-
Python 通过selniumwire调用企查查原生接口抓取企查查公开企业信息全过程——以抓取成都500万家企业为例
Python抓取数据解析有两种模式,一种是网站前后端融合的情况,利用Beautiful Soup 来解析,即网页显示有什么就能抓取什么,这种方法缺陷是解析速度慢,以及网页结构可能变化要随时修正脚本。另一种是针对前后端分离的情况,网站后端通过接口返回数据给前端解析显示,这种时候我们只需要抓到这个接口,再发起请求就可以得到数据字段比页面显示更丰富、格式更标准的数据。
企查查就是前后端分离的网站,在发起请求时会调用自身的接口返回数据给前端,如果是普通网站这时候我们已经可以通过浏览器F12观察接口的header,在脚本里构造好带cookies、header、请求参数params的get/post请求。这里使用企查查的高级查询功能调用接口,需要开通个普通vip才可使用高级查询功能,但比直接导出企查查所有数据好很多了,直接导出数据额外购买数据会员几千元且每天只能导出10W条。



但企查查作为盈利网站,接口都是按调用次数卖钱的,所以在脚本里直接用request请求接口时候会发现,接口只可用一次,每次只返回20条数据。这是因为请求里含分页信息,每页只返回20条,获取更多则需要在请求参数里填写请求第二页第三页。而我们脚本利用构造的请求时,只会返回当页请求,无法返回第二页第三页,仔细观察,原来是请求头headers中构造了一个企查查的自定义字段,每次发起新请求时(包括请求其他页数)该字段都会变化,所以脚本无法直接利用request请求所有数据。

但是我们在浏览器里访问的时候,是可以手动点击下一页下一页的,所以我们可以采用selnium来模拟浏览器的操作,来获得每次请求时网站生成的header中随机自定义字段,再利用request请求调用企查查原生接口获得返回数据。selnium是用脚本模拟人操作浏览器的工具,可以做到和人工操作一样,来完成一些纯请求脚本不好做的事情,支持多种浏览器,这里下载一个谷歌浏览器,再下载对应谷歌浏览器版本的selnium驱动放到Python文件夹里即可。我们在这里除了要模拟浏览器操作,还需要获取请求头headers的信息,所以我们要用的是selniumwire,可以理解为selnium加强版。
技术路径准备好后,考虑抓取流程,企查查即使在浏览器里查看,每次最多也只会返回5000条数据,所以要把这500多W条抓完,就必须把数据分段,这里可以使用企业注册日期来分段,使得每个日期区间的企业数量在5000条内即可,然后脚本中模拟人工查询、翻页操作,再调用request请求解析最后写入数据库。
首先我们要做日期分段功能,把日期切分到每段区间不超过5000条。人工观察了下,越早注册的企业越少,后期成都注册的企业一天就几千条了,所以我按照时间来粗分。2003年以前,以30天为分段;2003-2015以5天为分段;2015以后,每天为分段。期间如果多天分段的大于5000条则进一步拆分为每天分段,如果每天也大于5000则记录到日志中跳过,如果某段结果小于1000条,则扩展该段日期。
导入和定义一些基础信息
- from ast import keyword
- from asyncio.windows_events import NULL
- from cgitb import small
- from cmath import e
- from ctypes import addressof
- from email import header
- import email
- import errno
- import json
- from nturl2path import url2pathname
- from os import stat
- from pickletools import long1
- from re import S
- import string
- from tkinter import E
- from tracemalloc import start
- from turtle import st
- from urllib.error import HTTPError
- import winreg #windows相关库
- #加载自动化测试模块
- #from selenium import webdriver
- from bs4 import BeautifulSoup #网页解析库
- import urllib.request #请求库
- import requests
- #from lxml import etree
- import time
- import pymysql
- #加载自动化测试模块
- from seleniumwire import webdriver
- from selenium.webdriver.common.action_chains import ActionChains
- import gzip
- import datetime
- from selenium.webdriver.common.keys import Keys
- def get_desktop(): #获得windows桌面路径
- key = winreg.OpenKey(winreg.HKEY_CURRENT_USER,r'Software\Microsoft\Windows\CurrentVersion\Explorer\Shell Folders')
- return winreg.QueryValueEx(key, "Desktop")[0]
- log_path = get_desktop()+"\\脚本\\log\\log_抓企查查通过搜索抓基础信息.txt"
- Paging_path = get_desktop()+"\\脚本\\config\\config_抓企查查通过搜索抓基础信息_分页.txt"
- Paging_log_path = get_desktop()+"\\脚本\\log\\log_抓企查查通过搜索抓基础信息_分页_单日大于5000条的日期.txt"
- config_path = get_desktop()+"\\脚本\\config\\config_抓企查查通过搜索抓基础信息.ini"
- lastDate = datetime.datetime.now()
- lastDate = lastDate+datetime.timedelta(days=-15)
定义一些selium操作浏览器时选择、点击相关元素的基础方法
- # 利用异常捕获和递归实现网络延迟下的稳定抓取
- def find_element_by_css_selector(driver,id):
- try:
- get = driver.find_element_by_css_selector(id)
- except:
- time.sleep(0.2)
- get = find_element_by_css_selector(driver,id)
- return get
- # 利用异常捕获和递归实现网络延迟下的稳定抓取
- def find_element_by_class_name(driver,id):
- try:
- get = driver.find_element_by_class_name(id)
- except:
- time.sleep(0.2)
- get = find_element_by_class_name(driver,id)
- return get
- # 利用异常捕获和递归实现网络延迟下的稳定抓取
- def find_element_by_link_text(driver,id):
- try:
- get = driver.find_element_by_link_text(id)
- except:
- time.sleep(0.2)
- get = find_element_by_link_text(driver,id)
- return get
- # 利用异常捕获和递归实现网络延迟下的稳定抓取
- def find_element_by_xpath(driver,id):
- try:
- get = driver.find_element_by_xpath(id)
- except:
- time.sleep(0.2)
- get = find_element_by_xpath(driver,id)
- return get
- def find_element_by_css_selector2(driver,id,ele):
- try:
- get = driver.find_element_by_css_selector(id)
- except:
- ele.click()
- time.sleep(1)
- get = find_element_by_css_selector2(driver,id,ele)
- return get
主程序流程:打开企查查,自动登录帐号,手动操作通过验证码,然后自动进入高级查询查询成都企业数据,然后执行把日期分段到每段5000条结果内的操作
- if __name__ == '__main__':
- Paging_logfile = open(Paging_log_path,'a+',encoding='utf8',buffering=1)
- Paging_file = open(Paging_path,'a+',encoding='utf8',buffering=1)
- print(lastDate)
- driver = webdriver.Chrome()
- driver.get("https://www.qcc.com/weblogin")
- ele_login = find_element_by_class_name(driver,"login-change")
- ele_login.click()
- ele_login2 = find_element_by_link_text(driver,"密码登录")
- ele_login2.click()
- inputs = driver.find_elements_by_tag_name("input")
- for input in inputs:
- if "phone-number"==input.get_attribute("name"):
- ele_username = input
- if "password"==input.get_attribute("name"):
- ele_password = input
- ele_username.send_keys("你的帐号")
- ele_password.send_keys("你的密码")
- inputs =driver.find_elements_by_tag_name("button")
- for input in inputs:
- #print(input.get_attribute("id")+" | "+ input.get_attribute("name")+" | "+input.get_attribute("class"));
- if "btn btn-primary login-btn"==input.get_attribute("class"):
- ele_login3 = input
- ele_login3.click()
- find_element_by_css_selector(driver,"#searchKey")
- driver.get("https://www.qcc.com/web/search/advance")
- ele_select1 = find_element_by_css_selector(driver,"body > div:nth-child(2) > div.app-search-advance > div.fixed-bottom > div > div > a.btn.btn-default.m-r")
- ele_select1.click()
- ele_select2 = find_element_by_css_selector(driver,"body > div.app-nmodal.modal.fade.in > div > div > div.modal-body > div > section > ul > div:nth-child(1) > div > div.pull-left > div.title")
- ele_select2.click()
- ele_select3 = find_element_by_link_text(driver,"重新选择")
- ele_select3.click()
- time.sleep(2)
- ele_select4 = find_element_by_xpath(driver,"/html/body/div[1]/div[2]/div[1]/div/div/div[2]/div[6]/div[1]/div[2]/div[8]/label")
- ele_select4.click()
- ele_startDate = find_element_by_css_selector(driver,"body > div:nth-child(24) > div > div > div > div > div.ant-calendar-date-panel > div.ant-calendar-range-part.ant-calendar-range-left > div.ant-calendar-input-wrap > div > input")
- ele_endDate = find_element_by_css_selector(driver,"body > div:nth-child(24) > div > div > div > div > div.ant-calendar-date-panel > div.ant-calendar-range-part.ant-calendar-range-right > div.ant-calendar-input-wrap > div > input")
- getPagingFile(datetime.datetime.strptime("1800-01-01", "%Y-%m-%d"),datetime.datetime.strptime("1980-10-01", "%Y-%m-%d"),ele_startDate,ele_endDate)
- print("结束数量抓取")
这里面有两个关键方法,一个是获取接口返回的时间短内企业数量getCountResonseByRequests,一个是根据日期和日期区间内企业数量来划定最终日期区间方法getPagingFile。
getCountResonseByRequests参数(reqs,startDate,endDate) ,reqs是所有请求参数,通过selniumwire获取的请求头是打开浏览器后的所有headers,所以需要筛选我们需要的请求的最新的headers,startDate,endDate是日期区间的开始与结束日期
- #获取request请求列表的返回数据,一定要有返回结果,避免网络延迟无返回结果
- def getCountResonseByRequests(reqs,startDate,endDate):
- startDate = startDate.replace("-","")
- endDate = endDate.replace("-","")
- #print(startDate)
- for req in reqs:
- if ((str)(req.body).find(endDate)>0) and ((str)(req.body).find(startDate)>0):
- try:
- #driver里的请求参数是对的但不会返回后面页数请求的结果,所以必须取出后面页的header再重新发起post请求
- res=requests.post("https://www.qcc.com/api/search/searchCount",data=req.body,headers=req.headers).text
- print(req.body)
- data = json.loads(res)
- if 'Result' not in data:
- return 0
- count = data['Result']
- count = count['Count']
- #print(count)
- return count
- except:
- #用异常捕获并延迟等待循环请求返回数据,否则请求有了返回数据还无
- time.sleep(1)
- getCountResonseByRequests(reqs,startDate,endDate)
getPagingFile参数(startDate,endDate,ele_startDate,ele_endDate)是开始结束日期,与浏览器中开始结束日期输入框元素的位置。
- #把结果分为5000页内日期区间
- def getPagingFile(startDate,endDate,ele_startDate,ele_endDate):
- startDateSTR = (str)(startDate)[:10]
- endDateSTR = (str)(endDate)[:10]
- if endDate<=lastDate: ele_startDate.send_keys(Keys.CONTROL,'a') time.sleep(0.2) ele_startDate.send_keys(Keys.BACK_SPACE) ele_startDate.send_keys(startDateSTR) ele_endDate.send_keys(Keys.CONTROL,'a') time.sleep(0.2) ele_endDate.send_keys(Keys.BACK_SPACE) ele_endDate.send_keys(endDateSTR) #temp = find_element_by_css_selector(driver,"body > div:nth-child(2) > div.app-search-advance > div.container.m-t > div > div > div.npanel-body > div:nth-child(5) > span")
- #temp.click()
- count=None
- while count==None:
- time.sleep(1)
- reqs = driver.requests
- reqs.reverse()
- count = getCountResonseByRequests(reqs,startDateSTR,endDateSTR)
- #2003年以前,以30天为分段;2003-2015以5天为分段;2015以后,每天为分段。期间如果多天分段的大于5000条则进一步拆分为每天分段,如果每天也大于5000则记录到日志中跳过
- if endDate<datetime.datetime.strptime("2003-01-01", "%Y-%m-%d"):
- if count<1000: endDate = endDate+datetime.timedelta(days=15) getPagingFile(startDate,endDate,ele_startDate,ele_endDate) elif count>5000:
- #当区间断大于5000条结果,则按每天来分段,若每天里还有大于5000的,记录并跳过
- if (endDate != startDate):
- endDate=startDate
- getPagingFile(startDate,endDate,ele_startDate,ele_endDate)
- else:
- print(startDateSTR+"-"+endDateSTR+"超过5000,请手动查看处理")
- Paging_logfile.write(startDateSTR+"-"+endDateSTR+"超过5000,请手动查看处理"+"\n")
- startDate = endDate+datetime.timedelta(days=1)
- endDate=startDate
- getPagingFile(startDate,endDate,ele_startDate,ele_endDate)
- else:
- print(startDateSTR+" "+endDateSTR+" "+(str)(count))
- Paging_file.write(startDateSTR+" "+endDateSTR+" "+(str)(count)+"\n")
- startDate = endDate+datetime.timedelta(days=1)
- endDate=endDate+datetime.timedelta(days=31)
- getPagingFile(startDate,endDate,ele_startDate,ele_endDate)
- elif endDate<datetime.datetime.strptime("2015-01-01", "%Y-%m-%d"):
- if count<1000: endDate = endDate+datetime.timedelta(days=5) getPagingFile(startDate,endDate,ele_startDate,ele_endDate) elif count>5000:
- #当区间断大于5000条结果,则按每天来分段,若每天里还有大于5000的,记录并跳过
- if (endDate != startDate):
- endDate=startDate
- getPagingFile(startDate,endDate,ele_startDate,ele_endDate)
- else:
- print(startDateSTR+"-"+endDateSTR+"超过5000,请手动查看处理")
- Paging_logfile.write(startDateSTR+"-"+endDateSTR+"超过5000,请手动查看处理"+"\n")
- startDate = endDate+datetime.timedelta(days=1)
- endDate=startDate
- getPagingFile(startDate,endDate,ele_startDate,ele_endDate)
- else:
- print(startDateSTR+" "+endDateSTR+" "+(str)(count))
- Paging_file.write(startDateSTR+" "+endDateSTR+" "+(str)(count)+"\n")
- startDate = endDate+datetime.timedelta(days=1)
- endDate=endDate+datetime.timedelta(days=6)
- getPagingFile(startDate,endDate,ele_startDate,ele_endDate)
- else:
- if count<1000: endDate = endDate+datetime.timedelta(days=1) getPagingFile(startDate,endDate,ele_startDate,ele_endDate) elif count>5000:
- print(startDateSTR+"-"+endDateSTR+"超过5000,请手动查看处理")
- Paging_logfile.write(startDateSTR+"-"+endDateSTR+"超过5000,请手动查看处理"+"\n")
- startDate = endDate+datetime.timedelta(days=1)
- endDate=startDate
- getPagingFile(startDate,endDate,ele_startDate,ele_endDate)
- else:
- print(startDateSTR+" "+endDateSTR+" "+(str)(count))
- Paging_file.write(startDateSTR+" "+endDateSTR+" "+(str)(count)+"\n")
- #如果抓取了所有日期结果分段,则结束数量抓取方法
- if endDate==lastDate:
- return
- startDate = endDate+datetime.timedelta(days=1)
- endDate=startDate
- getPagingFile(startDate,endDate,ele_startDate,ele_endDate)
- else:
- getPagingFile(startDate,lastDate,ele_startDate,ele_endDate)
这个过程完成后后,我们就可以获得写入txt的日期分段,每行数据是日期区间的开始日期、结束日期、日期区间内企业数量

然后再开始按遍历所有日期区间开始一页页抓取调用企查查原生接口searchmulti,这里写一个解析该接口结果的方法
- #获取request请求列表的返回数据,一定要有返回结果,避免网络延迟无返回结果
- def getResonseByRequests(reqs,page):
- strPage = ""pageIndex":"+(str)(page)
- for req in reqs:
- if ((str)(req.body).find(""pageSize":40")>0) and (str)(req.body).find(strPage)>0:
- try:
- #driver里的请求参数是对的但不会返回后面页数请求的结果,所以必须取出后面页的header再重新发起post请求
- res=requests.post("https://www.qcc.com/api/search/searchMulti",data=req.body,headers=req.headers).text
- print(req.body)
- #print("获取数据中")
- #print(res)
- return res
- except:
- #用异常捕获并延迟等待循环请求返回数据,否则请求有了返回数据还无
- time.sleep(1)
- getResonseByRequests(reqs,page)
主程序里开始解析每个日期区间的结果并写入数据库
- Paging_file = open(Paging_path,'r',encoding='utf8')
- dateRanges=Paging_file.readlines()
- for dateRange in dateRanges:
- startDateSTR = dateRange.split()[0]
- endDateSTR = dateRange.split()[1]
- ele_temp = driver.find_elements_by_link_text("重置筛选")
- if ele_temp == []:
- #滚动到浏览器顶部
- js_top = "var q=document.documentElement.scrollTop=0"
- driver.execute_script(js_top)
- ele_select3 = find_element_by_link_text(driver,"重新选择")
- ele_select3.click()
- time.sleep(2)
- ele_select4 = find_element_by_xpath(driver,"/html/body/div[1]/div[2]/div[1]/div/div/div[2]/div[6]/div[1]/div[2]/div[8]/label")
- ele_select4.click()
- inputs =driver.find_elements_by_class_name("ant-calendar-input")
- ele_startDate = inputs[0]
- ele_endDate = inputs[1]
- ele_startDate.send_keys(Keys.CONTROL,'a')
- time.sleep(0.2)
- ele_startDate.send_keys(Keys.BACK_SPACE)
- ele_startDate.send_keys(startDateSTR)
- ele_endDate.send_keys(Keys.CONTROL,'a')
- time.sleep(0.2)
- ele_endDate.send_keys(Keys.BACK_SPACE)
- ele_endDate.send_keys(endDateSTR)
- ele_temp = find_element_by_css_selector(driver,"body > div:nth-child(2) > div.app-search-advance > div.container.m-t > div > div > div.npanel-body > div:nth-child(5) > span")
- ele_temp.click()
- #点击查找
- ele_select5 = find_element_by_css_selector(driver,"body > div:nth-child(2) > div.app-search-advance > div.fixed-bottom > div > div > a.btn.btn-primary")
- ele_select5.click()
- #每页显示40条结果
- temp = ""
- while temp.find("40")<0:
- ele_select6 = find_element_by_css_selector2(driver,"body > div:nth-child(2) > div.app-search-advance > div > nav > ul > li.size-change > a",ele_select5)
- temp = ele_select6.text
- ele_select6.click()
- ele_select7 = find_element_by_css_selector2(driver,"body > div:nth-child(2) > div.app-search-advance > div > nav > ul > li.size-change.open > div > a:nth-child(3)",ele_select6)
- ele_select7.click()
- time.sleep(0.5)
- temp = 0
- while 1:
- temp+=1
- #等待加载出请求的数据结果为止
- res=None
- while res==None:
- time.sleep(1)
- reqs = driver.requests
- reqs.reverse()
- res = getResonseByRequests(reqs,temp)
- data = json.loads(res)
- if 'Result' in data:
- lists = data['Result']
- for list in lists:
- Name = list['Name']
- KeyNo = list['KeyNo']
- No = list['No']
- CreditCode = list['CreditCode']
- OperName= list['OperName']
- ShortStatus= list['ShortStatus']
- #毫秒级时间戳转为日期
- StartDate= list['StartDate']
- timestamp = StartDate
- # 转换成localtime
- try:
- time_local = time.localtime(timestamp/1000)
- # 转换成新的时间格式(精确到秒)
- dt = time.strftime("%Y-%m-%d %H:%M:%S", time_local)
- d = datetime.datetime.fromtimestamp(timestamp/1000)
- StartDate = d.strftime("%Y-%m-%d")
- except:
- #1970年以前日期是另外公式
- timestamp = timestamp/1000
- StartDate = datetime.datetime(1970, 1, 1) + datetime.timedelta(seconds=timestamp+8*3600)
- StartDate = StartDate.strftime("%Y-%m-%d")
- Address = list['Address']
- RegistCapi = list['RegistCapi']
- ContactNumber= list['ContactNumber']
- Email= list['Email']
- strGW= list['GW']
- EconKind = list['EconKind']
- strX = list['X']
- strY= list['Y']
- Area= list['Area']
- City = ""
- if 'City' in Area:
- City= Area['City']
- County = ""
- if 'County' in Area:
- County = Area['County']
- Industry = list['Industry']
- SubIndustry = ""
- MiddleCategory = ""
- SmallCategory = ""
- if 'SubIndustry' in Industry:
- SubIndustry= Industry['SubIndustry']
- if 'MiddleCategory' in Industry:
- MiddleCategory = Industry['MiddleCategory']
- if 'SmallCategory' in Industry:
- SmallCategory = Industry['SmallCategory']
- Industry= Industry['Industry']
- Tag= list['Tag']
- Tag = Tag.replace("\t"," ")
- TagsInfos = list['TagsInfo']
- TagsInfosStr =""
- if TagsInfos!=None:
- for TagsInfo in TagsInfos:
- TagsInfo = TagsInfo['n']
- TagsInfosStr=TagsInfosStr+TagsInfo+" "
- # print(Name)
- try:
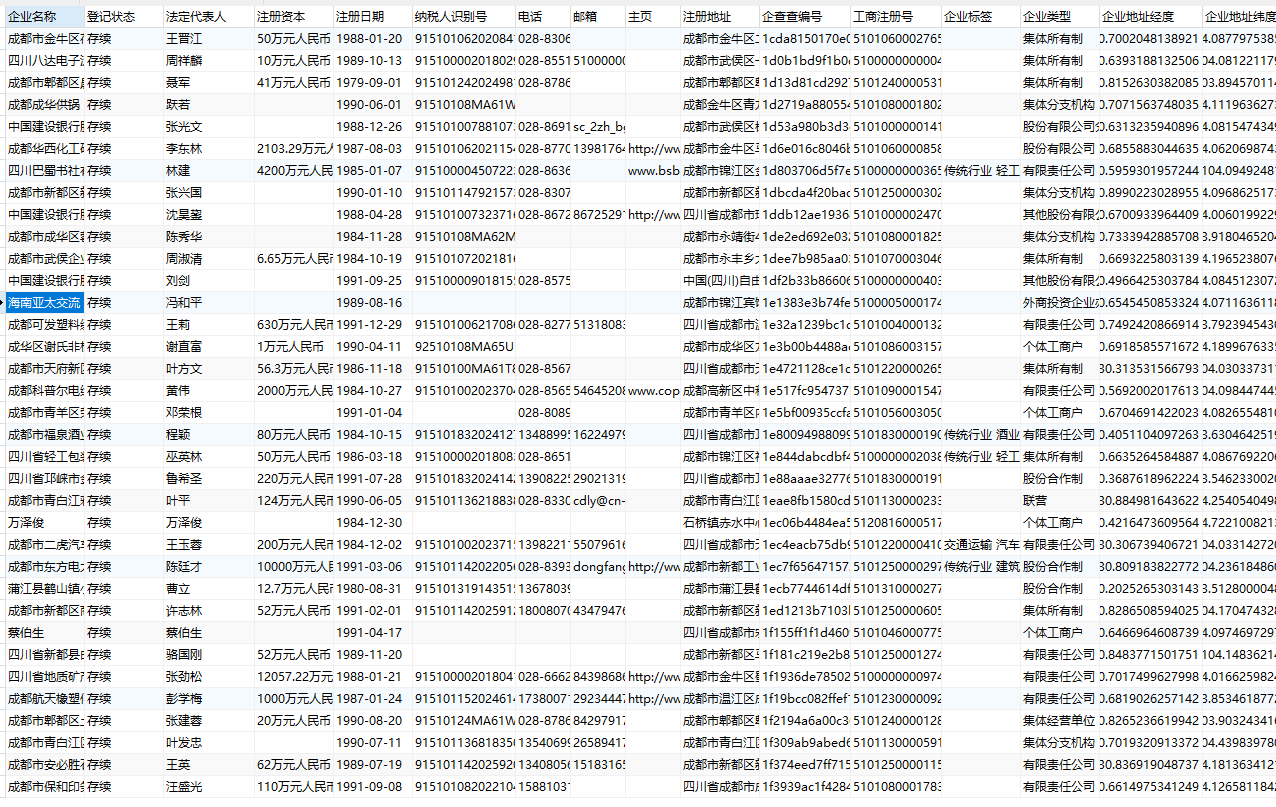
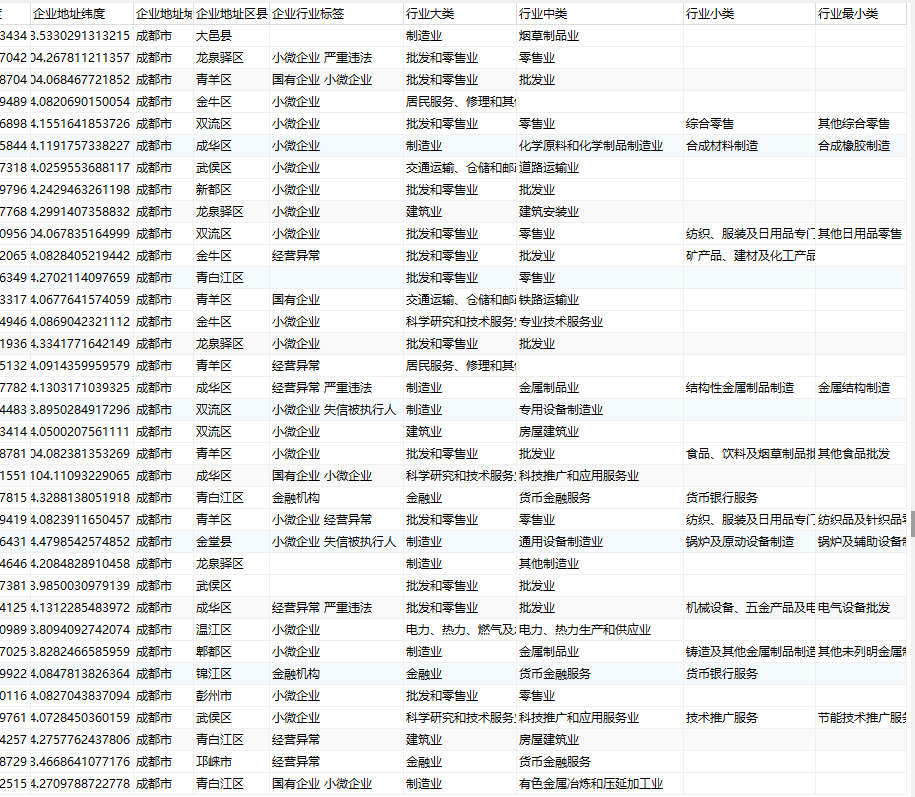
- insertSQLString = "INSERT IGNORE INTO `企业信息`.`成都企业信息库`(`企业名称`, `登记状态`, `法定代表人`, `注册资本`, `注册日期`, `纳税人识别号`, `电话`, `邮箱`, `主页`, `注册地址`, `企查查编号`, `工商注册号`, `企业标签`, `企业类型`, `企业地址经度`, `企业地址纬度`, `企业地址城市`, `企业地址区县`, `企业行业标签`, `行业大类`, `行业中类`, `行业小类`, `行业最小类`) VALUES ('{}','{}','{}','{}','{}','{}','{}','{}','{}','{}','{}','{}','{}','{}',{},{},'{}','{}','{}','{}','{}','{}','{}');".format(Name,ShortStatus,OperName,RegistCapi,StartDate,CreditCode,ContactNumber,Email,strGW,Address,KeyNo,No,Tag,EconKind,strX,strY,City,County,TagsInfosStr,Industry,SubIndustry,MiddleCategory,SmallCategory)
- cur.execute(insertSQLString)
- conn.commit()
- except Exception as e:
- print(insertSQLString)
- print((str)(datetime.datetime.now())+"抓企查查通过搜索 写入数据库 出现异常:"+str(e)+" "+insertSQLString)
- logfile.write((str)(datetime.datetime.now())+"抓企查查通过搜索 写入数据库 出现异常:"+str(e)+" "+insertSQLString+"\n")
- #根据页数计算这批是否完结,完结后则跳出循环再选新日期
- if 'Paging' in data:
- lists = data['Paging']
- PageSize = lists['PageSize']
- PageIndex = lists['PageIndex']
- TotalRecords = lists['TotalRecords']
- #print(PageSize*PageIndex)
- if PageSize*PageIndex>TotalRecords:
- break
- #这一页解析完成后,开始进入下一页
- ele_select8 = find_element_by_link_text(driver,">")
- ele_select8.click()
- Paging_file.close()
- conn.close()
- logfile.close()
至此完成成都500W余家企业的抓取,全过程基本自动化,只有脚本启动后的登录过程需要手动通过验证码,后续执行过程可能会出现几次验证码,即可自动抓取,同理可以抓取其他省市、其他限定条件的数据。
更多内容 可关注我的随笔博客
随笔自留地
-
相关阅读:
Linux - Django + Mysql + Nginx + uwsgi 部署项目 - 安装 nginx 服务器 - (1)
[量化投资-学习笔记016]Python+TDengine从零开始搭建量化分析平台-日志输出
shell之tar命令
基于C语言 -- 线程池实现
GraphQL的优势和开发模式
Java设计模式之亨元模式(Flyweight Pattern)
【D01】Django中实现带进度条的倒计时功能(简易版)
lua执行出错attempt to index global ‘ngx‘ (a nil value)[已解决]
列式数据库管理系统——ClickHouse(version:22.7.1 环境部署)
iOS AVAudioRecorder简介
- 原文地址:https://blog.csdn.net/xyydyyqf/article/details/125521378
