-
spark完全分布式部署
原创申明: 未经许可,禁止以任何形式转载,若要引用,请标注链接地址
全文共计6214字,阅读大概需要3分钟
欢迎关注我的个人公众号:不懂开发的程序猿一、 任务描述
本实验任务主要完成基于ubuntu环境的Spark完全分布式部署、配置和调试工作。通过完成本实验任务,要求学生熟练掌握Spark完全分布式部署方法,为后续实验的开展奠定Spark平台基础,也为从事大数据平台运维工程师、大数据技术支持工程师等岗位工作奠定夯实的技能基础。
二、 任务目标
掌握Spark完全分布式环境的部署
三、 任务环境
本次环境是:Ubuntu16.04
四、 任务分析
spark有以下几种安装模式,每种安装模式都有自己不同的优点和长处。
local(本地模式):
常用于本地开发测试,本地还分为local单线程和local-cluster多线程;
standalone(集群模式):
典型的Mater/slave模式,Master可能有单点故障的;Spark支持ZooKeeper来实现 HA。
on yarn(集群模式):
运行在 yarn 资源管理器框架之上,由 yarn 负责资源管理,Spark 负责任务调度和计算。
on mesos(集群模式):
运行在 mesos 资源管理器框架之上,由 mesos 负责资源管理,Spark 负责任务调度和计算。
on cloud(集群模式):
比如 AWS 的 EC2,使用这个模式能很方便的访问 Amazon的 S3;Spark 支持多种分布式存储系统:HDFS 和 S3。
完全分布式与伪分布对应,伪分布是由于机器数量的限制而产生的,而完全分布式是生产模式下的正常模式,至少需要3台机器。♥ 知识链接
Spark On YARN模式
spark on yarn 的支持两种模式:- yarn-cluster:适用于生产环境;
- yarn-client:适用于交互、调试,希望立即看到app的输出
yarn-cluster和yarn-client的区别在于yarn appMaster,每个yarn app实例有一个appMaster进程,是为app启动的第一个container;负责从ResourceManager请求资源,获取到资源后,告诉NodeManager为其启动container。yarn-cluster和yarn-client模式内部实现还是有很大的区别。如果你需要用于生产环境,那么请选择yarn-cluster;而如果你仅仅是Debug程序,可以选择yarn-client。
五、 任务实施
步骤1、主机映射配置
由于在实际环境中每次生成的主机名都不一致,为了命名的规范和简洁,需要修改每台虚拟机的主机名。在ip为192.168.0.2的虚拟机终端输入命令【
vim /etc/hostname】,进入编辑页面输入“master”,编辑完成后保存退出。在终端输入命令【reboot】重启后,主机名就修改完成了。依次将其它两台虚拟机的主机名修改为slave1,slave2。如图1所示。
图1 修改主机名
修改每台电脑的hosts文件。hosts文件和windows上的功能是一样的。存储主机名和ip地址的映射。在每台linux上,【
vim /etc/hosts】 编写hosts文件。将主机名和ip地址的映射填写进去。编辑完后,结果如图2所示: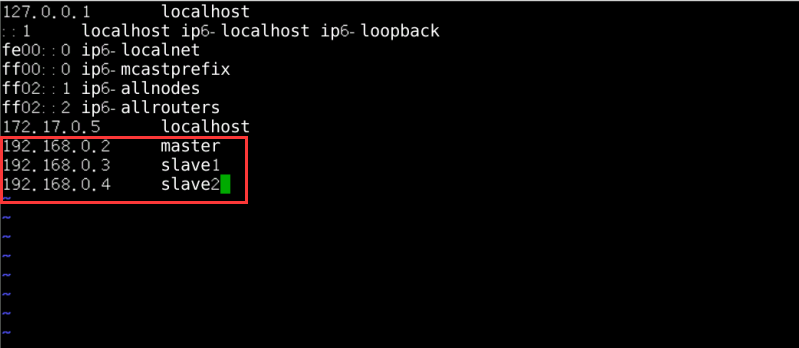
图2 编辑hosts文件
配置完映射之后,可以通过
ping命令进行测试是否能够连通,ping除了可以直接连接IP地址,也可以连接主机名,不过此时需要对配置文件hosts进行修改。“etc/hosts“文件是用来配置主机用的DNS服务器信息,是记载LAN内接各主机名称和IP地址,当用户在连接网络时,首先查找该文件,寻找对应的主机名和IP地址。这样就可以实现不同节点之间可以通过ip地址或主机名相互ping通。如图3所示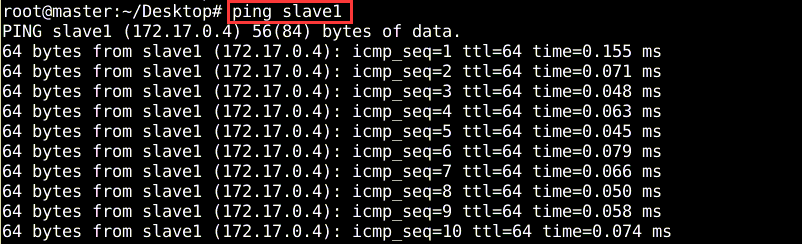
图3 测试机器之间的联通
完成以上操作即表示完成一个小的局域网络,为spark集群搭建准备好条件,由于每个节点之间需要相互配合,相互访问,为避免反复出现输入密码,此时需要对各个节点之间配置免密码配置。 无密码登陆,效果也就是在master上,通过
ssh master或ssh slave1或ssh slave2就可以登陆到对方计算机上。而且不用输入密码进入ssh目录。下面开始配置免密,进入.ssh目录并查看。如图4所示

图4 进入.ssh目录
使用命令【
ssh-keygen -t rsa】,一路按回车就行了。刚才都作甚了呢?主要是设置ssh的密钥和密钥的存放路径。 路径为~/.ssh下。
打开~/.ssh 下面有三个文件
(1)authorized_keys,已认证的keys
(2)id_rsa,私钥
(3)id_rsa.pub,公钥三个文件。
下面就是关键的地方了,(下面的操作为ssh认证。进行下面操作前,可以先搜关于认证和加密区别以及各自的过程。)在master上将公钥放到authorized_keys里。命令:【cat ~/.ssh/id_rsa.pub >>~/.ssh/authorized_keys】。如图5所示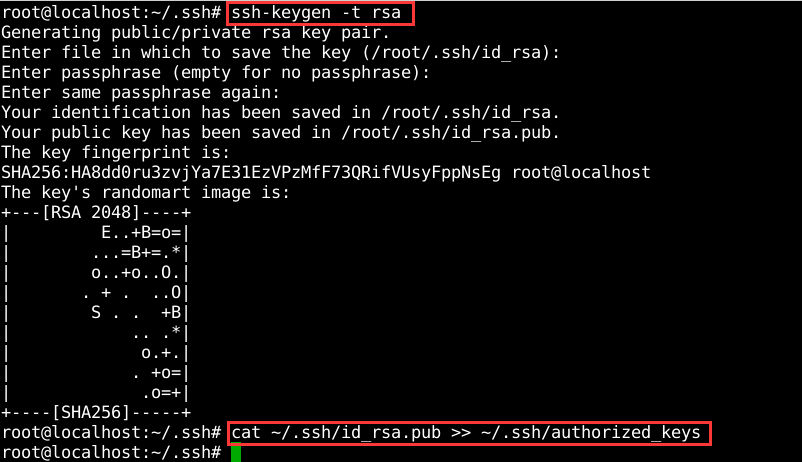
图5 生成公钥和私钥
如果有其他 slave 节点,也要执行将 master 公匙传输到 Slave 节点、在 slave 节点上加入授权这两步。这样,在 master 节点上就可以无密码 SSH 到各个 slave 节点了,可在 master 节点上执行如下命令进行检验,如下图所示
将master上的公钥放到其他虚拟机的~/.ssh目录下,并测试免密是否成功。下面是放到对slave1的免密配置,依次完成salve2。如图6所示。注意:在进行文件传输时需要密码为“Simplexue123“。上述的操作过程只是单向的,即此时,ssh root@slave1和ssh root@slave2是不需要密码的。而ssh root@master等反向仍然是需要密码的。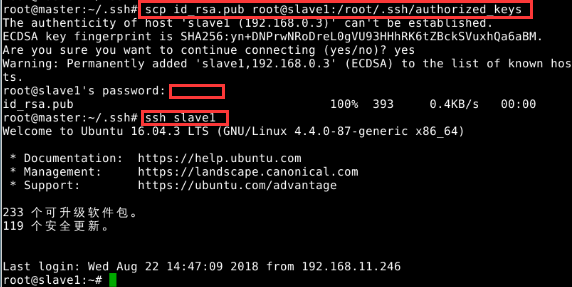
图6 将公钥传给其他机器
♥ 温馨提示
需要在所有节点上完成网络配置,如上面讲的是 master 节点的配置,而在其他的 slave 节点上,也要对/etc/hosts(跟 master 的配置一样)文件进行修改!步骤2、在master主节点上解压缩
执行命令:cd /simple/soft进入soft目录,如图7所示

图片7 进入安装包目录
执行命令:ls查看spark安装包,如图8所示
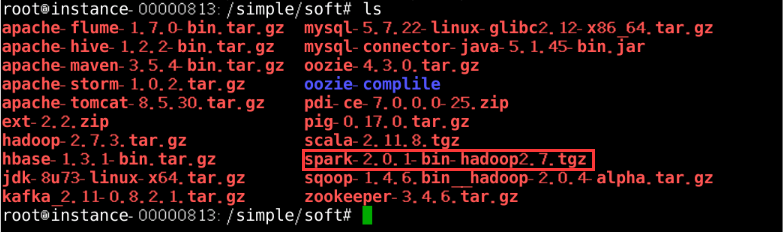
图片8 查看spark安装包
执行命令:
tar -zxvf spark-2.0.1-bin-hadoop2.7.tgz -C /simple进行解压缩,如图9所示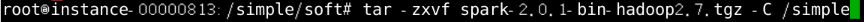
图片9 解压缩
进入simple目录,执行命令:ls查看spark解压后的文件夹并修改为简称,如图10所示

图片10 重命名解压文件
修改spark环境变量,在任意目录下执行命令:
vim ~/.bashrc编辑配置文件,如图11所示
图片11 配置环境变量
环境变量配置文件生效,执行命令:
source ~/.bashrc,如图12所示
图片12 环境变量配置文件生效
步骤3、spark完全分布式集群配置
切换至spark安装目录下的/simple/spark/conf文件并执行命令:
ls查看所有配置文件,并对文件spark-env.sh.template和slaves.template执行重命名命令生成spark-env.sh和slaves文件,如图13所示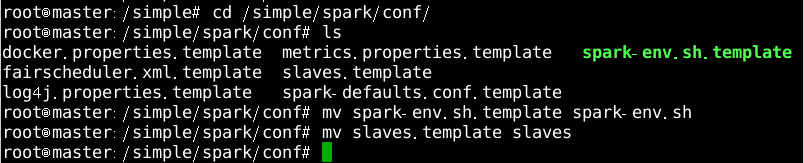
图片13 重命名文件
配置spark-env.sh。在conf目录下执行命令:
vim spark-env.sh并编辑其中内容,如图14所示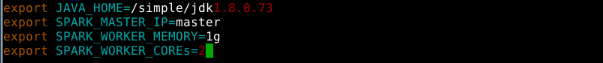
图片14 配置编辑文件
执行命令:vi slaves编辑修改slaves文件,如图15所示
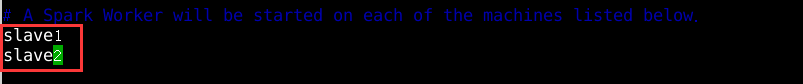
图片15 添加从节点
在另外两个节点进行一模一样的配置,使用scp将spark和.bashrc拷贝到slave1和slave2即可,
scp -r spark root@slave1:/simple/如图16所示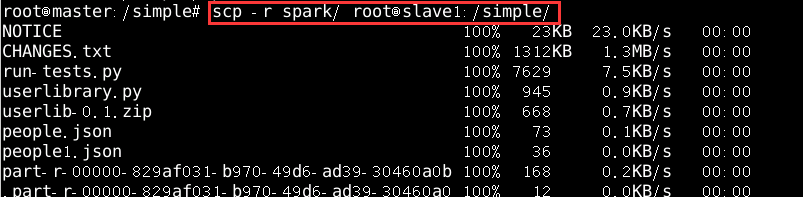
图片16 拷贝spark文件到从节点
scp -r ~/.bashrc root@slave1:~/如图17所示
图片17 拷贝.bashrc文件到从节点
在spark目录下的sbin目录执行
./start-all.sh启动spark服务,如图18所示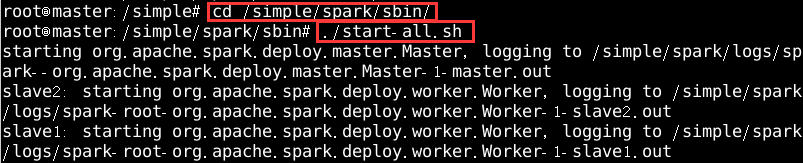
图片18 启动spark服务
步骤4、集群状态查看
查看主节点spark服务进程,如图19所示

图片19 显示主节点服务
查看两个从节点spark服务进程,如图20、21所示

图片20 显示从节点服务

图片21 显示从节点服务
通过浏览器访问端口查看主节点现在状态,状态表示:work机有两个,当前没有任务在执行,完成的任务数量为0(访问地址 http://localhost: 8080),如图22所示
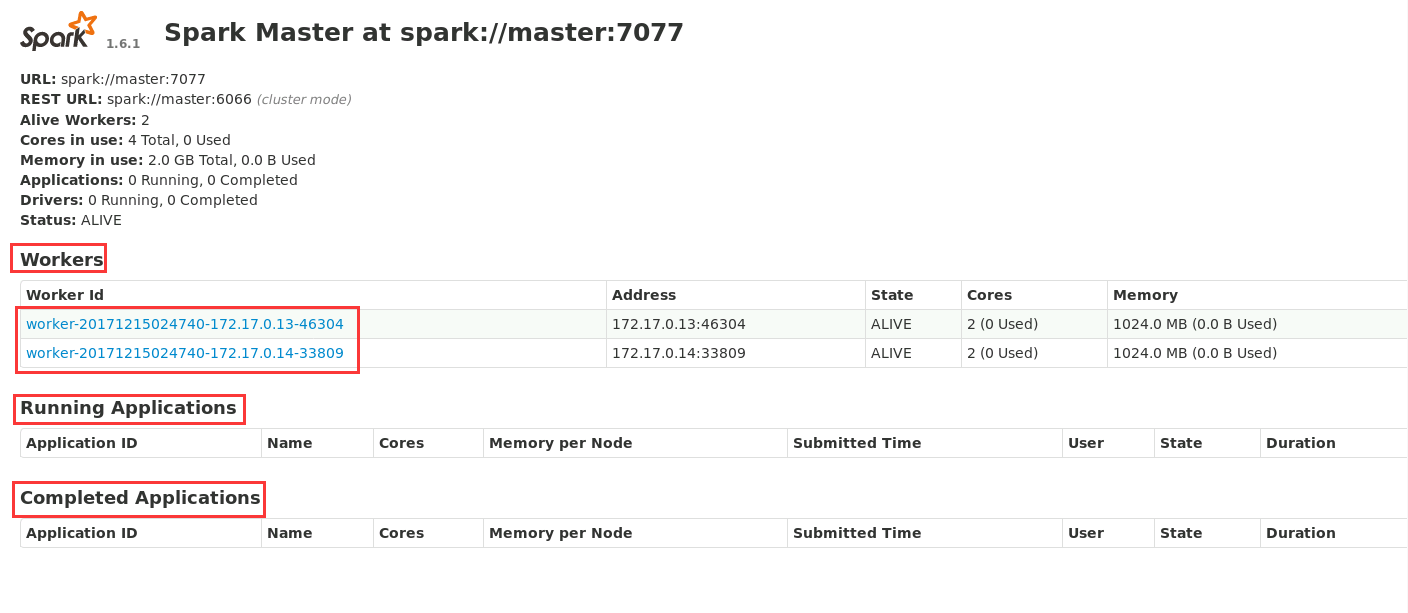
图片22 显示集群状态
在主节点中执行命令:
cd /simple/spark/sbin进入spark的sbin目录,如图23所示
图23 进入spark服务停止目录
执行命令:
./stop-all.sh停止spark服务进程,如图24所示
图片24 停止spark服务
再次查看主节点spark服务进程,如图25所示

图片25 显示主节点服务
再次查看两个从节点spark服务进程,如图26、27所示

图片26 显示从节点服务

图片27 显示从节点服务
♥ 温馨提示
配置好环境变量后一定要执行使配置生效的命令;使用spc命令传输文件夹时一定要带参数-r
-
相关阅读:
H5 tab点击切换CSS样式- 微信小程序开发技术要点总结(一)
SpringCloud OpenFeign
客户端日志打印规范
#力扣:14. 最长公共前缀@FDDLC
经典论文回顾:Decomposing Images into Layers via RGB-space Geometry
Java中的日期和时间的API(Calendar)
Json和Js之间转化(实际开发常用)
在谷歌浏览器上注册账号--具有偶然性的成功
作为公司测开岗的面试官,我是怎么选人的....
MKD调试下载的时候提示:Contents mismatch at: xxxxxxxxH (Flash=xxH Required=xxH)
- 原文地址:https://blog.csdn.net/qq_44807756/article/details/125544320