-
数据加载及预处理
1. 使用torch.utils.data.Dataset进行数据读取
- 通过继承该类进行数据读取
文件路径为:
import torch from torch.utils.data import Dataset,DataLoader import os import csv import glob import random from PIL import Image from torchvision import transforms import visdom from torchvision.datasets import ImageFolder class AnimalData(Dataset): def __init__(self,root,resize = [28,28],mode="train"): super(AnimalData,self).__init__() self.root = root self.resize = resize # [h,w] # 依据子文件夹名字获取各个类别的标签 self.class2label = {} for name in sorted(os.listdir(os.path.join(self.root))): if not os.path.isdir(os.path.join(self.root,name)): continue self.class2label[name] = len(self.class2label.keys()) print(self.class2label) # 从csv文件中加载数据的存储路径及其标签 images,labels = self.load_csv("animal.csv") # 根据任务需求,返回数据 if mode == "train": self.images = images[:int(0.6*len(images))] self.labels = labels[:int(0.6*len(images))] elif mode == "val": self.images = images[int(0.6 * len(images)):int(0.8 * len(images))] self.labels = labels[int(0.6 * len(images)):int(0.8 * len(images))] elif mode == "test": self.images = images[int(0.8 * len(images)):] self.labels = labels[int(0.8 * len(images)):] def load_csv(self,file_name): if not os.path.exists(file_name): images = [] for name in self.class2label.keys(): # glob.glob()方法可以匹配该路径下的文件,返回完整路径 images += glob.glob(os.path.join(self.root,name,"*.png")) images += glob.glob(os.path.join(self.root,name,".jpg")) # 打乱数据顺序 random.shuffle(images) # 写入csv文件,便于下次读取 with open(file_name,"w",encoding="utf-8",newline="") as f: writer = csv.writer(f) for path in images: name = path.split(os.sep)[1] label = self.class2label[name] writer.writerow([path,label]) # 通过csv加载数据 with open(file_name,"r",encoding="utf-8") as f: reader = csv.reader(f) images = [] labels = [] for line in reader: images.append(line[0]) labels.append(int(line[1])) return images,labels # 重写该方法,返回数据大小 def __len__(self): return len(self.images) # 反标准化,便于可视化 def de_normalize(self,x_hat): mean = torch.tensor([0.485, 0.456, 0.406]).unsqueeze(1).unsqueeze(1) std = torch.tensor([0.229, 0.224, 0.225]).unsqueeze(1).unsqueeze(1) x = x_hat *std + mean return x # 重写该方法,返回Tensor格式的数据及标签 def __getitem__(self,idx): label = torch.tensor(self.labels[idx]) tf = transforms.Compose([ lambda x: Image.open(x).convert("RGB"), # 读取图片 transforms.Resize([int(self.resize[0]*1.25),int(self.resize[1]*1.25)]), transforms.RandomRotation(15), # 数据增强 transforms.CenterCrop(self.resize), # 中心化裁剪 transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) ]) image = tf(self.images[idx]) return image,label if __name__ == '__main__': resize = [128,100] db = AnimalData(root="animal",resize=resize)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
{'cat': 0, 'dog': 1, 'rabbit': 2}- 1
2. 使用torch.utils.data.DataLoader进行数据加载
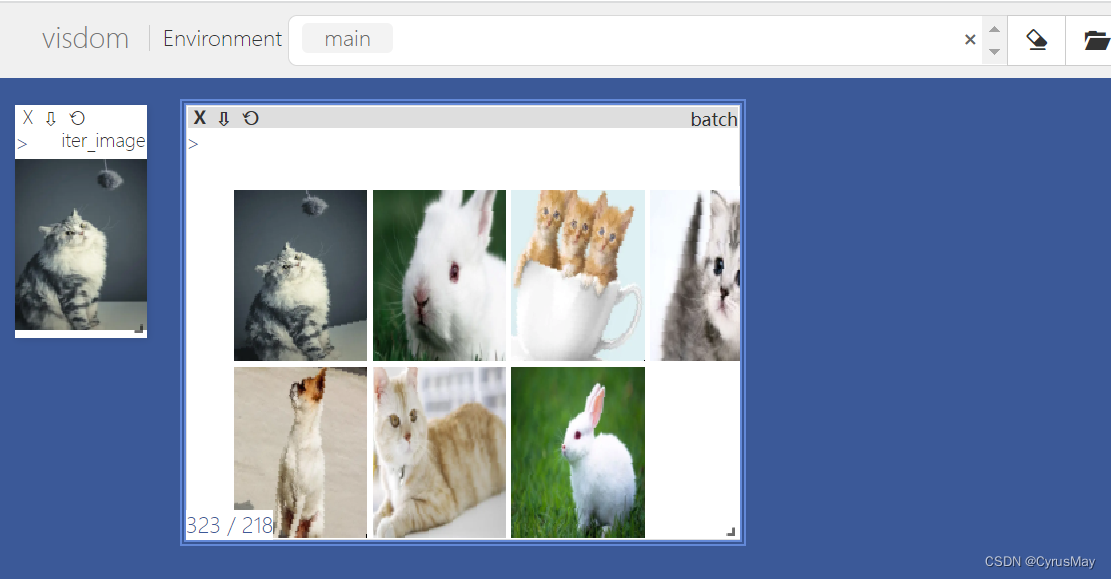
if __name__ == '__main__': resize = [128,100] db = AnimalData(root="animal",resize=resize) it_db = iter(db) vis = visdom.Visdom() image,label = next(it_db) vis.image(db.de_normalize(image),win="iter_image",opts=dict(title="iter_image")) # 使用数据加载器,设定batch loader = DataLoader(dataset=db,batch_size=16,shuffle=True,num_workers=8) # num_workers参数为多线程读取数据 for x,y in loader: vis.images(db.de_normalize(x),win="batch_imags",nrow=4,opts=dict(title="batch"))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
3. 使用torchvision.datasets.ImageFolder进行快速读取数据
# ImageFolder 可以一步实现上述过程 tf = transforms.Compose([ transforms.Resize([int(resize[0] * 1.25), int(resize[1] * 1.25)]), transforms.RandomRotation(15), # 数据增强 transforms.CenterCrop(resize), # 中心化裁剪 transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) ]) db = ImageFolder(root = "animal", transform=tf)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
by CyrusMay 2022 06 30
一生要有多少的辗转
才能走到幸福的彼岸
才能 活得此生无恨无憾
平凡却不平淡
——————五月天(青空未来)—————— - 通过继承该类进行数据读取
-
相关阅读:
DAO 中存在的不足和优化方案
【THM】SQL Injection(SQL注入)-初级渗透测试
AntScheduler
css实现多行文本的展开收起
无人机设计仿真--在Isight平台上进行的基于CST参数化+Xfoil的无人机翼型优化
MySQL常见知识点(面试题)总结
使用todesk或者向日葵远程Ubuntu22.04系统的客户机黑屏
华为防火墙双机热备拓扑
Java云原生(Spring Native)开发初体验报告
nginx配置kibana访问用户名和密码认证、及无认证访问配置
- 原文地址:https://blog.csdn.net/Cyrus_May/article/details/125539321
