-
人工智能知识全面讲解:非线性支持向量机与核函数
上一节讲述了SVM的硬间隔最大化算法。它对线性可分的数据集有较好的
处理效果,但是对线性不可分的数据集则显得束手无措。那么,当面对线性不
可分的数据集时,我们该如何处理呢?
回顾第4章中的线性回归算法,我们也遇到过类似的场景。当时我们的解
决方法是将低维非线性的数据集映射到高维,数据就变成线性可分的了。这也
启发了我们,对于线性不可分的低维数据集,如果想要使用 SVM 算法,则可
以将其映射到高维,使得线性不可分的数据集变成线性可分的,这样就可以使
用SVM 算法求解了。
线性可分SVM的优化目标函数为: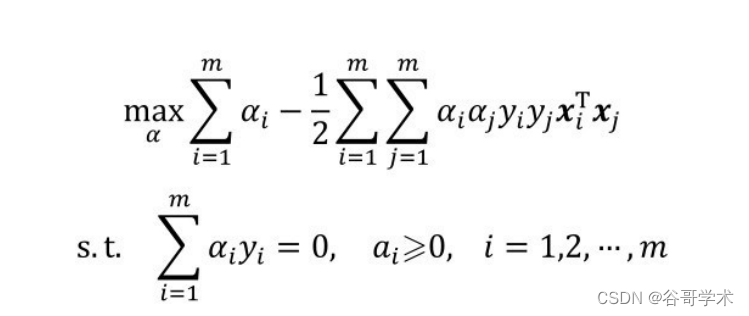
注意,上式中,低维特征以内积 x i ·x j 的形式出现。如果我们定?一
个低维特征空间到高维特征空间的映射ϕ,将所有特征映射到更高的维度,就
可以使用上述求解线性SVM的方法优化目标函数,求出分离超平面。
但是实际上我们没有办法这样求解,原因在于,如果一个数据集本身维数
就很多,那么映射到高维计算量太大,根本无法计算。假如是一个二维特征的
数据,则可以将其映射到五维做特征的内积。但如果低维特征有100个维度或
1000个维度,要将其映射到非常高的维度计算特征的内积,是不可能实现的。

可以看出,核函数大大简化了任务,使我们避免了繁杂的计算。实际上,
从低维到高维的映射,可使用的核函数不止一个。核函数的数学推导比较复
杂,在此我们不展开?述,好在前人已经帮我们找到了很多核函数,如?所
示,我们可以直接使用。
通过以上的讨论可知,我们希望样本在空间内线性可分,因此特征空间的
好坏对于SVM的性能尤为重要。但是在不知道特征映射的形式时,我们不知道
什么样的核函数才是合适的。因此在实际项目中,使用者只能多次尝试各种核
函数,选择其中效果最好的。此外,也有很多人尝试用这些核函数的线性组
合、直积等来组合成新的核函数,同样可以获得较好的效果。8.4 软间隔支持向量机
前面两节讲述的求解方法,无论是在原空间线性可分还是映射到高维空间
后线性可分,我们都是假设数据集在某种情况?线性可分。但是在实际项目
中,我们总会遇到一些噪声数据干扰模型训练的情形,一味追求数据集线性可
分可能会使模型陷入过拟合的困境,如图8-6所示。
从上图可以看出来,左边两种情况比最后一种情况的分类效果好,哪怕有
少数样本点没落在正确的类别上。我们没必要拟合出100%满足训练数据的分类
器,因为这种分类器在新数据上的表现不一定优秀,所以需要放宽对样本的要
求。
既然要放宽标准,允许部分样本点犯错,那么就要制定一个衡量标准才能
判断哪个拟合曲线的效果最好。前面我们介绍的 SVM 方法要求所有样本均满
足约束条件,即所有的样本都必须划分正确,称这种情况为“硬间隔”,硬间
隔最大化的条件为
要想让SVM容忍少数分类错误的样本,最容易的实现方法是引入一个松弛
因子ξi≥0,使函数间隔加上松弛变量大于等于1。这时候原式变为
以上式子被称为软间隔 SVM。在硬间隔 SVM 中,所有样本点到分割平面
的函数间隔都大于等于1。如今引入松弛变量,允许它们的函数间隔小于1,这
样就可以表示错误分类的样本了。并非每个样本都有松弛因子,只有误分类的
样本才有。式子中的参数C为惩罚参数,C越大,对误分类的惩罚越大;C越
小,对误分类的惩罚越小。也就是说,我们希望前面的式子尽量小,误分类的
点尽可能少。参数 C 是协调两者关系的正则化惩罚系数。在实际应用中,需
要调整该参数。
接?来的求解过程和线性可分SVM的优化过程类似,首先将软间隔最大化
的约束问题用拉格朗日函数转换为无约束问题:

软间隔SVM的结果与硬间隔SVM的结果相比,就是在限制条件中增加了一个
上限,即α i ≤C。软间隔SVM也可以用于非线性支持向量机,只需要将内积改
为核函数即可。软间隔支持向量的代价函数既考虑了样本分类误差,又考虑了
模型的复杂度,并且调节其中的参数C可以使函数既能够兼顾训练集上的分类
精度及模型复杂度,又能使模型泛化能力增加。因此,在实际项目中所使用的
SVM分类器基本上属于这一类。
8.5 支持向量机的不足之处
前面讲述了线性SVM、非线性SVM以及软间隔SVM的应用与推导过程。支持
向量机虽然诞生只有短短20余年,但由于它良好的分类性能、适应性与学习能
力,一度成为传统机器学习中最为强大的分类方法。
但是后来,随着硬件设备逐步提升以及数据量日益增长,神经网络与深度
学习后来居上,这才打破了机器学习界“一超多强”的状况。再后来各类集成
学习算法涌现,它们更是在表现效果上全面超越支持向量机算法,成为目前解
决复杂分类问题的首选。与这些算法相比,支持向量机主要有以?两个方面的
不足:
(1)对缺失数据敏感,对参数和核函数的选择敏感。在实际项目中,SVM
性能的优劣主要取决于选取的核函数。如何根据实际的数据模型选择合适的核
函数,从而构造SVM算法目前没有统一的标准。通常情况?根据工程师的经验
来选取,带有一定的随意性。
(2)SVM算法对大规模训练集难以适应。SVM算法最耗费资源的地方在
于,它需要存储训练样本和核矩阵。由于SVM算法借助二次规划来求解支持向
量,而求解二次规划涉及m阶矩阵的计算(m为样本的个数),当m数目很大时
该矩阵的存储和计算将耗费大量的机器内存和运算时间。
尽管如此,支持向量机的原理、想法的形式化过程以及求解思路仍然有研
究价值,值得我们深入了解与学习。通过对SVM算法的学习,产品经理能够对
数学与人工智能之间的联系有更深入的认识。 -
相关阅读:
专项技能训练五《云计算网络技术与应用》实训6-1:安装OpenDayLight控制器
适合企业的TTS文本转语音接口:微软TTS最新模型,发布9种更真实的AI语音
汽车电子电气TARA分析从入门到放弃
程序员从网上抄代码,被老板发现后....
如何写出易于维护的Vue代码(踩坑经验)
3.5 数据更新
选择最适合您的Bug管理软件:市场比较与推荐
C++异步:libunifex中的concepts详解!
周末折腾了两天,踩了无数个坑,终于把win7装成了centos7
图片优化对SEO有着重要作用
- 原文地址:https://blog.csdn.net/tysonchiu/article/details/125503047