-
TCP重头戏来!了!(3)—— 小林图解学习摘记
TCP重头戏来!了!
TCP 重传机制
TCP 针对数据包丢失的情况,会用重传机制解决。常见的重传机制有:
- 超时重传
- 快速重传
- SACK
- D-SACK
超时重传
在发送数据时,设定一个定时器,当超过指定的时间后,没有收到对方的
ACK确认应答报文,就会重发该数据,也就是我们常说的超时重传。TCP 会在以下两种情况发生超时重传:
- 数据包丢失
- 确认应答丢失
超时时间应该设置为多少呢?
RTT指的是数据发送时刻到接收到确认的时刻的差值,也就是包的往返时间。超时重传时间是以RTO表示。- 当超时时间 RTO 较大时,重发就慢,丢了老半天才重发,没有效率,性能差;
- 当超时时间 RTO 较小时,会导致可能并没有丢就重发,于是重发的就快,会增加网络拥塞,导致更多的超时,更多的超时导致更多的重发。
精确的测量超时时间
RTO的值是非常重要的,这可让我们的重传机制更高效。根据上述的两种情况,我们可以得知,超时重传时间 RTO 的值应该略大于报文往返 RTT 的值。但实际上「报文往返 RTT 的值」是经常变化的,因为我们的网络也是时常变化的。也就因为「报文往返 RTT 的值」 是经常波动变化的,所以「超时重传时间 RTO 的值」应该是一个动态变化的值。如果超时重发的数据,再次超时重传时,TCP 的策略是超时间隔加倍。也就是每当遇到一次超时重传的时候,都会将下一次超时时间间隔设为先前值的两倍。两次超时,就说明网络环境差,不宜频繁反复发送。
超时触发重传存在的问题是,超时周期可能相对较长。那是不是可以有更快的方式呢?于是就可以用「快速重传」机制来解决超时重发的时间等待。
快速重传
快速重传的工作方式是当收到三个相同的 ACK 报文时,会在定时器过期之前,重传丢失的报文段。快速重传机制只解决了一个问题,就是超时时间的问题,但是它依然面临着另外一个问题。就是**重传的时候,是重传之前的一个,还是重传所有的问题。**因为发送端并不清楚这连续的三个 Ack报文 是谁传回来的。为了解决不知道该重传哪些 TCP 报文,于是就有
SACK方法。SACK
这种方式需要在 TCP 头部「选项」字段里加一个
SACK的东西,它可以将缓存的地图发送给发送方,这样发送方就可以知道哪些数据收到了,哪些数据没收到,知道了这些信息,就可以只重传丢失的数据。D-SACK
其主要使用了 SACK 来告诉「发送方」有哪些数据被重复接收了。(没太看懂,点超链接去看小林)
流量控制 (滑动窗口)
窗口大小就是指无需等待确认应答,而可以继续发送数据的最大值。
窗口的实现实际上是操作系统开辟的一个缓存空间,发送方主机在等到确认应答返回之前,必须在缓冲区中保留已发送的数据。如果按期收到确认应答,此时数据就可以从缓存区清除。假设窗口大小为
3个 TCP 段,那么发送方就可以「连续发送」3个 TCP 段,并且中途若有 ACK 丢失,可以通过「下一个确认应答进行确认」。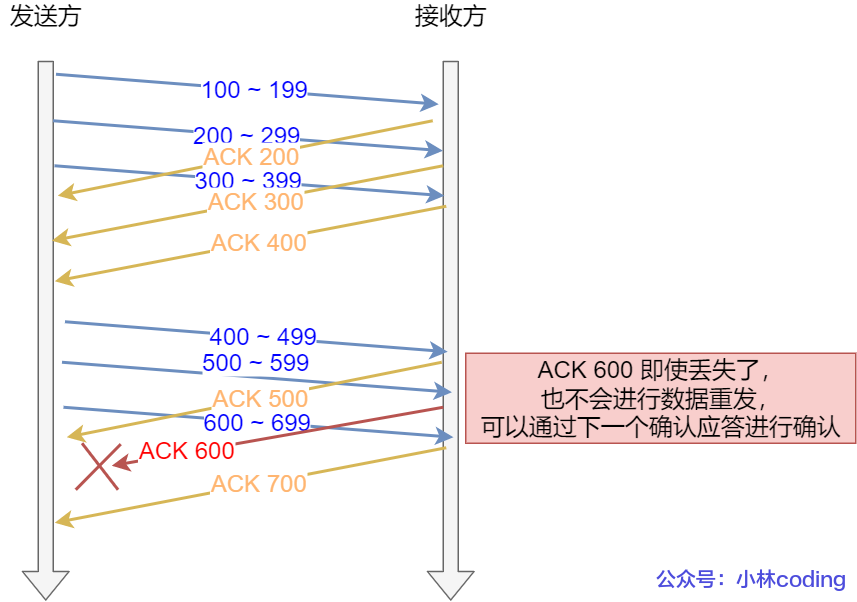
图中的 ACK 600 确认应答报文丢失,也没关系,因为可以通过下一个确认应答进行确认,只要发送方收到了 ACK 700 确认应答,就意味着 700 之前的所有数据「接收方」都收到了。这个模式就叫累计确认或者累计应答。
窗口大小
TCP 头里有一个字段叫
Window,也就是窗口大小。**这个字段是接收端告诉发送端自己还有多少缓冲区可以接收数据。于是发送端就可以根据这个接收端的处理能力来发送数据,而不会导致接收端处理不过来。**所以,通常窗口的大小是由接收方的窗口大小来决定的。发送方发送的数据大小不能超过接收方的窗口大小,否则接收方就无法正常接收到数据。接收窗口和发送窗口的大小是相等的吗?
并不是完全相等,接收窗口的大小是约等于发送窗口的大小的。
因为滑动窗口并不是一成不变的。比如,当接收方的应用进程读取数据的速度非常快的话,这样的话接收窗口可以很快的就空缺出来。那么新的接收窗口大小,是通过 TCP 报文中的 Windows 字段来告诉发送方。那么这个传输过程是存在时延的,所以接收窗口和发送窗口是约等于的关系。
如果接收方滑动窗口满了,发送方会怎么做?
基于 TCP 流量控制中的滑动窗口协议,我们知道接收方返回给发送方的 ACK 包中会包含自己的接收窗口大小,若接收窗口已满,此时接收方返回给发送方的接收窗口大小为 0,此时发送方会等待接收方发送的窗口大小直到变为非 0 为止,然而,接收方回应的 ACK 包是存在丢失的可能的,为了防止双方一直等待而出现死锁情况,(TCP 是如何解决窗口关闭时,潜在的死锁现象呢?)此时就需要坚持计时器来辅助发送方周期性地向接收方查询,以便发现窗口是否变大,当发现窗口大小变为非零时,发送方便继续发送数据。
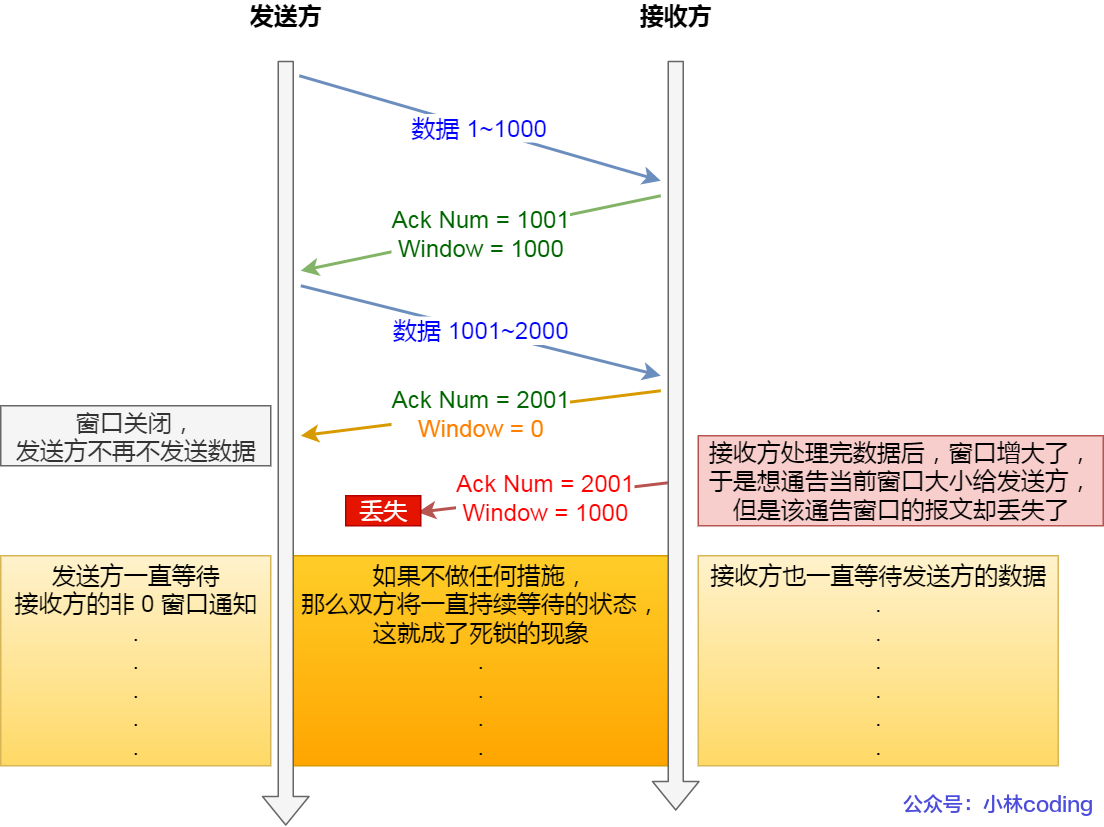
TCP 是如何解决窗口关闭时,潜在的死锁现象呢?
为了解决这个问题,TCP 为每个连接设有一个持续定时器,只要 TCP 连接一方收到对方的零窗口通知,就启动持续计时器。如果持续计时器超时,就会发送窗口探测 ( Window probe ) 报文,而对方在确认这个探测报文时,给出自己现在的接收窗口大小。
- 如果接收窗口仍然为 0,那么收到这个报文的一方就会重新启动持续计时器;
- 如果接收窗口不是 0,那么死锁的局面就可以被打破了。
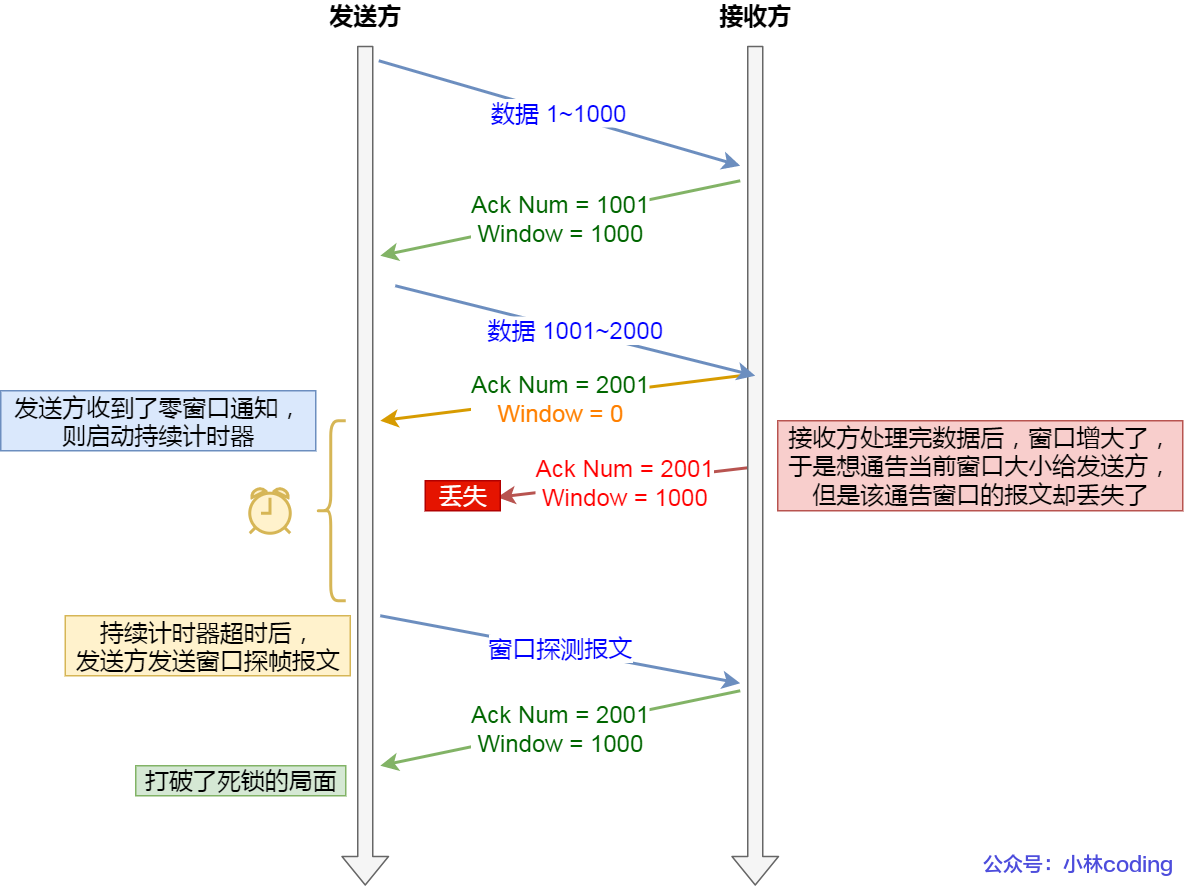
窗口探测的次数一般为 3 次,每次大约 30-60 秒(不同的实现可能会不一样)。如果 3 次过后接收窗口还是 0 的话,有的 TCP 实现就会发
RST报文来中断连接。糊涂窗口综合症
如果接收方太忙了,来不及取走接收窗口里的数据,那么就会导致发送方的发送窗口越来越小。到最后,如果接收方腾出几个字节并告诉发送方现在有几个字节的窗口,而发送方会义无反顾地发送这几个字节,这就是糊涂窗口综合症。要知道,我们的
TCP + IP头有40个字节,为了传输那几个字节的数据,要达上这么大的开销,这太不经济了。所以,糊涂窗口综合症的现象是可以发生在发送方和接收方:
- 接收方可以通告一个小的窗口
- 而发送方可以发送小数据
于是,要解决糊涂窗口综合症,就解决上面两个问题就可以了
- 让接收方不通告小窗口给发送方
- 让发送方避免发送小数据
怎么让接收方不通告小窗口呢?
当「窗口大小」小于 min( MSS,缓存空间/2 ) ,也就是小于 MSS 与 1/2 缓存大小中的最小值时,就会向发送方通告窗口为
0,也就阻止了发送方再发数据过来。等到接收方处理了一些数据后,窗口大小 >= MSS,或者接收方缓存空间有一半可以使用,就可以把窗口打开让发送方发送数据过来。怎么让发送方避免发送小数据呢?
使用 Nagle 算法,该算法的思路是延时处理,它满足以下两个条件中的一条才可以发送数据:
- 要等到窗口大小 >=
MSS或是 数据大小 >=MSS - 收到之前发送数据的
ack回包
只要没满足上面条件中的一条,发送方一直在囤积数据,直到满足上面的发送条件。
另外,Nagle 算法默认是打开的,如果对于一些需要小数据包交互的场景的程序,比如,telnet 或 ssh 这样的交互性比较强的程序,则需要关闭 Nagle 算法。可以在 Socket 设置
TCP_NODELAY选项来关闭这个算法(关闭 Nagle 算法没有全局参数,需要根据每个应用自己的特点来关闭)拥塞控制
在网络出现拥堵时,如果继续发送大量数据包,可能会导致数据包时延、丢失等,这时 TCP 就会重传数据,但是一重传就会导致网络的负担更重,于是会导致更大的延迟以及更多的丢包,这个情况就会进入恶性循环被不断地放大…所以,TCP 不能忽略网络上发生的事,它被设计成一个无私的协议,当网络发送拥塞时,TCP 会自我牺牲,降低发送的数据量。于是,就有了拥塞控制,控制的目的就是避免「发送方」的数据填满整个网络。
拥塞控制和流量控制的区别
拥塞控制往往是一种全局的,防止过多的数据注入到网络之中;
而流量控制往往指点对点通信量的控制,是端到端的问题。
什么是拥塞窗口?和发送窗口有什么关系呢?
为了在「发送方」调节所要发送数据的量,定义了一个叫做「拥塞窗口」的概念。拥塞窗口 cwnd是发送方维护的一个的状态变量,它会根据网络的拥塞程度动态变化的。
发送窗口的值是swnd = min(cwnd, rwnd),也就是拥塞窗口和接收窗口中的最小值。
拥塞窗口
cwnd变化的规则:- 只要网络中没有出现拥塞,
cwnd就会增大; - 但网络中出现了拥塞,
cwnd就减少;
怎么知道当前网络是否出现了拥塞呢?
只要「发送方」没有在规定时间内接收到 ACK 应答报文,也就是发生了超时重传,就认为网络出现拥塞。
拥塞控制有哪些控制算法?
拥塞控制主要是四个算法:
- 慢启动 \ 拥塞避免 \ 拥塞发生 \ 快速恢复
慢启动
当发送方开始发送数据时,由于一开始不知道网络负荷情况,如果立即将大量的数据字节传输到网络中,那么就有可能引起网络拥塞。一个较好的方法是在一开始发送少量的数据先探测一下网络状况,即由小到大的增大发送窗口(拥塞窗口 cwnd),意思就是一点一点的提高发送数据包的数量。
慢启动的算法记住一个规则就行:当发送方每收到一个 ACK,拥塞窗口 cwnd 的大小就会加 1。
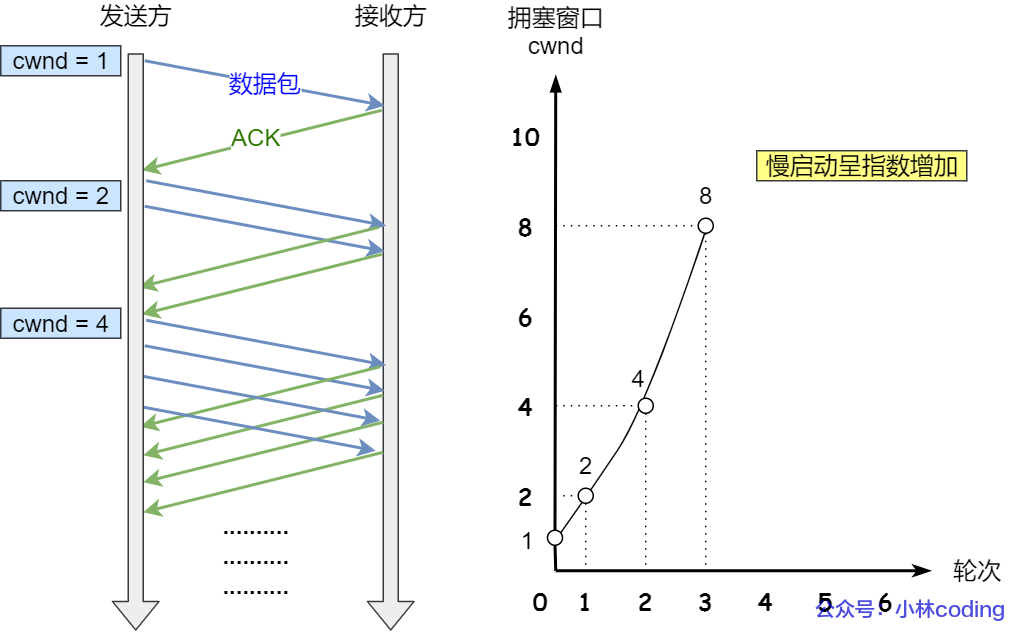
那慢启动涨到什么时候是个头呢?
慢启动门限
ssthresh(slow start threshold)状态变量。- 当
cwnd<ssthresh时,使用慢启动算法。 - 当
cwnd>=ssthresh时,就会使用「拥塞避免算法」。
拥塞避免
进入拥塞避免算法后,它的规则是:每当收到一个 ACK 时,cwnd 增加 1/cwnd。
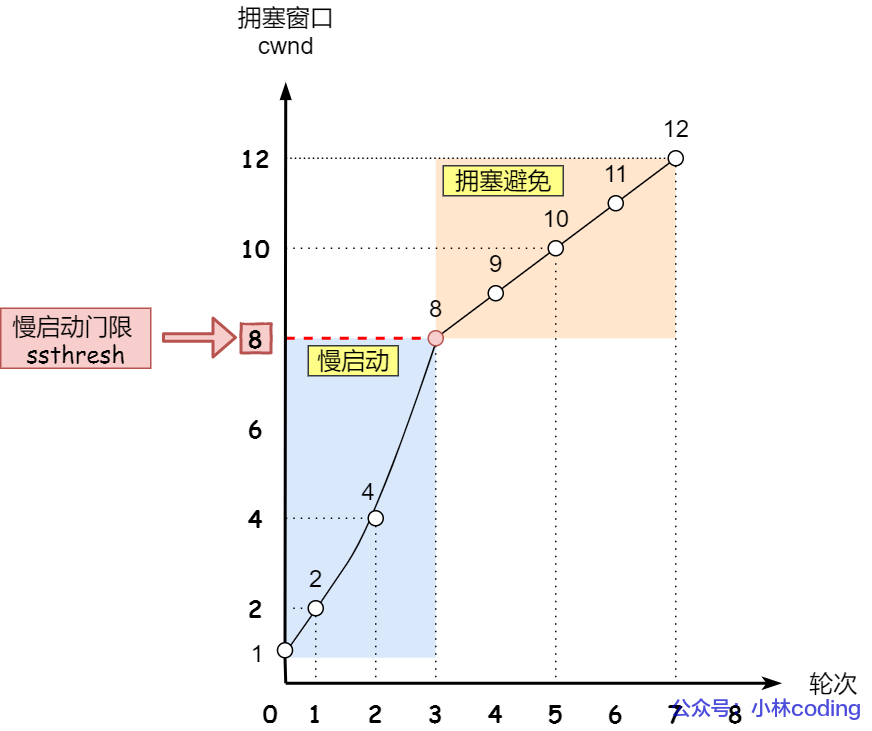
可以发现,拥塞避免算法就是将原本慢启动算法的指数增长变成了线性增长,还是增长阶段,但是增长速度缓慢了一些。就这么一直增长着后,网络就会慢慢进入了拥塞的状况了,于是就会出现丢包现象,这时就需要对丢失的数据包进行重传。
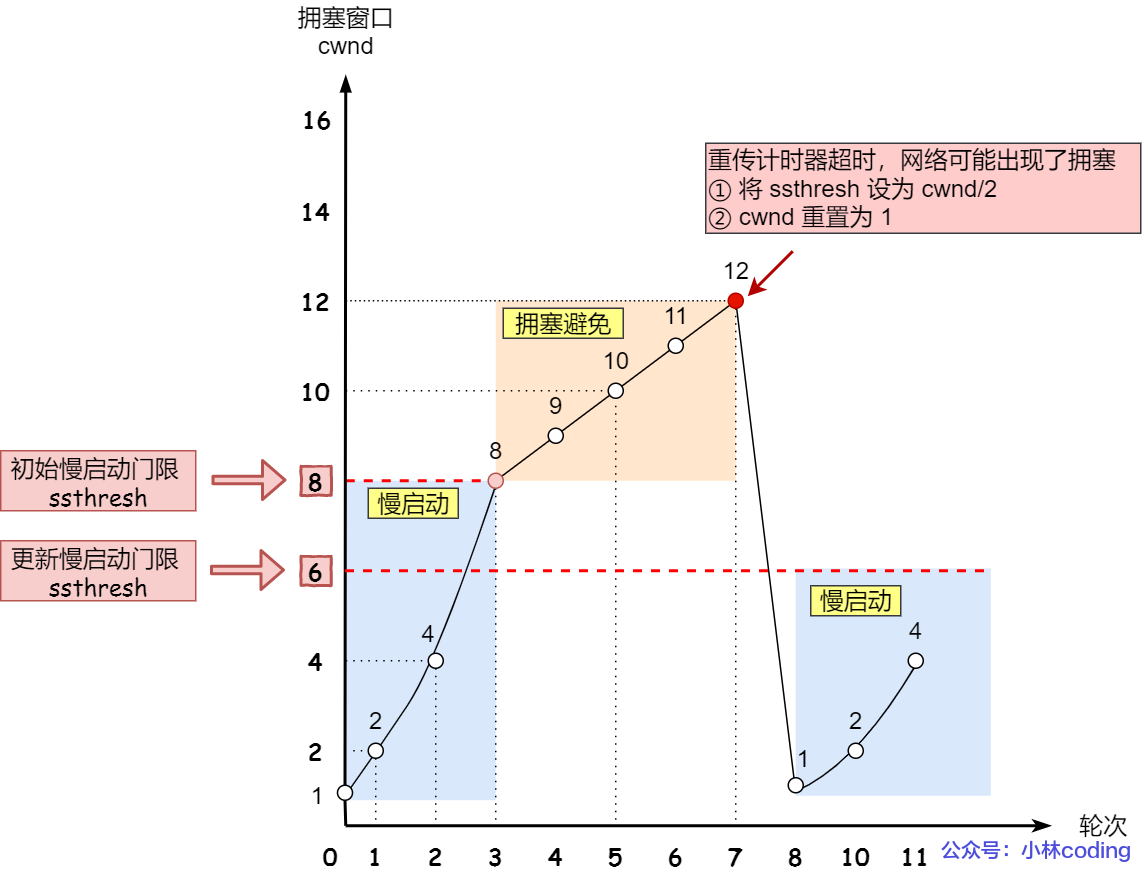
当触发了重传机制,也就进入了「拥塞发生算法」。
拥塞发生算法
超时重传
ssthresh设为cwnd/2,cwnd重置为1(是恢复为 cwnd 初始化值,我这里假定 cwnd 初始化值 1)- 然后再次重复两种算法(慢启动和拥塞避免),这时一瞬间会将网络中的数据量大量降低。这种方式太激进了,反应也很强烈,会造成网络卡顿。
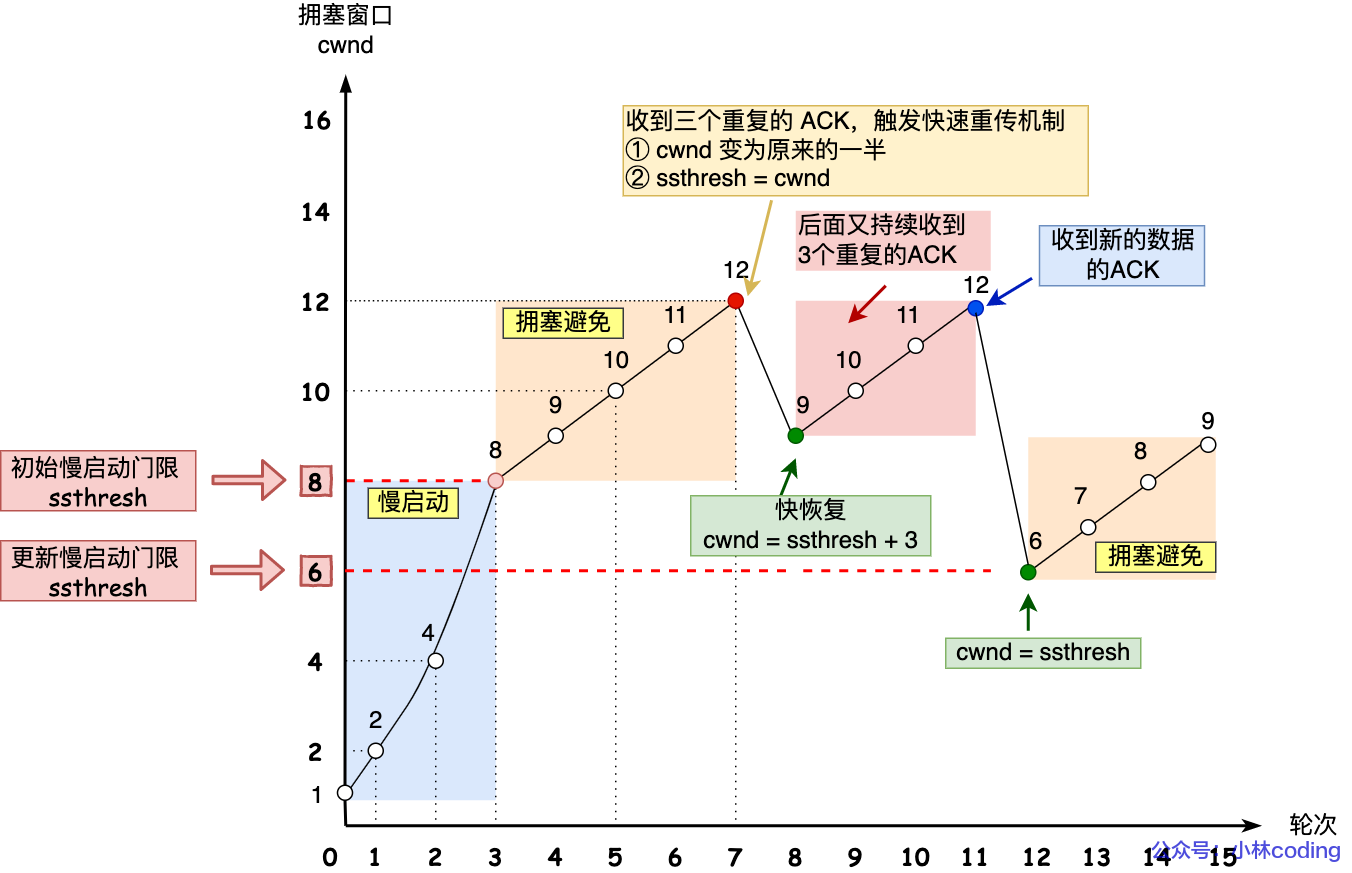
快速重传
「快速重传算法」。当接收方发现丢了一个中间包的时候,发送三次前一个包的 ACK,于是发送端就会快速地重传,不必等待超时再重传。
cwnd = cwnd/2,也就是设置为原来的一半;ssthresh = cwnd;- 进入快速恢复算法
快速恢复
- 拥塞窗口
cwnd = ssthresh + 3( 3 的意思是确认有 3 个数据包被收到了); - 重传丢失的数据包;
- 如果再收到重复的 ACK,那么 cwnd 增加 1;
- 如果收到新数据的 ACK 后,把 cwnd 设置为第一步中的 ssthresh 的值,原因是该 ACK 确认了新的数据,说明从 duplicated ACK 时的数据都已收到,该恢复过程已经结束,可以回到恢复之前的状态了,也即再次进入拥塞避免状态;
简述ARQ协议是什么?
为了实现可靠传输。它的基本原理是每发完一个分组就停止发送,等待对方确认。在收到确认后再发下一个分组。
socket() 套接字有哪些类型?
套接字(Socket)是对网络中不同主机上的应用进程之间进行双向通信的端点的抽象,网络进程通信的一端就是一个套接字,不同主机上的进程便是通过套接字发送报文来进行通信。例如 TCP 用主机的 IP 地址 + 端口号作为 TCP 连接的端点,这个端点就叫做套接字。
- 流套接字(SOCK_STREAM): 基于 TCP 传输协议
- 数据报套接字(SOCK_DGRAM): 基于 UDP 传输协议
- 原始套接字(SOCK_RAW): 由于流套接字和数据报套接字只能读取 TCP 和 UDP 协议的数据,当需要传送非传输层数据包(例如 Ping 命令时用的 ICMP 协议数据包)或者遇到操作系统无法处理的数据包时,此时就需要建立原始套接字来发送。
-
相关阅读:
“摸不着”的数字孪生,如何带来“看得见”的数据效益?
2-61 基于matlab的光学干涉仿真系统
用 Python 远程控制 Windows 服务器,太好用了!
C++中多态使用详细讲解
LeetCode 506.和为K的子数组
关于#matlab#的问题:我看到了gp-ols算法,请问gp我可以理解为是线性拟合吗,还是利用树结构寻优
让工程师拥有一台“超级”计算机——字节跳动客户端编译加速方案
博云入选 Gartner 中国云原生领域代表性厂商
java毕业生设计-学生考勤管理系统-计算机源码+系统+mysql+调试部署+lw
2022年,我们为什么要学习C++?
- 原文地址:https://blog.csdn.net/h0327x/article/details/125505962