-
hadoop3.x入门到精通-阶段三(HDFS源码..持续更新)
HDFS通信协议
Hadoop RPC接口主要是定义在org.apache.hadoop.hdfs.server.protocol和org.apache.hadoop.hdfs.protocol两个包中。其中主要包括如下几个接口:
- ClientProtocol:ClientProtocol定义了客户端和NameNode之间的交互,这个接口方法是非常多的,客户端对文件系统的所有操作都需要通过这个接口,同时客户端读写文件等操作也需要先通过这个接口与NameNode协商之后,在进行数据的读出和写入。
- ClientDatanodeProtocol:客户端与DataNode之间的交互,该接口定义的方法主要用于客户端获取数据节点信息时调用,而真正进行数据读写交互的则是后续要讲到的流式接口。
- DatanodeProtocol:DataNode通过这个接口与NameNode通信,同时NameNode会通过该接口中方法的返回值向DataNode下发指令。注意,这是NameNode与DataNode通信的唯一方式,DataNode会通过这个接口向NameNode注册、汇报数据块的全量以及增量的存储情况。同时,NameNode也会通过这个接口中的方法返回值,指令DataNode执行诸如数据块复制、删除以及恢复等操作。
- InterDatanodeProtocol:DataNode之间的通信,主要用于数据块的恢复,以及同步DataNode上存储的数据块副本的信息。
- NamenodeProtocol:SecondaryNamenode与NameNode之间的通信,因为引入了HA机制,checkpoint操作不再由SecondaryNamenode执行,所以这个接口不太需要详细介绍。
- 其他接口:主要包括安全相关的RefreshAuthorizationPolicyProtocol、RefreshUserMappingsProtocol,HA相关的接口HAServiceProtocol等。
ClientProtocol
- // 客户端从hdfs得到对应数据块在datanode的位置,按由远到近的距离进行排序返回给客户端
- LocatedBlocks getBlockLocations(String src, long offset, long length)
- // 客户端向namenode回报错误块,当客户端读取数据块发现数据校验和不正确的时候
- void reportBadBlocks(LocatedBlock[] blocks) throws IOException;
- // 用于在hdfs上面创建一个src路径的空文件夹,创建的时候对于其他的客户端是可读的,
- // 直到文件关闭或者租约过期,然后通过addBlock()方法获取存储块的位置信息,
- // 最后客户端就可以更具这些位置信息建立数据通道,就可以传数据了
- HdfsFileStatus create(String src, FsPermission masked,
- String clientName, EnumSetWritable<CreateFlag> flag,
- boolean createParent, short replication, long blockSize,
- CryptoProtocolVersion[] supportedVersions, String ecPolicyName)
- throws IOException;
- // 如果最后一个数据块没有写满返回数据块的信息,如果写满了,那么就调用create()
- LastBlockWithStatus append(String src, String clientName,
- EnumSetWritable<CreateFlag> flag) throws IOException;
- // 客户端先指定的文件添加一个数据块信息,并且返回这个数据块所有数据节点的位置信息
- LocatedBlock addBlock(String src, String clientName,
- ExtendedBlock previous, DatanodeInfo[] excludeNodes, long fileId,
- String[] favoredNodes, EnumSet<AddBlockFlag> addBlockFlags)
- throws IOException;
- // 当客户端上传的文件所有的数据块上传完毕,会调用complete()通知namenode,并且满足最小的副本数是1的时候那么返回true
- boolean complete(String src, String clientName,
- ExtendedBlock last, long fileId)
- throws IOException;
上面5个方法是客户端写文件必须调用的方法。
下面的方法是异常的情况
- // 当客户端上传文件时发现这个数据块的数据节点无法建立连接的时候会调用abandonBlock()
- // 并且返回不能建立连接的数据块给namenode避免下一次分配到
- void abandonBlock(ExtendedBlock b, long fileId,
- String src, String holder)
- throws IOException;
命名空间管理的相关方法


集群的安全模式方法
- // 在namenode满足数据块最小副本数据块达到一定比例之前,不接受客户端的请求,也不会触发datanode
- // 任何副本的复制
- boolean setSafeMode(HdfsConstants.SafeModeAction action, boolean isChecked)
- throws IOException;
ClientDatanodeProtocol
ClientDatanodeProtocol主要是客户端和datanode通信,它的方法相对于比较简单,如下
- // 获取文件的真实长度
- long getReplicaVisibleLength(ExtendedBlock b) throws IOException;
- // 读取文件的优化,作用是在读取文件的时候先查看本地有没有
- BlockLocalPathInfo getBlockLocalPathInfo(ExtendedBlock block,
- Token<BlockTokenIdentifier> token) throws IOException;
- // 使得datanode重新的加载配置文件,删除停止使用的块池文件
- void refreshNamenodes() throws IOException;
- // 删除对应的块池
- void deleteBlockPool(String bpid, boolean force) throws IOException;
- // 关闭数据节点
- void shutdownDatanode(boolean forUpgrade) throws IOException;
- // 得到datanode的信息
- DatanodeLocalInfo getDatanodeInfo() throws IOException;
- // 触发datanode异步加载配置
- void startReconfiguration() throws IOException;
DatanodeProtocol
datanode会使用这个接口先namenode发送握手,注册,心跳,进行全量或增量数据汇报,一个完整的启动操作有下面的4个步骤
- 调用versionRequest()与namenode进行握手
- 调用registerDatanode()向namenode注册当前的datanode
- 调用blockReport()汇报Datanode上面存储的数据块
- 最后调用cacheReport()汇报datanode缓存的所有数据块
versionRequest()主要的作用就是获取namenode的信息比如集群信息,版本信息,数据块池信息,然后datanode会对比自己的信息是否匹配,如果匹配那么就握手成功
datanode调用registerDatanode()汇报自己的信息给namenode,然后调用blockReport()汇报自己的块信息
HDFS主要流程
HDFS读流程
- 打开hdfs文件:首先调用DistributedFileSystem.open(),底层调用的是ClientProtocol.open()得到文件的元数据信息
- 从namenode获取datanode的地址:namenode返回这个数据块的datanode地址并且按数据块的位置进行排序返回给客户端。然后客户端就可以选择一个最后的节点建立连接获取信息
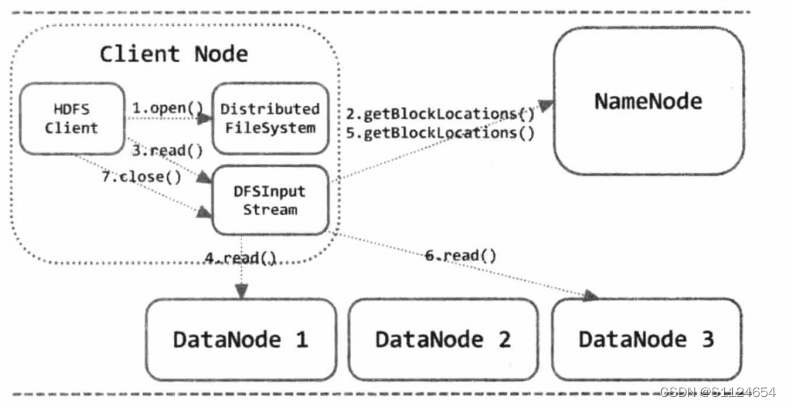
- datanode建立连接后会建立数据传输连接,当最后一个数据包接受完一会,client会在一次调用 ClientProtocol.getBlockLocations()获取下一个数据节点的最优的距离进行读取
- 最后数据传输完以后会调用HdfsDataInputStream.close()关闭连接
如果出现读取文件错误的时候,client会通过DFSInputStream读取下 一个节点的信息,注意,读取文件的时候除了有数据块的信息以外,还有数据的校验信息,如果client读取到的数据的校验信息错误时,client会通过ClientProtocol.reportBadBlocks()汇报给namenode错误块的信息,使得namenode会删除对应错误的副本,创建新的副本
HDFS客户端写流程
介绍完读流程以后,我们来看一下客户端的写流程
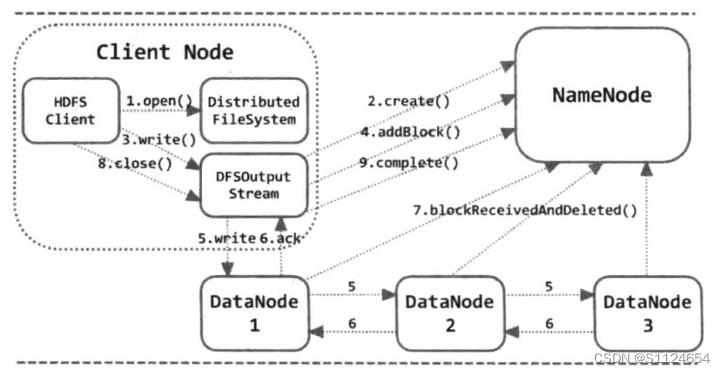
- 创建文件:client会调用DistributedFileSystem.create()底层执行的是ClientProtocol.create()通知namenode在指定的目录创建一个新的文件,然后这个操作会记录到editlog中,完成操作以后会返回一个HdfsDataOutputStream对象,里面封装的是DFSOutputStream,真正执行操作的是DFSOutputStream对象。
- 建立数据通道:由于DistributedFileSystem.create()只是创建了一个空的文件夹,并没有申请任何的数据块,所以DFSOutputStream会首先调用ClientProtocol.addBlock()先namenode申请新的数据块,当namenode返回数据块的位置信息以后那么client就可以建立通道写入数据了
- 写入数据的时候先写入到数据流的缓存块中,然后通过切分数据得到一个个数据包(packet),然后发送给datanode,datanode接受到数据以后先验证校验合看数据是否正确,如果正确那么就ack,这个packet就可以从数据流的缓存中删除了,如果数据块满了以后会调用addBlock()申请一个新的数据块,执行上面的循环。
- 当文件都传输完以后就会调用ClientProtocol.complete()通知namenode提交这个文件的所有的数据块,也就完成了整个数据的写入操作
如果在写入的过程中发生了错误,client会断开连接,并且汇报给namenode建立新的连接
Datanode启动、心跳以及执行名字节点指令流程
上面介绍了客户端的流程,下面介绍datanode和namenode的交互流程
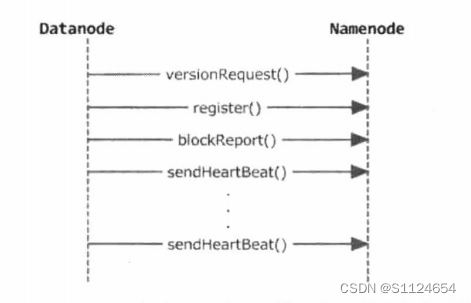
Datanode启动后与Namenode的交互主要包括三个部分:①握手;②注册:③块汇报以
及缓存汇报。- Datanode启动时会首先通过DatanodeProtocol..versionRequest()获取Namenode的版本
号以及存储信息等,然后Datanode会对Namenode的当前软件版本号和Datanode的
当前软件、版本号进行比较,确保它们是一致的。 - 成功地完成握手操作后,Datanode会通过DatanodeProtocol.register()方法向Namenode
注册。Namenode接收到注册请求后,会判断当前Datanode的配置是否属于这个集
群,它们之间的版本号是否一致。 - 注册成功之后,Datanode就需要将本地存储的所有数据块以及缓存的数据块上报到
Namenode,Namenode会利用这些信息重新建立内存中数据块与Datanode之间的对
应关系。
HA切换流程
HDFS的高可用(High Availability,HA)方案就是为了解决上述问题而产生的,在HA HDFS集群中会同时运行两个Namenode,一个作为活动
的(Active)Namenode,一个作为备份的(Standby)Namenode。Active Namenode的命名空
间与Standby Namenode是实时同步的,所以当Active Namenode发生故障而停止服务时,
Standby Namenode可以立即切换为活动状态,而不影响HDFS集群的服务。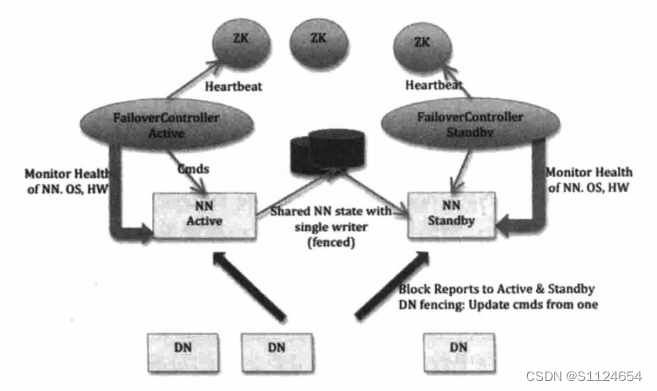
Hadoop RPC
RPC框架的结构,主要包括以下几部分。
- 通信模块:传输RPC请求和响应的网络通信模块,可以基于TCP协议,也可以基于
UDP协议,可以是同步的,也可以是异步的。 - 客户端Sub程序:服务器和客户端都包括Sub程序。在客户端,Sub程序表现得就
像本地程序一样,但底层却会将调用请求和参数序列化并通过通信模块发送给服务
器。之后Sub程序会等待服务器的响应信息,将响应信息反序列化并返回给请求程序。 - 服务器端Sub程序:在服务器端,Sub程序会将远程客户端发送的调用请求和参数
反序列化,根据调用信息触发对应的服务程序,然后将服务程序返回的响应信息序
列化并发回客户端。 - 请求程序:请求程序会像调用本地方法一样调用客户端Sub程序,然后接收Sub
程序返回的响应信息 - 服务程序:服务器会接收来自Sub程序的调用请求,执行对应的逻辑并返回执行结果。

Hadoop RPC使用慨述
图2-6给出了DFSClient调用ClientProtocol.rename()方法的流程图。我们首先看一下RPC
协议的定义部分。ClientProtocol协议定义了HDFS客户端与名字节点交互的所有方法,但是
ClientProtocol协议中方法的参数是无法在网络中传输的,需要对参数进行序列化操作,所以
HDFS又定义了ClientNamenodeProtocolPB协议。ClientNamenodeProtocolPB协议包含了
ClientProtocol定义的所有方法,但是参数却是使用protobuf序列化后的格式。这里还是以
rename()方法为例,ClientNamenodeProtocolPB将ClientProtocol中rename(String,String)方法
的两个参数抽象成一个RenameRequestProto对象,rename()方法的签名也就变成了
renamet(RenameRequestProto)。这里的RenameRequestProto对象是通过protobuf序列化后的对象,是可以在网络上传输的对象。

-
相关阅读:
数据结构-堆
Phoenix创建Hbase二级索引_尚硅谷大数据培训
MySQL索引和优化的理解学习
神经网络算法入门书籍,神经网络相关书籍
定时器事件和随机数
Day46-50:统计图表项目总结
Nginx代理配置详解
一文学会线程池、任务调度的使用
使用 Redis 实现生成分布式全局唯一ID(使用SpringBoot环境实现)
分布式限流:Redis
- 原文地址:https://blog.csdn.net/S1124654/article/details/125532853
