-
目标检测——【Transformer】Accelerating DETR Convergence via Semantic-Aligned Matching
文章侧重点
想要解决的问题:
DEFR收敛速度太慢,如此高的训练成本【DERT在COCO训练集上要训练500个epoch才能收敛,相比之下Faster R-CNN只要12~36个epoch就可以收敛】是因为在匹配query与特征映射空间中的开销,也就是对应的交叉注意力(cross-attention)的计算过程。这个过程是将一个随机赋值的Object query训练成一个可以从特征中通过加权突出待检测目标的query,这个过程需要不断训练。
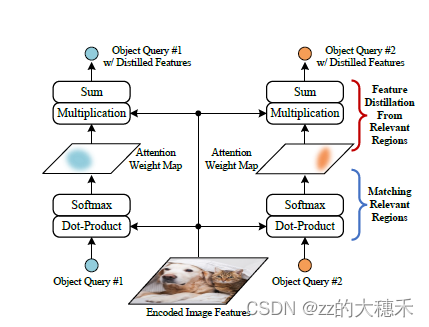
该过程如下图所示:
交叉注意机制的计算公式如下:
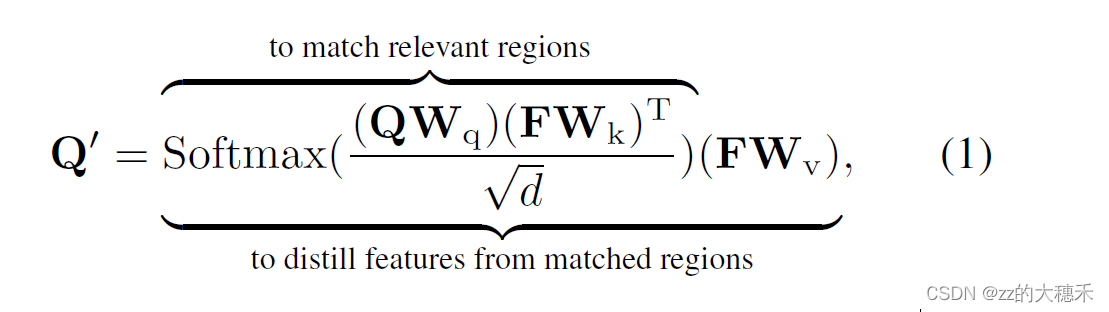
从实现效果的角度来看,交叉注意力的计算也可以解释为“匹配和特征蒸馏"的过程。 如公式所示,交叉注意力的实现包含了两部分含义:- 将Object query与Encoded Feature有关的区域进行匹配。相当于Object query与Encoded Feature进行全局计算相似度,找到感兴趣区域,因为是对Encoded特征的全局计算,所以这个操作非常耗时。 这一步计算完成之后,会得到上中的Attention Weight Map。可以看到图中某些区域得到了增强。
- 从匹配到的区域中再度提取特征。相当于对某些已经得到注意的区域进行再次强调,故得到Distilled Features。
基于上述观察,本文提出了对这个匹配过程进行优化!
Sematic-Aligned-Matching DERT
本文提出的语义对齐匹配方法,简称为SAM-DERT。旨在保持DERT的精度的同时,加速DERT。 所以首先文章开篇分析了当前DERT中的交叉注意力机制中存在的问题,并以此为突破口,设计了一个即插即用的头——SAM-DERT,嵌入交叉注意力模块中,为Object query与Encoded Feature有关的区域匹配之前,加入一个强有力的关于目标的先验信息,从而加速”匹配"过程。
网络结构
SAM-DERT
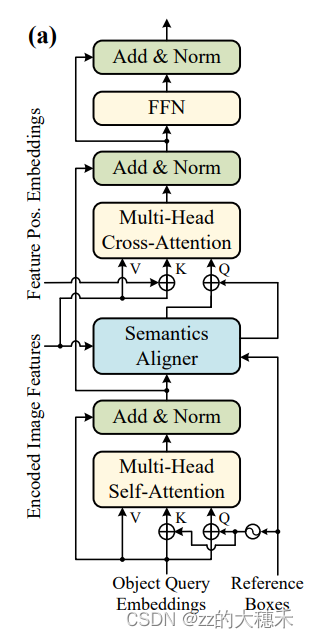
由上图可知,本文提出的这个即插即用的模块在DERT中的应用咋如图位置,在交叉注意力模块之前。Semantics Aligner
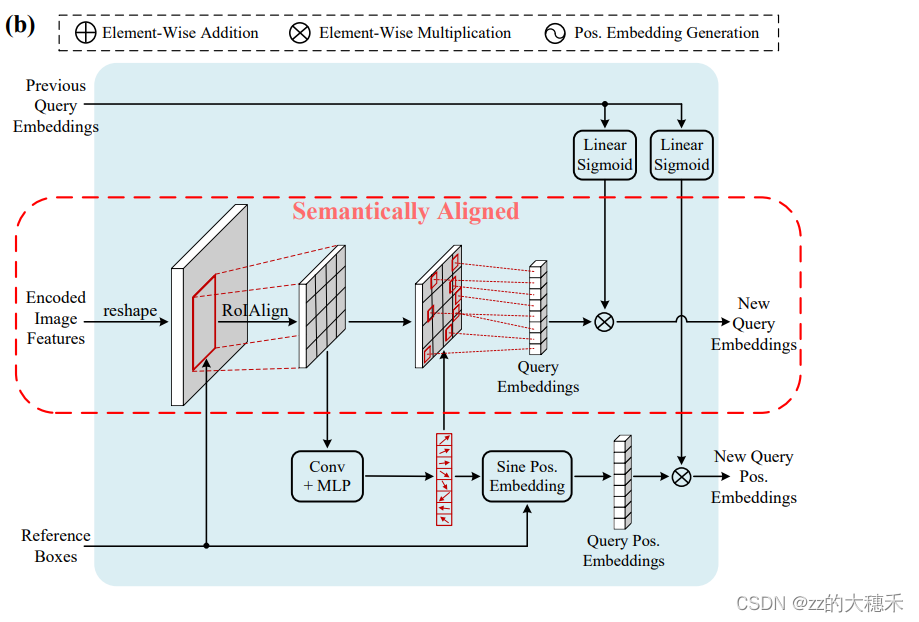
整个语义对齐模块的实现如上图。一共可以分为三个部分:语义对齐的匹配、显著点特征的匹配、信息损失的补偿。语义对齐的匹配
所谓“语义对齐”,就是将Object query和Encoded Feature映射到同一个Embedding空间。 原始DERT中在Object query的初始化阶段是将它随机映射到一个特征空间,所以在交叉注意力机制中就需要对Encoded Feature所有空间位置进行匹配。故现在的思路就是,一开始就给一些先验知识给Object query,使得Object query和Encoded Feature在相同的嵌入空间,以提升效率。
实现:

- 根据上图中的公式2,首先引入一个reference box向量 R b o x R_{box} Rbox,用于对Encoded Feature F F F作RoIAlign,生成区域级(region-level)的特征 F R F_R FR
- 通过一个显著点特征的匹配这一个重采样操作从 F R F_R FR生成Object query Q n e w Q^{new} Qnew、Object query pos Q p o s n e w Q^{new}_{pos} Qposnew 。
这一部分操作是为了给Object query一个强先验知识,使其的权重关注到语义相似区域中了。因为重采样操作中没有任何映射操作会影响嵌入空间(Embedding space),所以生成Object query Q n e w Q^{new} Qnew与Encoded Feature F F F是在同一嵌入空间。
显著点特征的匹配
其实这一部分完成的任务就是从区域级别特征 F R F_R FR中重采样出Object query的值。但是简单的average-pooling或max-pooling表达力不够。受到多头注意力机制的启发,它在DERT中扮演了不可或缺的角色,因为多头注意力机制中的多个head的作用就是关注图片特征的不同方面,因此增强模型的表达力。
实现:-
M
M
M表示注意力head数,一般设为8。对区域级别特征
F
R
F_R
FR,应用ConvNet、MLP输出每个区域的M个显著点坐标
R
S
P
R_{SP}
RSP。值得注意的是,我们将预测坐标限制在参考框内。
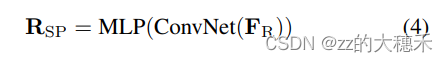
- 从区域级别特征
F
R
F_R
FR通过双线性插值生成显著点对应的特征,然后M个显著点就有M个对应特征,将这M个显著点对应的特征拼接起来,就是当前Object query的Embedding向量
Q
n
e
w
′
Q^{new'}
Qnew′。
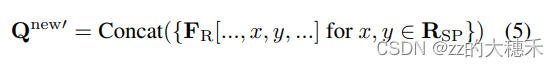
- Object query对应的位置编码
Q
p
o
s
n
e
w
′
Q_{pos}^{new'}
Qposnew′是由显著点对应图片的坐标和query的定位框组合进行sinusoidal函数。
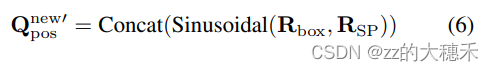
信息损失的补偿
到这一步,Semantics Aligner已经生成了新的与Encoded特征Object query。但是因为特征提取的过程是一个信息损失压缩的过程,所以这一步就用上一步传递来的query Q Q Q生成一个权重系数把自己再加进去,达到一个信息补偿的效果,说白了就是残差结构。
实现:
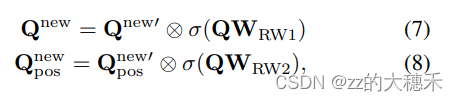
其中 W R W 1 W_{RW1} WRW1、 W R W 2 W_{RW2} WRW2分别表示线性映射的权重系数(可训练)。qq
-
相关阅读:
苹果推出iOS15.2正式版,“数字遗产”计划正式上线,你的“继承人”是谁?
基于Springboot+超市管理系统 毕业设计-附源码231443
给电脑重装系统后修改远程桌面端口的方法
34. 在排序数组中查找元素的第一个和最后一个位置
【TypeScript基础】TypeScript之常用类型(上)
旋转倒立摆的起摆与稳摆---QYC
神经网络ppt不足之处怎么写,神经网络ppt免费下载
前端教程-文档工具
2022年0705-Com.Java.Basis 第十五课 JDBC 简称CRUP
Android Studio新功能-设备镜像Device mirroring-在电脑侧显示手机实时画面并可控制
- 原文地址:https://blog.csdn.net/qq_42312574/article/details/127090059