-
Python3.9的69个内置函数(内建函数)介绍,并附简单明了的示例代码
Python 解释器内置(内建)了很多函数,这篇博文对它们进行逐一介绍,博主觉得有必要给出示例代码的会给出示例代码。
声明:博主(昊虹图像算法)写这篇博文时,用的Python的版本号为3.9.10。
官方文档:https://docs.python.org/zh-cn/3.9/library/functions.html#built-in-functions
说明:官方文档里列出了14*5-1=59个内置函数,但博主认为classmethod、staticmethod、property这三个更像是定义类的三个关键字,故没在这篇博文中进行介绍,如果要看这三个的介绍,可参考我的另一篇博文,链接 https://blog.csdn.net/wenhao_ir/article/details/125383895
这篇博文中反复提到了可迭代对象的概论,那么什么是可迭代对象呢?
列表、元组、字典和集合就是典型的可迭代对象,这些对象都包含方法 __iter__() 或__next__()。可迭代对象的元素能够通过其内部的方法 __iter__() 或 __next__()进行遍历。目录
- 01-函数abs():返回一个数的绝对值
- 02-函数all():判断可迭代对象是否所有元素为True
- 03-函数any():判断可迭代对象是否有一个以上元素为True
- 04-函数ascii():返回任何对象(字符串、元组、列表等)的ASCII码打印(可读)版本
- 05-函数bin():返回一个整数的二进制表示(这个二进制表示是字符串对象)
- 06-函数bool():返回对象的bool值(布尔值)
- 07-函数breakpoint():此函数在调用时将使程序陷入调试器中
- 08-函数bytearray():返回单字节数组
- 09-函数callable():测试对象是否能被调用
- 10-函数chr():返回代表指定unicode码值的字符
- 11-函数compile():将字符串代码编译成可运行的代码对象
- 12-函数complex():通过指定复数的实部和虚部来得到复数
- 13-函数delattr():从指定的对象中删除指定的属性属性或方法
- 14-函数dict():创建字典
- 15-函数dir():查询一个类或一个对象有哪些属性(方法(成员函数)、变量))
- 16-函数divmod():返回除法的商和余数
- 17-函数enumerate():将可迭代对象转化为枚举对象
- 18-函数eval():执行函数compile()后的代码对象
- 19-函数exec():执行函数compile()后的代码对象
- 20-函数filter():过滤掉可迭代对象中不符合条件的元素
- 21-函数float():将整数或字符串转换成浮点数
- 22-函数format():字符串格式化函数
- 23-函数frozenset():返回一个被冻结的可迭代对象
- 24-函数getattr():获取对象的某个属性的值
- 25-函数globals():返回程序当前运行位置的所有全局变量
- 26-函数hasattr():判断对象是否具有某属性
- 27-函数hash():获取对象(通常为字符的哈希值
- 28-函数help():用于查看函数、类、对象等的说明
- 29-函数hex():返回一个数字的16进制表示
- 30-函数id():返回对象的id(内存地址)
- 31-函数input():接受输入数据(如来自键盘的输入),返回string类型
- 32-函数int():将浮点数或字符串转换为整数
- 33-函数isinstance():判断一个对象是否是某个类的实例
- 34-函数issubclass():判断某个类是否是另一个类的子类
- 35-函数iter():用于生成可迭代对象的迭代器对象
- 36函数len():返回对象(字符串、列表、元组、字典、集合等)的长度
- 37-函数list():用于将元组或字符串转换为列表
- 38-函数locals():返回程序前当前运行位置的局部变量
- 39-函数map():将某可迭代对象通过某一函数映射到另一迭代对象
- 40-函数max():返回给定参数的最大值
- 41-函数memoryview():返回给定参数的内存查看对象(memory view)
- 42-函数min():返回给定参数的最小值
- 43-函数next():返回迭代器的下一个项目
- 44-函数object():创建一个空的对象
- 45-函数oct():将一个整数转换成 8 进制字符串
- 46-函数open():打开一个文件,并返回文件对象
- 47-函数ord():返回字符的ASCII 数值或者Unicode数值
- 48-函数pow():返回x的y次方值,还可对结果作取余除法
- 49-函数print():打印输出对象
- 50-函数property():获取、设置、删除类的某个属性
- 51-函数range():返回一个可迭代对象
- 52-函数repr(): 将对象字符串化(文本化)【repr应该是return print的缩写】
- 53-函数reversed():获得对象的反转迭代器(作用就是反转迭代器)
- 54-函数round():返回浮点数的五舍六入值(可控制小数位数)
- 55-函数set():创建集合对象
- 56-函数setattr():设置对象的属性值
- 57- 函数slice():辅助切片操作
- 58-函数sorted():对可迭代对象的元素进行排序操作
- 59-函数str():将对象转化为string对象(字符串对象)
- 60-函数sum():对可迭代对象求和
- 61-函数super():用于提供对父类或同胞类的方法和属性的访问
- 62-函数tuple():把可迭代对象转换为元组
- 63-函数type():返回对象的类型
- 64-函数vars():返回类的 \_\_dic\_\_ 属性
- 65-函数zip():打包多个可迭代对象
- 66-函数\_\_import\_\_():导入模块、脚本、类和函数等
01-函数abs():返回一个数的绝对值
abs(x)
返回一个数的绝对值。 参数可以是整数、浮点数或任何实现了 __abs__() 的对象。 如果参数是一个复数,则返回它的模。
这个的示例代码就不给了。02-函数all():判断可迭代对象是否所有元素为True
什么叫可迭代对象?列表、元组、字典和集合就是典型的可迭代对象,这些对象都包含方法 __iter__() 和 __next__()。可迭代对象的元素能够通过其内部的方法 __iter__() 和 __next__()进行遍历。
那么元素对象满足什么条件为True呢?可参考我的另一篇博文 https://blog.csdn.net/wenhao_ir/article/details/125439660注意:按道理,空元组、空列表的布尔值为False,所以对于空元组、空列表,函数all()应该返回False才对,但事实并不是这样,对于空元组、空列表函数all()的返回值也为True,这一点要特别注意。
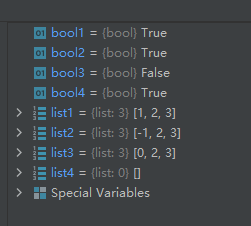
示例代码如下:list1 = [1, 2, 3] list2 = [-1, 2, 3] list3 = [0, 2, 3] list4 = [] bool1 = all(list1) bool2 = all(list2) bool3 = all(list3) bool4 = all(list4)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
运行结果如下:
03-函数any():判断可迭代对象是否有一个以上元素为True
什么叫可迭代对象?列表、元组、字典和集合就是典型的可迭代对象,这些对象都包含方法 __iter__() 和 __next__()。
any() 函数用于判断可迭代对象是否有一个以上元素为True,如果有一个为 True,则返回 True;如果全部为False,则返回 False。
那么元素对象满足什么条件为True呢?可参考我的另一篇博文 https://blog.csdn.net/wenhao_ir/article/details/125439660
注意:对于函数any()而言,空元组、空列表返回值为False。
示例代码如下:
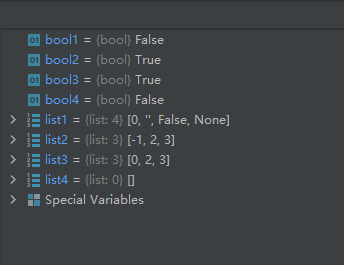
list1 = [0, '', False, None] list2 = [-1, 2, 3] list3 = [0, 2, 3] list4 = [] bool1 = any(list1) bool2 = any(list2) bool3 = any(list3) bool4 = any(list4)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
运行结果如下:
04-函数ascii():返回任何对象(字符串、元组、列表等)的ASCII码打印(可读)版本
函数ascii()返回任何对象(字符串、元组、列表等)的可读版本,有点类似于把对象强制转换为ASCII码字符串,它会将非ASCII字符替换为转义字符。
上面这句话不太好理解,看一个示例代码就知道了。示例代码如下:
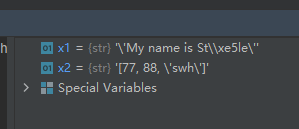
x1 = ascii('My name is Ståle') print(x1) x2 = ascii([77, 88, 'swh']) print(x2)- 1
- 2
- 3
- 4
- 5
运行结果如下:
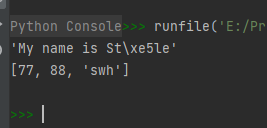
这里要注意x1中的“\xe5”是怎么回事?那是因为在ASCII码中没有字符å ,所以将其替换成了 \xe5
另外, 我们看到字符串的前后的引号也被转换成了字符。05-函数bin():返回一个整数的二进制表示(这个二进制表示是字符串对象)
示例代码如下:
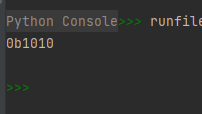
x1 = bin(10) print(x1)- 1
- 2
运行结果如下:
06-函数bool():返回对象的bool值(布尔值)
关于函数bool(),请参见我的另一篇博文 https://blog.csdn.net/wenhao_ir/article/details/125439660
07-函数breakpoint():此函数在调用时将使程序陷入调试器中
这个函数是3.7 版之后才有的,使用频率也不高,暂时不做过多介绍。
08-函数bytearray():返回单字节数组
函数bytearray()的语法如下:
bytearray([source[, encoding[, errors]]])- 1
参数介绍:
如果 source 为整数,则返回一个长度为 source 的初始化数组;
如果 source 为字符串,则按照指定的 encoding 将字符串转换为字节序列;
如果 source 为可迭代类型,因为每个元素的存储空间只有一个字节,则元素必须为[0 ,255] 中的整数;
如果没有输入任何参数,默认就是初始化数组为0个元素。
示例代码如下:bytearray0 = bytearray() bytearray1 = bytearray(5) bytearray2 = bytearray('suwenhao', 'utf-8') bytearray3 = bytearray([65, 66, 67])- 1
- 2
- 3
- 4
运行结果如下:
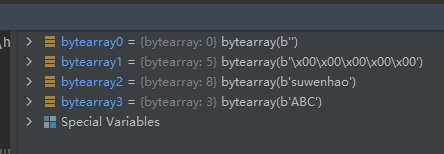
从上面的运行结果我们可以看出:
①长度为 source 的初始化数组的元素的默认值为\x00
②显示是以ASCII码来显示其值的,所以bytearray3的三个数被显示为了大写的字母ABC。09-函数callable():测试对象是否能被调用
如果指定的对象是可调用的,则返回 True,否则返回 False。
注意:如果函数callable()返回True,object 仍然可能调用失败;但如果返回 False,调用对象 object 绝对不会成功。
对于函数、方法、lambda 匿名函数、 类以及实现了 __call__ 方法的类实例, 它都会返回 True。
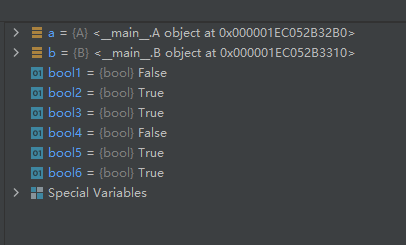
示例代码如下:def add(a_p, b_p): return a_p + b_p class A: def method(self): return 0 class B: def __call__(self): return 0 bool1 = callable(0) # 对象0不可被调用,所以应该返回False bool2 = callable(add) # 函数add返回True bool3 = callable(A) # 类A返回True a = A() bool4 = callable(a) # 类A的实例化对象a没有实现__call__,所以应该返回False bool5 = callable(B) # 类B返回True b = B() bool6 = callable(b) # 类B的实例化对象b实现了__call__,所以应该返回True- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
运行结果如下:
10-函数chr():返回代表指定unicode码值的字符
函数chr( i )返回 Unicode 码位为整数 i 的字符的字符串格式。例如,chr(97) 返回字符串 ‘a’,chr(8364) 返回字符串 ‘€’。
i — 可以是 10 进制也可以是 16 进制的形式的数字,数字范围为 0 到 1,114,111 (16 进制为0x10FFFF)。
示例代码如下:
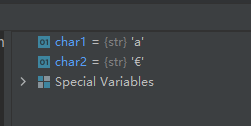
char1 = chr(97) char2 = chr(8364)- 1
- 2
- 3
运行结果如下:
另外,可用使用函数ord()返回字符的ASCII 数值或者Unicode数值,详情见本文的第47个函数。11-函数compile():将字符串代码编译成可运行的代码对象
函数compile()的作用将字符串代码编译成可运行的代码对象。
看了上面这句话通常还是不知道它干了啥。没关系,看一下示例代码就知道了。
示例代码如下:a1 = 188 x = compile('print(a1)', 'jhoij', 'eval') eval(x)- 1
- 2
- 3
- 4
运行结果如下:
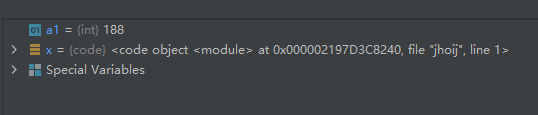

从上面的示例代码我们可以看出,当对语句 print(a1) 执行了形式为eval的compile操作后,得到了对象x,此时用eval()函数调用对象x,就相当于执行了语句print(a1)。那这样的操作有什么意义呢?
网上查到一个观点如下:
当执行字符串形式的代码时,每次都必须对这些代码进行字节编译处理。compile()函数提供了一次性字节代码预编译,以后每次调用的时候,都不用编译了。
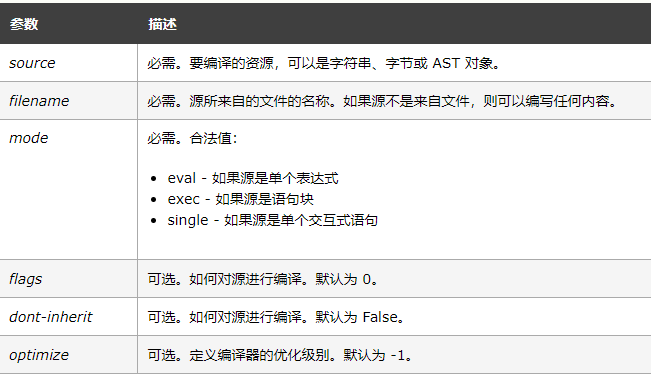
但是博主(昊虹君)觉得这个说法有点问题,从上面的例子来看,每次运行这个脚本的时候还是会去执行一次compile()函数,那还是每次都去编译了啊,除非它的结果被缓存在某个地方。compile()函数语法如下:
compile(source, filename, mode[, flags[, dont_inherit,[ optimize]]])- 1
参数意义如下:
12-函数complex():通过指定复数的实部和虚部来得到复数
复数是Python中数值类型的一种。可以用函数complex()通过指定复数的实部和虚部来得到复数。
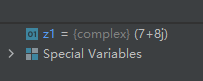
示例代码如下:z1 = complex(7, 8) print(z1)- 1
- 2
运行结果如下:

13-函数delattr():从指定的对象中删除指定的属性属性或方法
语法如下:
delattr(object, name)- 1
object – 对象。
name – 必须是对象的属性。
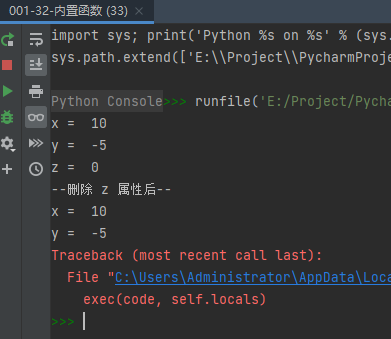
示例代码如下:class Coordinate: x = 10 y = -5 z = 0 point1 = Coordinate() print('x = ', point1.x) print('y = ', point1.y) print('z = ', point1.z) delattr(Coordinate, 'z') print('--删除 z 属性后--') print('x = ', point1.x) print('y = ', point1.y) # 触发错误 print('z = ', point1.z)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
运行结果如下:
14-函数dict():创建字典
函数dict()的详情请参见博文 https://blog.csdn.net/wenhao_ir/article/details/125412774 的“01-附2”
15-函数dir():查询一个类或一个对象有哪些属性(方法(成员函数)、变量))
函数dir()的详情请参见博文 https://blog.csdn.net/wenhao_ir/article/details/125421060
16-函数divmod():返回除法的商和余数
示例代码如下:
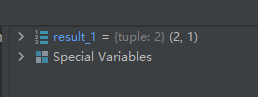
result_1 = divmod(5, 2)- 1
运行结果如下:
17-函数enumerate():将可迭代对象转化为枚举对象
关于函数enumerate()的详细介绍,请参见我的另一篇博文:https://blog.csdn.net/wenhao_ir/article/details/125443427
18-函数eval():执行函数compile()后的代码对象
详见对函数compile()的介绍,具体来说是这篇博文中的第11个。
19-函数exec():执行函数compile()后的代码对象
20-函数filter():过滤掉可迭代对象中不符合条件的元素
filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回一个迭代器对象,如果要转换为列表,可以使用 list() 来转换。
该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判断,然后返回 True 或 False,最后将返回 True 的元素放到新列表中。
示例代码如下:
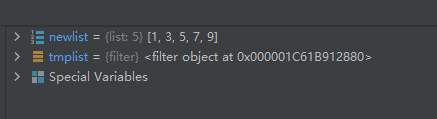
def is_odd(n): return n % 2 == 1 tmplist = filter(is_odd, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]) newlist = list(tmplist) print(newlist)- 1
- 2
- 3
- 4
- 5
- 6
- 7
运行结果如下:
这个函数与列表(list)的方法sort()的第一个参数key的使用挺类似的,详情见博文https://blog.csdn.net/wenhao_ir/article/details/12540609221-函数float():将整数或字符串转换成浮点数
什么?字符串也可以转换成浮点数,是的,你没看错,看下面的示例你就知道了。
int1 = 112 str1 = '123' float_1 = float(int1) float_2 = float(str1)- 1
- 2
- 3
- 4
- 5
运行结果如下:
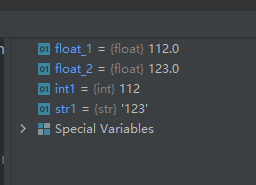
从上面的运行结果我们可以看出,字符串’123’被转换成了浮点数123.0,这就是Python的灵活之处,同样的功能,在C++中则需要使用类stringstream来实现,详情见我的另一篇博文 https://blog.csdn.net/wenhao_ir/article/details/12450845722-函数format():字符串格式化函数
关于函数format(),我已在博文https://blog.csdn.net/wenhao_ir/article/details/125390532中详细介绍过,这里就不再重复介绍了。
23-函数frozenset():返回一个被冻结的可迭代对象
函数frozenset()用于由原可迭代对象返回一个被冻结的可迭代对象,处于冻结状态的可迭代对象不能添加或删除任何元素。
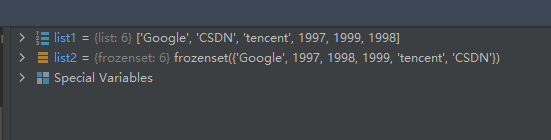
示例代码如下:list1 = ['Google', 'CSDN', 'tencent', 1997, 1999, 1998] list2 = frozenset(list1) list2[0] = 'facebook'- 1
- 2
- 3
- 4
- 5
- 6
运行结果如下:

24-函数getattr():获取对象的某个属性的值
示例代码如下:
class A(object): bar = 1 a1 = A() b1 = getattr(a1, 'bar')- 1
- 2
- 3
- 4
- 5
- 6
运行结果如下:
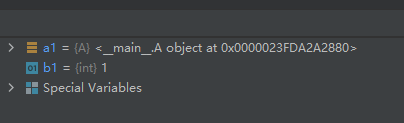
如果您想设置对象的属性值,可以用函数setattr()来设置哦!函数setattr()见本篇博文第56个函数25-函数globals():返回程序当前运行位置的所有全局变量
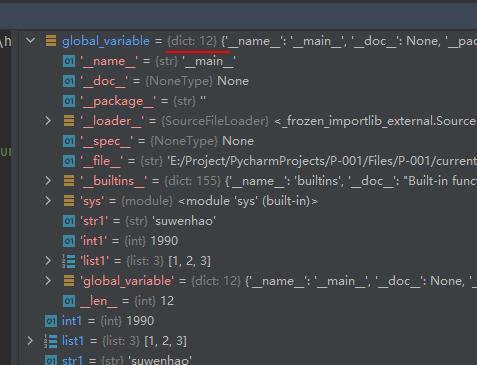
globals() 函数会以字典类型返回当前位置的全部全局变量。
示例代码如下:str1 = 'suwenhao' int1 = 1990 list1 = [1, 2, 3] global_variable = globals()- 1
- 2
- 3
- 4
- 5
运行结果如下:
26-函数hasattr():判断对象是否具有某属性
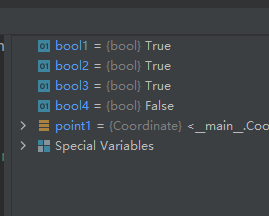
函数hasattr()的示例代码如下:
class Coordinate: x = 10 y = -5 z = 0 point1 = Coordinate() bool1 = hasattr(point1, 'x') bool2 = hasattr(point1, 'y') bool3 = hasattr(point1, 'z') bool4 = hasattr(point1, 'no') # 没有该属性- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
运行结果如下:
27-函数hash():获取对象(通常为字符的哈希值
示例代码如下:
hash1 = hash('swh') hash2 = hash(2487872782)- 1
- 2
- 3
将上面的代码运行两次,结果分别如下:
第一次的运行结果:
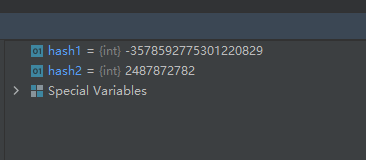
第二次运行的结果:
从上面两次的运行结果我们可以看出,一个字符串的hash值并不是唯一的,整数的hash值还是其本身。28-函数help():用于查看函数、类、对象等的说明
示例代码如下:
help('sys') # 查看sys模块的帮助 help('str') # 查看str类的帮助 a = [1, 2, 3] help(a) # 查看列表list的帮助 help(a.append) # 查看list的append方法的帮助- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
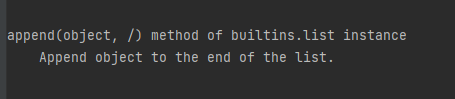
下面两行代码
a = [1, 2, 3] help(a.append) # 查看list的append方法的帮助- 1
- 2
- 3
的运行结果如下:
29-函数hex():返回一个数字的16进制表示
示例代码如下:
hex1 = hex(10)- 1
运行结果如下:
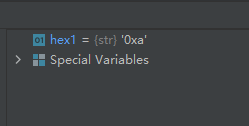
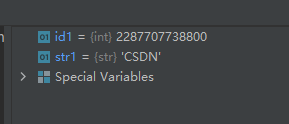
注意:函数hex()返回的是一个字符串对象。30-函数id():返回对象的id(内存地址)
示例代码如下:
str1 = 'CSDN' id1 = id(str1)- 1
- 2
运行结果如下:
31-函数input():接受输入数据(如来自键盘的输入),返回string类型
示例代码如下:
str1 = input("input:")- 1
运行结果如下:
第一次运行(输入字符串):
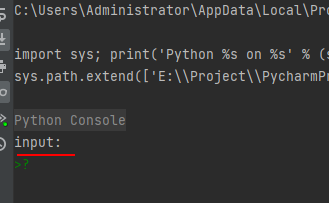
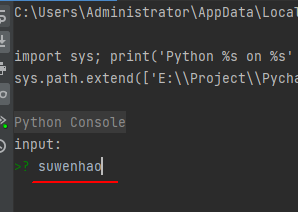

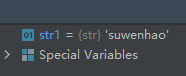
第二次运行(输入数字)
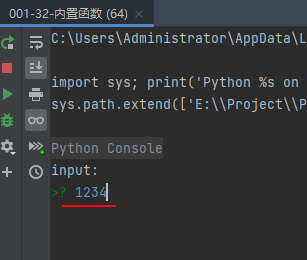

从第二次的运行结果我们可以看出,输入的数字也被当成字符串处理了。不过不要紧,我们可以用函数float()或函数int()将字符串型数字转化为float型和int型嘛。32-函数int():将浮点数或字符串转换为整数
语法如下:
int(x, base=10)- 1
参数意义:
x – 字符串或数字。
base – 代表x为哪种进制的数,注意不是表示返回傎的进制示例代码如下:
int1 = int(3.6) int2 = int('20') int3 = int('12', 16) #16进制的12换算成10进制是18 int4 = int('0xa', 16)- 1
- 2
- 3
- 4
运行结果如下:
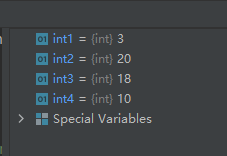
从上面的运行结果可以看出,函数int()在将浮点数转换为整数时,对于小数部分是直接舍弃处理的,而不是四舍五入。33-函数isinstance():判断一个对象是否是某个类的实例
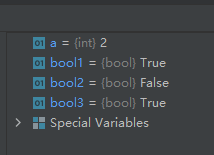
示例代码如下:
a = 2 bool1 = isinstance(a, int) bool2 = isinstance(a, str) bool3 = isinstance(a, (str, int, list)) # 只要是元组中的一个就返回True- 1
- 2
- 3
- 4
运行结果如下:
34-函数issubclass():判断某个类是否是另一个类的子类
语法如下:
issubclass(class1, class2)- 1
如果 class1 是 class2 的子类返回 True,否则返回 False。
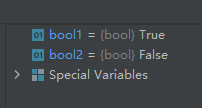
示例代码如下:class A: pass class B(A): pass class C: pass bool1 = issubclass(B, A) bool2 = issubclass(B, C)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
运行结果如下:
35-函数iter():用于生成可迭代对象的迭代器对象
这个函数用于生成可迭代对象的迭代器对象。以list对象为例,如果我们想通过迭代器遍历它,怎么操作呢?方法之一就是先生成其迭代器对象,然后用内置函数next()进行遍历操作。
内置函数next()的语法如下:
next(iterable[, default])- 1
iterable – 可迭代对象
default – 可选,用于设置在没有下一个元素时返回该默认值,如果不设置,又没有下一个元素则会触发 StopIteration 异常。再看函数iter()的语法:
iter(object[, sentinel])- 1
根据是否存在第二个实参,第一个实参的解释是非常不同的。
如果没有第二个实参,object 必须是支持迭代协议(有 __iter__() 方法)的集合对象(比如列表、元组、集合都是有 __iter__() 方法的,博文https://blog.csdn.net/wenhao_ir/article/details/125421060的第一个示例代码的运行结果便证明了这一点),或必须支持序列协议(有 __getitem__() 方法,且数字参数从 0 开始)。如果它不支持这些协议,会触发 TypeError。
如果有第二个实参 sentinel,那么 object 必须是可调用的对象。这种情况下生成的迭代器,每次迭代调用它的 __next__() 方法时都会不带实参地调用 object;如果返回的结果是 sentinel 则触发 StopIteration,从而停止迭代,否则返回调用结果.。
适合 iter() 的第二种形式的应用之一是构建块读取器。 例如,从二进制数据库文件中读取固定宽度的块,直至到达文件的末尾,这种情况下的示例如下:from functools import partial with open('mydata.db', 'rb') as f: for block in iter(partial(f.read, 64), 'b'): process_block(block)- 1
- 2
- 3
- 4
上面的函数partial()会被不带参数的迭代下去,直到其返回值为’b’才停止迭代。
再回头来说第一种情况,使用函数iter()和函数next()对列表进行迭代的示例代码如下:
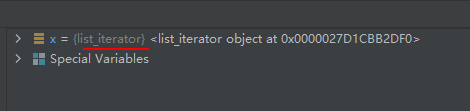
x = iter(["apple", "banana", "cherry"]) print(next(x)) print(next(x)) print(next(x))- 1
- 2
- 3
- 4
- 5
运行结果如下:
36函数len():返回对象(字符串、列表、元组、字典、集合等)的长度
这个在前面关于字符串、列表、元组、字典、集合的介绍时已经介绍过了,详情见下面的链接:
https://blog.csdn.net/wenhao_ir/article/details/125396412(这篇博文中的第14-3点中用到了len()测量字符串长度)
https://blog.csdn.net/wenhao_ir/article/details/125400072
https://blog.csdn.net/wenhao_ir/article/details/125407815
https://blog.csdn.net/wenhao_ir/article/details/125412774
https://blog.csdn.net/wenhao_ir/article/details/125424671
所以这里就不再举例了。37-函数list():用于将元组或字符串转换为列表
示例代码如下:
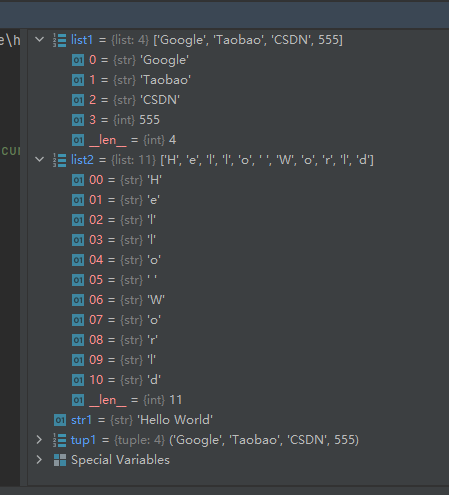
tup1 = ('Google', 'Taobao', 'CSDN', 555) list1 = list(tup1) str1 = "Hello World" list2 = list(str1)- 1
- 2
- 3
- 4
- 5
运行结果如下:
相关函数:
62-函数tuple():把可迭代对象转换为元组38-函数locals():返回程序前当前运行位置的局部变量
locals() 函数会以字典类型返回当前位置的全部局部变量。
示例代码如下:def fun1(arg): # 两个局部变量:arg、z z = 1 print(locals()) fun1(6)- 1
- 2
- 3
- 4
- 5
- 6
运行结果如下:
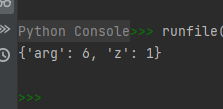
39-函数map():将某可迭代对象通过某一函数映射到另一迭代对象
map() 函数会根据提供的函数对指定序列做映射。它的第一个参数和list的方法sort()、filter()函数的第一个参数使用类似。
sort()方法的详细介绍见博文 https://blog.csdn.net/wenhao_ir/article/details/125406092
filter()函数上面已经介绍过了。示例代码一如下:
def square(x): # 计算平方数 return x ** 2 iter1 = map(square, [1, 2, 3, 4, 5]) list1 = list(iter1)- 1
- 2
- 3
- 4
- 5
- 6
运行结果如下:
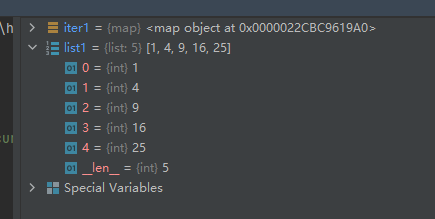
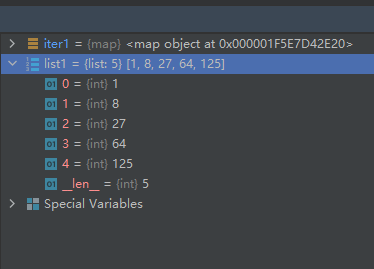
示例代码二如下(匿名函数):iter1 = map(lambda x: x ** 3, [1, 2, 3, 4, 5]) list1 = list(iter1)- 1
- 2
运行结果如下:
40-函数max():返回给定参数的最大值
这个函数在之前对字符串、列表、元组的介绍中均有提及,在字符串中它是作为字符类的方法出现的,不过它也可作用于字符串对象。
下面给一个综合性的示例代码。
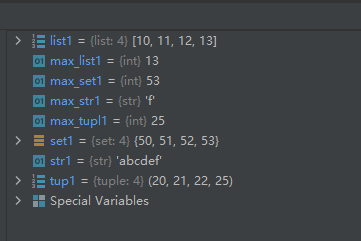
str1 = 'abcdef' max_str1 = max(str1) list1 = [10, 11, 12, 13] max_list1 = max(list1) tup1 = (20, 21, 22, 25) max_tupl1 = max(tup1) set1 = {50, 51, 52, 53} max_set1 = max(set1)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
运行结果如下:
41-函数memoryview():返回给定参数的内存查看对象(memory view)
所谓内存查看对象,是指对支持缓冲区协议的数据进行包装,然后可以按字节进行查看。
示例代码如下:v = memoryview(bytearray("abcefg", 'utf-8')) v_01 = v[1] v_02 = v[2]- 1
- 2
- 3
- 4
运行结果如下:
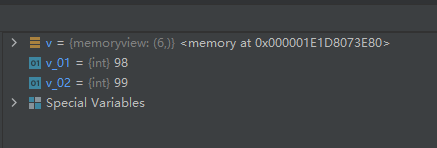
个人感觉在Pycharm-IDE中这个作用不是很大,因为我在IDE中可以很方便的查看对象的内存情况。42-函数min():返回给定参数的最小值
函数min()与第40个max()的使用一模一样,只是它返回的是最小值,所以这里就不再介绍,也不给示例代码了。
43-函数next():返回迭代器的下一个项目
函数next()在介绍35-函数iter()时已经介绍过了,这里就不再介绍了。
44-函数object():创建一个空的对象
object() 函数返回一个空对象。
您不能向这个对象添加新的属性或方法,这个函数不接受任何实参。
这个对象是所有类的基础,它拥有所有类默认的内置属性和方法。
示例代码如下:x = object()- 1
运行结果如下:

45-函数oct():将一个整数转换成 8 进制字符串
函数oct()将一个整数转换成 8 进制字符串,8 进制以 0o 作为前缀表示。
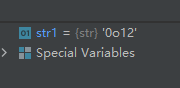
示例代码如下:str1 = oct(10)- 1
运行果如下:
46-函数open():打开一个文件,并返回文件对象
open()函数用于打开一个文件,并返回文件对象,在对文件进行处理过程都需要使用到这个函数,如果该文件无法被打开,会抛出 OSError。
注意:文件对象使用完后,一定要调用close()函数关闭文件。
open()函数常用的形式是接收两个参数:文件名(file)和模式(mode)。open(file, mode='r')- 1
完整的语法格式如下:
pen(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)- 1
file—文件的路径或名称。
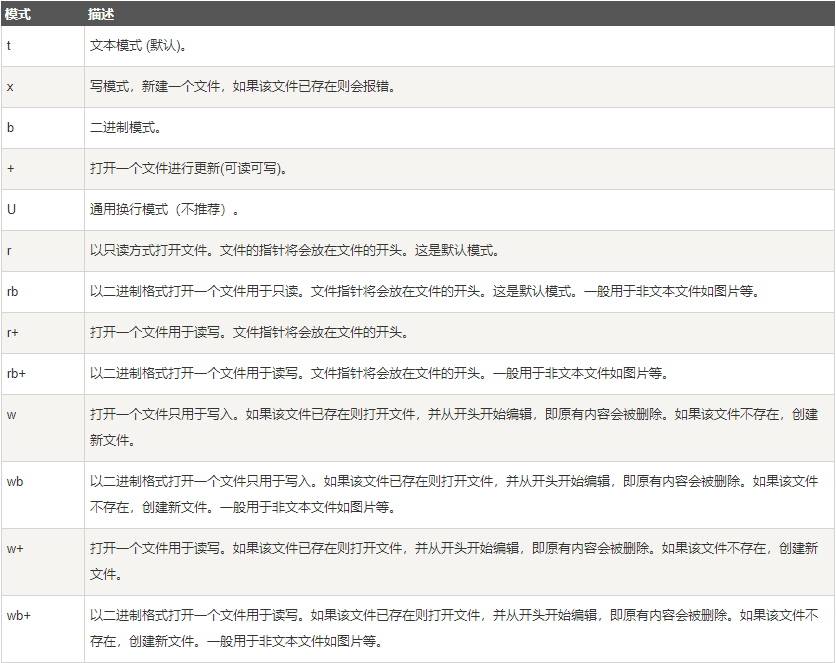
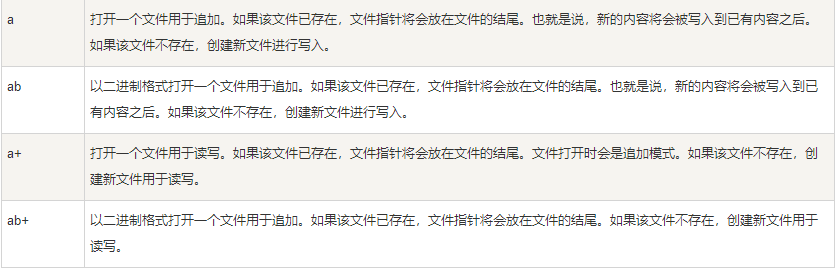
mode—文件打开模式,其具体内容如下:
补充说明:
mode 是一个可选字符串,用于指定打开文件的模式。
默认值是 ‘r’ ,与 ‘rt’ 同义,这意味着它以文本模式打开并读取文件。
其他常见模式有:写入 ‘w’ 、排它性创建 ‘x’ 、追加写 ‘a’(在 一些 Unix 系统上,无论当前的文件指针在什么位置,所有 写入都会追加到文件末尾)。接下来继续介绍函数open()的其它参数。
在文本模式,如果 encoding 没有指定,则根据平台来决定使用的编码:使用 locale.getpreferredencoding(False) 来获取本地编码。
要读取和写入原始字节,请使用二进制模式并不要指定 encoding。
以二进制模式打开的文件(包括 mode 参数中的 ‘b’ )返回的内容为 bytes 对象,不进行任何解码。在文本模式下(默认情况下,或者在 mode 参数中包含 ‘t’ )时,文件内容返回为 str ,首先使用指定的 encoding (如果给定)或者使用平台默认的的字节编码解码。模式 ‘w+’ 与 ‘w+b’ 将打开文件并清空内容。
模式 ‘r+’ 与 ‘r+b’ 将打开文件并不清空内容。buffering—这个参数用于设置缓冲。
encoding— encoding 是用于解码或编码文件的编码的名称,一般使用utf8。这应该只在文本模式下使用。默认编码是依赖于平台的(而不管 locale.getpreferredencoding() 返回何值),但可以使用任何Python支持的 text encoding 。有关支持的编码列表,请参阅Pythoncodecs 模块。
errors–是一个可选的字符串参数,用于指定如何处理编码和解码错误 - 这不能在二进制模式下使用。可以使用各种标准错误处理程序(列在 错误处理方案 ),但是使用 codecs.register_error() 注册的任何错误处理名称也是有效的。标准名称包括:
- ‘strict’:如果存在编码错误,‘strict’ 会引发 ValueError 异常, 默认值 None 具有相同的效果。
- ‘ignore’: 忽略错误。请注意,忽略编码错误可能会导致数据丢失。
- ‘replace’ :会将替换标记(例如 ‘?’ )插入有错误数据的地方。
- ‘surrogateescape’: 将把任何不正确的字节表示为 U+DC80 至 U+DCFF 范围内的下方替代码位。 当在写入数据时使用 surrogateescape 错误处理句柄时这些替代码位会被转回到相同的字节。 这适用于处理具有未知编码格式的文件。
- ‘xmlcharrefreplace’:只有在写入文件时才支持 ‘xmlcharrefreplace’。编码不支持的字符将替换为相应的XML字符引用 &#nnn;
- ‘backslashreplace’ :用Python的反向转义序列替换格式错误的数据。
- ‘namereplace’ (也只在编写时支持)用 \N{…} 转义序列替换不支持的字符。
newline—控制文件的换行,即 universal newlines 模式如何生效(它仅适用于文本模式)。它可以是 None,‘’,‘\n’,‘\r’ 和 ‘\r\n’。它的工作原理如下:
从流中读取输入时,如果 newline 为 None,则启用通用换行模式。输入中的行可以以 ‘\n’,‘\r’ 或 ‘\r\n’ 结尾,这些行被翻译成 ‘\n’ 在返回呼叫者之前。如果它是 ‘’,则启用通用换行模式,但行结尾将返回给调用者未翻译。如果它具有任何其他合法值,则输入行仅由给定字符串终止,并且行结尾将返回给未调用的调用者。
将输出写入流时,如果 newline 为 None,则写入的任何 ‘\n’ 字符都将转换为系统默认行分隔符 os.linesep。如果 newline 是 ‘’ 或 ‘\n’,则不进行翻译。如果 newline 是任何其他合法值,则写入的任何 ‘\n’ 字符将被转换为给定的字符串。closefd—如果 closefd 是 False 并且给出了文件描述符而不是文件名,那么当文件关闭时,底层文件描述符将保持打开状态。如果给出文件名则 closefd 必须为 True (默认值),否则将引发错误。
opener—可以通过传递可调用的 opener 来使用自定义开启器。然后通过使用参数( file,flags )调用 opener 获得文件对象的基础文件描述符。 opener 必须返回一个打开的文件描述符(使用 os.open as opener 时与传递 None 的效果相同)。
47-函数ord():返回字符的ASCII 数值或者Unicode数值
ord() 函数是chr() 函数对于 8 位的 ASCII 字符串)的配对函数[函数chr()见本文的第10个],它以一个字符串(Unicode 字符)作为参数,返回对应的 ASCII 数值,或者 Unicode 数值。
示例代码如下:int1 = ord('a') char1 = chr(int1)- 1
- 2
- 3
运行结果如下:

48-函数pow():返回x的y次方值,还可对结果作取余除法
语法如下:
pow(x, y[, z])- 1
计算x的y次方,如果z在存在,则再对结果进行取模,其结果等效于pow(x,y) %z
示例代码如下:
int1 = pow(2, 3) int2 = pow(2, 3, 6)- 1
- 2
运行结果如下:
49-函数print():打印输出对象
函数print()的详细介绍见我的另一篇博文:https://blog.csdn.net/wenhao_ir/article/details/125390532
50-函数property():获取、设置、删除类的某个属性
函数property()通常用于获取、设置、删除类的某个属性。
函数property()的语法如下:
class property([fget[, fset[, fdel[, doc]]]])- 1
参数:
fget – -获取属性值的函数(函数的功能并不一定是真正的去获取属性值,看了示例代码就容易理解这一点)
fset —设置属性值的函数(函数的功能并不一定是真正的去设置属性值,看了示例代码就容易理解这一点)
fdel — 删除属性值函数(函数的功能并不一定是真正的去删除属性,看了示例代码就容易理解这一点)
doc — 属性描述信息。示例代码如下:
class C(object): def __init__(self): self._x = None def getx(self): return self._x def setx(self, value): self._x = value def delx(self): del self._x x = property(getx, setx, delx, "I'm the 'x' property.")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
如果 c 是 C 的实例化, 则
c.x 将调用getx(),
c.x = value 将调用setx()
del c.x 将调用delx()
如果给定 doc 参数,其将成为这个属性值的 docstring,否则 property 函数就会复制 fget 函数的 docstring(如果有的话)。继续完善示例代码如下:
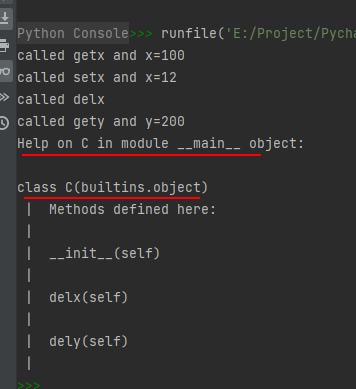
# 博主微信/QQ 2487872782 # 有问题可以联系博主交流 class C(object): def __init__(self): self._x = 100 self._y = 200 def getx(self): print('called getx and x={}'.format(self._x)) def setx(self, value): self._x = value print('called setx and x={}'.format(self._x)) def delx(self): del self._x print('called delx') def gety(self): print('called gety and y={}'.format(self._y)) def sety(self, value): self._y = value print('called sety and y={}'.format(self._y)) def dely(self): del self._y print('called dely') x = property(getx, setx, delx, "I'm the 'x' property.") y = property(gety, sety, dely, "I'm the 'y' property.") c = C() c.x c.x = 12 del c.x c.y help(c)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
运行结果如下:
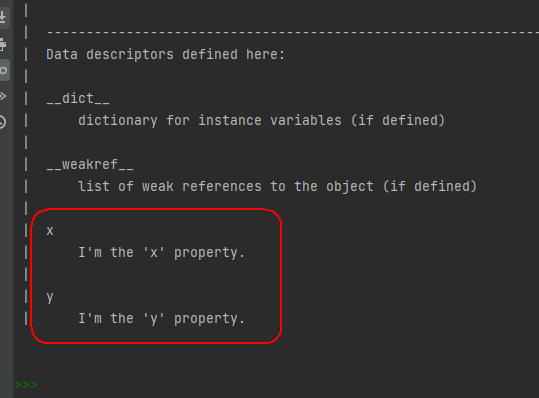
上面的代码中我定义了两个与函数property()有关的属性名,分别为x和y,并且我还为x和y设置了三个函数,以x为例,这三个函数分别通过
c.x
c.x = 12
del c.x
来调用。51-函数range():返回一个可迭代对象
注意:
Python3 range() 函数返回的是一个可迭代对象,而不是列表对象,可以用函数list()将其转化为列表。
Python2 range() 函数返回的则是列表。
语法如下(有两种形式):
range(stop)
range(start, stop[, step])
start—计数从 start 开始。默认是从 0 开始。例如range(5)等价于range(0, 5);
stop:—计数到 stop 结束,但不包括 stop。例如:range(0, 5是[0, 1, 2, 3, 4],注意没有包括5。
step—步长,默认为1。例如:range(0, 5) 等价于 range(0, 5, 1)示例代码如下:
rang1 = range(5) list1 = list(rang1) for i in range(1, 4, 1): print(i)- 1
- 2
- 3
- 4
- 5
运行结果如下:
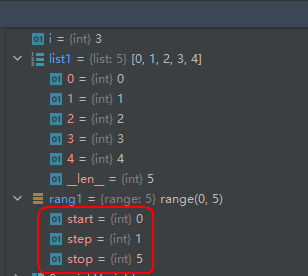
52-函数repr(): 将对象字符串化(文本化)【repr应该是return print的缩写】
示例代码如下:
dict1 = {'name': 'suwenhao', 'likes': 'reading', 123: 456} str1 = repr(dict1) print(str1) list1 = ['Google', 'CSDN', 1997, 1999] str2 = repr(list1) print(str2)- 1
- 2
- 3
- 4
- 5
- 6
- 7
运行结果如下:
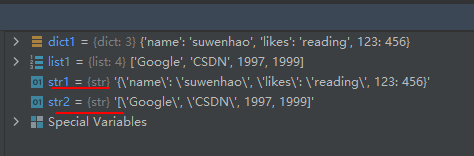
示例代码如下:
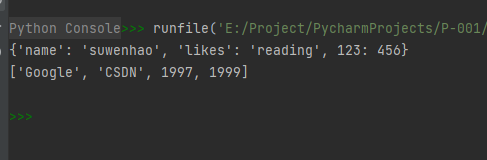
内置函数str()和这个函数的功能差不多,函数str()的介绍见本博文第59点。53-函数reversed():获得对象的反转迭代器(作用就是反转迭代器)
示例代码如下:
str1 = 'abcdefg' str1_reverse = reversed(str1) str1_reverse_list = list(str1_reverse) list1 = [1, 2, 3, 4, 5] list1_reverse = reversed(list1) list1_reverse_list = list(list1_reverse) tup1 = ('A', 'B', 'C', 'D') tup1_reverse = reversed(tup1) tup1_reverse_list = list(tup1_reverse)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
运行结果如下图所示:
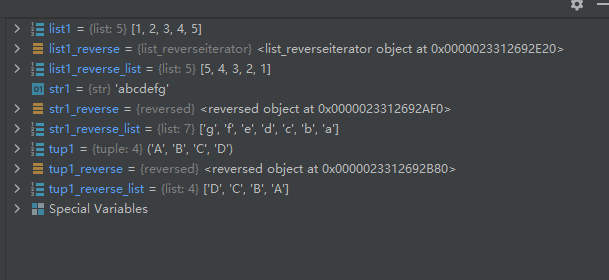
54-函数round():返回浮点数的五舍六入值(可控制小数位数)
语法如下:
round( x [, n] )- 1
参数意义:
x — 待处理的浮点数。
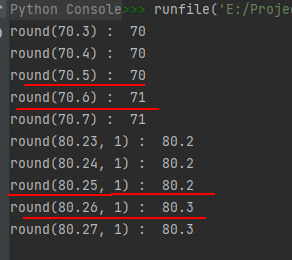
n — 表示需保留的小数位数,默认值为0,即不保留小数部分。注意:它做的是五舍六入的近似运算,而不是四舍五入,大家看下面的示例代码就知道了。
示例代码如下:
print("round(70.3) : ", round(70.3)) print("round(70.4) : ", round(70.4)) print("round(70.5) : ", round(70.5)) print("round(70.6) : ", round(70.6)) print("round(70.7) : ", round(70.7)) print("round(80.23, 1) : ", round(80.23, 1)) print("round(80.24, 1) : ", round(80.24, 1)) print("round(80.25, 1) : ", round(80.25, 1)) print("round(80.26, 1) : ", round(80.26, 1)) print("round(80.27, 1) : ", round(80.27, 1))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
运行结果如下:
55-函数set():创建集合对象
函数set()在博文 https://blog.csdn.net/wenhao_ir/article/details/125424671 中已经介绍过了,这里就不再重复介绍了。
56-函数setattr():设置对象的属性值
函数setattr()对应函数getattr(),用于设置属性值,该属性不一定是存在的哦。
语法如下:setattr(object, name, value)- 1
参数意义如下:
object – 对象。
name – 字符串,对象属性。
value – 属性值
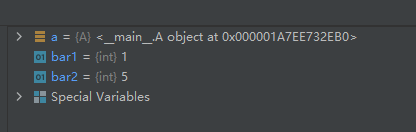
示例代码如下:class A(object): bar = 1 a = A() bar1 = getattr(a, 'bar') # 获取属性bar的值 setattr(a, 'bar', 5) # 设置对象a的属性bar的值 bar2 = getattr(a, 'bar') # 再次获取属性bar的值- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
运行结果如下:
57- 函数slice():辅助切片操作
slice() 函数实现切片对象,主要用在切片操作函数里的参数传递。
语法如下:
有两种形式:slice(stop)- 1
slice(start, stop[, step])- 1
参数意义:
start – 起始索引值
stop – 结束索引值
step – 索引间距示例代码如下:
list1 = [10, 20, 30, 40, 50, 60, 70, 80, 90, 100] slice1 = slice(5) list_sub1 = list1[slice1] slice2 = slice(1, 8, 2) list_sub2 = list1[slice2]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
运行结果如下:
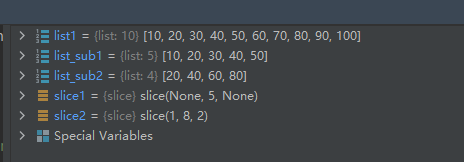
这里分析下list_sub2是怎么得到的?
索引区间为[1, 8) 注意是左闭右开区间。
索引步长为2,则有效索引值为1、1+2=3、3+2=5、5+2=7
索引值1、3、5、7对应的元素值分别为:10、40、60、80
所以list_sub2为[20, 40, 60, 80]
当然,我们一般都不用这个切片对象,而直接写出切片表达式,
即我们通常把语句:slice2 = slice(1, 8, 2) list_sub2 = list1[slice2]- 1
- 2
写成:
list_sub2 = list1[1:8:2]- 1
58-函数sorted():对可迭代对象的元素进行排序操作
函数sorted()的用法和列表中的方法sort()的使用方法和功能是基本一样的。
不同之处在于函数sorted()可以对所有的可迭代对象元素进行排序,并且它会返回一个新的列表。而列表中的方法sort()它只能针对列表,并且对原列表对象进行操作。
所以这里就不再对函数sorted()进行介绍了,大家可参考我的另一篇博文https://blog.csdn.net/wenhao_ir/article/details/125400072中第16点对方法sort()的介绍。59-函数str():将对象转化为string对象(字符串对象)
内置函数repr()和这个函数的功能差不多,函数repr()的介绍见本博文第52点。
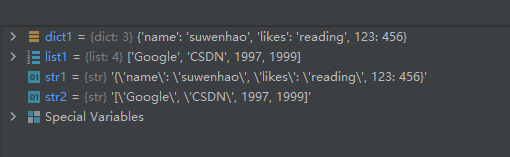
示例代码如下:dict1 = {'name': 'suwenhao', 'likes': 'reading', 123: 456} str1 = str(dict1) print(str1) list1 = ['Google', 'CSDN', 1997, 1999] str2 = str(list1) print(str2)- 1
- 2
- 3
- 4
- 5
- 6
- 7
运行结果如下:
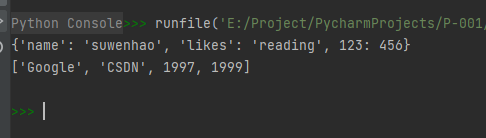
内置函数repr()和这个函数的功能差不多,函数repr()的介绍见本博文第52点。60-函数sum():对可迭代对象求和
语法如下:
sum(iterable, start)- 1
参数意义如下:
iterable—必需。需求和的可迭代对象(序列)。
start—可选。添加到返回值的值。
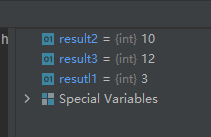
示例代码如下:resutl1 = sum([0, 1, 2]) result2 = sum((2, 3, 4), 1) # 元组对象计算总和后再加1 result3 = sum([0, 1, 2, 3, 4], 2) # 列表计算总和后再加2- 1
- 2
- 3
- 4
- 5
运行结果如下:
61-函数super():用于提供对父类或同胞类的方法和属性的访问
关于这个函数的详细介绍,可以查看我的另一篇博文:https://blog.csdn.net/wenhao_ir/article/details/125472478
62-函数tuple():把可迭代对象转换为元组
示例代码如下:
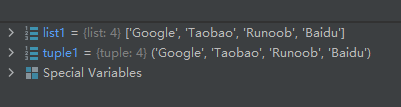
list1 = ['Google', 'Taobao', 'Runoob', 'Baidu'] tuple1 = tuple(list1)- 1
- 2
运行结果如下:
相关函数:
37-函数list():用于将元组或字符串转换为列表63-函数type():返回对象的类型
函数type()有两种语法:
type(object) type(name, bases, dict)- 1
- 2
第一种语法返回对象的类型,第二种语法返回新的类型对象。
第一种语法是常用的,第二种语法很少用,所以下面的示例代码只给第一种语法的示例代码:type1 = type(1) type2 = type([1, 2, 'swh']) type3 = type({0: 'zero'}) x = 1 bool1 = type(x) == int # 判断类型是否为int型- 1
- 2
- 3
- 4
- 5
- 6
运行结果如下:
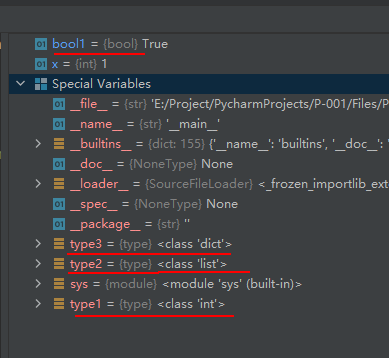
从上面的运行结果可以看出,函数type()返回的并不是字符串,而是type对象,type对象属于“Special Variables”。
并通,还可以用关系运算符“==”对类型进行判断哦。64-函数vars():返回类的 __dic__ 属性
示例代码如下:
class Person: name = "Bill" age = 19 country = "USA" x1 = dir(Person) # 返回类的所有属性 x2 = vars(Person) # 返回类的__dic__属性- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
运行结果如下:



资料上都说是返回对象的__dic__ 属性,但是我实测却返回不了,如下:class Person: name = "Bill" age = 19 country = "USA" object1 = Person() x1 = vars(object1)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
运行结果如下:
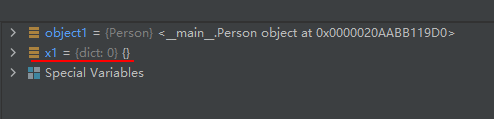
可能那些资料中的对象也把类认为是对象吧~在我的脑海里,认为类的实例化才叫对象。65-函数zip():打包多个可迭代对象
zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的对象,这样做的好处是节约了不少的内存。
我们可以使用 list() 转换来输出列表。
如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表。
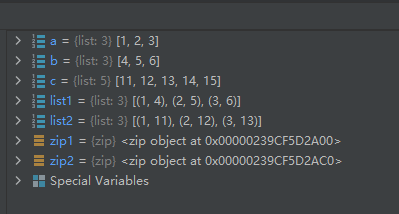
示例代码如下:a = [1, 2, 3] b = [4, 5, 6] c = [11, 12, 13, 14, 15] zip1 = zip(a, b) list1 = list(zip1) zip2 = zip(a, c) list2 = list(zip2)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
运行结果如下:
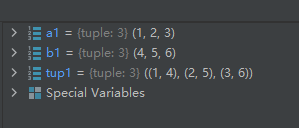
利用 * 号操作符,可以将元组解压为列表,示例代码如下:tup1 = ((1, 4), (2, 5), (3, 6)) a1, b1 = zip(*tup1)- 1
- 2
运行结果如下:
66-函数__import__():导入模块、脚本、类和函数等
虽然关键词import可以实现同样的功能,但是通常我们在程序的开头使用关键词import进入导入操作,如果我们想在程序中部,可以使用内置函数__import__(),这样会使程序看来顺眼。
其语法如下:__import__(name[, globals[, locals[, fromlist[, level]]]])- 1
可选参数意义暂时不作探究。
示例代码如下:
my_script.py中的代码如下:print('Successfully imported my_ script!') print('my_script execution completed!')- 1
- 2
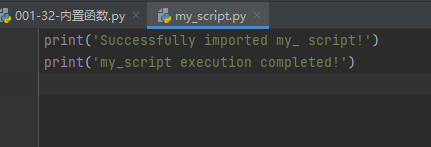
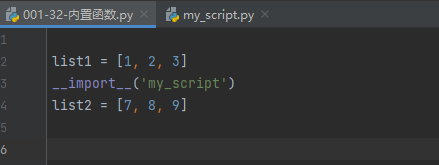
001-32-内置函数.py中的代码如下:
list1 = [1, 2, 3] __import__('my_script') list2 = [7, 8, 9]- 1
- 2
- 3
运行结果如下:


参考资料:https://blog.csdn.net/wenhao_ir/article/details/125100220 -
相关阅读:
C语言指针操作(五)*指向函数的指针
SpringBoot获取运行环境 获取静态配置 SpringBoot获取配置文件和属性值 springboot获取配置文件
关键性进展! 小米造车露真容 预计明年上市
【IoT开发工具箱 | 02】嵌入式网速测试方法
【原创】java+jsp+servlet简单图书管理系统设计与实现
【Pytorch with fastai】第 15 章 :深入探讨应用程序架构
HarmonyOS-使用call事件拉起指定UIAbility到后台
资源管理平台头部导航栏(1+X Web前端开发初级 例题)
渗透测试靶场环境搭建
QCC51XX---BLE_生活中的实例_医院的结构
- 原文地址:https://blog.csdn.net/wenhao_ir/article/details/125436091
