-
深度学习——GRU单元
GRU单元(Gated Recurrent Unit)
带有神经网络的梯度消失
Q:为什么引入GRU单元?
A:其实,基本的 RNN 算法还有一个很大的问题,就是梯度消失的问题。现在我们举个语言模型的例子,假如看到这个句子,“The cat, which already ate ……, was full.”,前后应该保持一致,因为 cat 是单数,所以应该用 was。“The cats, which ate ……, were full.”,cats 是复数,所以用 were。这个例子中的句子有长期的依赖,最前面的单词对句子后面的单词有影响。但是我们目前见到的基本的 RNN 模型,不擅长捕获这种长期依赖效应。而门控循环单元GRU,它改变了 RNN 的隐藏层,使其可以更好地捕捉深层连接,并改善了梯度消失问题。GRU
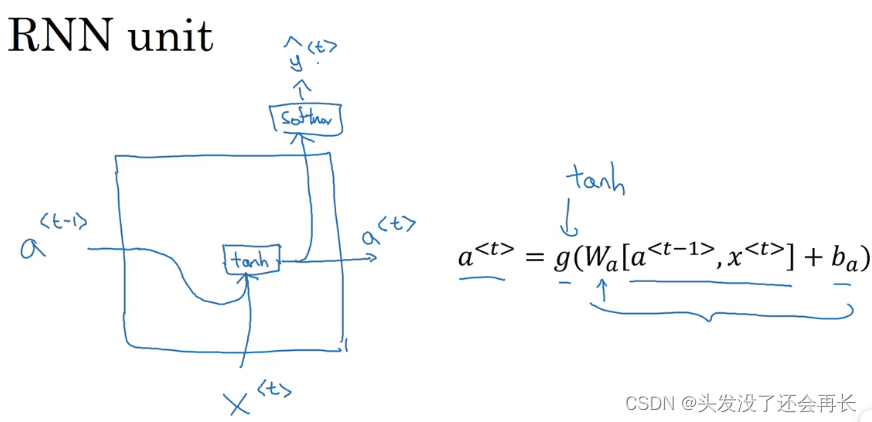
RNN隐藏层
你已经见过了这个公式,𝑎<𝑡> = 𝑔(𝑊𝑎[𝑎<𝑡−1>, 𝑥<𝑡>] + 𝑏𝑎),在 RNN 的时间𝑡处,计算激活值。我把这个画个图,把 RNN 的单元画个图,画一个方框,输入𝑎<𝑡−1>,即上一个时间步的激活值,再输入𝑥<𝑡>,再把这两个并起来,然后乘上权重项,在这个线性计算之后,如果𝑔是一个 tanh 激活函数,再经过 tanh 计算之后,它会计算出激活值𝑎<𝑡>。然后激活值𝑎<𝑡>将会传 softmax 单元,或者其他用于产生输出𝑦<𝑡>的东西。就这张图而言,这就是 RNN 隐藏层的单元的可视化呈现。
GRU的工作
“The cat was full.”或者是“The cats were full”。当我们从左到右读这个句子,GRU 单元将会有个新的变量称为𝑐,代表细胞(cell),即记忆细胞。记忆细胞的作用是提供了记忆的能力,比如说一只猫是单数还是复数,所以当它看到之后的句子的时候,它仍能够判断句子的主语是单数还是复数。于是在时间𝑡处,有记忆细胞𝑐<𝑡>,然后我们看的是,GRU 实际上输出了激活值𝑎<𝑡>,𝑐<𝑡> = 𝑎<𝑡>。于是我们想要使用不同的符号𝑐和𝑎来表示记忆细胞的值和输出的激活值.
这些等式表示了 GRU 单元的计算,在每个时间步,我们将用一个候选值重写记忆细胞,即𝑐̃<𝑡>的值,所以它就是个候选值,替代了𝑐<𝑡>的值。然后我们用 tanh 激活函数来计算,𝑐̃<𝑡> = 𝑡𝑎𝑛ℎ(𝑊𝑐[𝑐<𝑡−1>, 𝑥<𝑡>] + 𝑏𝑐),所以𝑐̃<𝑡>的值就是个替代值,代替表示𝑐<𝑡>的值.
在 GRU 中真正重要的思想是我们有一个门,我先把这个门叫做𝛤𝑢,这是个下标为𝑢的大写希腊字母𝛤,𝑢代表更新门,这是一个 0 到 1 之间的值。为了让你直观思考 GRU 的工作机制,先思考𝛤𝑢,这个一直在 0 到 1 之间的门值,实际上这个值是把这个式子带入sigmoid函数得到的,𝛤𝑢 = 𝜎(𝑊𝑢[𝑐<𝑡−1>, 𝑥<𝑡>] + 𝑏𝑢)。这个字母 u 表示“update”,我选了字母𝛤是因为它看起来像门.

GRU 的关键部分就是𝑐̃的等式,我们刚才写出来的用𝑐̃更新𝑐的等式。然后门决定是否要真的更新它。于是我们这么看待它,记忆细胞𝑐<𝑡>将被设定为 0 或者 1,这取决于你考虑的单词在句子中是单数还是复数,因为这里是单数情况,所以我们先假定它被设为了 1,或者如果是复数的情况我们就把它设为 0。然后 GRU 单元将会一直记住𝑐<𝑡>的值,直到上图was所在的位置,𝑐<𝑡>的值还是 1,这就告诉它,噢,这是单数,所以我们用 was。于是门𝛤𝑢的作用就是决定什么时候你会更新这个值,特别是当你看到词组 the cat,即句子的主语猫,这就是一个好时机去更新这个值。然后当你使用完它的时候,“The cat, which already ate……, was full.”,然后你就知道,我不需要记住它了,我可以忘记它了。
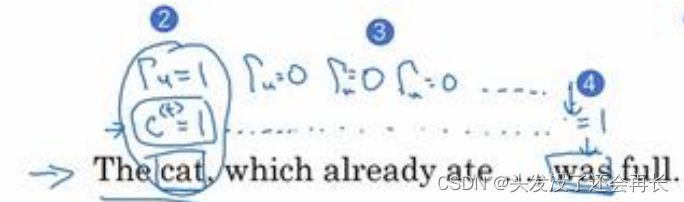
接下来要给 GRU 用的式子就是𝑐<𝑡> = 𝛤𝑢 ∗ 𝑐̃<𝑡> + (1 − 𝛤𝑢) ∗ 𝑐<𝑡−1>。你应该注意到了,如果这个更新值𝛤𝑢 = 1,也就是说把这个新值,即𝑐<𝑡>设为候选值(𝛤𝑢 = 1时简化上式,𝑐<𝑡> = 𝑐̃<𝑡>)。将门值设为 1,然后往前再更新这个值。对于所有在这中间的值,你应该把门的值设为 0,即𝛤𝑢 = 0,意思就是说不更新它,就用旧的值。因为如果𝛤𝑢 = 0,则𝑐<𝑡> = 𝑐<𝑡−1>,𝑐<𝑡>等于旧的值。甚至你从左到右扫描这个句子,当门值为 0 的时候(上图编号 3 所示,中间𝛤𝑢 = 0一直为 0,表示一直不更新),就是说不更新它的时候,不要更新它,就用旧的值,也不要忘记这个值是什么,这样即使你一直处理句子到上图编号 4 所示,𝑐<𝑡>应该会一直等𝑐<𝑡−1>,于是它仍然记得猫是单数的。GRU(simplified)
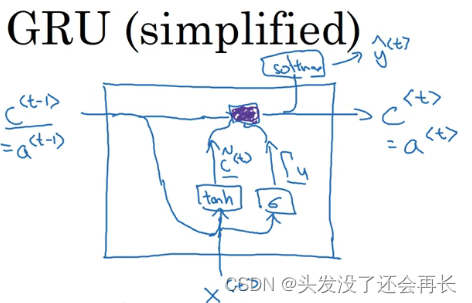
GRU 单元输入𝑐<𝑡−1>,对于上一个时间步,先假设它正好等于𝑎<𝑡−1>,所以把这个作为输入。然后𝑥<𝑡>也作为输入),然后把这两个用合适权重结合在一起,再用𝑡𝑎𝑛ℎ计算,算出𝑐̃<𝑡>,𝑐̃<𝑡> = 𝑡𝑎𝑛ℎ(𝑊𝑐[𝑐<𝑡−1>, 𝑥<𝑡>] + 𝑏𝑐),即𝑐<𝑡>的替代值。再用一个不同的参数集,通过sigmoid激活函数算出𝛤𝑢,𝛤𝑢 = 𝜎(𝑊𝑢[𝑐<𝑡−1>, 𝑥<𝑡>] + 𝑏𝑢),即更新门。最后所有的值通过另一个运算符结合通过式子𝑐<𝑡> = 𝛤𝑢 ∗ 𝑐̃<𝑡> + (1 − 𝛤𝑢) ∗ 𝑐<𝑡−1>计算(紫色方框),所以这就是紫色运算符所表示的是,它输入一个门值,新的候选值,这再有一个门值和𝑐<𝑡>的旧值,作为输入一起产生记忆细胞的新值𝑐<𝑡>,所以𝑐<𝑡>等于𝑎<𝑡>。如果你想,你也可以也把这个带入 softmax 或者其他预测𝑦<𝑡>的东西。
这就是 GRU 单元或者说是一个简化过的 GRU 单元,它的优点就是通过门决定,当你从左到右扫描一个句子的时候,这个时机是要更新某个记忆细胞,还是不更新,不更新直到你到你真的需要使用记忆细胞的时候,这可能在句子之前就决定了。因为 sigmoid的值,现在因为门很容易取到 0 值,只要这个值是一个很大的负数,再由于数值上的四舍五入,上面这些门大体上就是 0,或者说非常非常非常接近 0。所以在这样的情况下,这个更新式子就会变成𝑐<𝑡> = 𝑐<𝑡−1>,这非常有利于维持细胞的值。因为𝛤𝑢很接近 0,可能是 0.000001 或者更小,这就不会有梯度消失的问题了。因为𝛤𝑢很接近0,这就是说𝑐<𝑡>几乎就等于𝑐<𝑡−1>,而且𝑐<𝑡>的值也很好地被维持了,即使经过很多很多的时间步。这就是缓解梯度消失问题的关键,因此允许神经网络运行在非常庞大的依赖词上,比如说 cat 和 was 单词即使被中间的很多单词分割开。GPU(完整)
对于完整的 GRU 单元我要做的一个改变就是在我们计算的第一个式子中给记忆细胞的新候选值加上一个新的项,我要添加一个门𝛤𝑟,你可以认为𝑟代表相关性(relevance)。这个𝛤𝑟门告诉你计算出的下一个𝑐<𝑡>的候选值𝑐̃<𝑡>跟𝑐<𝑡−1>有多大的相关性。计算这个门 𝛤𝑟 需要参 数,正如你看到的这个,一个新的参数矩阵 𝑊𝑟 ,𝛤𝑟 = 𝜎(𝑊𝑟[𝑐<𝑡−1>, 𝑥<𝑡>] + 𝑏𝑟)。

Q:为什么有𝛤𝑟?
A:因为多年来研究者们试验过很多很多不同可能的方法来设计这些单元,去尝试让神经网络有更深层的连接,去尝试产生更大范围的影响,还有解决梯度消失的问题,GRU 就是其中一个研究者们最常使用的版本,也被发现在很多不同的问题上也是非常健壮和实用的。你可以尝试发明新版本的单元,只要你愿意。但是 GRU是一个标准版本,也就是最常使用的。你可以想象到研究者们也尝试了很多其他版本,类似这样的但不完全是,比如我这里写的这个。然后另一个常用的版本被称为 LSTM,表示长短时记忆网络,但是 GRU 和 LSTM 是在神经网络结构中最常用的两个具体实例。 -
相关阅读:
最详细、最全面的【Java日志框架】介绍,建议收藏,包含JUL、log4j、logback、log4j2等所有主流框架
释放Sqlite数据库占用的多余空间
了解string以及简单模拟实现(c++)
vue 自定义指令
1.1 - Android启动概览
有哪些挣钱软件一天能赚几十元?盘点十个能长期做下去的挣钱软件
FastAdmin列表实现自定义搜索及传值
Mysql - shell脚本操作Mysql数据库
【计算机网络】第三讲网络相关协议讲解(DNS、NAT、ICMP、总结)
A1140 Look-and-say Sequence(20分)PAT 甲级(Advanced Level) Practice(C++)满分题解【字符串处理】
- 原文地址:https://blog.csdn.net/m0_51474171/article/details/125500112