-
索引+sql练习优化
目录
2.创建存储过程插入数据(利用上面两个函数得到随机编号以及名字)
优势劣势
通过索引提高数据检索效率,降低IO成本 ,但是用了索引也会降低更新的效率,每次修改都会导致我们的索引文件里面的信息发送变化,并且内存消耗up

索引也可以理解为一张表,里面的索引字段指向实体表记录
什么时候用索引

频繁作为查询条件的、关联查询的、分组排序的、唯一索引的
Expain性能分析
作用:
使用Explain关键字可以模拟优化器(就是之前那个Optimizer优化器)执行SQL查询语句,得到mysql是如何处理sql语句的,进行分析(查看执行计划)
使用:

分析字段:
id表示一趟独立的查询,一个sql的躺数越少越好

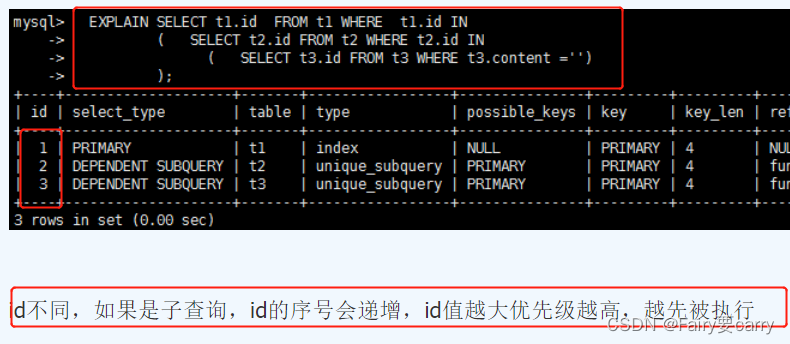
select_type

type
最关键三:range、index、all

key和key_len和rows
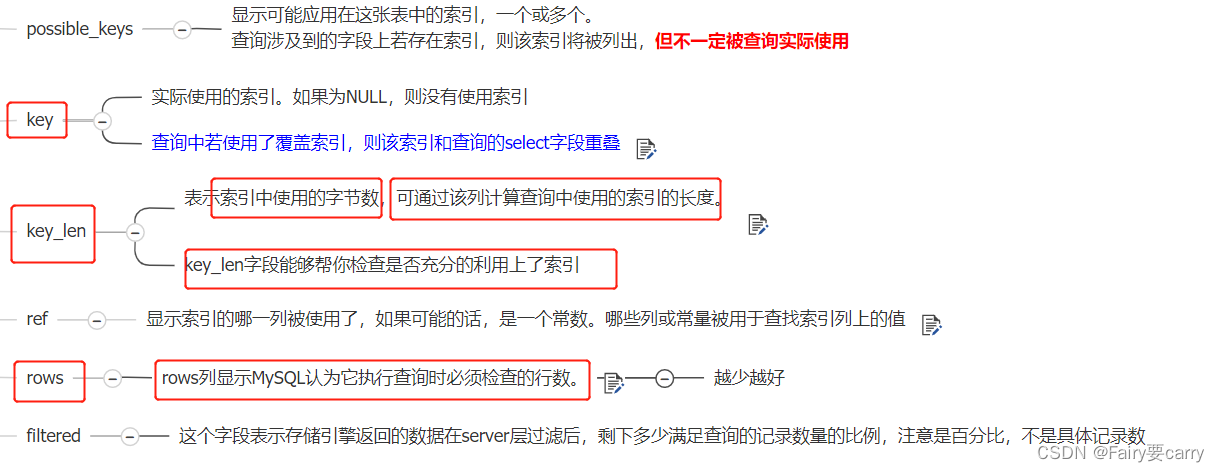
key_len如何计算索引长度

EXTRA

目的:减少全表扫描,增加性能

子查询(SUBQUERY):

范围查询(DEPENDENT SUBQUERY)

不可用缓存查询:
sql未命中,sql不一样——>当出现变量时,sql就肯定不一样了;
All问题:
All table scan,将全表进行遍历找到匹配的行;
index索引
出现index是sql使用了索引但是没有通过索引进行过滤,一般是使用了覆盖索引或者是利用索引进行排序分组;
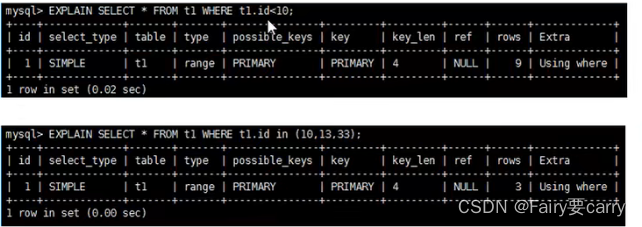
范围查询:
group by先进行排序后进行分组

用了索引之后发现速度发生百倍优化(reset cache)
两个表关联,关联字段要建索引
where条件后的字段用了索引
统计数量count(*):MyISAM的话,他统计了表中数据的数量,InnoDB没有统计会真的去打开表进行扫描
EXPLAIN SELECT * FROM t_dept字段解析 :

id指的是执行顺序,type指的是黄色红色黑色那些预警,key_len指的是where条件字段长度(长度越长,越容易命中),rows值的行数(物理扫描的行数,越少越好速度越快),Extra额外字段一般看group by,other by,关联查询;
插入100w数据如何做到最快
1.我们可以将100w条插入语句进行拼接,让他变为一条语句,速度肯定快一些
2.我们可以取消mysql的自动提交,因为100w条数据提交100w次和提交1次
肯定不一样;
3.使用多线程
mysql的主从复制
主机从机用一个binlog,里面有共有函数

1.创建函数(随机产生编号以及随机名字)

2.创建存储过程插入数据(利用上面两个函数得到随机编号以及名字)
- CREATE TABLE `dept` (
- `id` INT(11) NOT NULL AUTO_INCREMENT,
- `deptName` VARCHAR(30) DEFAULT NULL,
- `address` VARCHAR(40) DEFAULT NULL,
- ceo INT NULL ,
- PRIMARY KEY (`id`)
- ) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
- CREATE TABLE `emp` (
- `id` INT(11) NOT NULL AUTO_INCREMENT,
- `empno` INT NOT NULL ,
- `name` VARCHAR(20) DEFAULT NULL,
- `age` INT(3) DEFAULT NULL,
- `deptId` INT(11) DEFAULT NULL,
- PRIMARY KEY (`id`)
- #CONSTRAINT `fk_dept_id` FOREIGN KEY (`deptId`) REFERENCES `t_dept` (`id`)
- ) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
- #开启自定义函数配置的开启
- SET GLOBAL log_bin_trust_function_creators=1;
- #随机生成字符串函数
- DELIMITER $$
- CREATE FUNCTION rand_string(n INT) RETURNS VARCHAR(255)
- BEGIN
- DECLARE chars_str VARCHAR(100) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
- DECLARE return_str VARCHAR(255) DEFAULT '';
- DECLARE i INT DEFAULT 0;
- WHILE i < n DO
- SET return_str =CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1));
- SET i = i + 1;
- END WHILE;
- RETURN return_str;
- END $$
- USE mydb
- #用于随机产生多少到多少的编号
- DELIMITER $$
- CREATE FUNCTION rand_num (from_num INT ,to_num INT) RETURNS INT(11)
- BEGIN
- DECLARE i INT DEFAULT 0;
- SET i = FLOOR(from_num +RAND()*(to_num -from_num+1)) ;
- RETURN i;
- END$$
- #假如要删除
- #drop function rand_num;
- #假如要删除
- #drop function rand_string;
- #插入五十万条数据
- DELIMITER $$
- CREATE PROCEDURE insert_emp( START INT , max_num INT )
- BEGIN
- DECLARE i INT DEFAULT 0;
- #set autocommit =0 把autocommit设置成0,关闭自动提交
- SET autocommit = 0;
- REPEAT
- SET i = i + 1;
- INSERT INTO emp (empno, NAME ,age ,deptid ) VALUES ((START+i) ,rand_string(6) , rand_num(30,50),rand_num(1,10000));
- UNTIL i = max_num
- END REPEAT;
- COMMIT;
- END$$
- #删除
- # DELIMITER ;
- # drop PROCEDURE insert_emp;
- #执行存储过程,往dept表添加随机数据
- DELIMITER $$
- CREATE PROCEDURE `insert_dept`( max_num INT )
- BEGIN
- DECLARE i INT DEFAULT 0;
- SET autocommit = 0;
- REPEAT
- SET i = i + 1;
- INSERT INTO dept ( deptname,address,ceo ) VALUES (rand_string(8),rand_string(10),rand_num(1,500000));
- UNTIL i = max_num
- END REPEAT;
- COMMIT;
- END$$
- #删除
- # DELIMITER ;
- # drop PROCEDURE insert_dept;
- #插入1w条数据
- #执行存储过程,往dept表添加1万条数据
- DELIMITER ;
- CALL insert_dept(10000);
- #执行存储过程,往emp表添加50万条数据
- DELIMITER ;
- CALL insert_emp(100000,500000);
- SELECT COUNT(*) FROM emp;
- SELECT COUNT(*) FROM dept;

像这么多数据,我们进行查询就需要用到索引了,我们要执行下一个sql就要删除当前sql的索引
流程:
需要mysql承认你取出来的字符串

1. 查看表中索引
SHOW INDEX FROM t_emp;2.我们的索引也是一张表,在information数据库中,名字为STATISTICS
查看一下索引表,主键索引不能删除

3.创建索引
单字段下
先查询一下,发现explain估算49w多行
EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE emp.`age`=30;
CREATE INDEX idx_age ON emp(age);创建完索引后,就只有4w行了,速度up

0.03->0.007
多字段下
EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE emp.age=30 AND deptid=4 AND emp.name = 'abcd';CREATE INDEX idx_age_deptid_name ON emp(age,deptid,NAME);
速度由0.082->忽略不计
用图表示多字段索引的执行
最佳左前缀:从左边到右边按顺序执行,不然会断开
- 如果系统经常出现的sql如下:
- EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE emp.age=30 AND emp.name = 'abcd'
- 或者
- EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE emp.deptid=1 AND emp.name = 'abcd'
- 那原来的idx_age_deptid_name 还能否正常使用?
第二个不能正常执行,没有遵循从左到右的顺序执行 ,需要环环命中——>同时也体现出全值匹配,字段与索引一定要对应

练习
- #执行删除
- CALL proc_drop_index("mydb","emp");
- #在索引表中查询指定索引 (非主键)
- SELECT index_name FROM information_schema.`STATISTICS` WHERE TABLE_NAME='t_emp'
- AND TABLE_SCHEMA='mydb' AND INDEX_NAME <>'PRIMARY' AND SEQ_IN_INDEX=1;
- EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE emp.`age`=30; #0.03 0.007
- EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE emp.age=30 AND deptid=4
- EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE emp.age=30 AND deptid=4 AND emp.name = 'abcd';
- #创建索引
- CREATE INDEX idx_age ON emp(age);
- CREATE INDEX idx_age_deptid_name ON emp(age,deptid,NAME);
- SHOW INDEX FROM emp;
- #模糊查询
- EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE emp.`name` LIKE 'abc%';#0.8->0.016
- #这种会导致索引失效,别用函数
- EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE LEFT(emp.`name`,3)='abc';#0.8
- #创建索引
- CREATE INDEX idx_name ON emp(NAME);
- #执行删除
- CALL proc_drop_index("mydb","emp");
- CALL proc_drop_index("mydb","dept");
- #范围查询,范围右边的字段索引是失效的(这种右边是根据索引来判断的)
- EXPLAIN SELECT SQL_NO_CACHE * FROM emp #0.5->0.052,type:range
- WHERE emp.age=30 AND emp.deptId>20 AND emp.name = 'abc' ; #最佳效率0.004
- #创建索引
- CREATE INDEX idx_age_deptid_name ON emp(age,deptid,NAME);
- CREATE INDEX idx_age_deptid_name ON emp(age,NAME,deptid);
- EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE emp.`name` <> 'abc';
- #创建索引,对于上述失效!=会导致索引失效
- CREATE INDEX idx_name ON emp(NAME);
- EXPLAIN SELECT * FROM emp WHERE age IS NULL #0.2->0.001
- #这种为not都会失效
- EXPLAIN SELECT * FROM emp WHERE age IS NOT NULL;#0.04->0.009,索引失效,type为ALL
- #创建索引
- CREATE INDEX idx_age ON emp(age);
- #我们的索引结构平衡树是按照a-z,如果首字母都不能确定,索引就会失效
- EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE emp.`name` LIKE '%abc%';#0.329->0.274
- #创建索引
- CREATE INDEX idx_name ON emp(NAME);
- #执行删除
- CALL proc_drop_index("mydb","emp");
- CALL proc_drop_index("mydb","dept");
- #类型转换也会造成索引失效
- #有几个字段就建立几个字段的索引
索引是如何找到数据的
(24条消息) (3)MySQL是如何通过【索引】找到一条【真实的数据】_孤鸿寄语LWQ的博客-CSDN博客_mysql如何通过索引查询
注意事项
注意sql编写,防止索引失效

小总结
1. 记得最佳左前法则
2.不能使用函数:abs,max,<>....
3.不能用like前缀%xxx通配符
4.is not null不行
5.类型转换也不行

一些建议
1.当选择组合索引时,我们可以将过滤性较好的字段放在索引字段靠前位置,因为这样筛选出来到下一个树,可能节点就相对变少了,甚至为1,效率更高;
2.当选择组合索引,要尽量包含where后更多字段
3.尽量避免索引失效问题
关联查询
场景:
当两个表没有关联字段,然后进行关联查询,会两个表都进行全局扫描,从而出现笛卡尔积
如何关联:
当在关联查询场景下,我们关联查询->首先会扫描驱动表的第一行数据,然后根据第一行数据对被驱动表进行扫描,找到的数据合为一行为总的一行数据;
结论:
1.驱动表是一定会被全局扫描的,而被驱动表不一定,所以我们索引建在被驱动表上,驱动表因为一定全部被扫所以建不建索引是无所谓的;
2.为了提升效率,我们数据量相对较小的最好作为驱动表
3.另外,inner join和left join不太一样,在inner join下mysql会自动选择那个为被驱动表,而不是它们的相对位置,是根据小结果集的作为驱动表;

关联查询实例
- 关联查询一下两个表 ->extra出现两表之间没有关联字段,查很慢,出现笛卡尔
- EXPLAIN SELECT * FROM class LEFT JOIN book ON class.`card`=book.`card`;
- #创建索引,这里我们一般都是给被驱动表建立索引
- CREATE INDEX Y ON book(card);
- #执行删除
- CALL proc_drop_index("mydb","book");
- DROP INDEX Y ON book;
- DROP INDEX X ON class;
- #创建索引
- ALTER TABLE class ADD INDEX X (card);
- #inner join,mysql自己选择哪个是被驱动表——>根据索引进行判断,谁有索引就谁是被驱动
- #小数据为驱动表,扫描时间短以此提高效率
- #求所有dept对应的CEO名称
- #1.这里会发现是一趟查询,mysql5.7的一个优化,c表为驱动表,我们这个被驱动表为ab虚拟表
- #而虚拟表又不能创建索引,所以说会浪费一次优化机会,5.7更新所在之处
- EXPLAIN SELECT c.`name`,ab.name ceoname FROM t_emp c LEFT JOIN
- (SELECT b.`id`,a.`name` FROM t_emp a INNER JOIN t_dept b ON a.`id`=b.`CEO`)ab
- ON c.`deptld`=ab.id;
- #得到dept的掌门
- SELECT b.`id`,a.`name` FROM t_emp a INNER JOIN t_dept b ON a.`id`=b.`CEO`
- #2.先查询名字和CEO
- SELECT ab.name,c.`name` ceoname FROM
- (SELECT a.`name`,b.`CEO` FROM t_emp a LEFT JOIN t_dept b ON a.`deptld`=b.`id`) ab
- LEFT JOIN t_emp c ON ab.ceo=c.`id`;
- #3.最快,直接关联,不用子查询一次性两次外连接得到帮派派主(第一次得到用户那边信息,第二次根据CEO进行筛选)
- EXPLAIN SELECT a.`name`,c.`name` ceoname FROM t_emp a
- LEFT JOIN t_dept b ON a.`deptld`=b.`id`
- LEFT JOIN t_emp c ON b.`CEO`=c.`id`;
关联查询小结论:
1.我们需要保证被驱动表join的字段以及被索引
2.left join时,选择小表为驱动
3.inner join:小结果集作为驱动表
4.子查询尽量不要放在驱动表,因为5.7前虚拟表是不能用索引的,会导致效率降低
5.能直接关联就直接关联
关联优化测试
这里明显有not导致索引不能使用,优化->使用left join进行关联查询,然后根据条件过滤即可
- #至少两个非掌门成员的门派(先掌门编号,然后根据掌门编号在t_emp中查)
- SELECT * FROM t_emp a WHERE a.id NOT IN
- (SELECT b.CEO FROM t_dept b WHERE b.CEO IS NOT NULL);
- #优化(先得到所有掌门(left join),然后条键过滤)
- SELECT * FROM t_emp a LEFT JOIN t_dept b ON a.id = b.CEO
- WHERE b.id IS NULL;
索引对于分组查询的影响
(24条消息) 【mysql知识点整理】--- order by 、group by 出现Using filesort原因详解_nrsc的博客-CSDN博客_filesort 原因
总结:
1.分组查询order by后的字段能否使用索引->取决于后面是否接了过滤条件,如果接了则索引生效
2.order by后面的顺序是很重要的,顺序不一样结果不一样,所以并不会被优化
3.如果字段都升序或者降序是不影响结果的,如果不一致就会影响从而出现using filesort
- #执行删除
- CALL proc_drop_index("mydb","emp");
- CALL proc_drop_index("mydb","dept");
- #分组查询
- CREATE INDEX idx_age_deptid_name ON emp (age,deptid,NAME)
- CREATE INDEX idx_age_deptid_empno ON emp (age,deptid,empno);
- #以下是否能使用到索引,能否去掉using filesort ,(order by想用索引必须要过滤条件)
- EXPLAIN SELECT SQL_NO_CACHE * FROM emp ORDER BY age,deptid;
- EXPLAIN SELECT SQL_NO_CACHE * FROM emp ORDER BY age,deptid LIMIT 10;
- #无过滤 不索引
- EXPLAIN SELECT * FROM emp WHERE age=45 ORDER BY deptid;
- EXPLAIN SELECT * FROM emp WHERE age=45 ORDER BY deptid,NAME;
- EXPLAIN SELECT * FROM emp WHERE age=45 ORDER BY deptid,empno;
- #deptid字段需要再name前面,这顺序并不会被优化,因为结果会被影响,order by后面字段顺序是很重要的
- EXPLAIN SELECT * FROM emp WHERE age=45 ORDER BY NAME,deptid;
- EXPLAIN SELECT * FROM emp WHERE deptid=45 ORDER BY age;
- #顺序错,必排序,可以都是降序或者升序,这样的话,顺序改一下还是不影响结果的
- EXPLAIN SELECT * FROM emp WHERE age=45 ORDER BY deptid DESC, NAME DESC ;
- EXPLAIN SELECT * FROM emp WHERE age=45 ORDER BY deptid ASC, NAME DESC ;
- #方向反 必排序,一升一降不能索引:Using filesort
排序分组优化
mysql会对索引的选择进行优化,选择一个自认为最快的索引
如果不在字段不在索引列上,filesort有两种算法
1.双路排序:就是两次扫描磁盘,先把所有内容扫一遍放到磁盘,扫完后再对磁盘中的内容进行排序(也就是读取行指针和order by列),对磁盘两次扫描,IO很耗时
2.单路排序:从磁盘上读取查询的索引列,然后按照order by进行查询,他把每次读取的内容放到内存中,减少了IO的损耗

group by与other by的区别就是:
group by可以没有限制条件就是用索引,other by无过滤不索引
还一个很优化的点(覆盖索引):
之前不是出现模糊查询like %xx、is not、other by xxx这些都会导致索引失效嘛,我们可以对查询的内容进行限制,不再是select * ,而是字段限制了,这样可以根据字段来匹配索引,以此提高效率;
- CREATE INDEX idx_id_age_deptid ON emp(id,age,deptid);
- #可以对查询内容上索引
- EXPLAIN SELECT SQL_NO_CACHE NAME FROM emp WHERE age IS NOT NULL;
- EXPLAIN SELECT * FROM emp WHERE NAME LIKE '%abc';
- EXPLAIN SELECT SQL_NO_CACHE id,age,deptid FROM emp WHERE NAME LIKE '%abc';
- #查看索引
- SHOW INDEX FROM emp;
作业(sql练习+优化)
注意:Group by的字段设置之后,前面select的字段只能包含Group by的内容和函数内容,否则会报错
- EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE age =30 AND empno <101000 ORDER BY NAME ;#0.729
- #执行删除
- CALL proc_drop_index("mydb","emp");
- CALL proc_drop_index("mydb","dept");
- #建立索引,优先第一个idx_age_empno的索引,mysql会优选择最优的索引
- CREATE INDEX idx_age_empno ON emp(age,empno);
- CREATE INDEX idx_age_name ON emp (age,NAME);
- CREATE INDEX idx_age ON emp(age);
- CREATE INDEX idx_name ON emp(NAME);
- CREATE INDEX idx_id_age_deptid ON emp(id,age,deptid);
- #可以对查询内容上索引
- EXPLAIN SELECT SQL_NO_CACHE NAME FROM emp WHERE age IS NOT NULL;
- EXPLAIN SELECT * FROM emp WHERE NAME LIKE '%abc';
- EXPLAIN SELECT SQL_NO_CACHE id,age,deptid FROM emp WHERE NAME LIKE '%abc';
- #查看索引
- SHOW INDEX FROM emp;
- #1.求小弟比门派派主年龄小的信息
- SELECT a.name FROM t_emp a
- LEFT JOIN t_dept b ON a.`deptld`=b.id
- LEFT JOIN t_emp c ON b.CEO=c.`id`
- WHERE c.`age`<a.`age`;
- #优化
- EXPLAIN SELECT SQL_NO_CACHE a.`name`,a.`age`,c.`name`,c.`age` FROM emp a
- LEFT JOIN dept b ON a.`deptId`=b.`id`
- LEFT JOIN emp c ON b.`ceo`=c.`id`
- WHERE c.`age`<a.`age`;
- #2.列出年龄比帮派平均年龄小的人员(先得到部门分组的人员信息)
- SELECT c.`name`,c.`age` FROM t_emp c INNER JOIN
- (SELECT a.`deptld`,AVG(a.`age`) avgage FROM t_emp a WHERE a.`deptld` IS NOT NULL
- GROUP BY a.`deptld`)aa
- ON c.`deptld`=aa.deptld
- WHERE c.`age`<aa.avgage;
- #优化,将这个子查询作为驱动表
- #因为子查询5.7版本前是不能有索引的,所以我们把它作为驱动表,这样非驱动表就可以上索引
- EXPLAIN SELECT SQL_NO_CACHE c.`name`,c.`age`,aa.avgage FROM emp c
- INNER JOIN
- (SELECT a.deptId,AVG(a.age)avgage FROM emp a WHERE a.deptId IS NOT NULL
- GROUP BY a.deptId)aa
- ON c.`deptId`=aa.deptId
- WHERE c.`age`<aa.avgage;
- #创建索引
- CREATE INDEX idx_deptId ON emp(deptId);
- CREATE INDEX idx_deptId_age ON emp(deptId,age);
- #3.列出至少有2个年龄>40岁的成员的门派 (select得到数量,肯定是group by了)
- #(先按照门派分组 ->然后进行筛选得到>40岁的员工数量 —>最后进行判断)
- SELECT b.`deptName`,b.`id`,COUNT(*) FROM t_emp a
- INNER JOIN t_dept b ON a.`deptld`=b.`id`
- WHERE a.`age`>40
- GROUP BY b.`deptName`,b.`id`
- HAVING COUNT(*)>=2;
- #优化
- EXPLAIN SELECT SQL_NO_CACHE b.`deptName`,b.`id`,COUNT(*) FROM dept b
- STRAIGHT_JOIN emp a ON a.`deptId`=b.`id`
- WHERE a.`age`>40
- GROUP BY b.`deptName`,b.`id`
- HAVING COUNT(*)>=2;
- #建立索引
- CREATE INDEX idx_deptName ON dept(deptName);
- CREATE INDEX idx_deptId_age ON emp(deptId,age);
- #4.非掌门人员(先查询所有有帮派的帮派,然后提取CEO,然后not in)
- SELECT * FROM t_emp a WHERE a.`id` NOT IN
- (SELECT b.`CEO` FROM t_dept b WHERE b.`CEO` IS NOT NULL)
- ;
- SELECT * FROM t_emp
- SELECT * FROM t_dept
- #优化:(1.得到非掌门的门派成员信息,采用左外关联查询,门派表没有匹配的就会null,所以要b.id is null)
- SELECT * FROM t_emp a
- LEFT JOIN t_dept b ON a.`id`=b.`CEO`
- WHERE b.`id` IS NULL;
- SELECT c.deptName,c.id,COUNT(*)
- FROM t_emp a INNER JOIN t_dept c ON a.`deptld`=c.id
- LEFT JOIN t_dept b ON a.`id`=b.`CEO`
- WHERE b.`id` IS NULL
- GROUP BY c.deptName,c.id
- HAVING COUNT(*)>=2
- ;
- #5.得到所有在帮派的成员->得到在籍帮派的名字和id->在关联一次,去除掌门,留下非掌门的信息(利用左外的性质)
- #要得到数量,所以分组
- EXPLAIN SELECT SQL_NO_CACHE c.`deptName`,c.`id`,COUNT(*) FROM emp a
- INNER JOIN dept c ON a.`deptId`=c.`id`
- LEFT JOIN dept b ON a.`id`=b.`CEO`
- WHERE b.`id` IS NULL
- GROUP BY c.`deptName`,c.`id`
- HAVING COUNT(*)>=2;
- #创建索引
- CREATE INDEX idx_deptName ON dept(deptName);
- CREATE INDEX idx_deptId ON emp(deptId);
- CREATE INDEX idx_CEO ON dept(CEO);
- #6.列出所有人员,并且增加一列备注是否为掌门,如果是备注就是——>case when 判断
- #然后利用左外性质b的id->is null then xxx进行判断
- SELECT a.`name`,a.`age`,b.`deptName`,(CASE WHEN b.id IS NULL THEN '否' ELSE '是' END)'是否为掌门'
- FROM t_emp a
- LEFT JOIN t_dept b ON a.`id`=b.`CEO`;
- #7.列出所有门派,并且备注,平均年龄>50就是老鸟,否则为菜鸟
- SELECT b.`deptName`,b.`id`,IF(AVG(a.`age`)>50,'老鸟','菜鸟')'老鸟or菜鸟'
- FROM t_emp a
- INNER JOIN t_dept b ON a.`deptld`=b.`id`
- GROUP BY b.`deptName`,b.`id`;
- #8.显示每个门派年龄最大的人(->先得到最大年龄根据门派进行分组->然后关联一下人物表得到最大年龄的人)
- SELECT c.`name`,c.`age`,aa.maxage FROM t_emp c INNER JOIN
- (SELECT a.`deptld`,MAX(a.`age`)maxage
- FROM t_emp a WHERE a.`deptld` IS NOT NULL
- GROUP BY a.`deptld`)aa
- ON c.`deptId`=aa.deptld AND c.`age`=aa.maxage;
- #9.求每个门派第三大年龄的人(w写错了)
- SELECT a.`age`,a.`name`,a.`deptld` FROM t_emp a ORDER BY a.`age` DESC
- LEFT JOIN(
- SELECT a.`id` FROM t_emp a INNER JOIN t_dept b ON a.`deptld`=b.id
- )aa ON a.`deptld`=aa.id;#这里就分组错了,原计划分组后再limit完成
-
相关阅读:
图解 | 聊聊 MyBatis 缓存
gitLab 使用tortoiseGit 克隆新项目 一直提示tortoiseGitPlink输入密码 输完也不生效
【毕业设计】基于javaEE+原生servlet+tomcat的教师工资管理系统设计与实现(毕业论文+程序源码)——教师工资管理系统
NLP对话系统面试总结,从阿里 百度 滴滴一轮游到最终拿下40万offer
自己搜的算法题
gcc-linaro-7.5.0-2019.12-x86_64_aarch64-linux-gnu交叉编译Arm Linux环境下的身份证读卡器so库操作步骤
AI学习教程:AI(Adobe lliustrator)快速入门
React中useRef()方法
VTK与OpenGL是什么,有什么关系?
EXCEL表格-批量去除百分号%的三种方案
- 原文地址:https://blog.csdn.net/weixin_57128596/article/details/125455737
