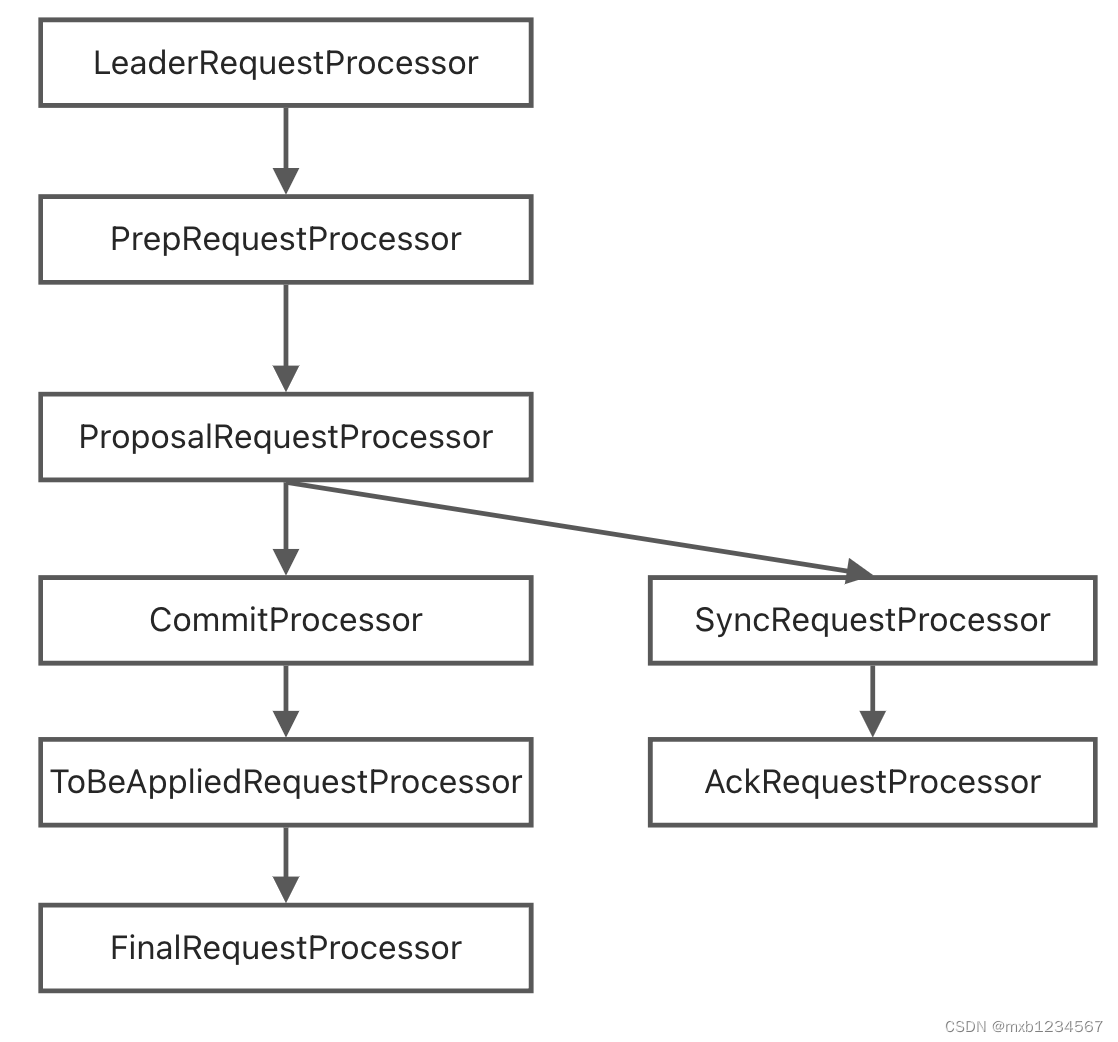
Leader的请求链在LeaderZooKeeperServer中定义:
/** * 版本:ZooKeeper 3.8.0 * org.apache.zookeeper.server.quorum * LeaderZooKeeperServer.java * 65行 */ @Override protected void setupRequestProcessors() { RequestProcessor finalProcessor = new FinalRequestProcessor(this); RequestProcessor toBeAppliedProcessor = new Leader.ToBeAppliedRequestProcessor(finalProcessor, getLeader()); commitProcessor = new CommitProcessor(toBeAppliedProcessor, Long.toString(getServerId()), false, getZooKeeperServerListener()); commitProcessor.start(); ProposalRequestProcessor proposalProcessor = new ProposalRequestProcessor(this, commitProcessor); proposalProcessor.initialize(); prepRequestProcessor = new PrepRequestProcessor(this, proposalProcessor); prepRequestProcessor.start(); firstProcessor = new LeaderRequestProcessor(this, prepRequestProcessor); setupContainerManager(); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
这里的LeaderRequestProcessor主要是处理直接连接在leader上的客户端的请求。
Follower的请求链
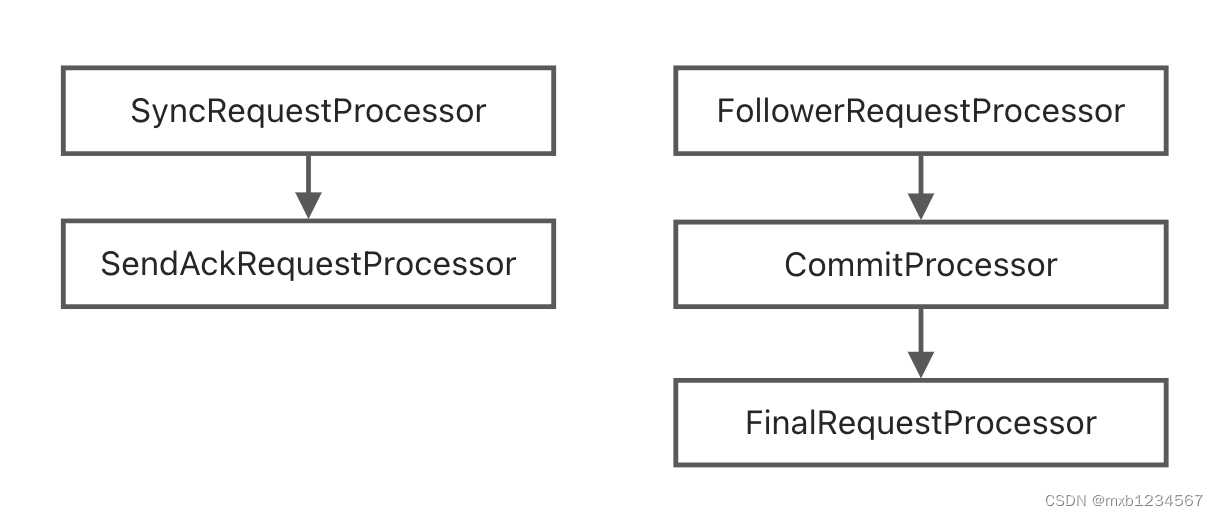
Follower的请求链在FollowerZooKeeperServer中定义:
/** * 版本:ZooKeeper 3.8.0 * org.apache.zookeeper.server.quorum * FollowerZooKeeperServer.java * 69行 */ @Override protected void setupRequestProcessors() { RequestProcessor finalProcessor = new FinalRequestProcessor(this); commitProcessor = new CommitProcessor(finalProcessor, Long.toString(getServerId()), true, getZooKeeperServerListener()); commitProcessor.start(); firstProcessor = new FollowerRequestProcessor(this, commitProcessor); ((FollowerRequestProcessor) firstProcessor).start(); syncProcessor = new SyncRequestProcessor(this, new SendAckRequestProcessor(getFollower())); syncProcessor.start(); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
Observer的请求链
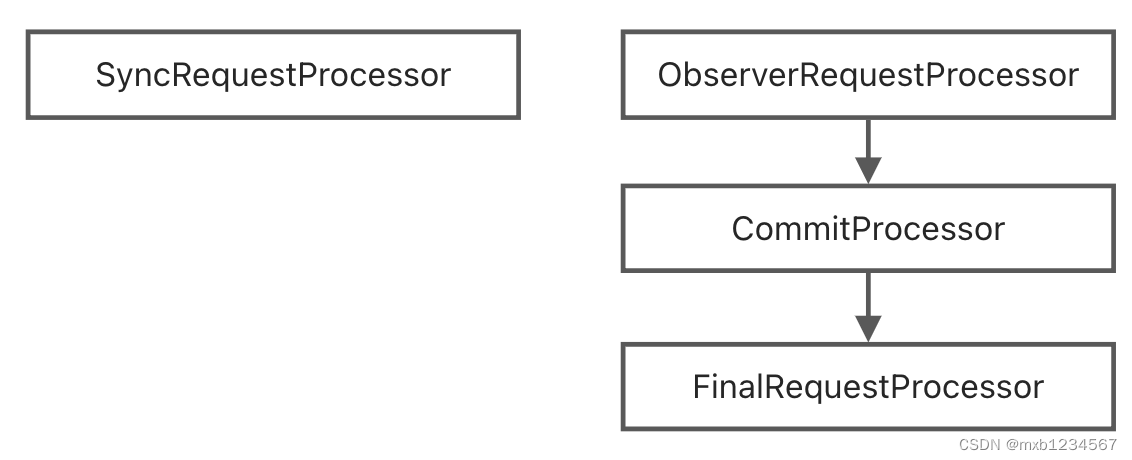
Observer的请求链定义在ObserverZooKeeperServer
/** * 版本:ZooKeeper 3.8.0 * org.apache.zookeeper.server.quorum * ObserverZooKeeperServer.java * 87行 */ @Override protected void setupRequestProcessors() { // We might consider changing the processor behaviour of // Observers to, for example, remove the disk sync requirements. // Currently, they behave almost exactly the same as followers. RequestProcessor finalProcessor = new FinalRequestProcessor(this); commitProcessor = new CommitProcessor(finalProcessor, Long.toString(getServerId()), true, getZooKeeperServerListener()); commitProcessor.start(); firstProcessor = new ObserverRequestProcessor(this, commitProcessor); ((ObserverRequestProcessor) firstProcessor).start(); /* * Observer should write to disk, so that the it won't request * too old txn from the leader which may lead to getting an entire * snapshot. * * However, this may degrade performance as it has to write to disk * and do periodic snapshot which may double the memory requirements */ if (syncRequestProcessorEnabled) { syncProcessor = new SyncRequestProcessor(this, null); syncProcessor.start(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
这里的FollowerRequestProcessor主要逻辑是将request提交给leader。
单机模式请求链
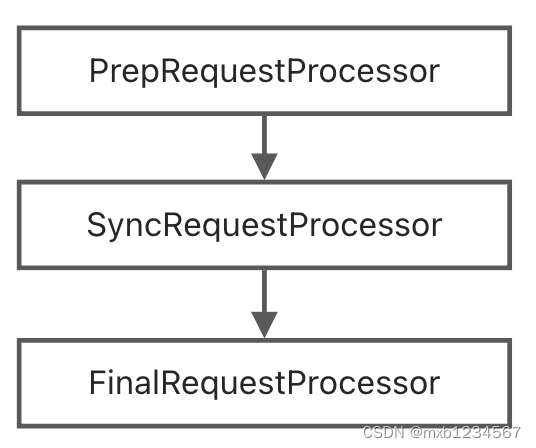
单机模式请求链比较简单,定义在org.apache.zookeeper.server.ZooKeeperServer.java
/** * 版本:ZooKeeper 3.8.0 * org.apache.zookeeper.server * ZooKeeperServer.java * 746行 */ protected void setupRequestProcessors() { RequestProcessor finalProcessor = new FinalRequestProcessor(this); RequestProcessor syncProcessor = new SyncRequestProcessor(this, finalProcessor); ((SyncRequestProcessor) syncProcessor).start(); firstProcessor = new PrepRequestProcessor(this, syncProcessor); ((PrepRequestProcessor) firstProcessor).start(); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
参考
ZooKeeper源码解析(9)-几种RequestProcessor
Zookeeper系列(二十四)Zookeeper原理解析之处理流程
Zookeeper(4) - 会话管理和事务处理
12 服务端是如何处理一次会话请求的? -
相关阅读:
[CISCN 2019初赛]Love Math - RCE(异或绕过)
Ubuntu服务器安全性提升:修改SSH默认端口号
现代面试中的乱象
Vue快速入门
【数据结构】队列(C语言实现)
【C++】贪心算法
【Docker】Compose容器编排:微服务实战
【Maven】SpringBoot多模块项目利用reversion占位符,进行版本管理.打包时版本号不能识别问题
企业有了BI,为什么还需要以指标为核心的ABI平台?
Mysql热备增量备份与恢复(-)--备份部分
- 原文地址:https://blog.csdn.net/mxb1234567/article/details/125526834
