-
技术干货|昇思MindSpore算子并行+异构并行,使能32卡训练2420亿参数模型

由于深度学习模型的参数量越来越大,已远超单设备的内存上限,故数据并行的方式已不能满足模型训练的需求。为此,MindSpore支持算子粒度并行和异构并行。算子粒度并行统一了数据并行和模型并行:将每个算子的输入输出张量的各个维度均等看待,均看作是可切分的。为保证切分后的算子执行的语义正确性,MindSpore会在内部自动插入必要的通信算子。异构并行通过将一些内存占用大的算子放到host侧执行,其余算子在加速器(device)侧执行,依次来降低加速器的内存压力。本文首先介绍卷积单算子的切分方案,进而介绍MoE(Mixture of Expert)这个结构如何使用算子级切分实现,介绍异构并行的实现和其带来的收益。
01
卷积算子切分
超分辨率图像往往非常大,以遥感图像为例,分辨率可达4*30000*30000,一张图片约14GB,单卡受限于内存无法完成计算,需要对图片进行多机多卡的并行处理。
在训练和推理过程中,由于模型将对图片进行大量的卷积等计算,而图片的H、W维被切分后,对每个计算节点来说,可能有部分边缘特征信息存储在其他节点上。由于卷积的滑动窗口的机制,对于切分后图片边缘处的数据,MindSpore自动识别边缘特征信息的分布情况,采用相邻节点交换等通信技术对分布在周边节点上的特征信息进行整合,最终保证计算语义的正确性和网络执行结果无精度损失。具体的步骤如下:
步骤一:识别出需要获取的周边device数据。输入数据切分并分发到多个device后,每个device进行卷积计算时需要从相邻device获取缺失的数据(Overlap),如下图所示。
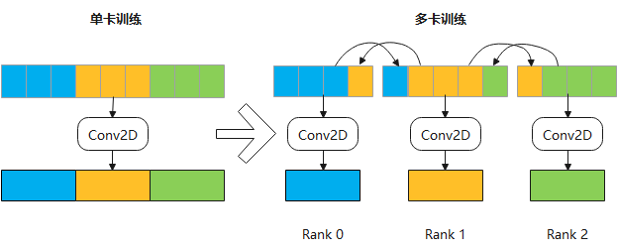
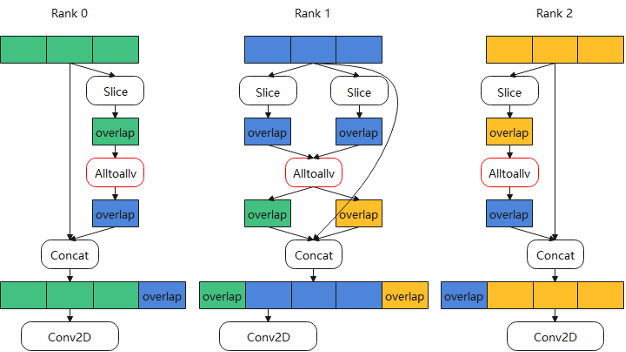
步骤二:调整模型网络结构,保证网络语义无变化。1)使用Slice从卷积的原始输入数据中提取overlap的部分;2)通过AllToAllv算子在相邻device间交换overlap数据;3)每个device将本地的数据与接收到的overlap数据进行拼接,使用拼接后的数据做卷积计算。
02
混合专家及其并行
基于Transformer扩展的大模型是当前各种大模型的主干,现在,混合专家(Mixture of Expert,MoE)结构成为扩展Transformer的一种关键技术。
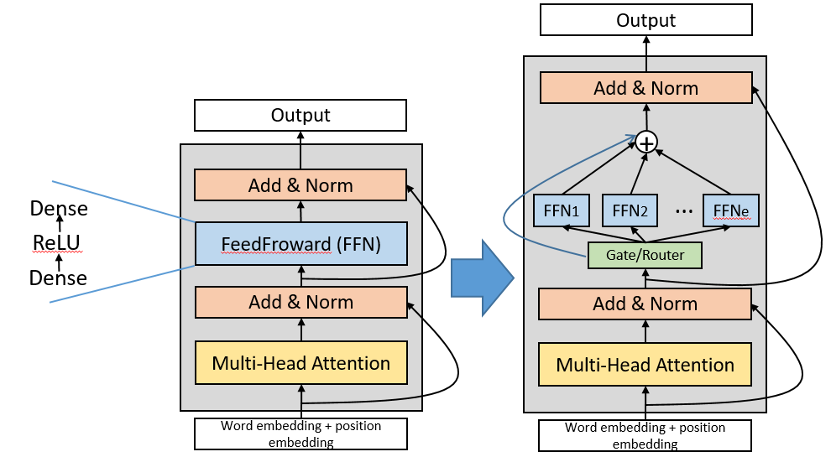
如下图所示,Transformer中每层是由Attention和FeedForward(FFN)这两个基础结构组成的(下图左半部分)。将FFN看做是一个专家(expert),MoE结构是由多个专家并行组成,其入口是一个路由器(router),负责将token分发给各个专家,可以有多种路由策略可选择(如Top,Top2等),其出口是加权求和(下图右半部分)。MoE已被验证过在多种任务上有优异的效果,是万亿以上大模型的基础结构。
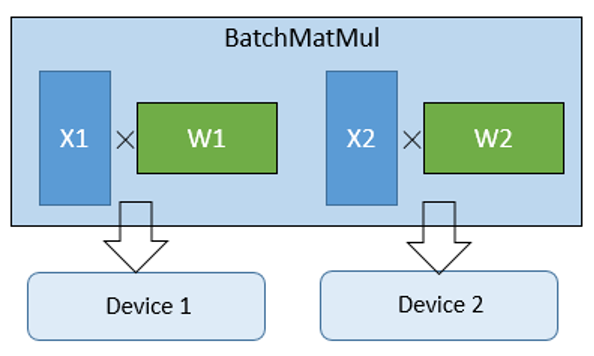
MindSpore通过算子切分的方式实现了专家并行,由于每个专家是由Dense->ReLU->Dense构成的,其中的核心是MatMul。MindSpore使用BatchMatMul扩展MatMul,第0维的大小表示专家数,将第0维切分表示将专家切分到不同设备上。如下图中,由两个MatMul构成的BatchMatMul切分到两个device上。
由于多专家在多设备上并行执行,且路由器是数据并行的,需要经过AllToAll算子将token分配到各个设备上的专家进行计算,而后,又进过AllToAll将结果汇聚。

MindSpore MoE的代码实现详见:
https://gitee.com/mindspore/mindspore/blob/r1.5/mindspore/parallel/nn
03
异构并行
受限于GPU/NPU设备的内存瓶颈,有效利用Host端的内存成为解决大模型扩展的一种可行的途径。异构并行训练方法是通过分析图上算子内存占用和计算密集程度,将内存消耗巨大和适合CPU处理的算子切分到CPU子图,将内存消耗较小计算密集的算子切分到硬件加速器子图,框架协同不同子图进行网络训练的过程,能够充分利用异构硬件特点,有效的提升单卡可训练模型规模。

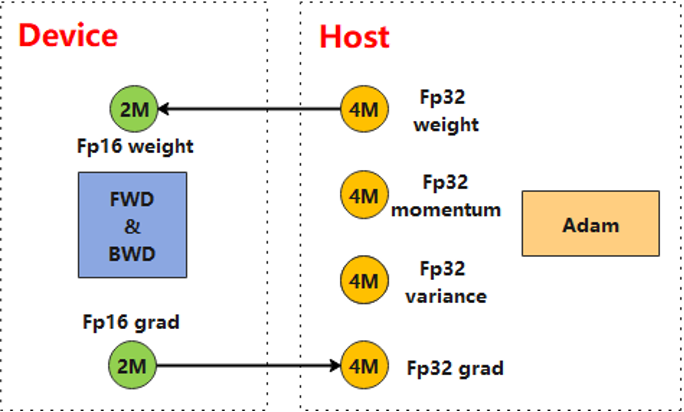
当前典型使用异构并行计算的场景有:优化器异构、Embedding异构、PS异构。对于大规模预训练模型,其主要的瓶颈往往在于参数量过大,设备显存无法存放下来。MindSpore1.5版本在处理大规模预训练网络时,可以通过优化器异构将优化器指定到CPU上,以减少优化器状态量显存占用开销,进而扩展可训练模型规模。如下图所示,将FP32的Adam优化器放置于CPU上进行运算,可以减少60%多的参数显存占用。具体的步骤为:1) 配置优化器算子到CPU执行;2) 初始化FP16的权重参数以及FP32的优化器状态变量;3) 将输入优化器的梯度转为FP16;4) 权重和梯度转为FP32参与优化器运算;5) 更新后的FP32权重赋值给FP16的权重。
更详细的优化器异构讲解、Embedding异构、PS异构可见文档:
https://www.mindspore.cn/docs/programming_guide/zh-CN/r1.5/design/heterogeneous_training.html
04
应用MoE+异构并行,实现32卡训练2420亿参数模型
我们使用MoE结构扩展鹏程·盘古模型[1],同时应用了专家并行+异构并行+数据并行+模型并行。
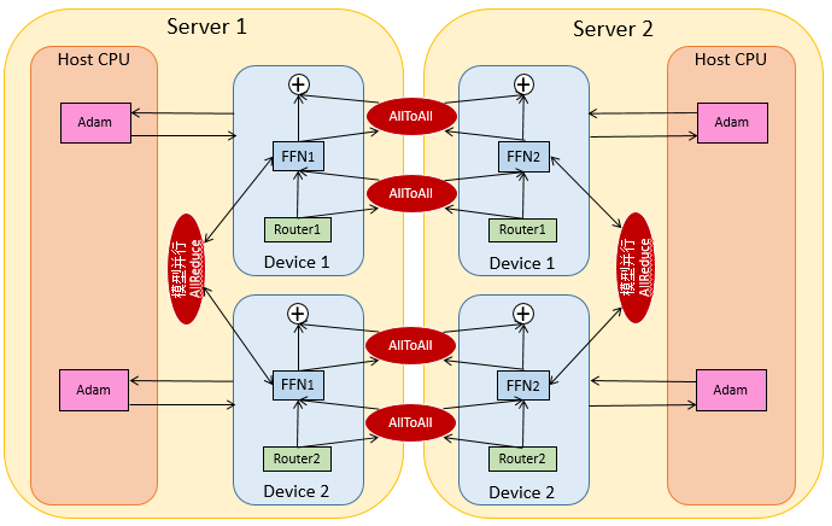
如下示意图,将优化器相关的状态及其计算放到CPU端。在MoE结构中,同时应用了模型并行和专家并行,即在同一专家会切分到Server内部,如图中Server 1上的FFN1被切分到了两个设备上,由此产生的模型并行AllReduce会发生在Server内部;而不同Server的对应设备间是数据并行(和专家并行),即Server 1上的Device 1与Server 2上的Device 1是数据并行(和专家并行),Server 1上的Device 2与Server 2上的Device 2是数据并行(和专家并行),由此产生的AllToAll会发生在Server间。AllToAll用于完成数据并行到专家并行的转换和专家并行到数据并行的转换。
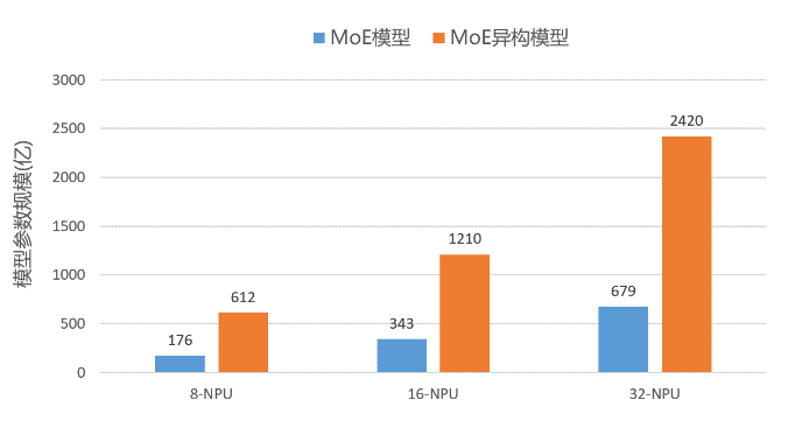
我们分别在8卡、16卡、32卡昇腾设备上验证了优化器异构和专家并行对训练模型规模提升的效果,如下图所示,使用优化器异构基本都能达到3倍的模型规模提升,在8卡上可以跑到612亿参数量,16卡上可以跑到1210亿参数量,32卡上可以跑到2420亿参数量的模型规模。
具体地,在4台Server 32卡环境中,每个专家会被分配到一台Server的8卡上, 模型并行AllReduce group的大小是8,4台Server的对应设备间是数据并行和专家并行的,AllToAll group的大小是4。
参考文献:
[1] Zeng, Wei, et al. "PanGu-$\alpha $: Large-scale Autoregressive Pretrained Chinese Language Models with Auto-parallel Computation." arXiv preprint arXiv:2104.12369 (2021).

MindSpore官方资料
GitHub : https://github.com/mindspore-ai/mindspore
Gitee : https : //gitee.com/mindspore/mindspore
官方QQ群 : 871543426
-
相关阅读:
如何提高项目决策的科学性和效率?
设计新鲜事(News Feed)系统
chrome插件-Web开发者助手 FeHelper
材料数据库设计问题
# (1462. 课程表 IV leetcode)广搜+拓扑-------------------Java实现
React@16.x(38)路由v5.x(3)其他组件
基于Spring MVC + Spring + MyBatis的【超市会员管理系统】
USB应用实战视频教程第4期:手把手玩转基于QT6.4的USB BULK上位机和下位机开发下篇(2022-11-07)
C语言实现动态版本的通讯录
信息学奥赛一本通:1158:求1+2+3+...
- 原文地址:https://blog.csdn.net/Kenji_Shinji/article/details/125513652