-
跨境电商背景下,DolphinScheduler 在 SHEIN 的二开实践

分享嘉宾:董文彬
编辑整理:低代码无代码平台Treelab 张德通
SHEIN是一家中国跨境电商巨头公司,也是一家估值千亿的美金独角兽企业。本次分享由SHEIN架构部资深后端开发工程师董文彬介绍海豚调度器 Apache DolphinScheduler(以下简称DS)在SHEIN的使用和二次开发实践。
“
本次分享将介绍以下四部分内容:
SHEIN选择DS的背景和使用DS的实际效果
SHEIN使用DS的实践和对DS的二次开发
在使用和二次开发过程中遇到的问题
SHEIN调度引擎的规划
Apache DolphinScheduler
01
背景和使用
SHEIN引入DolphinScheduler之前,各个团队就已经有了使用调度的需求,但是内部的这些需求并没有出现一个统一的平台和技术栈来解决,所以各个团队要么就是自研,要么就是使用开源组件解决各自的调度需求。比叡SHEIN数仓团队在引入DolphinScheduler前是通过自研的调度系统;SHEIN的AI团队使用的是Airflow;SHEIN风控团队也自研了另一个调度系统;还有一些轻量级调度任务,直接用定时器的方式部署在机器上等等。任务的执行类型也各不相同,有Shell、Python、Spark、MR、Flink等类型繁多的调度任务。
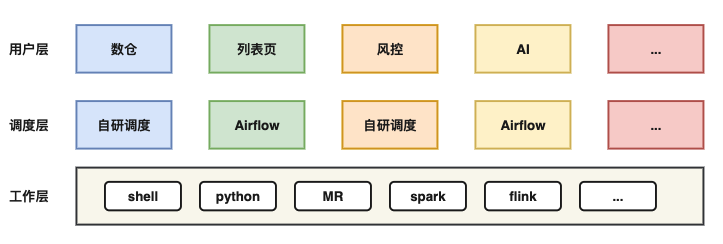
将调度层打通、实现调度层统一化,是SHEIN引入DolphinScheduler的目的,旨在方便运维、降低研发和维护成本。
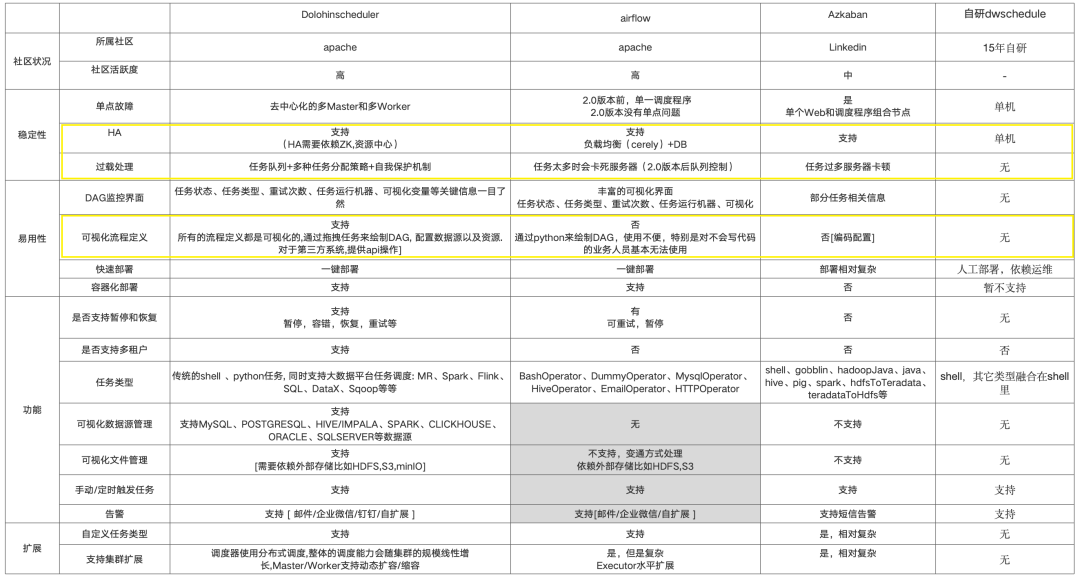
经过详细的竞品对比之后,鉴于稳定性、易用性、功能和可扩展性几方面做了深度调研,最终我们选择了DolphinScheduler作为调度引擎。表格如下图(市面调度工具对比)。
DolphinScheduler支持多种任务的调度,社区非常活跃,能够满足多业务方的调度需求。SHEIN在使用DolphinScheduler统一了调度层后整体架构得到了简化。
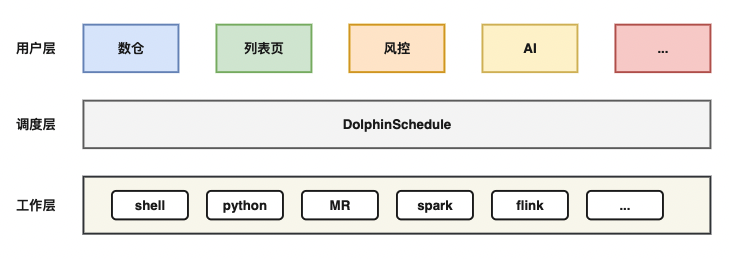
但用户层的用户习惯不会随着调度层的变更迅速改变,调度平台的用户量大、需求多样,难以抽象化地统一改造。为了让数据调度平台能更加贴合用户使用习惯和业务特性与场景,我们对DolphinScheduler进行了改造,适配多样化的业务方需求。
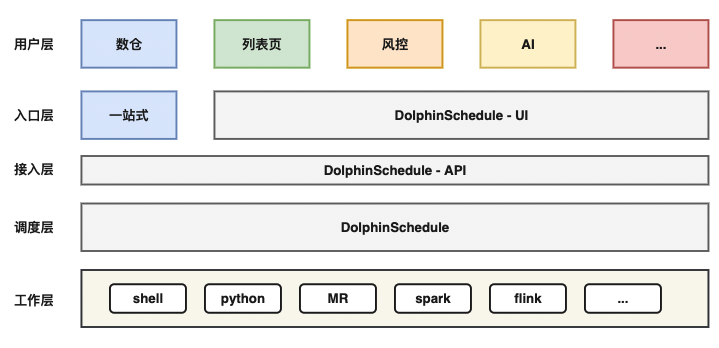
为了满足用户例如任务发布流程、冒烟测试、发布上线、审核等需求,我们基于DolphinScheduler提供的API为数仓用户抽象了一站式的入口层。列表页、风控、AI等客户沿用DolphinScheduler的UI。接入层和DolphinScheduler UI都调用DolphinScheduler API与调度层的DS交互。
SHEIN 自 2020 年引入 DolphinScheduler ,但在接入 K8S 前都是小范围使用、定义的任务数少,任务实例少。接入 K8S 后,我们从虚拟机部署转为 K8S 容器化部署。2021年 4 月开始接入了 AI 业务,2022年1月,我们将数仓任务从公司自研调度引擎迁移到了DolphinScheduler调度引擎上运行。
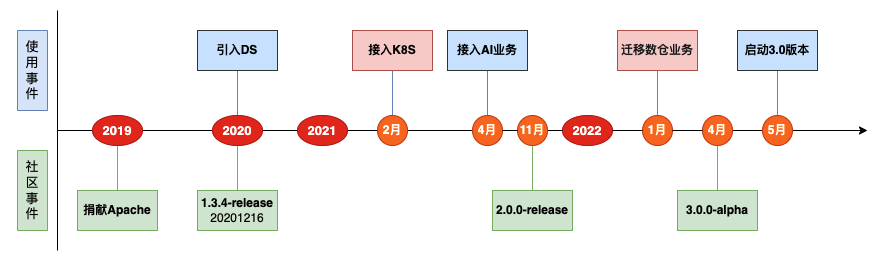
在数仓任务迁移后,我们面临着多项挑战:大量的任务实例、工作流实例、任务实例和大量并发场景的挑战等。2022年4月我们启动了3.0版本升级,5月正式上线了 DolphinScheduler 3.0 版本。
DolphinScheduler在SHEIN的部署有两个特点:
多站点部署,SHEIN部署了4个站点
虚拟机、K8S混合部署
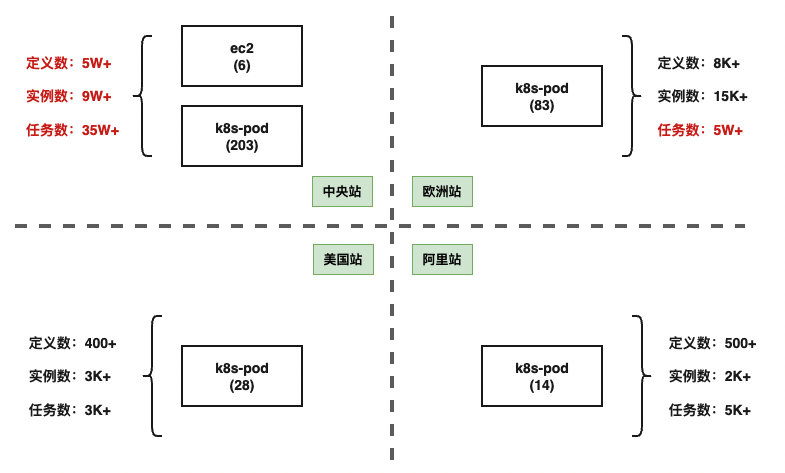
中央站我们部署了6台虚拟机,K8S Pod 203个,定义的DAG定义数量5w+,每天运行DAG实例数9W+,每天运行35w+任务数。欧洲站每天任务数5w+,美国站和阿里占两个站点数仓业务正在迁移中,当前任务较少。
02
DS在SHEIN的实践与二次开发
Apache DolphinScheduler是一个分布式去中心化,易扩展的可视化DAG工作流任务调度平台,致力于解决数据处理流程中错综复杂的依赖关系,使调度系统在数据处理流程中开箱即用。
DolphinScheduler 内部有几种角色分类:
UI:前端界面
API:前端界面接口应用
Master:工作流实例管理、任务实例管理
Worker:执行任务实例的角色
DS使用Zookeeper做节点管理,MySQL存储工作流定义的元数据信息和任务数据。
DolphinScheduler 实践
DS
SHEIN 从2020年开始使用的DS版本是1.3.4版本,下图是架构图,与2.0有较大区别。UI层是用户操作层,用户定义 DAG、定时器等操作,还可以看到运行实例的过程等。UI对应的是DolphinScheduler API,API与数据库交互,读取任务定义和任务的状态。API 与 Worker交互,从Worker的log server内拉取任务的日志信息。
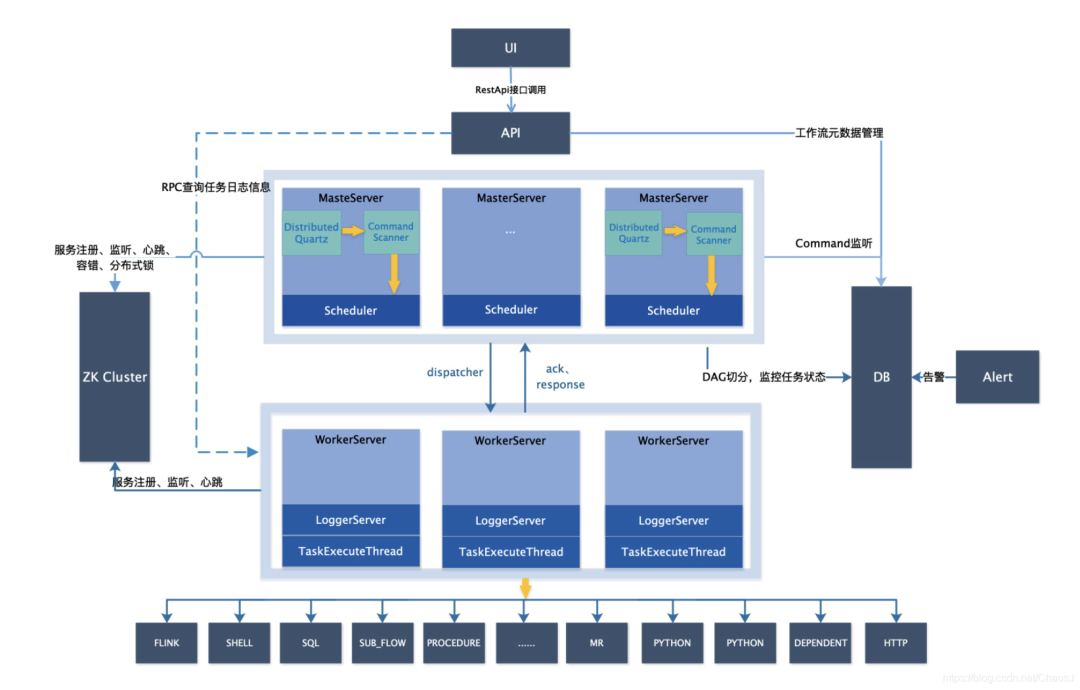
DolphinScheduler MasterServer 内的Quartz组件是生成定时任务命令的组件,通过Command Scanner生成DAG实例、切分DAG实例到任务颗粒度后,将任务通过Netty通信的方式分发给 Worker。
Worker 是真正的执行角色、是执行层,下层对接着Flink、Shell、SQL等任务类型角色,可以把各种各样的任务类型角色调度起来。执行结果会被反馈给Master,Master把结果存入数据库。
当任务执行出现异常时,通过Alert模块扫描异常情况并告警。
下图是我们根据官方架构图与SHEIN业务结合后归纳出的逻辑图。用户通过UI查看任务、操作DAG、查看任务运行情况,最终查询MySQL,任务的运行是Master切分后分发给Worker等。任务的异常由Alert Server查到MySQL中,对接企业微信进行告警。
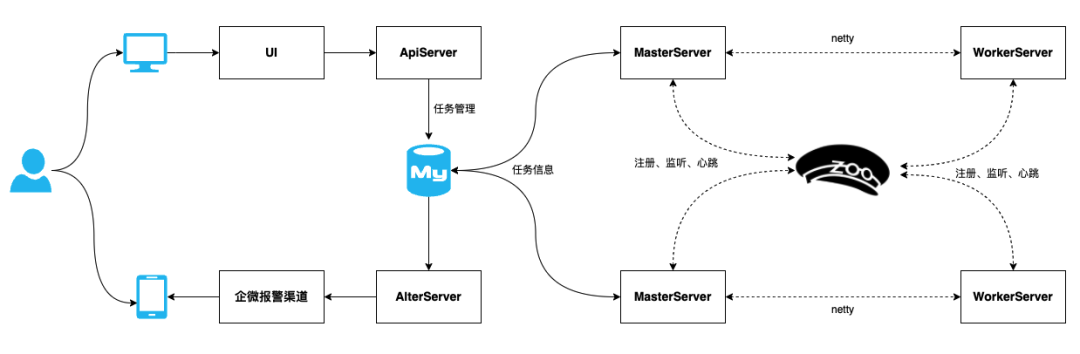
逻辑图中,Master是分布式的、Worker也是分布式的,Zookeeper作为中间角色负责节点管理和心跳管理。如果Worker挂掉,通过zk监听机制,Master会将挂掉的worker上任务进行容错;重新分发到新的Worker上。API、Alert、Master节点都连接到MySQL数据库。
调度平台需要满足多元业务特性、数据合规性,我们在多个站点都部署了独立的DolphinScheduler 调度系统,目前共4套DolphinScheduler调度系统。
我们的业务需要处理场景多站点之间任务互相依赖的情况,要考虑多站点之间依赖通信。例如,国内站业务运行完毕后需要通知下游业务运行,若下游业务在欧洲站,这个场景下的任务通信和调度是原生的 DolphinScheduler 所不支持的,网段也是互相隔离的。
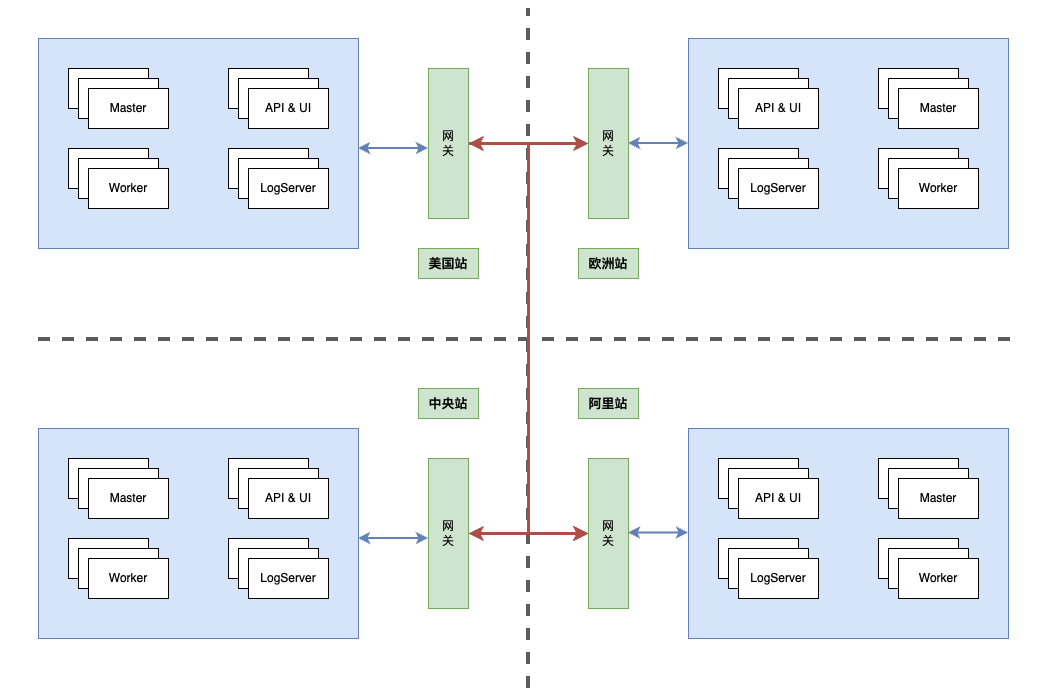
我们通过SHEIN的网关机制打通了不同DS集群之间任务互相依赖的通信方案。国内站任务运行完成后,请求发到网关,网关会对任务所在集群进行识别后分发到欧洲站网关,欧洲站网关再把数据转发给欧洲站的DS。
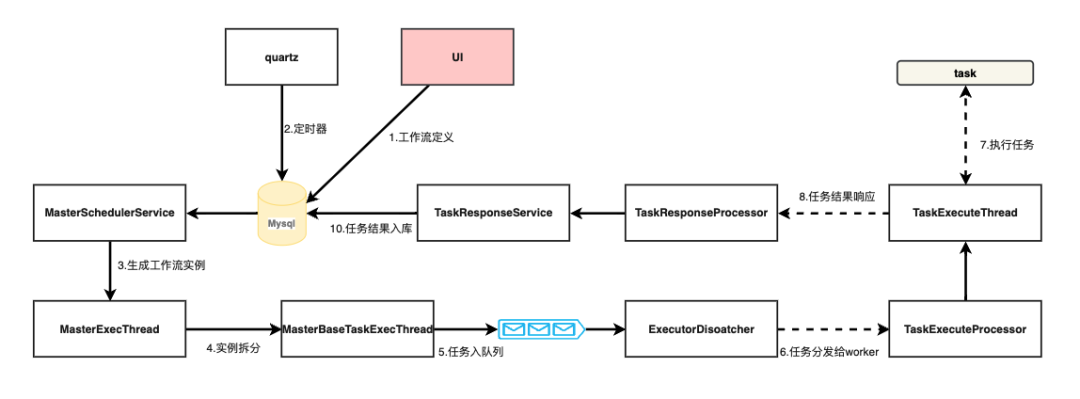
为了将抽象行为具体化和让内部复杂结构显性可见、方便团队人员上手DS理解整个项目、改造代码,我们梳理了代码导览图。如下,首先UI定义工作流存入MyQL,Quartz模块定时器拉取MySQL内数据,生成DAG实例命令。定义生成命令后生成工作流实例、而后拆分成任务实例,任务实例入队列、由Master分发给Worker。Worker负责任务的执行,反馈结果到Master,Master处理反馈、结果入库。
下图是更加详细的DS内部工作流程。红色部分是Master和Worker启动类,ZK在Master、Worker中间负责节点管理、心跳管理。
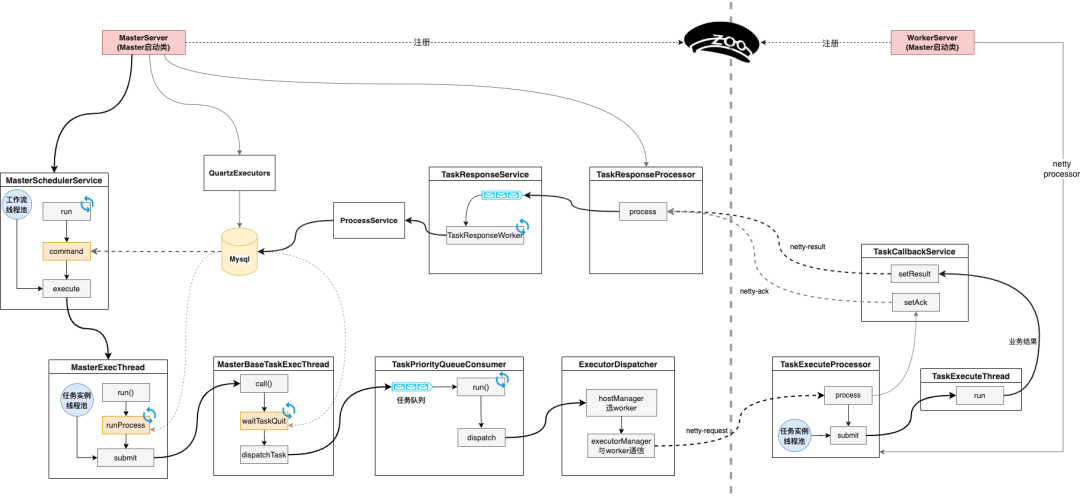
从代码导览图中可以理解 DS 的设计理念。DS 内部有大量轮询,对应着扫描 MySQL 数据库,有的是扫MySQL 内存储的 DAG 命令、有的是扫任务状态,循环对应了线程池,也对应着一个队列。队列的作用是解耦不同的业务。
下图更详细地展示了DS容错方面的设计细节。
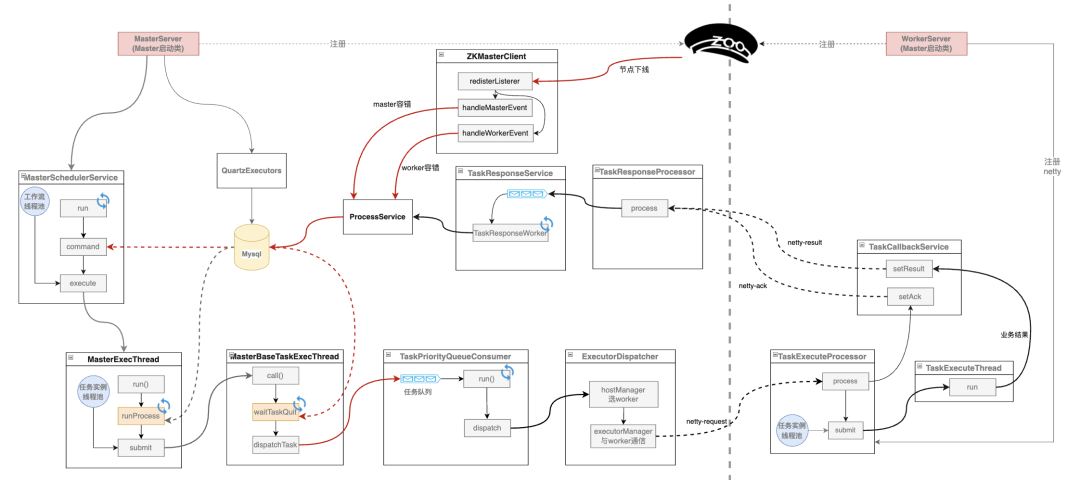
ZK 负责节点管理、心跳管理,能监控和管理到节点,监听者会知道哪些节点下线,可以区分是 Master 还是Worker的下线。如果监听到 Master 节点下线,容错流程会重新生成 command,其他 Master 会在某个Master下线后重新生成 DAG。如果监听到 Worker 下线,容错机制会让任务重新下发给新的 Worker。
二次开发
DS
01
数据库性能优化
SHEIN在2022年将数仓工作流调度任务从自研调度引擎迁移到 Dolphin Scheduler。数仓工作流是一个超级大的DAG;如果直接把这个DAG放入海豚调度,那么就出现页面爆炸现象,因此我们要拆分DAG。我们需要既要不破坏自研调度系统调度又要适配海豚调度方式,所以我们将超级大的DAG中每个节点拆分成4个节点组成的小DAG(海豚调度中的一个工作流);每个小的DAG里面都有一个依赖节点,指向其依赖的工作流。拆解后的工作流拆解成为近两万个工作流定义,每天大约运行30w左右任务。每天凌晨左右跑任务,同时拉起近2w工作流实例,此时线程池会打满,MySQL负载过高可能宕机(QPS 7W+)。
下图标红的循环部分是会导致出现故障的业务模块,拉起DAG工作流实例、任务级别现成不断扫MySQL表,导致MySQL的QPS过高。
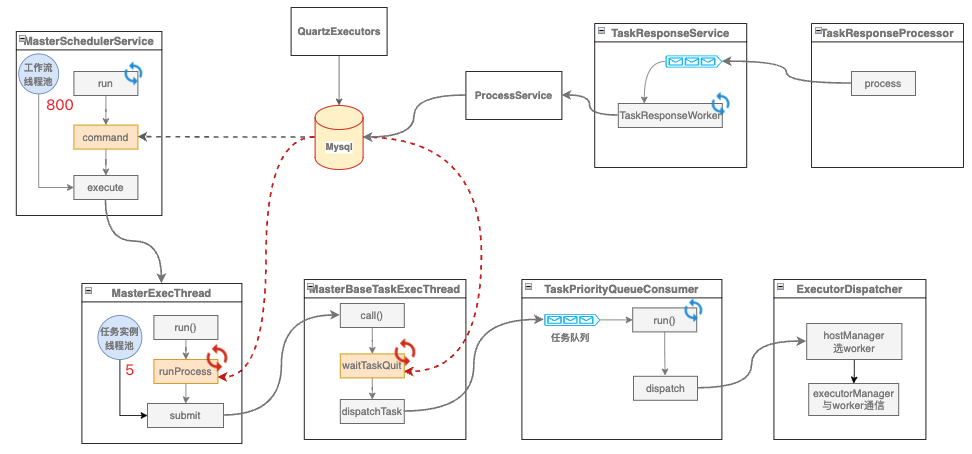
从监控可以看到,Master线程池配置了800、基本被打满,QPS在6、7w,后续就出现了MySQL宕机。
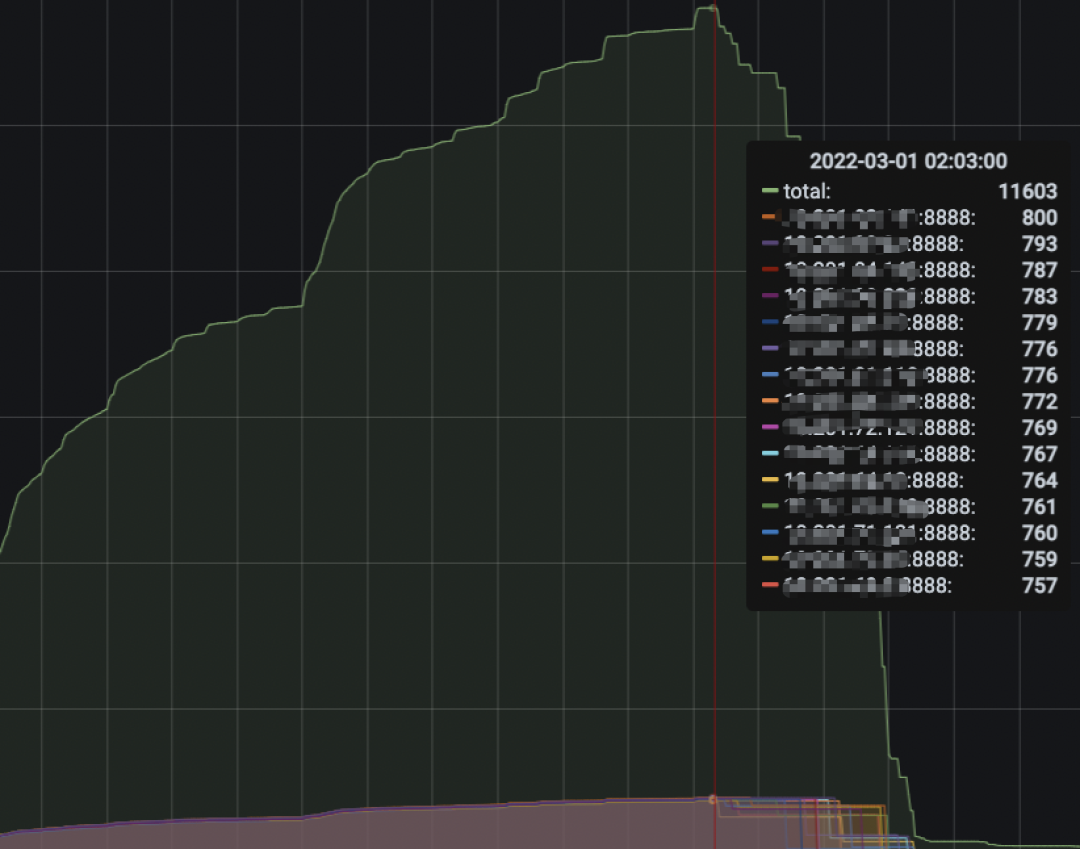
每个工作流定义创建工作流实例;会创建一个工作流实例级别的线程。每个工作流实例会拆解为若干个任务,每个任务又会对应一个线程。工作流实例和任务实例需要轮询数据库来判断任务的运行情况。我们的解决方案是:工作流实例和任务实例轮询数据库处上加上sleep策略(1-20秒的策略)。下图是实施该方案后的监控,优化后的QPS稳定在1.4w,效果很好。
02
分发线程优化
我们有大量的用户组,用户组数量大后会出现此类问题。假如有3组Worker,共用2台 Master,其中一组Worker心跳异常,Master 判断为下线;而该组Worker工作流实例还在不断的生成,Master 总线程数持续升高,直至线程耗尽。关键点是,大量的任务实例在分发环节重复分发,失败后进入分发队列,导致大量的死循环。
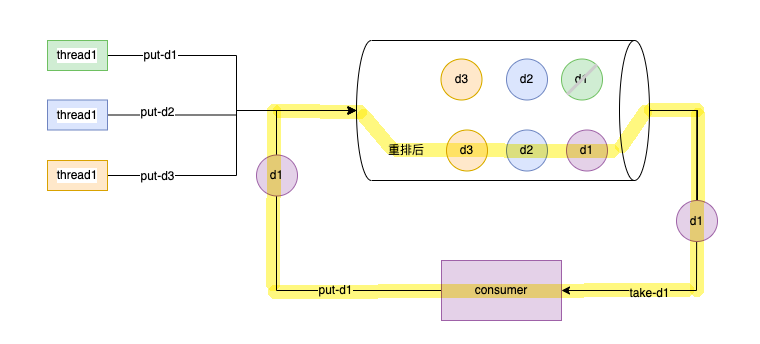
任务实例具备优先级,优先级决定因素是优先级级别、生成任务的时间。任务实例在分发时重复分发且分发失败,导致大量死循环,分发队列由于存在优先级导致了任务重发。优先级的决定因素一是优先级别,另一个是任务生成的时间。
假如优先级级别一致,8点有一批任务实例,9点有一批任务实例;假如8点的任务实例全部分发失败,如果时间到了9点,那么这时候需要分发8点和9点的任务实例;从而产生了这样的现象:失败的这批任务实例,影响了9点正常业务的分发。影响的分发对应下图中红色框部分,Worker已经下线、不能选择Worker。
影响分发的逻辑我们定位到下图中红框部分,由于Worker下线,分发不到Worker、选择Worker时候也不能选择。
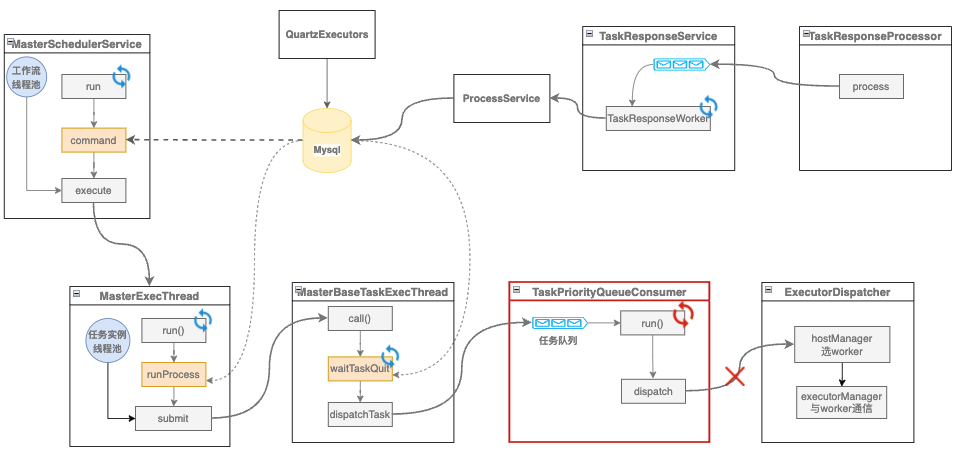
详细分析失败的模块我们发现,任务级别的线程在不断提交任务到分发队列中,分发队列线程不断到队列内取任务、再做分发,分发失败的任务被放到失败容器内。失败容器内的任务会在一定时间后再放回到分发队列内。
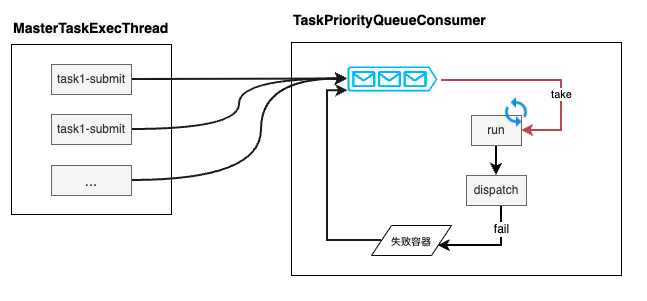
这样的链路中存在一个环,我们的优化是打破这个环。
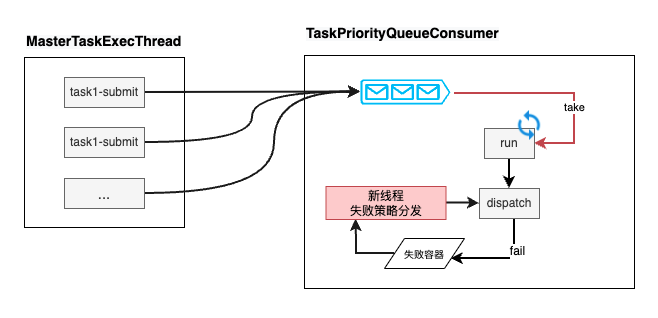
我们的解决方案是:新增一个处理失败队列的线程;task失败之后,把失败的task放入失败队列,新增的这个线程消费失败队列task,走失败策略,分发给Worker。正常的任务就可以得到有效的分发。
03
平滑上下线功能
平滑上下线功能是我们基于官方DS新开发的功能。主要解决上线过程中可能存在的Worker变更。
比如,当前集群内存在1组 Worker,1组 Master,此时 Worker 组迭代功能发布,发布前 Worker 组上正在运行着的任务实例,在新发布后会容错到新的Worker 组上重新运行。
有些任务具备长时间运行特性,如 AI 模型训练的任务需要20小时左右,在第19小时发布 Worker、容错到新 Worker 上,已经运行过的计算会作废重跑,重跑成本高。有些是资源型任务,在运行过程中可能会占用10G+的内存空间,重试成本也很高。
我们把 Worker 的发布改成了平滑发布,如下图,我们维护两套发布流水线,称为蓝绿发布流水线。一条流水线上跑着业务,另一条流水线空闲。当有新功能发布时候,发布动作发生在新流水线上,新、老流水线共存,发布完成后把老 Worker流量切到新 Worker ,Master 不再向老流水线分发任务,但老流水线的Worker 会维持任务的运行状态。任务运行完成会被逻辑、物理下线。
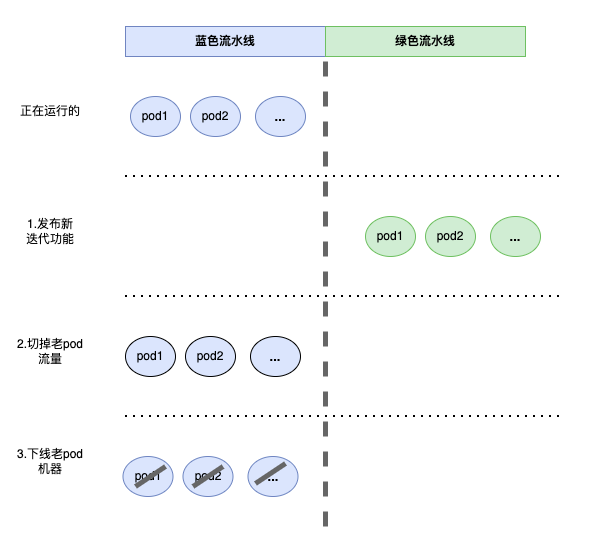
下面将介绍蓝绿发布Worker的具体流程:
1、上线新版本前 Worker 现状如下。
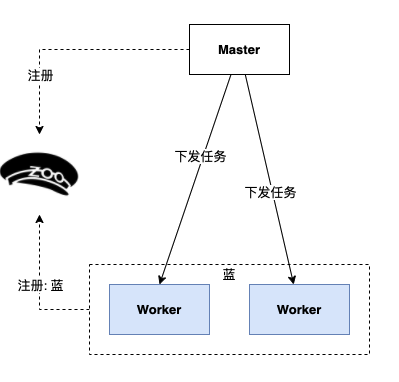
2、发布一组标签为绿色的 Worker;蓝绿实例并行运行。
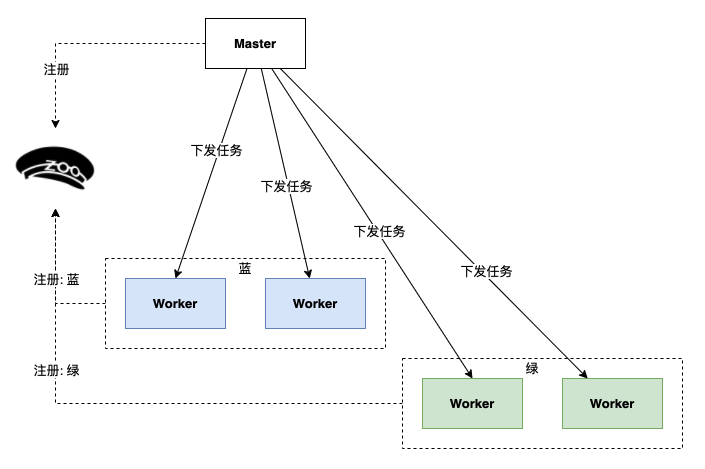
3、发布绿色分组 Worker后,切断蓝色分组的流量。
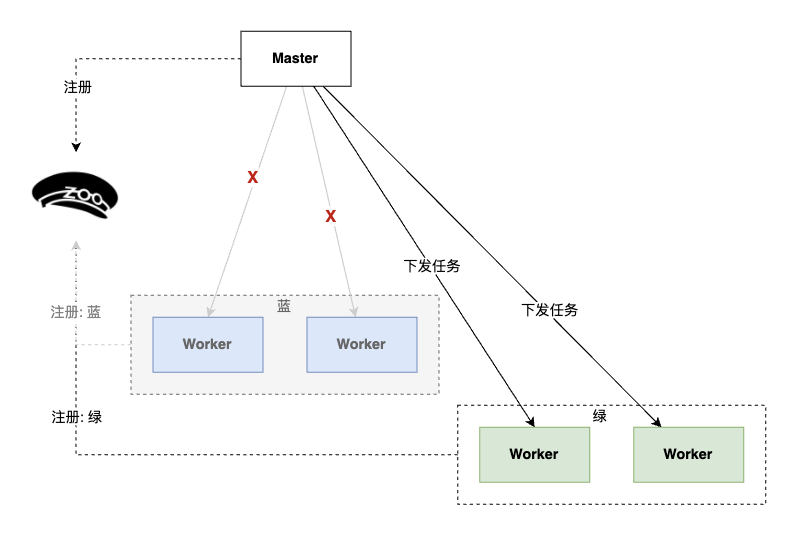
4、下线蓝色 Worker;绿色Worker工作。
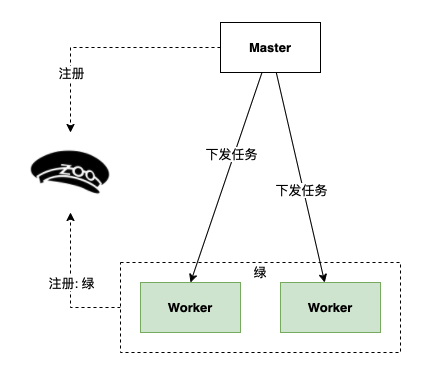
蓝绿发布过程帮助我们把任务重跑成本高的问题规避掉了。
04
任务分发不均衡,导致部分Worker负载过高
从EC2迁移到K8S时,可能有任务分发不均匀问题。Master分发任务实例有三种策略
随机策略:
从当前的Worker分组中随机挑选一台Worker
轮询策略:
从当前的Worker分组中逐一挑选Worker并分配任务实例
低负载策略:
从当前的Worker分组中挑选负载最低的一台Worker(1分钟内的CPU load avg)
我们Worker的混布在虚拟机和K8S内。
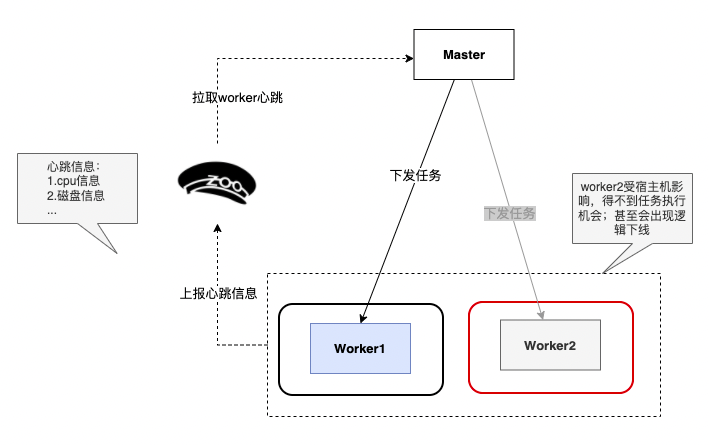
K8S中的 Worker 获取的 cpu load avg是宿主机的,数值一直比虚拟机的高,如果宿主机负载高,上线pod时会出现逻辑下线。我们会在机器负载监控数值大于核数x 2 Master时不再向此Worker分发任务实例。Java8环境,K8S中的POD无法获取真实的POD中 CPU load avg,因此CPU load avg不足以全面的衡量 Worker 负载情况。考虑到我们的几千个工作流定义的计算逻辑非常相似,除了CPU load avg、磁盘使用率等指标之外,我们增加了活跃线程数指标作为衡量负载的主要标准指标之一。
下图是改造前分发的逻辑,Worker2受到宿主机影响不能被Master分发任务、可能被逻辑下线。
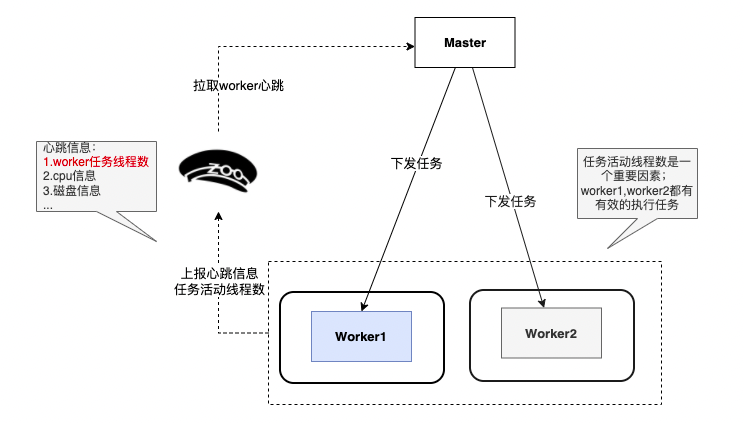
改造后,我们把CPU、磁盘的指标权重降低,加入Worker任务线程数指标作为考量依据后,Worker2和Worker即可以有效地被Master分发任务。
以上是SHEIN在DS上做的比较典型的四个二次开发场景。
03
在使用和二次开发过程中遇到的问题
01
Worker部署问题
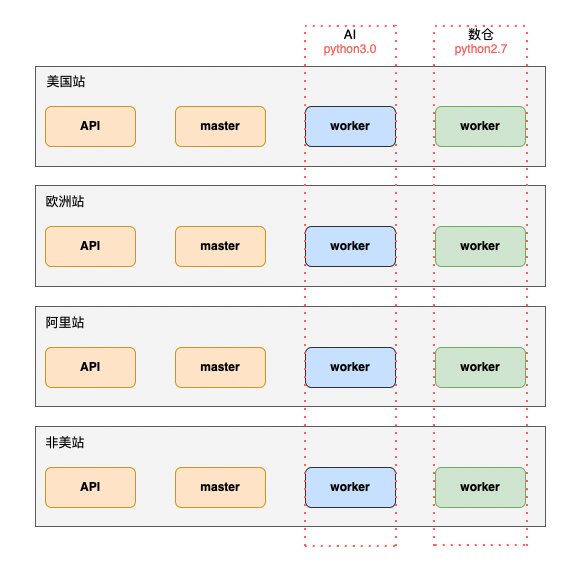
Worker混合部署在EC2和K8S上,用户组多、对环境要求不同,python版本可能不同。我们的每几个站点可能对不同用户组部署不同Worker group,一个特性可能就会部署两个Worker group。这样的复杂也难以避免,我们的团队认为:“复杂难以避免,但可以对复杂问题做统一规律化”。
我们最初把环境特性融入到了代码层,不同用户组有不同启动脚本,程序真实启动的位置、DockerFile中也都融入了用户特性。我们把用户特性都统一模块化到DockerFile层,统一了源码层、启动脚本层,团队的环境特性打成了共识、降低了维护成本。
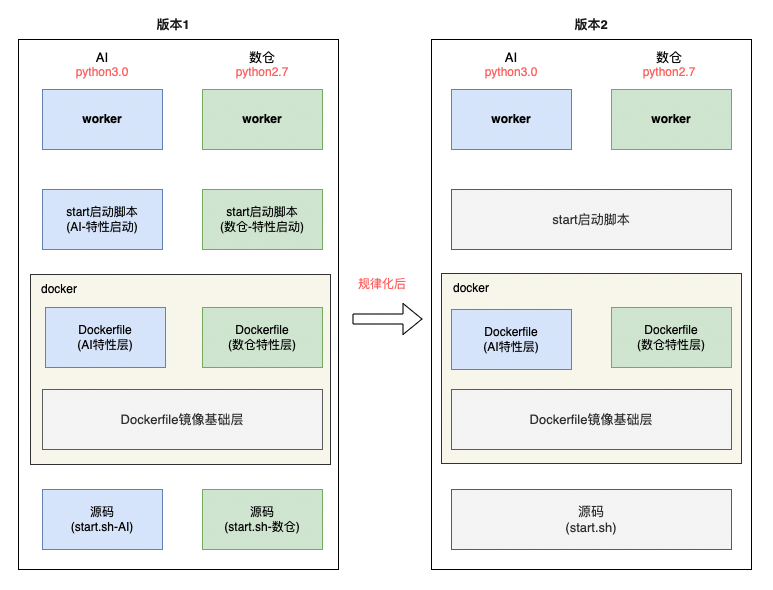
目前虽然部分缓解了部署问题,部署复杂、环境混乱的问题并没有彻底解决,我们也一直思考如何彻底规避复杂。这部分功能我们的团队还在不断迭代和演进。
02
监控问题
日志监控没有实例级别的连续性(没有traceId),导致排查问题需要收集碎片化的日志
调度引擎管理用户监控和业务监控未区分开
业务监控未下方到用户组自主配置
03
DS(1.3.4版本)问题
在使用DS中遇到的问题,有些高版本已经修复
1.3.4版本 cpu使用率返回的是 cpu负载,此后DS版本已经修复。
我们在升级前修改成了近一分钟内的CPU使用率。
当任务实例特别多的时候,mysql线程池是一个短板,在前面介绍的二次开发中介绍过的。
DS 3.0已经改变了实现方式。
逻辑下线在docker中不准确,获取的下线指标是K8S宿主机的。
历史实例,一直堆积在mysql中,没有归档机制。
我们已经加入了归档机制,一个月前的数据被归档、历史数据可查询。
04
其它问题
依赖的周任务(本周当前时间之前本周每一天;
而不是本周一次成功就可以)。
我们改成了本周一次的依赖。
实例丢失(quartz、netty等)。
网络抖动可能导致Worker下线、Master重新分发给其他Worker后网络恢复,任务可能重复运行。
任务停止问题。
kill可能不准确。
面对这些问题,我们解决了很多,但是有些也没有根本地解决。
04
SHEIN调度引擎的规划
1、升级3.0版本
mysql不再轮询
2、日志
日志输出规范
串联日志,添加traceId
3、监控
基础监控框架
任务监控下发到用户层
4、告警
基础告警框架
自定义告警
5、规范
项目空间和WorkerGroup绑定问题
用户token管理
任务版本控制
任务、资源中心等权限审批
05
Q&A
1、可以在多个站点配置一次就可以在多个站点运行任务吗?
DS
SHEIN有一个入口层,叫一站式、不分站点,在同一入口层会生成任务、分发到各个站点。
2、DS存储业务数据吗?
DS
DS不存储业务。只存储DS任务实例信息,运行状态信息,任务信息交给用户存储。调度引擎的定位是支持底层调度,不处理业务。
3、元数据有单点故障风险吗?
DS
目前DS社区架构MySQL是一个单点,我们是主从架构规避单点,可以做到稳定运行。
4、Worker由于异常与zk失联后,Master重启任务,两个任务同时运行如何处理?
DS
1.3.4可能出现任务重复跑,我们借鉴了3.0的解决方法:Worker由于网络抖动和zk连接断开,此时把Worker进程停掉,新启动的进程的task会被Master发到新的Worker上。
5、调度平台底层是用Hadoop、CDH吗?
DS
SHEIN使用的是Hadoop平台,利用EMR。
6、数仓迁移转化成工作流的过程是怎样的?
DS
迁移方案,在数仓内通过解析、把原有任务拆解成适合DS任务的Json,通过原有系统调用DS的API生成新的DS内部DAG。通过接口调用解决,将原DAG转化为新DAG。
7、MySQL不再轮询是怎样的?
DS
MySQL 不再轮询其实是社区的一个改进。如果我们要想知道事件的进展,一方面可以直接跟踪最底层、MySQL 存储层;另外一方面我可以跟踪事件,就不需要查 MySQL 了。3.0 的解决方案就是使用事件跟踪机制来解决 MySQL 的轮询问题的。
8、从1.3.4升级到3.0以上版本遇到了什么问题?
DS
版本升级对我们来说非常有挑战,首先表结构变更、前端页面也有变更,我们对前端页面有一些改动也要重做。但1.0到3.0的产品特性没有改变,首先我们要把3.0版本没有支持的内容,且我们做了修复的部分同步过去。可能存在的数据库不一致问题,我们也有一些迁移的开发工作。
参与贡献
随着国内开源的迅猛崛起,Apache DolphinScheduler 社区迎来蓬勃发展,为了做更好用、易用的调度,真诚欢迎热爱开源的伙伴加入到开源社区中来,为中国开源崛起献上一份自己的力量,让本土开源走向全球。

参与 DolphinScheduler 社区有非常多的参与贡献的方式,包括:

贡献第一个PR(文档、代码) 我们也希望是简单的,第一个PR用于熟悉提交的流程和社区协作以及感受社区的友好度。
社区汇总了以下适合新手的问题列表:https://github.com/apache/dolphinscheduler/issues/5689
非新手问题列表:https://github.com/apache/dolphinscheduler/issues?q=is%3Aopen+is%3Aissue+label%3A%22volunteer+wanted%22
如何参与贡献链接:https://dolphinscheduler.apache.org/zh-cn/docs/development/contribute.html
来吧,DolphinScheduler开源社区需要您的参与,为中国开源崛起添砖加瓦吧,哪怕只是小小的一块瓦,汇聚起来的力量也是巨大的。
参与开源可以近距离与各路高手切磋,迅速提升自己的技能,如果您想参与贡献,我们有个贡献者种子孵化群,可以添加社区小助手微信(Leonard-ds) ,手把手教会您( 贡献者不分水平高低,有问必答,关键是有一颗愿意贡献的心 )。
添加小助手微信时请说明想参与贡献。
来吧,开源社区非常期待您的参与。
更多精彩推荐
☞恭喜!Apache DolphinScheduler社区再添9枚“新鲜”Committer
☞达人专栏 | 还不会用 Apache Dolphinscheduler?大佬用时一个月写出的最全入门教程【二】
☞Apache Dolphinscheduler 5月Meetup:6个月重构大数据平台,帮你避开调度升级改造/集群迁移踩过的坑
☞金融任务实例实时、离线跑批,Apache DolphinScheduler 在新网银行的三大应用场景与五大优化
☞中国联通改造 Apache DolphinScheduler 资源中心,实现计费环境跨集群调用与数据脚本一站式访问
我知道你在看哟

-
相关阅读:
数字图像处理(九)双边滤波
Java 复习笔记 - 常见算法:API Arrays
Ctfshow web入门 XSS篇 web316-web333 详细题解 全
8 年 Java 开发含泪刷题,架构岗现在好难进,有点崩溃
边用边充电影响寿命吗?看看计算机指令组成与操作类型
辉芒微IO单片机FT60F010A-URT
数组复制(java)
STC51单片机30——单个数码管显示
蓝桥杯十五届国赛模拟题1答案
Oracle day9
- 原文地址:https://blog.csdn.net/DolphinScheduler/article/details/125532535