-
分布式锁最实用解决方案--redisson分布式锁(一)
分布式锁的由来
分布式锁主要是实现在分布式场景下保证数据的最终一致性。在单进程的系统中,存在多个线程可以同时改变某个变量(可变共享变量)时,就需要对变量或代码块做同步(lock—synchronized),使其在修改这种变量时能够线性执行消除并发修改变量。但分布式系统是多部署、多进程的,开发语言提供的并发处理API在此场景下就无能为力了。
目前常见的分布式锁
1.基于数据库实现分布式锁; --效率较低
2.基于缓存(Redis等)实现分布式锁; --好用且常用
3.基于Zookeeper实现分布式锁; --好用且常用Redisson介绍
大部分网站使用的分布式锁是基于缓存的,有更好的性能,而缓存一般是以集群方式部署,保证了高可用性。而Redis分布式锁官方推荐使用redisson。
Redisson原理图如下:
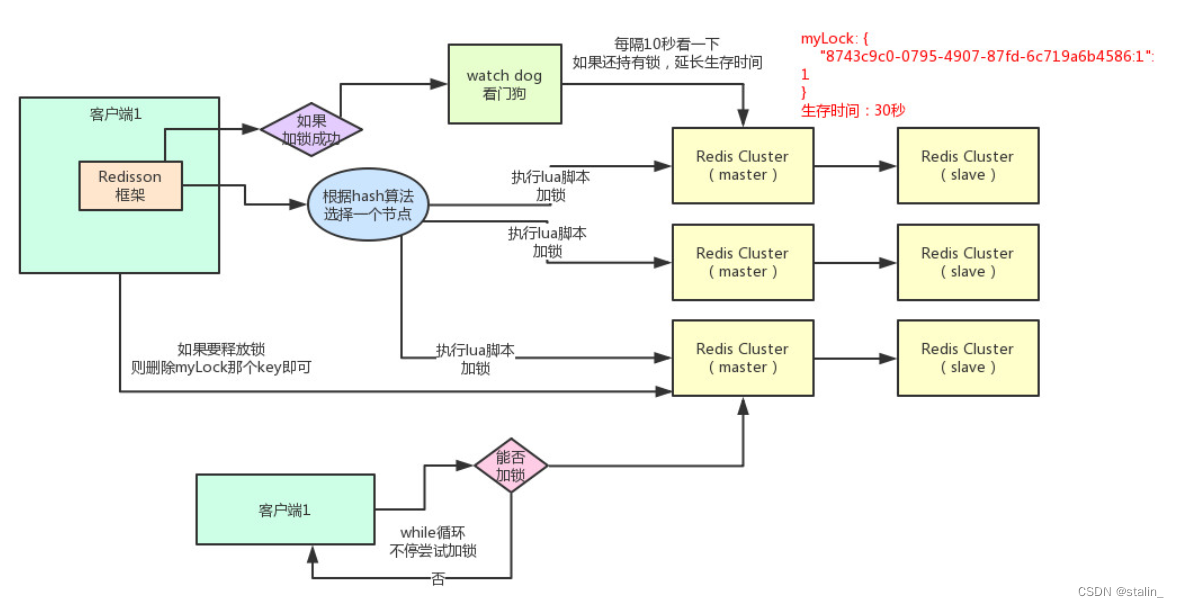
Redisson锁说明:
1、redission获取锁释放锁的使用和JDK里面的lock很相似,底层的实现采用了类似lock的处理方式
2、redisson 依赖redis,因此使用redisson 锁需要服务端安装redis,而且redisson 支持单机和集群两种模式下的锁的实现
3、redisson 在多线程或者说是分布式环境下实现机制,其实是通过设置key的方式进行实现,也就是说多个线程为了抢占同一个锁,其实就是争抢设置key。Redisson原理:
加锁:
if (redis.call('exists', KEYS[1]) == 0) then redis.call('hset', KEYS[1], ARGV[2], 1); redis.call('pexpire', KEYS[1], ARGV[1]); return nil; end; if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then redis.call('hincrby', KEYS[1], ARGV[2], 1); redis.call('pexpire', KEYS[1], ARGV[1]); return nil; end; return redis.call('pttl', KEYS[1]);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
将业务封装在lua中发给redis,保障业务执行的原子性。
第1个if表示执行加锁,会先判断要加锁的key是否存在,不存在就加锁。
当第1个if执行,key存在的时候,会执行第2个if,第2个if会获取第1个if对应的key剩余的有效时间,然后会进入while循环,不停的尝试加锁。
释放锁:
if (redis.call('exists', KEYS[1]) == 0) then redis.call('publish', KEYS[2], ARGV[1]); return 1; end; if (redis.call('hexists', KEYS[1], ARGV[3]) == 0) then return nil; end; local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1); if (counter > 0) then redis.call('pexpire', KEYS[1], ARGV[2]); return 0; else redis.call('del', KEYS[1]); redis.call('publish', KEYS[2], ARGV[1]); return 1; end; return nil;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
执行lock.unlock(),每次都对myLock数据结构中的那个加锁次数减1。如果发现加锁次数是0了,说明这个客户端已经不再持有锁了,此时就会用:“del myLock”命令,从redis里删除这个key,另外的客户端2就可以尝试完成加锁了。
缺点:
Redisson存在一个问题,就是如果你对某个redis master实例,写入了myLock这种锁key的value,此时会异步复制给对应的master slave实例。但是这个过程中一旦发生redis master宕机,主备切换,redis slave变为了redis master。接着就会导致,客户端2来尝试加锁的时候,在新的redis master上完成了加锁,而客户端1也以为自己成功加了锁。此时就会导致多个客户端对一个分布式锁完成了加锁。这时系统在业务上一定会出现问题,导致脏数据的产生。
-
相关阅读:
JavaWeb核心(1)
Android 11.0 禁止弹出系统simlock的锁卡弹窗功能实现
系统内存管理:虚拟内存、内存分段与分页、页表缓存TLB以及Linux内存管理
掌握Go语言:深入encoding/gob包的高效数据序列化
初识设计模式 - 单例模式
力扣 -- 1218. 最长定差子序列
RestTemplate源码debug:可变形参引发的问题
聊聊日志聚类算法及其应用场景
记一次Android项目升级Kotlin版本(1.5 -> 1.7)
腾讯mini项目-【指标监控服务重构-会议记录】2023-08-18
- 原文地址:https://blog.csdn.net/stalin_/article/details/125475896