-
【手把手教你写Go】03.基本数据类型
Go的数据类型还是很简单的。和C一样,简约而不简单。
2.基础类型
2.1 命名
Go语言中的函数名、变量名、常量名、类型名、语句标号和包名等所有的命名,都遵循一个简单的命名规则:
一个名字必须以一个字母(Unicode字母)或下划线开头,后面可以跟任意数量的字母、数字或下划线。
大写字母和小写字母是不同的:heapSort和Heapsort是两个不同的名字。
Go语言中类似if和switch的关键字有25个(均为小写)。关键字不能用于自定义名字,只能在特定语法结构中使用。
break default func interface select case defer go map struct chan else goto package switch const fallthrough if range type continue for import return var- 1
- 2
- 3
- 4
- 5
此外,还有大约30多个预定义的名字,比如int和true等,主要对应内建的常量、类型和函数。
内建常量: true false iota nil 内建类型: int int8 int16 int32 int64 uint uint8 uint16 uint32 uint64 uintptr float32 float64 complex128 complex64 bool byte rune string error 内建函数: make len cap new append copy close delete complex real imag panic recover- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
2.2 变量
变量是几乎所有编程语言中最基本的组成元素,变量是程序运行期间可以改变的量。
从根本上说,变量相当于是对一块数据存储空间的命名,程序可以通过定义一个变量来申请一块数据存储空间,之后可以通过引用变量名来使用这块存储空间。
2.2.1 变量声明
Go语言的变量声明方式与C和C++语言有明显的不同。对于纯粹的变量声明, Go语言引入了关键字var,而类型信息放在变量名之后,示例如下:
var v1 int var v2 int //一次定义多个变量 var v3, v4 int var ( v5 int v6 int )- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
2.2.2 变量初始化
对于声明变量时需要进行初始化的场景, var关键字可以保留,但不再是必要的元素,如下所示:
var v1 int = 10 // 方式1 var v2 = 10 // 方式2,编译器自动推导出v2的类型 v3 := 10 // 方式3,编译器自动推导出v3的类型 fmt.Println("v3 type is ", reflect.TypeOf(v3)) //v3 type is int //自动推导类型 //出现在 := 左侧的变量不应该是已经被声明过,:=定义时必须初始化 var v4 int v4 := 2 //err //注意:自动推导类型只能在函数内部使用- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
2.2.3 变量赋值
var v1 int v1 = 123 var v2, v3, v4 int v2, v3, v4 = 1, 2, 3 //多重赋值 i := 10 j := 20 i, j = j, i //多重赋值- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
2.2.4 匿名变量
_(下划线)是个特殊的变量名,任何赋予它的值都会被丢弃:
_, i, _, j := 1, 2, 3, 4 func test() (int, string) { return 250, "sb" } _, str := test()- 1
- 2
- 3
- 4
- 5
- 6
- 7
用途:回收变量,常用于接收函数的返回值,因为go的函数是可以有多个返回值的,如果只想用其中的一个, 就可以用匿名变量丢弃其他变量。
2.3 常量
在Go语言中,常量是指编译期间就已知且不可改变的值。常量可以是数值类型(包括整型、浮点型和复数类型)、布尔类型、字符串类型等。
2.3.1 字面常量(常量值)
所谓字面常量(literal),是指程序中硬编码的常量,如:
123 3.1415 // 浮点类型的常量 3.2+12i // 复数类型的常量 true // 布尔类型的常量 "foo" // 字符串常量- 1
- 2
- 3
- 4
- 5
2.3.2 常量定义
变量:程序运行期间,可以改变的量, 变量声明需要var
常量:程序运行期间,不可以改变的量,常量声明需要const
const Pi float64 = 3.14 const zero = 0.0 // 浮点常量, 自动推导类型 const ( // 常量组 size int64 = 1024 eof = -1 // 整型常量, 自动推导类型 ) const u, v float32 = 0, 3 // u = 0.0, v = 3.0,常量的多重赋值 const a, b, c = 3, 4, "foo" // a = 3, b = 4, c = "foo" //err, 常量不能修改- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
2.2.3 iota枚举
常量声明可以使用iota常量生成器初始化,它用于生成一组以相似规则初始化的常量,但是不用每行都写一遍初始化表达式。
在一个const声明语句中,在第一个声明的常量所在的行,iota将会被置为0,然后在每一个有常量声明的行加一。
const ( x = iota // x == 0 y = iota // y == 1 z = iota // z == 2 w // 这里隐式地说w = iota,因此w == 3。其实上面y和z可同样不用"= iota" ) const v = iota // 每遇到一个const关键字,iota就会重置,此时v == 0 const ( h, i, j = iota, iota, iota //h=0,i=0,j=0 iota在同一行值相同 ) const ( a = iota //a=0 b = "B" c = iota //c=2 d, e, f = iota, iota, iota //d=3,e=3,f=3 如果是同一行,值都一样 g = iota //g = 4 ) const ( x1 = iota * 10 // x1 == 0 y1 = iota * 10 // y1 == 10 z1 = iota * 10 // z1 == 20 ) const ( a = iota //0 b //1 c //2 d = "ha" //独立值,iota += 1 e //"ha" iota += 1 f = 100 //iota +=1 g //100 iota +=1 h = iota //7,恢复计数 i //8 ) fmt.Println(a,b,c,d,e,f,g,h,i)//0 1 2 ha ha 100 100 7 8- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
2.4 基础数据类型
2.4.1 分类
Go语言内置以下这些基础类型:
类型 名称 长度 零值 说明 bool 布尔类型 1 false 其值不为真即为家,不可以用数字代表true或false byte 字节型 1 0 uint8别名 rune 字符类型 4 0 专用于存储unicode编码,等价于uint32 int, uint 整型 4或8 0 32位或64位 int8, uint8 整型 1 0 -128 ~ 127, 0 ~ 255 int16, uint16 整型 2 0 -32768 ~ 32767, 0 ~ 65535 int32, uint32 整型 4 0 -21亿 ~ 21 亿, 0 ~ 42 亿 int64, uint64 整型 8 0 float32 浮点型 4 0.0 小数位精确到7位 float64 浮点型 8 0.0 小数位精确到15位 complex64 复数类型 8 complex128 复数类型 16 uintptr 整型 4或8 ⾜以存储指针的uint32或uint64整数 string 字符串 “” utf-8字符串 2.4.2布尔类型
var v1 bool v1 = true v2 := (1 == 2) // v2也会被推导为bool类型 //布尔类型不能接受其他类型的赋值,不支持自动或强制的类型转换 var b bool b = 1 // err, 编译错误 b = bool(1) // err, 编译错误- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
bool转int
func bool2int(b bool) int { if b { return 1 } return 0 }- 1
- 2
- 3
- 4
- 5
- 6
int转bool
func int2bool(i int) bool { return i != 0 }- 1
- 2
- 3
2.4.3 整型
var v1 int32 v1 = 123 v2 := 64 // v1将会被自动推导为int类型- 1
- 2
- 3
int 和 uint 的区别就在于一个 u,有 u 说明是无符号,没有 u 代表有符号。
解释这个符号的区别:
以 int8 和 uint8 举例,8 代表 8个bit,能表示的数值个数有 2^8 = 256。
- uint8 是无符号,能表示的都是正数,0-255,刚好256个数。
- int8 是有符号,既可以正数,也可以负数,那怎么办?对半分呗,-128-127,也刚好 256个数。
int8 int16 int32 int64 这几个类型的最后都有一个数值,这表明了它们能表示的数值个数是固定的。
而 int 并没有指定它的位数,说明它的大小,是可以变化的,那根据什么变化呢?
- 当你在32位的系统下,int 和 uint 都占用 4个字节,也就是32位。
- 若你在64位的系统下,int 和 uint 都占用 8个字节,也就是64位。
出于这个原因,在某些场景下,你应当避免使用 int 和 uint ,而使用更加精确的 int32 和 int64,比如在二进制传输、读写文件的结构描述(为了保持文件的结构不会受到不同编译目标平台字节长度的影响)
2.4.4 浮点型
var f1 float32 f1 = 12 f2 := 12.0 // 如果不加小数点, fvalue2会被推导为整型而不是浮点型,float64- 1
- 2
- 3
float32 和 float64
Go语言中提供了两种精度的浮点数 float32 和 float64。
float32,也即我们常说的单精度,存储占用4个字节,也即4*8=32位,其中1位用来符号,8位用来指数,剩下的23位表示尾数

float64,也即我们熟悉的双精度,存储占用8个字节,也即8*8=64位,其中1位用来符号,11位用来指数,剩下的52位表示尾数
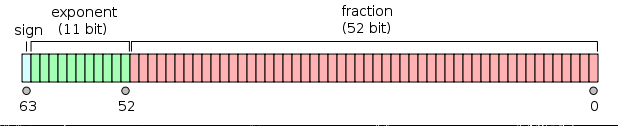
那么精度是什么意思?有效位有多少位?
精度主要取决于尾数部分的位数。
对于 float32(单精度)来说,表示尾数的为23位,除去全部为0的情况以外,最小为2-23,约等于1.19*10-7,所以float小数部分只能精确到后面6位,加上小数点前的一位,即有效数字为7位。
同理 float64(单精度)的尾数部分为 52位,最小为2-52,约为2.22*10-16,所以精确到小数点后15位,加上小数点前的一位,有效位数为16位。
通过以上,可以总结出以下几点:
一、float32 和 float64 可以表示的数值很多
浮点数类型的取值范围可以从很微小到很巨大。浮点数取值范围的极限值可以在 math 包中找到:
- 常量 math.MaxFloat32 表示 float32 能取到的最大数值,大约是 3.4e38;
- 常量 math.MaxFloat64 表示 float64 能取到的最大数值,大约是 1.8e308;
- float32 和 float64 能表示的最小值分别为 1.4e-45 和 4.9e-324。
二、数值很大但精度有限
人家虽然能表示的数值很大,但精度位却没有那么大。
- float32的精度只能提供大约6个十进制数(表示后科学计数法后,小数点后6位)的精度\
- float64的精度能提供大约15个十进制数(表示后科学计数法后,小数点后15位)的精度\
这里的精度是什么意思呢?
比如 10000018这个数,用 float32 的类型来表示的话,由于其有效位是7位,将10000018 表示成科学计数法,就是 1.0000018 * 10^7,能精确到小数点后面6位。
此时用科学计数法表示后,小数点后有7位,刚刚满足我们的精度要求,意思是什么呢?此时你对这个数进行+1或者-1等数学运算,都能保证计算结果是精确的
import "fmt" var myfloat float32 = 10000018 func main() { fmt.Println("myfloat: ", myfloat) fmt.Println("myfloat: ", myfloat+1) } /* myfloat: 1.0000018e+07 myfloat: 1.0000019e+07 /- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
上面举了一个刚好满足精度要求数据的临界情况,为了做对比,下面也举一个刚好不满足精度要求的例子。只要给这个数值多加一位数就行了。
换成 100000187,同样使用 float32类型,表示成科学计数法,由于精度有限,表示的时候小数点后面7位是准确的,但若是对其进行数学运算,由于第八位无法表示,所以运算后第七位的值,就会变得不精确。
这里我们写个代码来验证一下,按照我们的理解下面 myfloat01 = 100000182 ,对其+5 操作后,应该等于 myfloat02 = 100000187,
import "fmt" var myfloat01 float32 = 100000182 var myfloat02 float32 = 100000187 func main() { fmt.Println("myfloat: ", myfloat01) fmt.Println("myfloat: ", myfloat01+5) fmt.Println(myfloat02 == myfloat01+5) }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
但是由于其类型是 float32,精度不足,导致最后比较的结果是不相等(从小数点后第七位开始不精确)
myfloat: 1.00000184e+08
myfloat: 1.0000019e+08
false
由于精度的问题,就会出现这种很怪异的现象,myfloat == myfloat +1 会返回 true 。
2.4.5 字符类型
在Go语言中支持两个字符类型,一个是byte(实际上是uint8的别名),代表utf-8字符串的单个字节的值;另一个是rune,代表单个unicode字符。
package main import ( "fmt" ) func main() { var ch1, ch2, ch3 byte ch1 = 'a' //字符赋值 ch2 = 97 //字符的ascii码赋值 ch3 = '\n' //转义字符 fmt.Printf("ch1 = %c, ch2 = %c, %c", ch1, ch2, ch3) //大写转小写,小写转大写, 大小写相差32,小写大 fmt.Printf("大写:%d, 小写:%d\n", 'A', 'a')//大写:65, 小写:97 fmt.Printf("大写转小写:%c\n", 'A'+32) fmt.Printf("小写转大写:%c\n", 'a'-32) }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
2.4.6 字符串
在Go语言中,字符串也是一种基本类型:
- 双引号
- 字符串有1个或多个字符组成
- 字符串都是隐藏了一个结束符,‘\0’
var str string // 声明一个字符串变量 str = "abc" // 字符串赋值 ch := str[0] // 取字符串的第一个字符 fmt.Printf("str = %s, len = %d\n", str, len(str)) //内置的函数len()来取字符串的长度 fmt.Printf("str[0] = %c, ch = %c\n", str[0], ch) //`(反引号)括起的字符串为Raw字符串,即字符串在代码中的形式就是打印时的形式,它没有字符转义,换行也将原样输出。 str2 := `hello mike \n \r测试 ` fmt.Println("str2 = ", str2) /* str2 = hello mike \n \r测试 */- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
2.4.7 复数类型
复数实际上由两个实数(在计算机中用浮点数表示)构成,一个表示实部(real),一个表示虚部(imag)。
var v1 complex64 // 由2个float32构成的复数类型 v1 = 3.2 + 12i v2 := 3.2 + 12i // v2是complex128类型 v3 := complex(3.2, 12) // v3结果同v2 fmt.Println(v1, v2, v3) //内置函数real(v1)获得该复数的实部 //通过imag(v1)获得该复数的虚部 fmt.Println(real(v1), imag(v1))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
2.5 fmt包的格式化输出输入
2.5.1 格式说明
格式 含义 %% 一个%字面量 %b 一个二进制整数值(基数为2),或者是一个(高级的)用科学计数法表示的指数为2的浮点数 %c 字符型。可以把输入的数字按照ASCII码相应转换为对应的字符 %d 一个十进制数值(基数为10) %e 以科学记数法e表示的浮点数或者复数值 %E 以科学记数法E表示的浮点数或者复数值 %f 以标准记数法表示的浮点数或者复数值 %g 以%e或者%f表示的浮点数或者复数,任何一个都以最为紧凑的方式输出 %G 以%E或者%f表示的浮点数或者复数,任何一个都以最为紧凑的方式输出 %o 一个以八进制表示的数字(基数为8) %p 以十六进制(基数为16)表示的一个值的地址,前缀为0x,字母使用小写的a-f表示 %q 使用Go语法以及必须时使用转义,以双引号括起来的字符串或者字节切片[]byte,或者是以单引号括起来的数字 %s 字符串。输出字符串中的字符直至字符串中的空字符(字符串以’\0‘结尾,这个’\0’即空字符) %t 以true或者false输出的布尔值 %T 使用Go语法输出的值的类型 %U 一个用Unicode表示法表示的整型码点,默认值为4个数字字符 %v 使用默认格式输出的内置或者自定义类型的值,或者是使用其类型的String()方式输出的自定义值,如果该方法存在的话 %x 以十六进制表示的整型值(基数为十六),数字a-f使用小写表示 %X 以十六进制表示的整型值(基数为十六),数字A-F使用小写表示 2.5.2 输出
//整型 a := 15 fmt.Printf("a = %b\n", a) //a = 1111 fmt.Printf("%%\n") //只输出一个% //字符 ch := 'a' fmt.Printf("ch = %c, %c\n", ch, 97) //a, a //浮点型 f := 3.14 fmt.Printf("f = %f, %g\n", f, f) //f = 3.140000, 3.14 fmt.Printf("f type = %T\n", f) //f type = float64 //复数类型 v := complex(3.2, 12) fmt.Printf("v = %f, %g\n", v, v) //v = (3.200000+12.000000i), (3.2+12i) fmt.Printf("v type = %T\n", v) //v type = complex128 //布尔类型 fmt.Printf("%t, %t\n", true, false) //true, false //字符串 str := "hello go" fmt.Printf("str = %s\n", str) //str = hello go- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
2.5.3 输入
var v int fmt.Println("请输入一个整型:") fmt.Scanf("%d", &v) //fmt.Scan(&v) fmt.Println("v = ", v)- 1
- 2
- 3
- 4
- 5
2.6 类型转换
Go语言中不允许隐式转换,所有类型转换必须显式声明,而且转换只能发生在两种相互兼容的类型之间。
var flag bool flag = true fmt.Printf("flag = %t\n", flag) //bool类型不能转换为int //fmt.Printf("flag = %d\n", int(flag)) //0就是假,非0就是真 //整型也不能转换为bool //flag = bool(1) var ch byte ch = 'a' //字符类型本质上就是整型 var t int t = int(ch) //类型转换,把ch的值取出来后,转成int再给t赋值 fmt.Println("t = ", t)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
2.7 类型别名
type bigint int64 //int64类型改名为bigint var x bigint = 100 type ( myint int //int改名为myint mystr string //string改名为mystr )- 1
- 2
- 3
- 4
- 5
- 6
- 7
-
相关阅读:
某集团营销、制造多公司业财一体核算整体流程图(ODOO15/16)
从零开始利用MATLAB进行FPGA设计(一):建立脉冲检测模型的Simulink模型1
自学数据库-MySQL
iStoreOS搭建主路由有什么好处
初出茅庐:主程的历练
leetcode-aboutString
FreeROTS 任务通知和实操 详解
无需设计经验,也能制作出精美的房地产电子传单
Mojo 正式发布,Rust 能否与之匹敌?
逻辑回归原理
- 原文地址:https://blog.csdn.net/happy_teemo/article/details/119355746
